https://arxiv.org/abs/1512.03385
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
더 깊은 neural network은 train하기에 어려움이 있습니다. 그래서 저자들은 이전에 비해 훨씬 더 깊은 network를 train하는 데 용이한 residual learning framework를 소개합니다. 저자들은 layer를 layer input에 대한 reference를 바탕으로 학습하는 residual function으로 재정의합니다. 저자들은 residual network가 optimize하기 더 쉽고, 훨씬 더 깊어진 깊이로 인해 accuracy의 향상을 얻을 수 있음을 보입니다.
Introduction
Deep convolutional neural networks는 image classification의 상당한 발전을 이끌었습니다. Deep network는 low/mid/high level feature와 classifier를 하나의 multi-layer 방식으로 통합하며, feature의 level은 stacked layer의 수(depth)에 의해 풍부해질 수 있습니다. network depth가 중요하다는 연구가 등장했으며, ImageNet dataset에서 뛰어난 성능을 보이는 model들은 모두 매우 깊은(16~30) network로 이루어집니다.
depth의 중요성이 대두됨에 따라 '더 많은 layer를 쌓는 것만으로 더 나은 network를 학습하는 것이 쉬운가?'라는 질문이 등장했습니다. 해당 질문에 장애물로 gradient vanishing/exploding이 존재하며, 이는 수렴을 방해합니다. 그러나 이러한 문제는 normalized initialization과 intermediate normalization layer를 이용해 상당 부분 해결되었으며, 10개의 layer를 가진 network를 SGD를 이용해 수렴할 수 있게 되었습니다.

깊은 network가 수렴하기 시작함에 따라, degradation 문제가 등장하기 시작했습니다. network depth가 증가하면서 정확도가 포화되고 빠르게 성능이 감소하는 문제가 등장했습니다. 이러한 degradation은 overfitting에 의한 것이 아닙니다. 이는 적정한 depth의 model에 layer를 추가하면 train error가 높아지기 때문에 발생하는 문제입니다.
이 논문에서, 저자들은 deep residual learning framework를 이용해 degradation 문제를 해결합니다. 저자들은 몇 개의 stacked layer가 바로 원하는 기본 mapping을 직접 맞추는 것이 아닌, residual mapping에 맞도록 만듭니다. 원하는 기본 mapping을 H(x)라고 할 때, stacked nonlinear layers는 F(x) := H(x) - x을 mapping하도록 합니다. 저자들이 제안한 방식대로 residual mapping을 최적화하는 것이 기존 방식보다 더 쉽게 최적화할 수 있다고 합니다.

F(x) + x는 shortcut connection을 가진 feedforward로 나타낼 수 있습니다. shortcut connection은 1개 또는 더 많은 수의 layer를 생략하는 것을 의미합니다. 저자들의 경우, shortcut connection을 간단하게 identity mapping을 수행하고, 그 값은 stacked layer의 output과 더해져 사용됩니다. identity shortcut connection은 추가적인 parameter가 필요하지 않고, 계산량 증가가 필요하지 않습니다. 전체 network는 backpropagation으로 한 번에 학습될 수 있으며, 쉽게 구현할 수 있습니다.
저자들이 제안한 방식은 더 깊은 network를 이용해도 쉽게 최적화할 수 있으며 training error가 높아지지 않습니다. 그리고 depth가 늘어남에 따라 이전 network들보다 더 좋은 정확도를 보여줍니다.
Related Work
Residual Representation
image recognition task에서, VLAD는 dictionary에 관한 residual vector를 encoding하여 표현하는 방법이고, Fisher Vector는 VLAD의 확률론적 version으로 구성될 수 있습니다. 둘 다 image retrieval과 classification를 위한 powerful shallow representation입니다. vector 양자화에서, encoding residual vector는 encoding original vector보다 더 효과적입니다.
low level vision & computer graphics에서 Partial Differential Equations(PDE)를 해결하기 위해, 자주 사용되는 multigrid method는 multiple scale에서의 하위 문제로 system을 재정의하는 방식입니다. 여기서 각 하위 문제들은 더 coarser한 scale과 더 finer한 scale 사이의 residual solution을 담당합니다.
multigrid의 대안으로 게층적 basis preconditioning이 있으며, 이는 두 scale 사이의 residual vector를 나타내는 변수에 의존합니다. 이러한 해결책들은 서 빠르게 수렴하도록 만들어줍니다.
Shortcut Connections
shortcut connection에 대한 실험과 이론들은 오랜 기간 동안 이루어져 왔습니다. 초기 MLP 학습에서는, network의 input에서 output으로 connect된 linear layer를 추가하는 방식이었습니다. 몇몇 중간 layer들이 직접적으로 보조 classifier에 연결되는 방법이며 이를 통해 gradient vanishing/exploding 문제를 해결하는 방식입니다.
몇몇 연구들에선 layer response, gradient, propagated error를 centering하는 방법들을 제안했고, 이는 shortcut connection을 통해 구현되었습니다.
'highway network'는 gating function을 가진 shortcut connection을 제안합니다. 이 gates는 data dependent하며 parameter를 가지고 있습니다. 하지만 저자들이 제안한 identity shortcut은 parameter가 없습니다. gated shortcut이 close(0에 가까워질 때)이면, highway network에 있는 layer들은 non residual function을 나타냅니다. 대조적으로 저자들의 방식은 항상 residual function을 이용합니다. 그래서 모든 정보는 항상 pass되며 추가적인 residual function이 학습됩니다. 'highway network'의 경우, depth가 매우 증가(100개 layer 이상)되었을 때, accuracy 향상에 대한 입증이 일어나지는 않았습니다.
Deep Residual Learning
Residual learning
H(x)를 기본 mapping으로 여기겠습니다. 이 H(x)는 몇 개의 stacked layer로 인해 mapping되며, 여기서 x는 첫 번째 layer의 input을 의미합니다. 만약 여러 개의 nonlinear layer가 복잡한 함수를 근사할 수 있다고 가정한다면, H(x) - x라는 residual function 역시 복잡한 함수를 근사할 수 있다는 것과 동등한 가정입니다(input과 output은 동일한 크기의 차원). 따라서, 저자들은 stacked layer가 H(x)를 근사하기를 기대하는 대신, F(x) := H(x) - x를 근사하도록 설정합니다. 이 식을 이용한다면 H(x)는 F(x) + x가 됩니다. 두 형태의 training 용이성은 다를 수 있습니다.
만약 추가된 layer가 identity mapping으로 구성할 수 있다면, deeper model이 shallower model에 비해 training error가 더 클 수 없어야 합니다. degradation 문제는 해결책이 multiple nonlinear layer을 통해 identity mapping을 근사하는 데 어려움을 겪을 수 있음을 제안합니다. residual learning 재구성을 이용하여 identity mapping이 optimal하다면, 해결책은 여러 non linear layer의 weight를 0으로 만들어 identity mapping에 가까워지도록 할 수 있습니다.
실제로는, identity mapping이 optimal한 경우는 흔치 않지만, 저자들의 재구성 방식은 문제를 precondition하는 데 도움을 줄 수 있습니다.
Identity mapping by shortcut
저자들은 residual learning을 모든 몇 개의 stacked layer에 적용했습니다.

여기서 x는 input vector를 의미하고 y는 output vector를 의미합니다. function F(x, {W_i})은 학습된 residual mapping을 의미합니다.

위 예시를 보면 이와 같이 2개의 layer로 구성되어 있습니다. 여기서 σ는 ReLU를 의미하고 bias는 그냥 표기를 편하게 하기 위해 생략되었습니다. F + x는 shortcut connection과 element-wise addition으로 동작합니다. 마지막에 덧셈을 한 다음에 ReLU를 적용합니다.
shortcut connetion Eq (1)은 추가적인 parameter나 연산량이 필요하지 않습니다. Eq(1)의 경우, x와 F의 차원은 무조건 동일해야만 합니다. 만약 동일하지 않다면, 차원을 맞추기 위해 linear projection W_s을 사용해야 합니다.

square matrix W_s를 사용하면 위와 같은 식으로 나타낼 수 있습니다. 저자들은 본인들의 방식이 degradation problem을 다루기 충분히 효과적이고 경제적임을 실험으로 보여주며, W_s는 차원을 맞출 때만 사용합니다.
residual function F는 유동적입니다. 이 논문에서 실험은 F가 2개 또는 3개 layer를 가진 상태로 진행됩니다. 물론 더 많은 layer를 사용할 수 있습니다. 하지만 F가 1개 layer로만 이루어진다면, Eq (1)은 linear layer와 비슷한 형태가 되며(y = W_1x + x) 이점을 가질 수 없습니다. 그래서 2개 이상의 layer를 이용해 구현합니다.
위 식의 경우 fully-connected layer 형태로 표현했지만, convolutional layer도 적용할 수 있습니다. function F(x, {W_i})은 multiple convolutional layer로 표현할 수 있습니다. element wise addition은 2개의 feature map이 channel 별로 덧셈하는 것을 의미합니다.
Network Architectures
저자들은 다양한 plain/residual network를 실험하며, 일관된 현상을 관측했습니다.
- Plain Network

위 그림은 저자들이 사용하는 34-layer plain network입니다. 이는 VGGnet을 기반으로 하는 model입니다. convolutional layer는 3x3 filter를 가집니다. 그리고 동일한 output feature map size를 갖기 위해 각 layer들은 동일한 수의 filter를 갖습니다. 그리고 만약 feature map size가 절반으로 줄어든다면, 각 layer의 시간 복잡도를 보존하기 위해 filter 수를 2배 늘렸습니다. 저자들은 convolutional layer에 stride 2를 두어 downsampling을 바로 진행했습니다. network의 마지막에는 global average pooling layer와 1000 크기 fully connected layer with softmax를 두었습니다. 최종 weighted layer 수는 34입니다.
해당 plain network는 기존 VGGnet에 비해 더 적은 filter를 사용하고 더 적은 복잡성을 갖습니다.
- Residual Network

위 network은 residual network입니다. 이는 이전에 보았던 plain network에 shortcut connection을 추가한 형태입니다. identity shortcut은 input과 output의 차원이 동일하다면 바로 사용할 수 있습니다(위 network에서 실선). 차원이 증가되는 경우(위 network에서 실선), 2가지 option이 있습니다. 먼저, 증가되는 차원에 0을 padding하는 방식입니다. 이를 통해 shortcut은 identity mapping을 그대로 수행합니다. 두 번째로, Eq (2)와 같이 projection shortcut을 이용해 차원을 맞추는 방식입니다.
Implementation
저자들은 image를 랜덤하게 224 x 224 크기로 crop했습니다. 그리고 data augmentation을 위해 horizontal flip, standard color augmentation을 했습니다. 저자들은 batch normalization을 각 convolution 바로 뒤에 적용했습니다. SGD를 사용하고, mini-batch size를 256으로 설정해 train했습니다.
Experiments
ImageNet Classification

위 표는 layer 수에 따른 구조를 표현합니다.


plain network의 경우, 34-layer가 18-layer에 비해 약간 더 낮은 training error를 보여줍니다. 저자들은 이러한 결과를 gradient vanishing 때문일 가능성이 낮다고 생각합니다. plain network는 BN을 통해 0이 아닌 signal을 forward propagate합니다. 그리고 backward propagated gradient도 BN을 통해 vanishing되었을 가능성이 낮기 때문입니다. 사실, 34 layer plain network는 여전히 경쟁력 있는 accuracy를 보여주긴 합니다. 저자들은 deep plain network의 수렴률이 기하급수적으로 낮기 때문에 training error를 줄이는 데 어려움이 있을 것이라고 추측합니다.
residual network의 경우, plain network에 shortcut connection을 추가한 구조입니다. 먼저, 34-layer ResNet이 18-layer ResNet보다 더 나은 결과를 보여줍니다. 34-layer ResNet의 결과를 보면, depth가 늘어나도 accuracy 향상을 얻는 것을 볼 수 있으며 degradation problem을 잘 해결하고 있다는 것을 알 수 있습니다. 그리고 plain network에 비해 더 좋은 결과를 보이는 것을 알 수 있으며 training error를 효과적으로 줄인 것을 위 그래프로 알 수 있습니다. 이를 통해 deep network에서 residual learning의 효과를 입증할 수 있습니다.
18-layer plain network와 18-layer ResNet을 비교했을 때, 둘의 정확도는 비교가능한 정도이지만, 18-layer ResNet이 더 빠르게 수렴합니다. 이를 통해 ResNet이 더 빠르게 수렴함으로써 효율적으로 optimization한다는 것을 알 수 있습니다.
Identity vs Projection shortcuts
이전 결과를 통해 추가적 parameter가 필요 없는 identity shortcut이 train에 도움을 준다는 것을 알 수 있습니다. 이번에는 projection shortcut(eq (2))에 대해 보겠습니다.

위 표는 3가지 option에 대해 비교합니다. A의 경우, zero-padding shortcut을 사용해 차원을 늘려 shortcut을 사용하는 방식입니다. 이는 추가적은 parameter가 필요로 하지 않습니다. B의 경우, projection shortcut을 차원이 늘어나는 곳에만 적용하고 아닌 부분은 identity shortcut을 사용하는 방식입니다. C의 경우, 모든 shortcut을 projection matrix로 구현하는 방식입니다.
위 표를 보면 3가지 방식 모두 plain network에 비해 뛰어난 모습을 보입니다. B가 A보다 약간 더 나은 모습을 보입니다. A의 zero padding된 차원들은 residual learning을 하지 않기 때문이라고 볼 수 있습니다. C는 B보다 더 나은 모습을 보이며, 많은(13개) projection shortcut에 의해 사용되는 추가적 parameter 때문이라고 저자들은 이야기합니다. 그러나 A/B/C의 차이에서 알 수 있듯이, projection shortcut이 degradation problem을 해결하는 데 필수적인 것은 아닙니다. 그래서 저자들은 model size를 줄이고 memory/time 복잡도를 줄이기 위해 더 이상 C를 사용하지는 않습니다.
Deeper bottleneck architectures
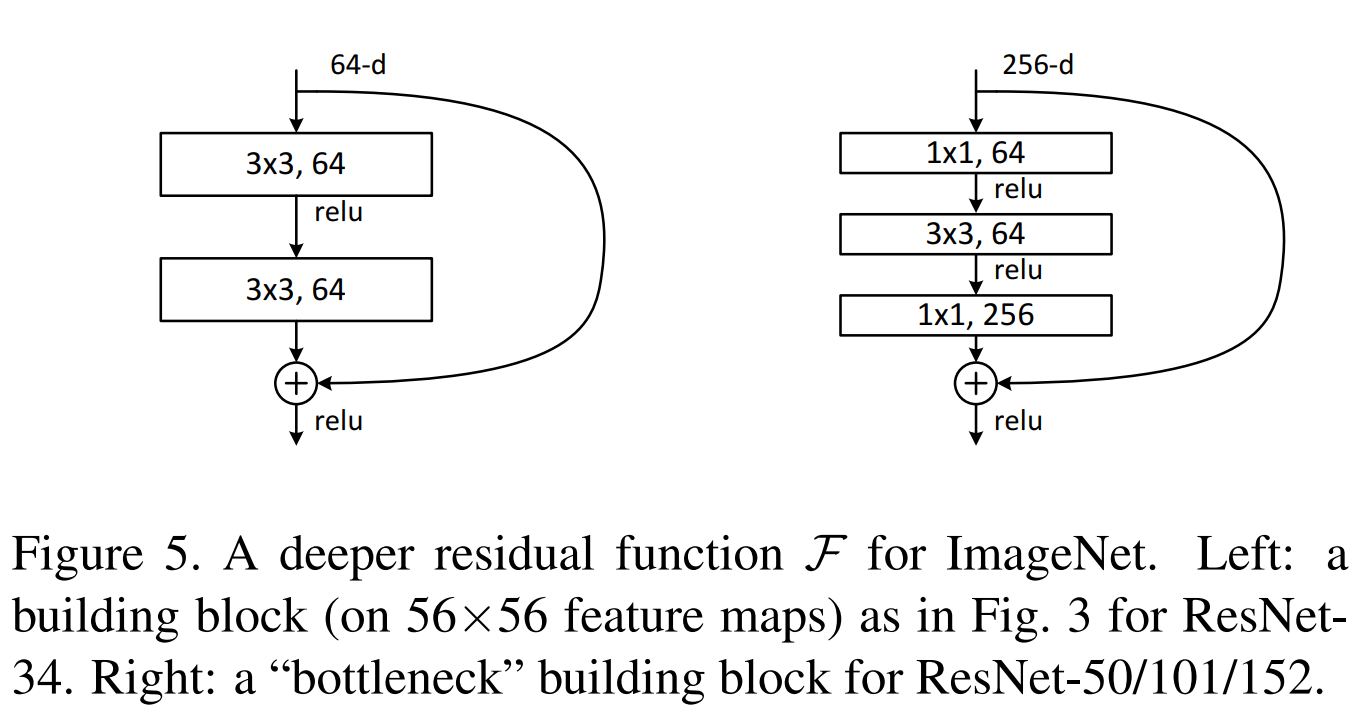
이번에는 더 깊은 network를 보겠습니다. 저자들은 training time을 고려해 bottleneck design을 수정했습니다. 각 residual function F를 2개의 layer가 아닌 3개 layer로 수정했습니다. 1x1, 3x3, 1x1 convolution layer로 구성했습니다. 위 그림에서 나타내는 두 block의 시간 복잡도는 유사합니다.
parameter가 필요 없는 identity shortcut은 bottleneck architecture에서 특히 중요합니다. 만약 위 그림에서 오른쪽 identity shortcut을 projection으로 대체한다면, 시간 복잡도와 model size는 2배로 늘어납니다(shortcut이 2개의 고차원 결과에 연결되기 때문에). 그래서 identity shortcut은 bottleneck design을 더 효과적인 model로 만들어줍니다.
- 50-layer ResNet
저자들은 34-layer network에 있는 2 layer bottleneck block을 3 layer bottleneck block으로 대체하여 50-layer ResNet을 만듭니다. 저자들은 option B를 사용해 차원 증가를 해결했습니다.
- 101-layer and 152-layer ResNets
3-layer block을 더 많이 사용하여 101-layer와 152-layer ResNet을 구현했습니다. 비록 depth가 눈에 띄게 증가했지만, 152-layer ResNet이 VGG-16/19 network에 비해 더 적은 연산량을 가지게 됩니다.
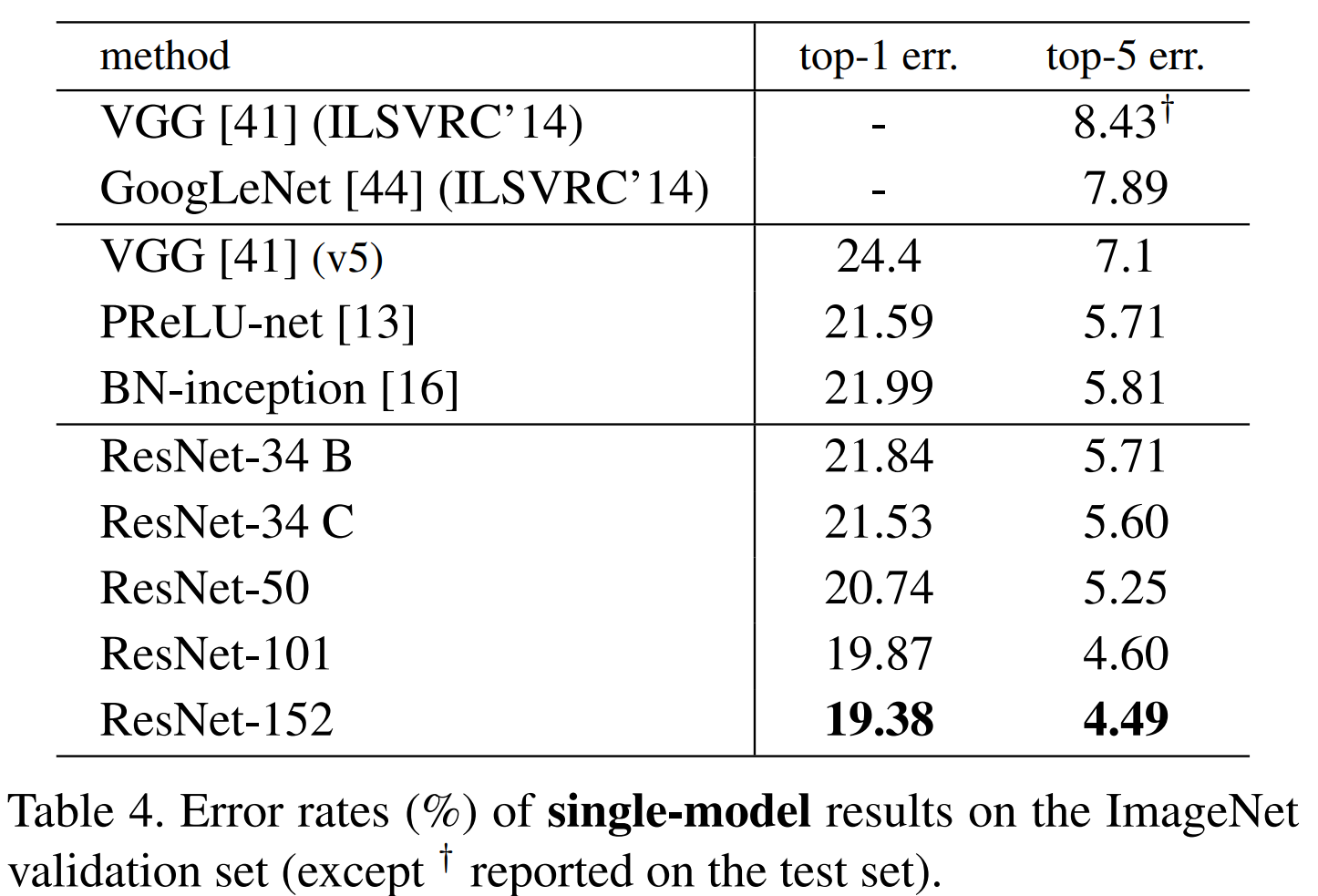
50/101/152-layer ResNet은 34-layer에 비해 더 높은 정확도를 보입니다. 저자들이 제안한 ResNet에서는 degradation problem이 발견되지 않았으며, depth의 증가에 따른 성능 향상을 얻을 수 있었습니다.
저자들은 1202-layer network도 이용해 결과를 비교했습니다. 1202-layer가 더 많은 layer를 가지고 있음에도 불구하고 110-layer network가 더 좋은 결과를 보이거나 비슷한 training error를 보입니다. 이는 overfitting 때문이라고 저자들이 생각합니다. 1202-layer network는 dataset에 비해 불필요하게 크기 때문에 overfitting이 일어났다고 생각합니다. 강력한 regularization trick과 같이 사용한다면 결과가 좋아질지에 대한 연구는 앞으로 등장해야 한다고 합니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Learning Transferable Visual Models from Language Supervision (0) | 2024.02.22 |
|---|---|
| [논문] LoRA: Low-Rank Adaptation of Large Language Models (0) | 2024.02.20 |
| [논문] Generative Adversarial Net (0) | 2024.02.17 |
| [논문] Large-Scale Self-Supervised Speech Representation Learning for Automatic Speaker Verification (0) | 2024.02.08 |
| [논문] ResNeXt and Res2Net Structures for Speaker verification (0) | 2024.02.07 |



