https://ieeexplore.ieee.org/document/5545402
Front-End Factor Analysis for Speaker Verification
This paper presents an extension of our previous work which proposes a new speaker representation for speaker verification. In this modeling, a new low-dimensional speaker- and channel-dependent space is defined using a simple factor analysis. This space i
ieeexplore.ieee.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문에서는 speaker verification에 사용할 수 있는 speaker를 표현하는 새로운 방식을 소개합니다. 간단한 factor analysis를 이용하여 새로운 저차원 speaker 및 channel dependent space를 정의합니다. 해당 space는 total variability space인데, speaker와 channel variability를 modeling하기 때문에 이와 같이 명명되었습니다. 저자들은 두 가지 speaker verification system을 제안합니다. 첫 system은 SVM 기반이며, input data와의 유사도를 추정하기 위해 cosine kernel을 사용합니다. 두번째 system은 마지막 decision score로 consine similarity를 직접 사용하는 방식입니다. 저자들은 3가지 channel compensation technique을 total variability space에 test했는데, within-class covariance(WCCN), linear discriminate analysis(LDA), nuisance attribute projection(NAP) 방식들입니다. 저자들이 실험을 통해, LDA가 WCCN에 의해 뒤따를 때 가장 좋은 결과를 얻었습니다. NIST 2008 Speaker Recognition Evaluation dataset의 core condition에서 남성 영어 시험에 대해 cosine distance를 사용하여 1.12%의 EER과 0.0094의 MinDCF를 얻었습니다.
Introduction
최근 몇 년동안, JFA는 text-independent speaker detection task에서 우수한 성능을 보였습니다. JFA는 inter-speaker(화자 간) variability를 modeling하고, GMM의 맥락에서 channel/session variability compensation하기 위한(channel/session variability의 특성이 화자 인식 결과에 미치는 영향을 줄이는) 강력한 tool을 제안했습니다.
동시에, GMM supervector space에서 SVM을 적용하는 것은, 특히 nuisance attribute projection(NAP)가 channel effect를 다루기 위해 적용될 때 흥미로운 결과를 얻을 수 있었습니다. 이러한 접근법에선, 사용된 kernel은 두 GMM 사이의 KL distance의 선형 근사를 기반으로 합니다. speaker GMM mean supervector는 universal back ground model(UBM) mean supervector가 maximum a posterior(MAP) adaptation을 이용해 speaker frame에 adapting하여 얻어집니다.
저자들은 과거에 speaker verification을 위해 JFA와 SVM을 결합하는 방법을 제시했었습니다. JFA를 speaker factor 추정하는 데 직접 사용했습니다. 그리고 얻은 speaker factor를 SVM의 input으로 사용했습니다. 저자들은 여러 kernel을 테스트했고, speaker factor space에서 residual channel effect을 위한 compensation(남아있는 channel effect를 줄이기 위한) 을 사용하려고 WCNN(동일한 클래스 내의 데이터 변동성을 정규화하는 기법, 즉 같은 화자의 다른 녹음에 대한 변동성을 줄이는 것이다)을 사용하는 경우에 cosine kernel을 사용한 결과가 가장 좋다는 것을 알아냈습니다.
최근에 저자들은 JFA를 통해 추정된 channel factor가 speaker의 information까지 포함하고 있다는 것을 알아냈습니다. 그래서 저자들은 feature extractor로써 factor analysis를 사용하는 새로운 speaker verification system을 제안합니다. factor analysis는 'total variability space'라는 새로운 저차원 공간을 정의하는 데 사용되었습니다. 이 새로운 space에서, 주어진 발화는 total factor라는 이름의 새로운 vector로 표현됩니다(저자들은 해당 vector를 'i-vecor'라고도 부릅니다). 해당 연구에서 channel compensation은 total variability space라는 저차원에서 이루어지며, 기존의 JFA는 고차원 GMM supervector space에서 이루어졌습니다. 그래서 저자들은 total factor 사이의 유사도를 측정하는 cosine kernel을 이용한 SVM 기반 system을 제시합니다. 추가적으로, target speaker factor와 test total factor의 cosine distance를 직접 계산한 결과를 decision score로 사용하는 system도 제시합니다. 두번째 system의 경우, SVM을 결정 과정에서 제거했습니다. 여기서 중요한 특징은, SVM, JFA 등을 사용한 method들과 다르게 speaker enrollment가 필요 없으며, 더 빠르고 더 간단하게 결정 과정을 진행할 수 있다는 것입니다. 저자들은 WCCN을 사용한 다음에 LDA을 적용하는 것이 가장 좋은 결과를 얻었다고 했으며, LDA는 같은 화자의 분산은 줄이고 다른 화자간의 분산은 키우기 위해 적용되었습니다.
Joint Factor Analysis
JFA에서 speaker 발화는 supervector M으로 표현됩니다. supervector M은 speaker와 channel/session subspace로부터 얻어지는 추가적인 구성요소들로 이루어집니다. 특히 speaker dependent supervector는

이와 같은 형태입니다. 위 식에서 m은 speaker 및 session independent supervector입니다(해당 supervector는 일반적으로 UBM을 통해 얻어집니다). V와 D는 speaker subspace에 의해 정해지는 값입니다. V는 eigenvoice matrix이고 D는 diagonal residual입니다. 그리고 U는 session subspace(eigenchannel matrix)입니다. y, z vector는 speaker dependent factor이며, x는 session dependent factor입니다. 이 factor들은 각각 관련된 subspace에서 얻어지며, random variable ~ N(0, I)라고 추정됩니다. speaker recognition을 위해 JFA을 적용하는 것은, 먼저 appropriately labelled development corpora에서 subspace(i.e., V, D, U)를 추정하고, 해당 subspace에서 speaker factor와 session factor를 추정하는 과정으로 이루어집니다. speaker dependent supervector s는 m+ Vy + Dz로 구해집니다. scoring은 test 발화 fature vector와 session-compensated speaker model (M - Ux) 사이의 likelihood를 계산하여 구해집니다.
Front-End Factor Analysis
이제 저자들이 말한 두 system에 대해 살펴보겠습니다. 두 system 모두 feature extractor로 factor analysis를 사용합니다.
Total Variability
speaker와 channel factor를 기반으로 하는 전통적인 JFA modeling은 두개의 구별된 space을 정의하는 것이 목표입니다. speaker space는 eigenvoice matrix V로 표현되고, channel space는 eigenchannel matrix U로 표현됩니다. 저자들이 제안한 접근법은 오직 한개의 space만 정의합니다. 'total variability space'라 불리는 이 space는 speaker와 channel variability를 동시에 포함합니다. total variability matrix로 정의되고, total variability matrix는 total variability convariance matrix에서 가장 큰 eigenvalue를 가진 eigenvector를 포함하고 있습니다. 저자들은 GMM supervector space에서 speaker effect와 channel effect를 구분짓지 않습니다. 일반적으로 channel effect만 modeling한 JFA의 channel factor가 speaker의 정보도 포함하고 있다는 사실 때문에, 저자들은 single space를 이용하는 새로운 접근법을 정의했습니다. 발화가 주어졌을 때, 새로운 speaker와 channel dependent GMM supervector는

이와 같이 다시 정의할 수 있습니다. 여기서 m은 speaker 및 channel independent supervector를 의미합니다. T는 low rank의 직사각 matrix이고, w는 standard normal distribution에서 얻어진 random vector입니다. vector w의 구성요소를 total factor or i-vector(identity vector)라고 합니다. M은 일반적으로 mean vector m과 공분산 matrix TT^t을 가진 정규 분포라고 가정합니다. total variability matrix T를 학습하는 과정은 정확히 engienvoice V matrix를 학습하는 것과 동일하지만, 한 가지 차이점이 존재합니다. eigenvoice를 학습할 때, 주어진 speaker의 모든 recording들이 같은 사람에서 생성된 것이라고 간주하고 진행되지만, total variability matrix는 주어진 화자의 전체 발화는 다른 speaker에 의해 생성되었다고 간주합니다(주어진 모든 발화가 전부 다른 화자로부터 생성되었다고 간주합니다). 저자들이 제시한 새로운 모델은 speech utterance를 저차원의 total variability space로 투영하는 factor analysis로 볼 수 있습니다.
total factor w는 hidden variable인데, 주어진 발화에 대한 Baum-Welch statistics에 조건을 부여한 posterior distribution에 의해 정의될 수 있습니다. 이 posterior distribution은 gaussian distribution이고 이 distribution의 평균은 i-vector에 정확히 해당합니다.

Baum-Welch statistics은 UBM을 통해 추출됩니다. L 길이의 frame sequence {y_1, y_2, ... , y_L}가 가지고 있고 UBM Ω이 F차원의 feature space에서 정의되는 C개의 혼합 components로 구성되어 있다고 가정하겠습니다. 이 상황에서, 주어진 발화 u에 대한 i-vector를 추정하기 위해 필요한 Baum-Welch statistic은 위와 같이 얻어집니다. 여기서 c는 1부터 C까지이며, 이는 gaussian index입니다. P(c|x_t, Ω)은 혼합 구성요소 c가 vector y_t를 생성할 posterior probability를 의미합니다. i-vector를 추정하기 위해, 저자들은 UBM mean mixture component를 기반으로 하는 centralized first-order Baum-Welch를 계산합니다. 식은 아래와 같습니다.

여기서 m_c는 UBM 혼합 구성요소 c의 평균을 의미합니다. 주어진 발화에 대한 i-vector는 다음 식으로 얻어집니다.

N(u)는 대각행렬이고, 대각 행렬 block은 N_cI(c = 1, 2, ... , C)이며 차원은 CF x CF입니다. F^~(u)는 CF x 1 차원의 supervector이고, 이는 발화 u에서 얻어진 모든 first order Baum Welch statistics F^~_c를 붙인 값입니다. Σ는 CF x CF 차원의 대각 공분산 행렬이며, 이는 factor analysis training을 통해 얻어지는 값입니다. 그리고 Σ는 total variability matrix T에 의해 capture되지 않는 residual varaibility를 modeling합니다.
Support Vector Machines
SVMs은 supervised binary classifier입니다. supervised learning example을 가지고 positive example과 negative example을 구분지을 수 있는 가장 좋은 선형 seperator H를 찾는 방식입니다.

linear seperator는 위와 같은 식인 function f로 정의됩니다. x는 input vector가 되고, (w,b)는 학습을 통해 선택된 SVM parameter입니다.

새로운 example x에 대한 분류는 f(x)의 부호에 따라 달라집니다.

kernel funcion이 base일 때, 최적의 분류기는 위 식으로 표현됩니다. 여기서 a_i*와 w_0*는 SVM의 parameter로, 학습을 통해 최적의 값을 찾게 됩니다.
1) Cosine Kernel: 저자들은 이전 실험에서 SVM을 speaker factor space에 적용했을 때, cosine kernel을 사용하는 경우가 가장 좋은 결과를 얻었습니다. 동일한 방식으로, 두 i-vector w1과 w2 사이에 cosine kernel을 사용합니다.

식은 위와 같습니다. cosine kernel은 각 i-vector의 norm으로 정규화된 linear kernel로 구성됩니다. 두 i-vector의 각도만 고려하고 크기는 고려하지 않는다는 뜻입니다. non-speaker information(ex, session & channel)이 i-vector의 크기에 영향을 준다고 생각했기에, 이와 같이 cosine kernel을 정의했다고 합니다. 이를 통해 i-vector system의 강건성을 크게 향상시켰다고 합니다.
Cosine Distance Scoring
저자들은 cosine distance scoring을 통해 target speaker i-vector w_target과 test i-vector w_test에 cosine kernel을 적용해 직접 점수를 구하는 방식을 제시합니다.

식은 위와 같습니다. 이 kernel의 값과 threshold θ을 이용해 final decision을 합니다. 이렇게 점수를 구하는 방식은 SVM과 JFA와 다르게 target speaker enrollment가 요구되지 않습니다. SVM과 JFA는 target speaker dependent supervector가 enrollment step에서 추정되어야 합니다. target i-vector와 test i-vector는 정확히 같은 상황(target and test i-vector를 추정하는 과정에서 추가적인 과정이 없는 상황)에서 추정되므로, i-vector는 new speaker recognition feature로 보여질 수 있습니다. 이러한 새로운 modeling에서는 factor analysis는 speaker와 channel effect를 modeling하기보단 feature extractor 역할을 수행한다고 볼 수 있습니다. speaker verification을 위해 cosine kernel을 decision score로써 사용하는 것은 다른 JFA scoring method보다 더 빠르고 더 적은 연산량을 사용합니다.
Intersession Compensation
total variability space을 기반으로 한 modeling은 기존 JFA처럼 GMM supervector space에서 channel compensation 하는 것이 아닌 total factor space에서 channel compensation을 합니다. total factor space에서 channel compensation을 적용했을 때의 장점은 GMM supervector에 비해 저차원 vector를 사용한다는 점입니다. 이를 통해 더 적은 연산량이 사용됩니다. 저자들은 nuisance effect를 없애기 위해 total variability space에서 3가지 channel compensation technique을 test했습니다.
1) Within-Class Covariance Normalization(WCCN)
speaker factor space에서 성공적으로 적용되었던 방식입니다. class 내의 공분산의 역수를 사용하여 cosine kernel을 정규화합니다.
2) Linear Discriminant Analysis(LDA)
주어진 speaker의 모든 발화는 하나의 class로 추정될 때, LDA는 새로운 special axes를 정의합니다. special axes는 channel effect에 의해 야기되는 intra-class variance를 minimize하며, speaker 사이의 분산은 maximize합니다. LDA approach의 이점이 있습니다. 원치 않는 방향을 제거하고 화자 간의 정보에 대한 손실을 최소화한다는 점이 이점입니다.
speaker verification을 위해 discriminative version NAP algorithm을 사용해봤는데, 큰 소득은 없었다고 합니다.
3) Nuisance Attribute Projection(NAP)
그래서 마지막으로 NAP를 사용합니다. 이는 class 내 공분산의 가장 큰 eigenvalue를 갖는 eigenvector를 기반으로 channel space를 정의합니다. 새로운 i-vector는 speaker space인 orthogonal complementary channel space에 투영됩니다.
이제 이 방식들에 대해 저 사제히 살펴보겠습니다.
- Within Class Covariance Normalization(WCNN)
WCCN은 SVM modeling에서 target speaker와 impostor 사이의 선형 분리를 기반으로 하며, one-versus-all decision을 사용합니다. WCCN의 idea는 SVM train동안에 false acceptance와 false rejection의 예상 오류율을 최소화하는 것입니다. error rate를 minimize하기 위해, classification error metric에 upper bound를 적용합니다. 이 문제의 최적화된 solution은 upper bound를 minimize하며 찾아지며, 이는 동시에 classification error를 줄입니다. 이 optimization 과정은 SVM의 hard-margin 분리 형식을 변경할 수 있게 합니다. 최종 도출된 solution은 아래와 같이 linear kernel에 의해 주어집니다.

R은 대칭이고, positive semi-definite matrix(모든 eigenvalue값이 음이 아닌형태)입니다. 최적의 정규화 kernel matrix는 R = W^-1에 의해 얻어지며, W은 train중에 계산되는 모든 impostor에 관한 within class covariance matrix입니다. 모든 발화가 동일한 화자에서 주어졌다고 가정한 상태로 진행됩니다. within class covariance matrix는
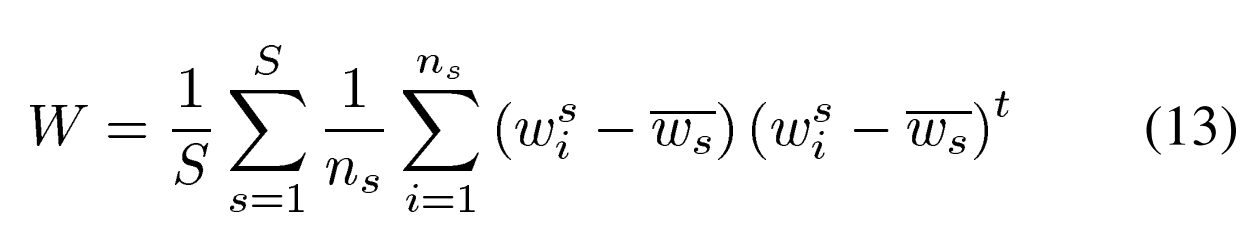
이와 같은 식으로 계산됩니다.

이는 각 speaker의 i-vector의 평균을 의미합니다. S는 speaker의 수를 나타내며, n_s는 speaker s의 발화 수를 나타냅니다. cosine kernel의 내적 형태를 보존하기 위해, feature mapping function φ는 아래와 같은 식으로 정의됩니다.

B는 W^-1 = BB^t라는 Cholesky decomposition에 의해 얻어지는 값입니다. 저자들의 방식은, WCNN algorithm이 cosine kernel 적용됩니다. 새로운 형태의 kernel은
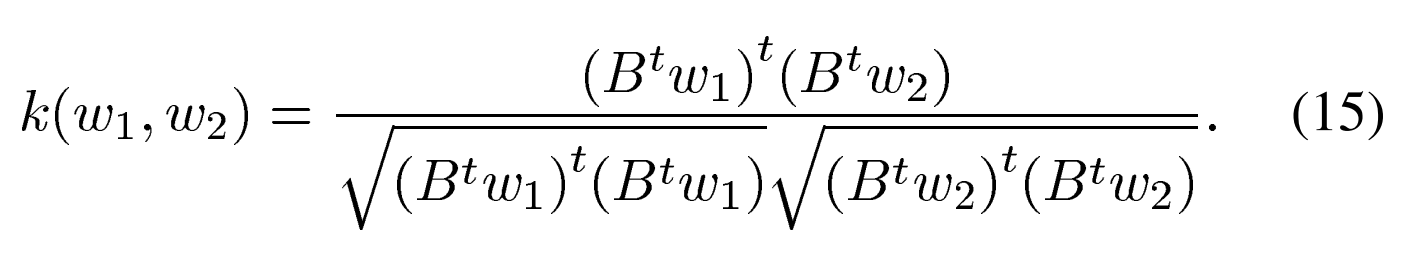
이와 같이 작성됩니다. WCNN algorithm은 within class covariance matrix를 사용하여 cosine kernel function을 정규화하여 intersession variability에 compensation을 부여합니다. 이는 다른 방식들과는 달리 공간 내에서 방향 보존을 보장합니다.
- Linear Discriminant Analysis(LDA)
LDA는 pattern recognition 분야에서 자주 사용되는 차원 축소 기술입니다. 이는 서로 다른 class를 더 잘 구분하기 위해 새로운 직교 축을 찾는 방식입니다. 찾아진 축은 무조건 다른 class의 분산을 maximize해야하고, class 내의 분산은 minimize해야한다는 조건이 있습니다. 저자들의 방식에서는 각 class가 단일 speaker의 모든 recording으로 구성됩니다. LDA 최적화 문제는

이와 같이 정의될 수 있습니다. 위 비율은 space direction v에 대한 Rayleigh coefficient(레일리 계수)라고 종종 불립니다. 서로 다른 class의 분산 S_b와 동일 class의 분산 S_w의 정보 비율을 나타내고, 공간 방향 v는 주어집니다.

각 인자들은 위와 같은 식으로 표현할 수 있습니다. 여기선 w_s bar는 각 speaker의 i-vector의 평균을 의미하고, S는 speaker의 수, n_s는 각 speaker s의 발화 수를 나타냅니다. i-vector의 경우, speaker population mean vector는 null vector입니다. 왜냐하면 FA에서 i-vector는 standard normal distribution을 갖기 때문에 평균 vector는 null vector가 됩니다.
LDA의 목적은 Rayleigh coefficient를 maximize하는 것입니다. 이 최대화는 가장 높은 eigenvalue를 갖는 eigenvector로 구성된 projection matrix A를 정의하는 데 사용됩니다. i-vector는 LDA에서 얻어지는 projection matrix A에 적용됩니다. 최종적으로 두 i-vector w1, w2의 cosine kernel은

이와 같아집니다.
- Nuisance Attribute projection
nuisance attribute projection algorithm은 nuisance direction을 제거한 적절한 projection matrix를 찾는 것이 목표입니다. projection matrix는 channel complementary space에서 직교 projection을 수행하며, 이 projection matrix는 오직 speaker에만 의존적입니다. projection matrix는 아래와 같습니다.

R은 column이 k개의 within-class coraiance matrix(or channel covariance)에서 큰 eigenvalue를 갖는 eigenvectors로 이루어진 low rank 직사각 matrix입니다. 이러한 eigenvectors는 channel space로 정의됩니다. NAP matrix 기반 cosine kernel은 다음과 같습니다.

여기서 w1과 w2는 2개의 total i-vector들입니다.
Experiments
Dataset & Experiments Setup
모든 실험은 NIST 2006 speaker recognition evaluation(SRE)을 development dataset으로 사용하고 2008 SRE를 test data로 사용하면서 진행되었습니다. 2006 evaluation set은 350명의 남성, 461명의 여성, 51448개의 test 발화를 포함하고 있습니다. 각 target speaker model에 대해, 약 2분간의 화자의 음성이 포함된 5분의 전화 대화 recording이 제공됩니다. NIST 2008 SRE의 핵심 condition은 2006 SRE 전화 대화와 비슷하면서 새로운 interview data라는 것입니다. 저자들의 실험은 training과 testing 모두 전화 data로만 진행되었습니다. 2008 SRE의 핵심 condition은 short2-short3로 이름이 붙었습니다. 1140명의 여상, 648명의 남성, 37050개의 파일로 이루어져 있습니다. 저자들은 NIST 2008 SRE의 short2-10초(enrollment를 위한 음성 데이터의 길이가 약 2분, test에 사용될 음성 데이터의 길이가 10초)초 그리고 10초-10초(enrollment를 위한 음성 데이터의 길이가 10초, test에 사용될 음성 데이터의 길이가 10초) 조건에서도 실험했습니다. 두 조건에서는 1140명의 여성, 648명의 남성, 총 21907개의 test file을 이용했습니다.
저자들은 25ms의 hamming window를 이용해 추출된 cepstral feature를 사용해 실험을 진행했습니다. 매 10ms마다, 19mel frequency cepstral coefficient(MFCCs)와 log energy가 계산되었습니다. 이러한 20차원의 feature vector는 3초 sliding window를 사용하여 feature warping(window 내에서 feature를 얻은 후 균일하게 만드는)을 적용받았습니다. delta와 delta-delta coefficient는 60차원의 feature vector를 생성하기 위해 5 frame window를 이용하여 계산되었습니다.
저자들은 성별에 따라 다른 UBM을 사용했으며, UBM은 2048개의 gaussian으로 이루어집니다. 그리고 두 성별에 따른 joint factor analysis를 사용했습니다. 첫번째 JFA는 300개의 speaker factor와 100 channel factor로 이루어져 있습니다. 두번째는 speaker의 common factor를 포함할 수 있도록 diagnoal matrix D를 추가했습니다. diagonal matrix가 추정되었을 때, eigenvoice matrix V와 diagonal matrix D로 분리하여 사용했습니다. total variability matrix T에 의해 정의되는 400개의 factor를 사용했습니다.
JFA scoring에 의해 얻어지는 decision scroe는 zt-norm에 의해 정규화됩니다. 여성에 대해 300 t-norm model을 사용했고, 약 1000개의 z-norm 발화를 사용했습니다. SVM system에서, t-정규화를 하기 위해 307개의 여성 모델과 SVM 훈련을 위한 1292개의 여성 SVM 배경 impostor model을 사용했습니다. impostor는 NIST 2005 SRE 데이터셋을 제외하고는 UBM train과 동일한 dataset에서 가져왔습니다. 저자들은 NIST 2005 SRE dataset에서 가져온 204 impostor을 기반으로 한 t-norm score normalization을 수행했습니다.
저자들은 LDA와 WCCN matrix를 추정할 때 서로 다른 dataset을 이용했습니다. DLA는 speaker variability을 modeling하기 때문입니다. 더 많은 speaker를 추가하는 것은 performance 향상에 매우 큰 도움이 되겠지만, WCCN은 channel을 modeling하며, NIST-SRE dataset은 서로 다른 channel에서 동시에 통화하는 여러 speaker를 포함하고 있기 때문에 NIST-SRE dataset만 사용하는 것이 더 좋다고 합니다.
SVM-FA

Within-Class Covariance Normalization
total variability factor에 WCCN을 수행했을 때와 안했을 때를 비교하겠습니다. channel factor의 합을 기반으로 한 JFA scoring에서 얻어진 결과도 제시합니다. WCCN을 사용했을 때와 안했을 때를 비교해보면, total factor space에 channel variability에 대한 compensate를 적용하는 것이 도움이 된다는 것을 알 수 있습니다. NIST 2006 SRE all trial을 보면 특히 알 수 있습니다. JFA scoring에 비해 1% 향상된 EER(Equal Error Rate)수치 2.76%을 얻을 수 있습니다. 그러나 NIST 2008 SRE data에서의 성능을 비교해보면, classical JFA scoring 기반 channel factor가 가장 좋은 결과를 보이는 것을 알 수 있습니다. NIST 2004와 2005 SRE dataset에서 추정된 WCCN이 NIST 2008 SRE의 channel compensation에는 적절하지 않다는 것을 의미합니다.
Linear Discriminant Analysis
channel effect compensation을 하기 위해 i-vector에 linear discriminant analysis를 적용하여 얻은 결과를 비교합니다. 저자들은 여러 다른 차원의 LDA 차원 감소를 사용하여 결과를 얻었으며, 이를 통해 원치 않는 nuisance direction을 제거하는 기술의 효과를 보여줄 수 있습니다.

실험은 NIST 2006 SRE dataset을 이용했습니다. 위 결과는 channel effect에 compensate를 적용하기 위해 LDA를 사용했을 때의 효과를 보여줍니다. 첫번째 중요한 결과를 보면, 동일 화자의 분산을 minimize하기 위해 LDA를 사용하여 space를 rotate시키는 것이 차원 축소없이(dim = 400) cosine kernel의 성능을 향상시킨다는 점입니다. 만약 저자들이 DCF(system의 error decision에 대한 종합적인 비용을 수치화한 값, 낮을수록 좋은 값)를 minimize하기 위해 차원을 250으로 줄이면 가장 좋은 결과를 얻을 수 있습니다. channel compensation을 사용하지 않을 때, 저자들은 DCF 값으로 0.021을 얻었습니다. 400에서 250으로 차원 축소를 진행하면 DCF 값이 0.011로 감소되는 효과를 얻을 수 있습니다. 하지만, LDA를 사용해 얻은 EER과 WCCN을 이용해 얻은 EER을 비교했을 때, 후자가 전자보다 더 좋은 결과를 보인다는 것을 알 수 있습니다. 그래서 저자들은 LDA를 이용해 nuisance direction을 주리고, 차원이 감소된 상태에서 WCCN을 사용해 새로운 cosine kernel을 정규화합니다. train동안, matrix T를 학습하기 위해 LDA projection matrix를 모든 데이터에 사용했고, within class covariance matrix를 계산하기 위해 같은 데이터를 축소된 space에 project했습니다. 위 그래프는 LDA에 의해 정의된 축소된 최적(DCF가 가장 낮은)의 차원의 수를 찾는 모습을 그린 모습입니다. 위 그래프는 NIST 2006 SRE dataset으로 진행한 결과를 보이는 것입니다.

가장 DCF 수치가 낮은 경우는, 차원을 200으로 축소하는 LDA와 WCCN을 결합한 형태로 English trial에는 0.010, all trials엔 0.016을 보입니다. 저자들은 실험을 통해, WCCN을 LDA projected space에 적용하는 것이 LDA만 적용했을 때보다 더 좋은 결과를 보인다는 것을 알아냈습니다. 만약 LDA와 WCCN을 사용한 경우를 JFA scoring만 사용하거나 WCCN 만 사용했을 때와 비교하면, english trials와 all trials에서 DCF가 가장 낮은 결과는 결합한 경우라는 것을 알 수 있습니다. 그리고 결합한 경우가 all trials에서 가장 좋은 EER을 보이는 것을 볼 수 있습니다.
 |
 |
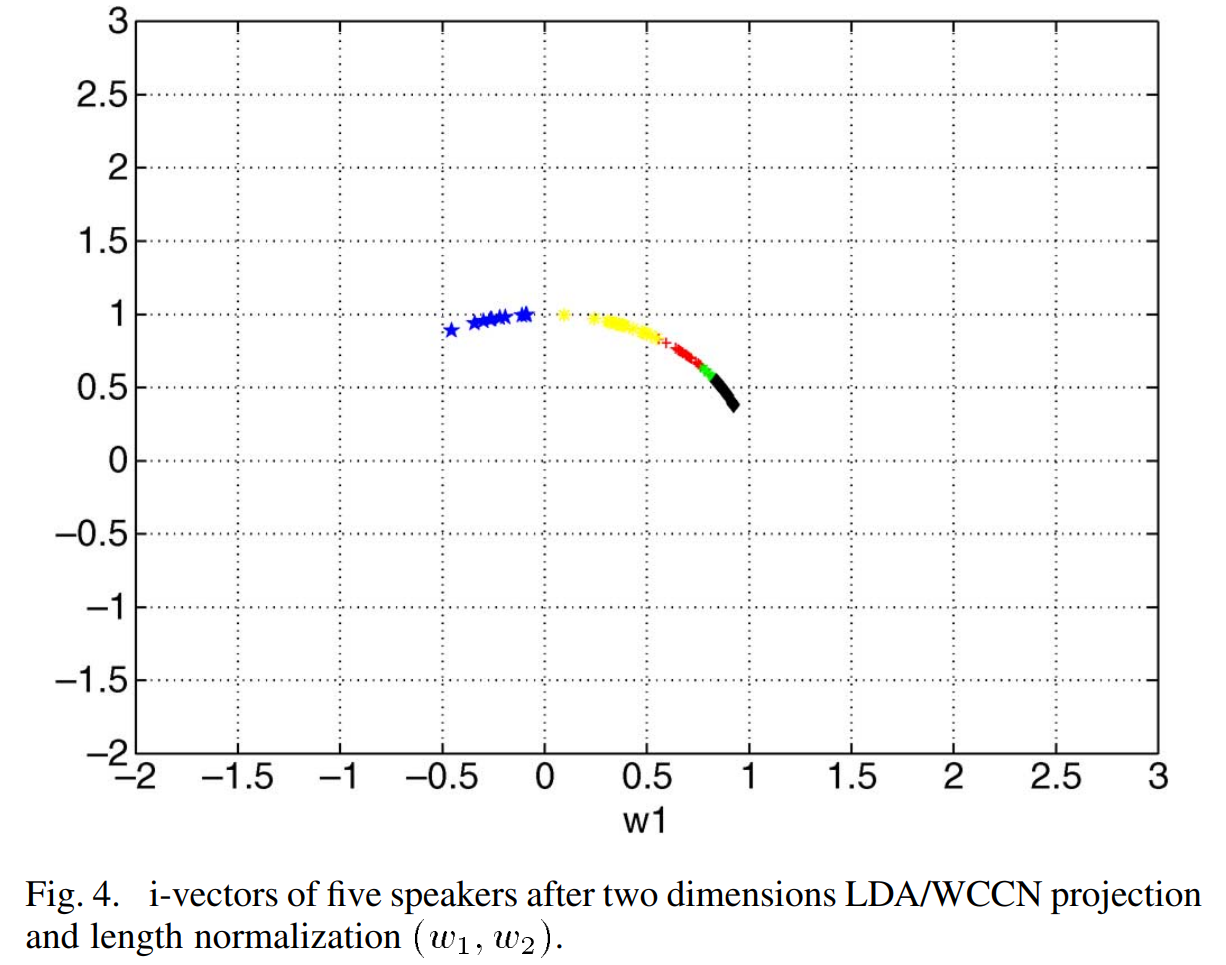 |
먼저 Fig 2는 다섯 여성 speaker의 i-vector를 2차원으로 LDA projection한 모습입니다. Fig 3은 LDA와 WCCN을 한 값을 보여주는 것이도 Fig 4는 length normalization도 적용한 모습입니다.
projection 2차원 space에서 WCCN을 하는 것은 intra-speaker variability를 minimize하여 channel effect를 줄이는 데 도움을 준다는 것을 알 수 있습니다. 그리고 Fig 4를 보면, cosine kernel을 이용해 length normalization을 한 결과인데, consine kernel을 적용하였기 때문에 각 i-vector가 더 구분하기 좋은 형태가 됩니다. 즉, 해당 결과는 cosine kernel이 speaker factor space에서도 좋은 결과를 보일 것이라는 근거가 됩니다.
Nuisance Attribute projection
저자들은 channel effect에 compensation을 제공하는 NAP 기술의 효과를 보여줍니다. 저자들은 몇개의 차원을 제거했는지를 나타내는 corank number를 다양하게 설정하여 NAP를 적용하여 얻는 결과를 보입니다.

위 결과는 NAP를 사용하여 channel effect를 compensation하는 것이 i-vector space에 SVM을 적용한 결과가 좋아지는 것을 보여줍니다. channel compensation을 적용하지 않았을 때 얻는 English trials MinDCF 0.021이 200개의 차원을 제거하는 NAP를 사용했을 때 English trials MinDCF 0.011로 줄어든 것을 볼 수 있습니다. LDA의 경우와 마찬가지로, WCCN이 NAP보다 더 좋은 결과를 주는 것을 볼 수 있습니다. 그래서 저자들은 NAP와 WCCN을 결합하기로 했습니다. train을 하기 위해, 모든 data를 사용하여 total variability matrix를 train하는 것과 동일한 방식으로 새로 projection된 space의 WCCN matrix를 훈련시켰습니다.

NAP(corank = 150)와 WCCN을 결합하였을 때, english trials에서 DCF는 0.010, all trials에서 DCF는 0.015로 좋은 결과를 얻었습니다. NAP와 WCCN을 결합한 결과도 역시 NAP만 사용했을 때보다 더 좋은 결과를 보입니다.

JFA scoring과 WCCN기반 SVM-FA, LDA와 WCCN의 조합, 그리고 NAP와 WCCN의 조합을 비교한 표입니다. LDA와 WCCN 결합이 English trials에서 가장 낮은 DCF 0.014보였으며, all trials에서도 EER 수치가 가장 뛰어난 모습을 보였습니다. 하지만, NAP와 WCCN 결합은 all trials에서 가장 좋은 DCF를 보였습니다.
Results for Both Genders

이번엔 total factor space에서 SVM을 적용함으로써 얻어지는 두 성별에 대한 결과를 보겠습니다. 이전 두 실험과 동일한 UBM을 사용하고 factor analysis configuration(400 total factors)을 사용합니다. 한 가지가 다른데, 두 성별의 total variability matrix T를 학습할 때 사용하는 data 양이 다릅니다. data를 추가하여 total variability가 더 넓은 범위를 capture하도록 하였습니다. channel effect compensate를 위해 LDA와 NAP를 WCCN과 함께 사용했습니다.
위 표를 보면, SVM-FA system의 경우, LDA + WCCN이 NAP + WCCN보다 더 좋은 결과를 보여줍니다. total variability factor space에 train data를 추가하는 것이 SVM-FA system의 성능 향상을 이끌었습니다. LDA + WCCN의 경우, NIST 2008 SRE English trial EER값은 3.95%(Table Ⅳ)에서 3.68%(Table Ⅷ)로 감소된 것을 볼 수 있습니다. 특히 남성 data의 경우 눈에 띄는 성능 향상을 얻을 수 있었습니다. 여성 data의 경우, EER 수치를 보았을 때 JFA가 3.17%로 더 나은 모습을 보이지만, all trial에선 LDA + WCCN이 더 좋은 수치를 보입니다. 결론적으로, total factor space에 SVM을 적용하는 것은 full JFA와 비교하였을 때, 주목할만한 결과를 얻을 수 있었습니다. 저자들이 제안한 SVM-FA modeling은 common factor가 없음에도 불구하고 주목할만한 결과를 보였습니다.
Cosine Distance Scoring
i-vector에 cosine kernel을 이용해 얻어지는 결과는 speaker 사이를 꽤나 선형적인 분리가 있다는 것을 보여줍니다. Cosine distance scoring은 total variability matrix와 i-vector를 기반으로 구해집니다. SVM-FA system과 동일한 t-norm model impostor을 기반으로 하는 zt-norm을 사용하여 점수를 정규화합니다. SVM을 학습할 때 사용되는 impostor는 z-norm 발화로 사용됩니다.
실험은 NIST 2008 SRE dataset으로 short2-short3, short2-10sec, 10sec-10sec condition에서 이루어집니다. 모든 condition에 대해 동일한 cosine distance scoring과 channel compensation을 사용했습니다.
1. Short2-Short3 condition

위 표를 보면 cosine distance scoring을 확인할 수 있습니다. i-vector기반 cosine distance scoring이 모든 condition에서 JFA scoring보다 더 좋은 결과를 제공해줍니다.

해당 그래프는 core condition인 Short2-Short3 condition에서의 Detcurve를 비교한 모습입니다. 여성에 대한 결과인데, X축은 거짓 수용률(False Alarm probability, 인증되지 않은 화자를 오인하여 수용하는 비율), Y축은 누락 확률(Miss probability, 실제 화자를 오인하여 거부하는 비율)를 의미합니다. cosine distance가 더 안정적인 성능을 보인다는 것을 알 수 있습니다.
2. Short2-10sec condition

위 표를 보면, cosine distance scoring이 full joint factor analysis configuration보다 더 좋은 성능을 보이는 것을 알 수 있습니다. 남성에 비해 여성의 결과가 좀 더 눈에 띄게 좋은 걸 알 수 있습니다.
3. 10sec-10sec

10sec-10sec conditionl이다 보니, 이전 조건들에 비해 좀 더 정확도가 떨어질 수 밖에 없습니다. 그래도 cosine dstance scoring이 훨씬 더 뛰어난 결과를 보이는 것을 알 수 있습니다. i-vector의 parameter가 더 적기 때문에 이와 같은 조건에서, 더 적은 speech frame으로 학습 가능하기에 성능이 향상되었다고 합니다.
Conclusion
저자들은 factor analysis가 speaker와 channel variability를 model하는 저차원 space에 정의되는 새로운 speaker verification system을 제안했습니다. 그리고 저자들은 new space에서 cosine kernel 기반 scoring method를 제안했습니다. SVM을 이용하는 방법과 cosine distance value를 decision score로 바로 사용하는 방법을 제시했습니다. 후자의 경우 더 적은 연산량으로 decision process를 수행합니다. 저자들이 제안한 modeling은, 간단한 factor analysis을 사용하여 각 recording을 i-vector(identity vector)라는 이름의 저차원 vector로 표현합니다. channel effect를 GMM supervector보다 저차원인 i-vector로 다룹니다.
저자들은 intersession problem을 위한 compensate를 적용하기 위해 LDA, NAP, WCCN을 실험했습니다. 저자들은 LDA와 WCCN의 결합이 가장 좋은 결과를 보인다는 것을 알아냈습니다. 여러 조건의 실험들을 통해 저자들이 제안한 방식의 우수성을 입증했습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Deep Neural Networks for Small Footprint Text-dependent Speaker Verification (0) | 2024.01.31 |
|---|---|
| GMM supervector, Eigenvoice vector, JFA, I-vector (0) | 2024.01.31 |
| 음성 인식 관련 용어 정리 (0) | 2024.01.28 |
| [논문] Auto-Encoding Variational Bayes (0) | 2024.01.19 |
| [논문] BrainNetGAN: Data augmentation of brainconnectivity using generative adversarialnetwork for dementia classification (0) | 2023.07.15 |



