https://arxiv.org/pdf/2103.08494.pdf
해당 논문을 보고 작성했습니다.
Abstract
알츠하이머 병은 가장 흔한 나이와 관련된 치매 중 하나이며, 개인의 삶과 사회적에 큰 영향을 줍니다. 정확한 관리를 위해 개인의 치매 위험성을 측정하는 것은 문제로 남아있습니다. Brain MRI는 뇌 노화정도를 탐지하여 제공합니다. 딥 러닝 모델 기반으로 Diffusion MRI로 생성된 구조적 brain network를 이용해 치매를 정확하게 분류할 수 있습니다. 그러나 diffusion MRI의 제한된 이용 가능성은 딥 러닝 모델을 학습하는데 문제가 됩니다. 저자들은 변형된 GAN인 BrainNetGAN을 제안하는데, 이는 치매를 진단하기 위해 구조적 brain network를 효과적으로 증강합니다. BrainNetGAN은 가짜 brain connectivity matrics를 만들어내고 이는 잠재 분포를 반영하고 진짜 brain network data의 feature를 반영할 것입니다. BrainNetGAN은 AD 분류에 있어 뛰어난 성능을 보입니다.
Introduction
diffusion MRI(dMRI)로 측정된 구조적 brain network는 복잡한 뇌 백질 구조를 수량화하고 뇌 해부학적 사전 지식을 통합하는 기술입니다. 구체적으로, dMRI에서 수행되는 tractography는 brain atlas에서 정의된 해부학적으로 분리된 뇌 영역의 연결 강도를 수량화할 수 있습니다. 다양한 연구에서 구조적 brain network가 AD를 포함한 신경학적 질환을 특징짓는 데 유용하다는 것을 보이고 있습니다.
동시에, 구조적 network를 기반으로 한 machine learning 접근법이 AD 환자를 정상 대조군으로부터 분류하는 데 유망하다는 것을 보이고 있었습니다. 딥 러닝 모델들이 좋은 성능을 보이기도 합니다. 하지만 딥 러닝 모델은 많은 양의 train data를 필요로 하며, data는 class 별로 균형 잡힌 수만큼 존재해야 좋은 성능을 보입니다. 하지만 이는 임상 실무에서 실현시키기에 비현실적입니다.
이러한 문제들을 해결하기 위해 최근 연구들은 train dataset을 늘리기 위해 데이터 증강 기술을 사용하고 있습니다. 일반적으로 이미지를 증강시킬 때, 돌리거나 뒤집거나 합니다. 하지만, 뇌 구조를 단순히 뒤집거나 돌리면, 뇌 영역의 순서가 완전히 변하기 때문에 뇌 구조에 맞는 접근법이 필요합니다.
BrainNetGAN
저자들은 conditional 한 brain network를 합성하기 위해 사용되는 변형된 GAN을 제시합니다. 데이터 증강은 brain network를 input으로 사용하는 치매 분류기의 성능을 향상할 수 있습니다. 저자들이 제시한 BrainNetGAN은 치매와 정상인의 brain network를 생성할 수 있습니다.
2D convolution kernel을 사용해 brain network의 위상적 특성을 학습합니다. gradient panelty가 있는 Wasserstein GAN을 사용해 빠르고 안정적으로 학습되는 GAN을 만듭니다. GNN을 이용해 효과적으로 brain network의 위상적 특성을 학습하는 능력을 평가합니다.

Method
Structural brain networks
brain network의 인접행렬은 Figure 1의 A와 같은 순서로 생성됩니다. 먼저, dMRI는 FSL을 이용해 전처리됩니다. Diffusion Toolkit으로 전처리된 dMRI는 Tractography가 수행됩니다. dMRI의 회색 영역은 Advanced Normalization Tools를 이용해 표준 영역에 비선형성을 적용한 후 Automated Anatomical Labelling atlas를 이용해 90개의 뇌 영역으로 나눠집니다. 구조적 brain network는 각 뇌 영역의 쌍 간의 tracts 수를 계산하여 인접행렬을 생성하여 model의 input으로 사용되었습니다. tract 수는 0과 1 사이로 정규화됩니다.
Loss
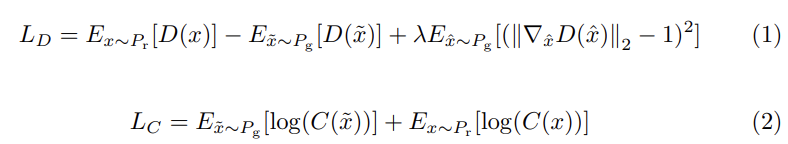
식 (1)은 gradient penalty가 있는 wasserstein loss입니다. 처음 두 항은 real과 fake의 분포에 대한 Earth-Mover distance W(P_r, P_g)를 의미합니다. generator는 이 거리를 줄이도록 학습됩니다. P_r은 real sample의 분포를 나타내고, D는 discriminator를 나타냅니다. D(x)는 input으로 x가 주어졌을 때 output을 의미합니다. P_g는 G(z|c)의 분포를 의미합니다. G(z|c)는 label c인 gaussian noise z를 이용해 생성한 결과를 의미합니다. 세 번째 항은 gradient penalty를 의미합니다. random sample의 gradient norm을 적용해 1-Lipscitz continuity를 강화하는 방식입니다.
두 번째 식은 classifier C의 loss를 의미하며 generator G와 classifier C 모두 correct class 수를 늘리도록 학습됩니다.
Data augmentation using BrainNetGAN

BrainNetGAN은 generator G, discriminator D, classifier C로 이루어집니다. G는 DNN을 사용한 4개의 hidden layer로 이루어집니다. G는 Gaussian 분포를 따르는 random vector z와 brain network에 대해 one-hot 코딩을 적용한 class label c를 input으로 받습니다. G의 output은 1 x 4005 vector이고 이는 대각행렬은 0인 90 x 90의 brain network 행렬로 reshape 됩니다.
D와 C는 3개의 특정 kernel을 가진 convolutional layer 3개와 5개의 fully connected layer로 이루어집니다. 행렬의 특정 값의 지역 이웃들에만 영향을 받는 일반적인 convolutional kernel과 다르게 채택된 kernel은 convolution 연산에 특정 값의 행과 열을 사용하고, edge-edge와 edge-node convolution을 사용합니다. D와 C의 input은 90 x 90 행렬이고, 이는 합성되었거나 진짜 brain network 행렬입니다. 비록 D와 C의 구조는 동일하지만, loss function은 다릅니다. C는 이진 분류를 수행하기 위해 cross entropy loss를 사용했으며, D는 real과 fake 사이의 차이를 평가하기 위해 wasserstein loss를 적용했습니다.
pytorch-geometric을 사용하여 graph convolution으로 구현된 GNN classifier를 AD/CN 분류기로 사용했습니다. 이 분류기는 생성한 데이터가 AD와 CN 사이의 위상적 차이를 잘 포착하는지 평가합니다. GNN은 GraphConv라고 불리는 graph convolutional layer와 graph를 embed 하는 fully connected layer로 이루어져 있습니다. 먼저 multiple method로 생성된 fake data만 분류기의 input으로 넣어서 학습하는 실험을 했습니다. 그다음 분류기에 train data와 생성한 데이터를 섞어 input으로 넣어 학습하는 실험을 했습니다.
Conclusion
저자들이 제시한 BrainNetGAN은 치매 분류를 위한 brain network 행렬 데이터를 증강합니다. 다른 방법들보다 수치적으로 우수한 성능을 보이며, 효과적으로 분류 성능을 향상시키는 fake sample을 생성합니다.
'연구실 공부' 카테고리의 다른 글
| 음성 인식 관련 용어 정리 (0) | 2024.01.28 |
|---|---|
| [논문] Auto-Encoding Variational Bayes (0) | 2024.01.19 |
| [논문] DynaGAN: Dynamic Few-shot Adaptation of GANs to Multiple Domains (0) | 2023.03.31 |
| [논문] FIFO: Learning For-invariant Features for Foggy Scene Segmentation (0) | 2023.03.26 |
| [ML] 7. Logistic Regression (0) | 2023.03.06 |



