Speaker-recognition task
speaker recognition은 speaker identification과 verification으로 이루어집니다. speaker identification은 known speaker 집단을 이용해 unknown speaker를 식별하는 것이 목표입니다. 다시말해, audio sample에서 unknown speaker의 음성과 가장 유사하게 들리는 화자를 찾는 것입니다. 주어진 sample의 화자들이 전부 known speaker set에 존재한다면, 이를 closed or in-set scenario라고 합니다. 반대로, 우리가 미리 정의해놓은 known speaker set 외부에서의 화자일 수 있다면, open-set scenario라고 하며, 따라서 world model이나 universal background model(UBM)이 필요합니다. 이러한 경우를 open-set speaker recognition(out-of-set speaker identification)이라고 합니다.
speaker verification의 경우, unknown speaker의 identity가 true인지 입증하는 것입니다. 이는 두 음성의 sample/utterance를 비교해서 같은 화자인지 결정하는 과정을 담고 있습니다. 몇몇 방법에서는, unknown sample을 claimed speaker model과 world model을 이용해 비교힙니다. 법의학 상황에선, 범죄를 의심받는 unknown spaeker를 식별하는 것이 주된 task이며, 상황에 따라 verification도 필요합니다.
화자의 신원 정보는 주로 음성이 어떻게 발화되는지에 내재되어 있습니다. 사람들은 같은 단어를 항상 동일한 방식으로 말하지 않습니다. 이를 style shifting 또는 intraspeaker variability라고 합니다. 또한, 다양한 녹음 장치와 전송 방법에 따라 더 변동성이 커지기도 합니다. 예를 들어, 전화기를 통해 말을 하거나 화자가 감기를 걸린 상황이거나, 속삭이거나 큰소리로 말할 때, 목소리를 인식하기 어려워집니다. 즉 화자 인식이라는 것이 쉽게 동작하진 않습니다.
Source of variability in speaker recognition

변동성을 고려했을 때, speaker recognition에서 mismatch에 영향을 줄 수 있는 요소들을 위에서 보여주고 있습니다. 3가지 class로 나눌 수 있습니다. 1) speaker based 2) conversation based 3) technology based.
speaker based variability sources: 화자의 발화하는 방식이 변화하는 것에 따라 speaker recognition의 성능이 변한다는 것을 의미합니다. 즉, 화자의 내재적이거나 화자 내부 변동성을 의미합니다.
- Situational task stress: 화자가 말을 하면서 어떤 작업을 수행하는 상태를 의미하며 예시로 운전이 있습니다.
- Vocal effort/style: 화자가 발화 방식을 변경하는 것을 의미하며, 속삭임 등의 예시가 있습니다.
- Emotion: 화자가 감정을 섞어 말하는 것을 의미하며, 화가나거나 슬플 때 발화 방식이 변화합니다.
- Physiological: 화자가 질병이 있거나 약물에 취해있거나, 노화되었을 때를 의미합니다.
- Disguise: 화자가 의도적으로 본인을 숨기거나 남을 모방하기 위해 발화 방식을 변경하는 것입니다.
Conversation-based/higer-level model/language of speaking variability sources: 다른 사람이나 시스템과의 음성 상호작용과 관련된 다양한 scenario를 의미합니다.
- human to human: 두명 이상의 화자들이 서로 상호작용하거나 한명의 화자가 연설하는 상황을 의미합니다. 이 경우 사용된 언어와 방언이 발화에 영향을 줍니다. 그리고 화자들이 서로 준비된 대본을 읽으며 말을 하는 것인지, 혹은 자연스러운 대화형식인지에 따라 발화 특성이 달라집니다. 또한, 대중들 앞에서 하는 연설의 경우 화자의 일반적인 발화 성의 변화가 생기기도 합니다.
- human to machine: 화자가 machine에게 발화하는 경우입니다. 이 경우, 음성 기반 시스템과 상호작용하며 화자의 일반적인 발화형식에 변화가 생기기도 합니다.
Technology or external-based variability sources: audio가 어디서, 어떻게 capture되었는지를 의미합니다.
- electromechanical: 전송 채널, 무선/유선 전화 및 확성기의 종류와 품질에 따라 화자 인식에 영향을 줄 수 있습니다.
- environmental: 배경 소음, 방음 특성, 원거리 마이크 위치와 환경이 음성 인식 시스템의 성능에 영향을 줄 수 있습니다.
- data quality: 녹음의 길이, sampling rate, 녹음 품질, 오디오 코덱/압축 방식 등이 영향을 줄 수 있습니다.
이러한 다양한 variation 원인들은 자동 algorithm을 사용하든, 인간의 청취/평가가 이루어지든, 화자를 정확하게 모델링하고 인식하는 데 가장 큰 문제가 됩니다. 화자 검증을 하기 위해선, 변동성이 동일한 화자에서 일어난 것인지 다른 화자들때문에 발생한 것인지 결정해야 합니다. 만약 음성의 내재적 변동성이 존재하여, 이를 정량화하고 자동 평가하도록 만드는 것은 매우 어렵습니다. 화자의 건강 상태와 녹음 환경에 따라 변동성이 존재하게 될 수 있지만, 대체적으로 화자의 스타일은 동일하게 유지되기 때문에 이를 분석할 수 있는 전문적인 지식이 필요합니다.
Challenges in speaker recognition
과거에는 전화기와 통신 채널의 변동성이 주된 관심사였습니다. 핸드폰이 전 세계 통신 시장을 지배하면서, 전화 scenario가 더 다양해졌습니다. 핸드폰을 이용해 스피커 모드로 통화하는 경우, 멀리서 화자가 발화를 하거나 움직이면서 통화를 하면 변동성이 생기게 되며, device로 인해 발생하는 variance의 경우가 늘어났습니다.
음성은 시간에 따라 변화하는 요소입니다. 오디오가 다른 시간에 녹음되었을 때, 화자의 내재적 변화가 존재했으며 이는 음성 인식 성능에 영향을 줍니다. Multisession Audio Research Project에서는, 36달동안 같은 위치에서 매달 동일한 장비를 이용하여 음성을 녹음하여 음성 인식 성능을 비교했습니다. 이때 측정 가능한 정도의 음성 인식 성능 차이가 발생했습니다. 즉 다양한 음성 인식의 성능에 영향을 줄 수 있는 variance들이 존재하며 이를 해결하는 연구들이 진행중에 있습니다.
Speaker characterization: feature parameters
법의학 화자 식별의 경우, 범죄자와 용의자로부터 충분한 음성 자료를 얻어냅니다. 체게적인 분석을 수행하여 음성 데이터에서 화자의 특이적 특성, 즉 feature parameter를 추출하고 sample간 비교를 합니다. 자동 화자 인식 시스템은, 화자를 구별하기 위해 설계된 feature가 먼저 추출되고 수학적으로 모델링되어 비교를 수행합니다. 그럼 어떤 특성이 사람을 식별하는 데 도움을 주는지 보겠습니다(평가를 수행하는 데 고려해야 할 feature parameter가 무엇인지).
모든 화자의 목소리에는 고유한 특징이 있습니다. 개별 화자의 특징을 구별하는 것은 쉽지 않지만, 주로 화자의 성대관 생리학과 발음의 습득된 습관으로 인해 고유합니다. 심지어 일란성 쌍둥이도 그들의 목소리에 차이가 있으며, 연구에 따르면 그들은 유사한 성대관 형태와 음향 특성을 가지고 있지만, 인간이 지각하기는 어렵다고 합니다.
그래서 feature parameter로는 측정 가능하고 의미있는 비교를 수행할 수 있어야 하며, 다양한 feature parameter를 사용하는 것이 좋습니다. ' F. Nolan, The Phonetic Bases of Speaker Recognition. Cambridge, U.K.: Cambridge Univ. Press, 1983 '에서 제시한 이상적인 feature parameter를 보겠습니다.
1) 높은 화자 간 변동성과 낮은 화자 내 변동성
2) 의도적인 위장이나 모방에 대한 저항성
3) 관련 자료에서 높은 빈도로 등장
4) 전송 과정에 따른 변동성 x
5) 추출하고 측정하기에 용이해야 함
이와 같이 5가지 특성을 지니면, 이상적인 feature parameter라 할 수 있겠습니다. feature에 대한 변동성은 항상 존재하겠지만, 중요한 것은 변동성의 원인이 동일한 화자인지(화자의 기분이나 상태에 따른 변화가 예시) 다른 화자이기 때문에(다른 화자이기에 생긴 변동) 생성된 것인지 결정하는 것입니다. 대표적인 feature parameter는 대략적으로 청각적 versus 음향적, 언어적 versus 비언어적, 단기 versus 장기 feature로 분류될 수 있습니다.
Auditory versus Acoustic feature
auditory feature는 '들을 수 있고 훈련된 청취자에 의해 객관적으로 기술될 수 있는 음성의 측면'으로 정의됩니다. 이러한 feature에는 개별 음성 소리의 특정한 발음 방식이 포함될 수 있습니다. 반대로 acoustic feature는 음성 신호에서 자동 알고리즘을 사용하여 파생된 수학적으로 정의된 parameter를 의미합니다. 이러한 feature는 auto system에서 사용됩니다. 예를 들어 음성 신호의 기본 주파수 및 forment 주파수 대역폭이 acoustic feature입니다.
Linguistic versus Nonliguistic feature
linguistic feature parameter는 '주어진 언어의 내부적 구조나 언어 또는 방언 간에서의 대비'를 의미합니다. 음운론적, 형태론적, 구문론적으로 더 세분화하여 표현될 수 있습니다. 예를 들어 'car'이라는 단어를 발음할 때, 'r' 소리를 내는 방식이 있고 내지 않는 방식의 방언이 존재합니다. nonlinguistic feature는 음성 내용과 관련이 없는 측면을 나타냅니다. 예를 들어 숨을 헐떡이거나, 유창성, 음성 중단(빈도와 유형), 말하기 속도, 평균 기본 주파수, 비음성 소리(기침, 웃음 등)가 포함될 수 있습니다.
Automatic Speaker Recognition

auto speaker recognition은 최소한의 인간 개입으로 독립적으로 작동하도록 설계된 컴퓨터 프로그램이 화자의 목소리를 식별합니다. 위 그림은 기초적인 auto speaker recognition의 block diagram입니다. 미리 정의된 feature parameter들이 audio recording에서 추출됩니다. 해당 feature는 음성의 특이적 feature를 포착할 수 있습니다. 해당 모델은 test 음성과 기존에 등록된 음성의 화자가 동일한지를 나타내는 점수를 제공합니다. 이 점수가 미리 정의된 임계값보다 높으면, 동일한 화자로 분류합니다. 화자를 등록할 때, 단기 음성과 긴 지속 시간의 음성 또는 전체 발화에서 feature를 추출하여 등록됩니다.
Feature Parameters In Automatic Speaker Recognition Systems

Voice Activity Detection(VAD)는 위 그림에서 (a)에 해당됩니다. VAD는 time domain에서 진폭값을 나타냅니다. 진폭이 크다면 음성이 존재한다는 것을 의미하고, 0이면 음성이 존재하지 않는 상태라는 것을 의미합니다. 최근에는 combo-speech Activity Detection(SAD)와 같은 새로운 기술들이 등장하고 있습니다.
Short-term Features
20~25 milliseconds 길이의 짧은 음성 frame에서 추출된 feature를 의미합니다. 가장 유명한 것으로 Mel-frequency cepstral coefficients(MFCCs)와 Linear Predictive Coding(LPC)가 있습니다.

위 내욘은 MFCCs를 얻는 과정을 보여줍니다. MFCCs를 얻기 위해선, 먼저 audio sample을 짧은 중첩 frame으로 나눕니다. 해당 frame에서 얻은 신호는 window function에 의해 곱해집니다. 각 window에 맞춰 fourier transform을 진행합니다. fast fourier transform을 진행하면, 해당 신호를 이루고 있는 다양한 주기 함수들이 등장합니다. 각 함수들의 frequency는 다르고, fourier transform을 진행하고 나면 time domain에서 fequency domain으로 변환됩니다. 그리고 log를 적용하면 spectrum을 얻게 됩니다. spectrum은 결국 frequency domain으로 amplitude를 표현하다보니, 음성의 시간적 특성을 잃어버리게 되었습니다. 그래서 각 window에 맞는 spectrum을 이어 붙이면 시간 특성도 띄는 spectrogram을 얻을 수 있게 됩니다. 인간의 청각 성질을 고려한 mel-spectrogram을 만들기 위해서, mel filterbank를 사용합니다. 일반적으로 24channel의 filterbank를 사용하는데 위 (c)와 같은 형태입니다. 인간은 저주파 소리에 더 민감하게 반응하기 때문에 그림과 같이 저주파에 더 dense하게 filter가 형성되어 있는 것을 볼 수 있습니다. 이렇게 생성된 mel spectrogram을 통해 MFCC를 얻어낼 수 있습니다. 소리 신호는 formant와 배음이라는 feature를 가지고 있습니다. 배음의 경우, 악기나 성대의 구조에 따라 달라지며, 배음 구조의 차이가 음색의 차이를 만들어줍니다. formant는 악기나 목소리에 특유의 음색을 주는 특정 주파수대를 의미합니다. spectrum의 spectral envelope의 극점이 formant에 해당합니다. formant는 배음과 만나 소리를 풍성하게 혹은 선명하게 만드는 필터 역할을 합니다. 배음 구조는 주로 음악이나 주파수에 대한 일반적인 특성을 파악하는 데에 사용되고, formant는 주로 음성과 같은 발음에 관련된 특성을 파악하는 데에 사용됩니다. formant를 얻기 위해, spectrum과 formant를 연결한 곡선을 분리해내야하는데 이때 도출되는 값이 MFCC입니다.

위 그림과 같은 순서로 MFCC를 구할 수 있습니다. MFCC를 구하는 cepstral analysis과정에서, IFFT대신 DCT(Discrete Cosine Transform)을 주로 사용합니다. mel spectrum의 경우 frequency 간의 상관관계가 존재하는데, cepstrum에서 몇 개의 계수(보통 상위 12개)만 선택하여 사용하는 MFCC는 frequency간의 상관관계가 존재하지 않게 됩니다. MFCC는 일반적으로, 여러 frame의 음성에 걸쳐 계산된 속도 및 가속도 매개변수가 추가됩니다. 이 매개변수들은 단기 특징 계수의 동적 특성을 나타냅니다. Mel-spectrogram은 domain이 한정적인 문제에서 좋은 성능을 보이고, MFCC의 경우에는 일반적인 상황에서 더 좋은 성능을 보인다고 합니다.
Speaker Modeling
audio segment를 feature parameter로 변환하고 이를 speaker-recognition model의 input으로 사용합니다. 일반적으로, modeling은 주어진 화자에 대한 feature 속성을 분석하는 과정이라고 정의할 수 있습니다. 최근 대규모 신경망 모델들은 MFCC보단 mel spectrum에 filter bank를 적용한 값을 그대로 사용할 때 더 좋은 성능을 보입니다. 이제 model들에 대해 보겠습니다.
Gaussian-Mixture-Model Based Method
Gaussian mixture model(GMM)은 다변량 data를 modeling하는데 사용되는 gaussian probability density function의 결합입니다. GMM은 unsupervised 방식으로 data를 clustering하지만 data의 PDF를 제공합니다. speaker의 특징을 모델링하기 위해 GMM을 사용하면 speaker의 의존적인 PDF가 생성됩니다. test 발화에서 얻은 특징과 같이 다른 datapoint의 PDF를 평가하면 speaker의 GMM과 unknown speaker's data의 유사도를 계산할 때 사용할 수 있는 확률 점수를 제공합니다. 간단한 speaker identification task는 각 speaker에 대한 GMM을 생성합니다. 그 다음 test용 발화는 존재하는 각 GMM과 비교하여 가장 높은 점수를 갖는 GMM의 speaker를 선택합니다.
text에 독립적인(어떤 speech 내용인지에 대한 사전 지식이 없는 상태) speaker recognition task에서 short-term feature를 modeling하기 위해 GMM을 사용하는 것이 음향 모델링에 대해 가장 효과적이라고 합니다. short-term spectral feature은 시간적인 특성에 의해 영향을 받기 보단 화자에 더 의존적이기 때문이라고 합니다. GMM이 등장하기 전엔, speaker recognition task에 사용되는 vector quantization(VQ) 방식이 있었습니다. VQ는 PDF 대신 prototype vector set(각 subgroup을 대표하는 vector들의 집합)을 사용해 speaker를 modeling합니다. GMM은 VQ에 비해 더 좋은 speaker model이라고 여겨지는데, GMM은 변동성을 허용하는 확률적 특성을 갖기 때문입니다. 그러므로, test 발화가 다른 acoustic condition이라도, GMM은 VQ model에 비해 더 data에 잘 연관될 수 있습니다.
GMM은 여러 개의 평균 vector, 공분산 matrix 및 각 혼합 구성에 대한 weight로 매개변수화된 gaussian PDF의 혼합입니다. model은 각 PDF의 weighted sum으로 나타내어 집니다. 만약 random vector x_n이 평균 μ_g, 공분산 Σ_g인(여기서 g는 1부터 M까지이며 component의 index를 의미합니다) M개의 gaussian 구성요소로 modeling된다고 하겠습니다. 이 경우 x_n의 PDF는

위 식과 같이 나타낼 수 있습니다. 여기서 π_g는 g번째 혼합 구성의 weight를 의미합니다. GMM model λ = {π_g, μ_g, Σ_g | g = 1, ... ,M} 로 표현할 수 있습니다. GMM model에 의해생성된 feature vector의 likelihood는 위 식을 통해 구할 수 있습니다. acoustic feature vector는 일반적으로 독립입니다. feature vector가 X = {x_n | n∈1...T}일 때, GMM model에 각 feature들이 주어질 확률은

위와 같이 구할 수 있습니다. feature의 순서는 likelihood를 구할 때 상관없기 때문에 text-dependent speaker recognition의 계산을 단순화할 수 있습니다. GMM은 EM algorithm을 통해 학습됩니다.
Adatped GMMs: The GMM-UBM
GMM은 speaker identification task에서 효과적이였습니다. speaker verification에선, 주장된 화자 모델 외에도 대체 화자 모델(target이 아닌 다른 화자들을 대표하는)이 필요합니다. speaker identification의 경우, 음성을 듣고 그 음성이 누구의 것인지 식별하는 과정을 나타냅니다. speaker verification의 경우, 음성을 듣고 특정 화자의 것이 맞는지 확인하는 과정입니다. 이를 통해, 두 model이 test data로 비교될 수 있고, 더 가까운 model이 선택될 것이고 이를 통해 accept되거나 reject 될 것입니다. 대안 speaker model은 background나 world model로 알려져있으며, target speaker를 제외한 모든 화자가 존재하는 UBM을 사용한다는 아이디어가 등장했습니다. UBM은 모든 화자의 화자 독립적 음성 feature distribution을 나타내도록 훈련된 대규모 GMM입니다.

위 그림을 보면 GMM-UBM의 구조를 알 수 있습니다. UBM은 모든 등록된 speaker의 대안 모델로서 작동하는 universal model입니다. 몇몇 방식들은 speaker에 의존적인 특이한 background model을 제공하는 것을 고려하기도 했습니다(즉 각 화자에 맞는 model을 구현하는 방식). 그러나, single background model을 사용하는 것이 가장 효과적이고 의미있는 전략이라는 것이 밝혀졌습니다. UBM에 input 음성을 넣고 feature를 추출하고, 주장되는 화자 model에 음성을 넣어 feature를 추출합니다. 두 feature vector를 가지고 비교합니다. UBM의 점수를 기준으로, UBM보다 주장된 화자 model의 score가 높다면 그 화자는 test 음성의 화자라고 보는 방식입니다. 그 후에, 어떤 연구에서는 UBM을 enrollment speaker GMM의 초기 모델로 사용되었습니다. 즉 UBM을 이용해 특정 화자를 위한 GMM을 생성하는 데 사용했다는 뜻입니다. 이러한 접근법은 GMM-UBM method라고 불리는데, UBM에 Beysian adaptation을 사용하여 speaker의 GMM을 구합니다. 등록 화자에 대한 GMM을 maximize likelihood training하는 것과 달리, 이 모델은 잘 훈련된 UBM parameter를 update하여 얻어집니다(이게 Beysian adaptation). speaker model과 background model의 관계는 독립적으로 훈련된 GMM보다 더 나은 성능을 제공하고, 이후에 등장하는 speaker model adaptation 기술의 기초가 됩니다. 이제 공식을 통해 이러한 접근법을 살펴보겠습니다.
The LR Test
observation O, hypothesized speaker s가 주어졌을 때, speaker verification은 두 가설(H_0: O의 speaker는 s. H_1: O의 speaker는 s가 아니다)에 대한 가설 검정으로 볼 수 있습니다. GMM-UBM 접근법에서, 가설 H_0은 speaker dependent GMM λ_s , H_1은 UBM λ_0로 표현될 수 있습니다. 그러므로, 구해진 feature vector X를 이용해 LR test를 진행하면 됩니다.

위 식에서 τ는 결정 treshold입니다. 주로 LR test는 log scale로 진행되고, log-LR은

위와 같은 식이 됩니다.
Maximum A Posteriori Adaptation of UBM
X = {x_n | n ∈ 1 ... T}을 erollment speaker s로부터 얻어진 acoutstic feature vector set이라고 하겠습니다. UBM과 X가 주어졌을 때, UBM component에 관한 feature vector의 확률을 계산하면
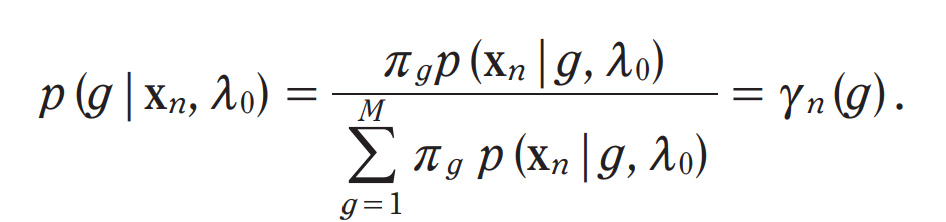
이와 같은 식으로 나타낼 수 있습니다. π_g는 g번째 component의 parameter를 의미합니다. Υ_n(g)는 가중치, 평균, 공분산 parameter을 구할 때 사용됩니다.

위 식은 제로차, 일차, 이차 baum-welch 통계량을 의미합니다. 먼저 제로차 통계량은, 특정 state에 대한 총 시간(또는 빈도)를 나타냅니다. 특정 state이 얼마나 자주 발생하는지를 나타내며, HMM(Hidden Markov Model)의 상태 전이 확률을 계산하는 데 사용됩니다. 일차 통계량은 특정 state에서 관측될 수 있는 feature vector의 weighted sum을 나타냅니다. 이차 통계량은 관측치의 제곱합을 나타내며, 이를 통해 분산이나 공분산을 추정할 수 있습니다. 이러한 parameter를 사용하여, data vector X가 주어졌을 때 feature들의 posterior 평균과 공분산 matrix를 구하면 아래와 같습니다.

위 식과 같이 구할 수 있게 됩니다.

MAP update는 위 식을 통해 진행됩니다. weight는 (3), 평균은 (4), 공분산은 (5)입니다. 식 (3)의 scaling factor β는 모든 adapted mixture weights가 합쳐져 단위 합을 이루도록 계산됩니다. 그러므로, 새로운 GMM parameter는 UBM parameter와 관측된 데이터로부터 얻은 통계량의 가중합으로 이루어집니다.

변수 α_g는 위와 같은 식을 통해 구할 수 있습니다. 여기서 r은 relevance factor입니다. 해당 parameter는 adapted GMM parameter가 관측된 speaker data에 의해 어떻게 영향을 받을 것인지를 조절합니다. 이 relevance factor는 평균 vector에만 적용하는 것이 가장 효과적이라고 합니다. 즉, 새로운 평균 μ_g = α_gμ_g + (1 - α_g)μ_g 로 표현됩니다. 여기서 α_g가 곱해진 평균은 UBM을 통해 구한 기존 평균 vector이며, 1 - α_g가 곱해진 평균은 관찰된 데이터로부터 직접 계산된 평균 벡터입니다.
The GMM Supervectors
speaker recognition의 한가지 문제는 train data와 test data의 길이가 다를 수 있다는 점입니다. 즉 서로 다른 길이의 두 발화를 비교해야 한다는 것입니다. 그러므로, 효과적인 speaker recognition을 위해선, 한 발화에 대해서 고정된 차원의 표현을 얻어야 합니다. 그래야 다양한 machine learning classifier를 발화 수준 feature에 사용할 수 있습니다. 길이가 서로 다른 발화들에서 고정된 차원의 vector를 얻는 효과적인 방법중 하나로 GMM supervector가 있습니다. 이는 GMM model의 parameter를 concate하여 얻은 큰 크기의 vector입니다. 일반적으로 GMM supervector는 MAP adpated speaker model의 GMM mean vector를 concate하여 얻습니다.
supervector라는 단어는 speech recognition application에서 eigen-voice speaker adaptation을 위해 처음 사용되었습니다. 연구자들은 큰 차원의 vector이 channel compensation method을 설계할 때 매우 효과적이라는 것을 알아냈습니다. 그래서 supervector space에서 동작하는 효과적인 modeling 기술들이 등장했습니다. 이러한 연구들이 진행되며 두 가지 지배적인 추세가 등장했는데, factor analysis(FA)와 support vector machines(SVM)입니다.
GMM Supervector SVMs
SVM은 유명한 machine learning 기반 supervised binary classifier입니다. GMM supervector는 SVM을 이용한 speaker recognition/verification에 효과적으로 사용될 수 있다고 합니다. training 발화로부터 얻어진 supervector는 positive example로 사용되고, impostor(가짜) 발화의 supervector negative example로 사용됩니다. Nuisance Attribute Projection(NAP)와 Within-Class Covariance Normalization(WCCN)과 같이 channel compenstation 전략들도 개발되었습니다. short and long term feature를 사용하는 speaker recognition SVM 모델들도 등장했습니다. 그래도 GMM supervectors with SVM and NAP 가 가장 효과적인 접근 방법이라고 알려져있습니다.
SVM(Support Vector Machines)
SVM classifier는 hyperplane을 이용하는 두 class로부터 얻어지는 고차원의 data point를 분류하는 것이 목표입니다. SVM은 hyperplane의 위치를 기반으로 unknown observation의 class를 예측하는데 사용될 수 있습니다. 최적화된 linear separator H는 class 간 최대 margin(즉, 다른 클래스의 훈련 데이터 projecion의 거리가 최대인)을 제공합니다. 간단한 2차원데이터의 경우, SVM은 아래와 같이 동작합니다.

train data가 선형적으로 분리되지 않는 경우, class가 선형적으로 분리가 되는 고차원의 space로 feature들은 mapping됩니다. 이때 kernel function을 사용합니다.
FA of the GMM Supervectors
Factor analysis는 적은 수의 관측하지 못하는/숨겨진 변수를 이용해 관측가능한 고차원 data vector의 변동성을 설명하는 것이 목표입니다. speaker recognition을 위해, GMM supervector space에서 화자 및 채널 dependent variability를 설명하기 위해 FA를 도입하는 연구가 등장했습니다. 최근엔 i-vector 접근법이 등장하게 되었습니다.
Linear Distortion Model
일단 speaker dependent GMM supervector m_s에 대해 살펴보겠습니다. m_s는 일반적으로 4개의 구성요소로 이루어진 linear combination이라고 가정됩니다.
1. speaker/channel/environment independent component m_0
2. speaker dependent component m_spk
3. channel/environment dependent component m_chn
4. residual m_res
이와 같이 4개의 요소로 이루어져 있다고 가정합니다. 보통 1번은 UBM에서 얻어지며, 상수입니다. 나머지는 random vector이고 다양한 현상으로 인한 supervector의 variability를 담당합니다. speaker s와 h로부터 얻어진 GMM supervector는 4개 요소의 합으로 표현됩니다.
d차원 acoustic feature이고 M개의 혼합 구성 요소를 가진 UBM을 사용하는 경우, GMM supervector의 차원은 Md x 1입니다. 예를 들어, speaker와 channel에 독립적인 supervector m_0는 UBM의 평균 vector들의 concat 결과입니다. m_0의 g번째 혼합에 대한 subvector를 m_0[g]라고 표현하며 이는 μ_g입니다.

위 table은 model들을 식으로 나타낸 모습입니다.
Classical MAP Adaptation

MAP adaptation을 위해 사용하는 mean vector를 update하는 공식을 다시 살펴보겠습니다. 위 식은 speaker dependent한 component와 speaker independent한 component의 선형 결합인 형태입니다. 좀 더 일반적인 상태로 표현하자면, MAP adpatation은 GMM mean supervector에 대한 연산으로 표현될 수 있습니다. m_s = m_0 + Dz_s 형태로 표현가능하며, D는 Md x Md의 대각 행렬이며, z_s는 Md x 1인 standard normal random vector입니다. 여기서 Dz_s는 m_spk이며, D^2 = Σ/r인 경우, MAP adaptation equation은 m_s = m_0 + Dz_s 형태로 표현할 수 있게 됩니다(여기서 r은 relevance factor입니다).
Eigenvoice Adaptation
speaker recognition에 사용되는 FA-related model은 eigenvoice method입니다. eigenvoice method는 speech recognition에서 speaker adaptation을 위해 처음 등장했습니다. 해당 method는 speaker model parameter가 저차원 subspace( eigenvoice matrix의 열에 의해 정의된 저차원 subpace)에 존재하도록 제한을 둡니다. 이 model은 speaker dependent GMM mean supervector m_s를 m_0 + Vy_s로 표현합니다. m_0는 UBM에서 얻어진 speaker independent supervector이고, matrix V의 열은 speaker subspace을 구성하고, y_s는 speaker factor라고 알려진 standard normal hidden variable입니다. 여기선 m_spk=Vy_s가 됩니다. 이 model은 probabilistic PCA(PPCA) 또는 FA처럼 residual noise가 없다는 것에 주목해야 합니다. 이는 eigenvoice model이 본질적으로 PCA와 동일하다는 것을 의미합니다. model의 공분산은 W^T입니다. supervector가 고차원이기 때문에 full rank sample covariance matrix(supercovariance matrix)는 제한된 양의 data로 구하는 것은 어렵습니다. 그러므로 EM algorithm을 이용해 eigenvoice를 얻습니다. speaker factor는 enrollment speaker에 대해 추정되어야 합니다. adaptation된 supervector를 이용해 likelihood를 구합니다. 이 model은 GMM supervector parameter의 adaptation이 eigenvoice matrix에 의해 제한된다는 것을 시사합니다. 이 model의 이점은 적은 양의 data로 adaptation할 수 있는 경우, adapted model은 더 강건하다는 점입니다. speaker dependent subspace에 존재하도록 제한되어 있기 때문에, nuisance directions에 의한 영향을 덜 받는다고 합니다. 그러나 eigenvoice model은 cahnnel이나 intraspeaker variability를 modeling할 수 없다는 단점도 존재합니다.
Eigenchannel Adaptation
UBM을 speaker model에 adapting하는 것과 유사하게, speaker model은 channel model에 adpating될 수 있습니다. unseen channel distortion이 test중에 존재할 때 유용할 수 있으며, enrollment speaker model이 channel에 adapting될 수 있습니다. eigenvoice model과 유사하게, channel variability는 channel 공분산 matrix의 주요 eigenvector로 span된 subspace에 위치한다고 가정할 수 있습니다.
The i-Vector Approach
GMM supervector에 대한 SVM 분류기는 강건한 speaker recognition에 매우 성공적입니다. FA based method(JFA technique) 역시 좋은 성과를 보였습니다. 그래서 두 방식의 강점을 결합하기 위해, JFA를 feature extractor로 사용하는 SVM에 관한 연구들이 등장했습니다. 초기엔, JFA를 사용하여 추정된 speaker factors는 SVM classifier에 사용되는 feature로 사용되었습니다. channel factor 또한 speaker dependent information에 포함된다는 사실이 관측되어, speaker와 channel factor는 total variability space라고 불리는 single space로 결합되었습니다. 이 FA model에서, speaker와 session dependent GMM supervector는

이와 같은 형태로 표현합니다. hidden variable w_s,h는 N(0,I)에서 sampling된 값이고 이는 total factor라고 불립니다. FA method와 유사하게, hidden variable은 관측하지 못하지만, posterior expectation을 통해 추정할 수 있습니다. classifier의 다음 단계에 feature로 사용될 수 있는 total factor의 추정치는 i-vector로 알려져 있습니다. i-vector라는 용어는 speaker identification application에 대한 'identity vector의 줄암말이며, supervector와 acoustic feature vector 사이의 중간 차원을 가리키는 'intermediate vector'를 나타내는 것으로도 사용됩니다.
JFA 또는 다른 FA method와 다르게, i-vector 접근법은 speaker와 channel을 구분하지 않습니다. GMM supervector의 차원 축소 방식입니다. 즉 GMM supervector에 PCA model을 적용한 것과 유사합니다. T matrix는 eigenvoice model에 적용된 알고리즘과 동일한 방식으로 학습되며, 각 발화가 다른 speaker로부터 얻어진 것으로 가정하고 진행됩니다.
i-vector 방식은 어떠한 보상 작업을 수행하지 않습니다. GMM supervector의 의미있는 lower dimensional을 표현할 뿐입니다. 그래서 supervector의 대부분의 장점을 가지고 있습니다. 그리고 저차원이기 때문에, 고차원의 supervector에서는 효과적으로 동작하지 못했던 보상 전략들이 speaker recognition에서 잘 동작하게 되었습니다.



