https://arxiv.org/abs/2103.00020
Learning Transferable Visual Models From Natural Language Supervision
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual co
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
computer vision system은 사전 정의된 object category set을 예측하도록 학습됩니다. 이러한 제한된 형태의 supervision(감독)은 system의 일반화 성능과 사용성을 제한합니다. 왜냐하면 다른 시각적 개념을 지정하기 위해선 추가적인 labeled data가 필요하기 때문입니다. image에 대한 raw text로부터 바로 학습하는 것은 훨씬 더 많은 source를 사용하는 대안이 됩니다. 저자들은 어떤 image가 어떤 caption과 일치하는지 예측하는 간단한 pre-training task가 40억 개 (image, text) 쌍의 dataset에서 처음부터 SOTA image representation을 학습할 수 있는 효율적이고 확장 가능한 방법임을 보입니다. pre-training 이후에, natural language는 학습된 visual concepts(or describe new ones)를 참조하는 데 사용되거나, model이 zero-shot prediction을 하는 task로 변환할 때 사용됩니다.
Introduction and motivating work
raw text로부터 바로 학습하는 pre-training method는 NLP에 새로운 변화를 가져다 주었습니다. autoregressive와 masked language modeling과 같은 task-agnostic objectives(task를 불가지정하는 objective)는 컴퓨팅 성능, model 용량, data의 증가 등 다양한 분야의 발전을 통해 확장되어 왔습니다. "text-to-text"의 표준 input-output interface 개발은 task-agnostic architecture가 downstream dataset으로의 zero-shot transfer을 가능하게 하여, 특수화된 output head나 dataset을 customizing할 필요가 사라졌습니다. GPT-3와 같은 system은 많은 task에서 맞춤형 model과 경쟁력 있으며, task에 특화된 train data를 거의 또는 전혀 요구하지 않습니다.
대규모 natural language model들은 웹에서 모을 수 있는 text를 이용한 pre-train model이 기존의 labeling된 dataset으로 학습한 model보다 성능이 좋아지거나 능가하는 모습을 보였습니다. 하지만 computer vision에서는 ImageNet과 같이 crowd-labeled dataset으로 pre-train 하는 것이 여전히 일반적입니다. '그럼, web text로부터 바로 학습하는 pre-training method가 computer vision에서도 좋은 성능을 보일까?'에 대한 질문의 답을 저자들이 해줍니다.
20년 이상 전, content 기반 image 검색 성능을 향상시키는 연구가 있었습니다. 이는 image와 짝지어진 text 문서에서 명사와 형용사를 예측하는 model을 학습하여 이뤄낸 성과였습니다. 그리고 몇 년 후, caption들 중 image와 연관된 단어를 예측할 수 있도록 학습된 classifier의 weight space에서 manifold learning을 하여 image representation을 효율적으로 할 수 있음을 보였습니다. 이후, low-level image와 text tag feautre를 이용해 multimodal Deep Boltzmann Machine을 학습하여 deep representation learning에 대한 연구가 등장했습니다. 그 이후에도 다양한 multimodal 연구들이 등장했으며 많은 발전이 있었습니다.
이러한 multimodal 분야는 여러 발전이 있었지만, natural language를 image representation learning에 사용되는 경우는 매우 드물었습니다. 왜냐하면, 다른 방식들에 비해 성능이 좋지 않았기 때문입니다. 대신에, weak supervision(labeling data의 비율이 낮은 dataset)은 성능을 향상시키는 결과를 보였습니다.
이러한 연구들은 제한된 labeled dataset으로 학습하는 것과 labeling되지 않은 text로부터 학습하는 것 사이의 현재 위치를 보여줍니다. 두 학습 방식 모두 static softmax classifier를 predict할 때 사용했기 때문에 동적인 output이 부족합니다. 이로 인해 flexibility가 떨어지고 "zero-shot" 능력을 제한시키게 됩니다.
weakly supervised model과 natural language로부터 직접적으로 학습하는 image representation 사이의 차이는 scale이라고 합니다. 예를 들어 weakly supervised model의 경우 수백만에서 수십억 개의 image에 대해 train하지만, VirTex, ICMLM, ConVIRT와 같은 model은 10만에서 20만 개의 image에 대해 train했습니다.
그래서 해당 논문에서는, 저자들이 이 gap을 줄이고 natural language를 label로 하는 대규모 dataset으로 학습된 image classifier의 행동에 대해 연구합니다. 저자들은 인터넷을 이용해 4억 개의 (image, text) 쌍을 만들고, natural language supervision에서 저자들이 제안한 ConVIRT의 단순화 버전인 Contrastive Language-Image Pre-training(CLIP)이 효과적임을 증명합니다.
Approach
Natural language supervision
저자들의 방식의 핵심은, natural language에 포함된 supervision에서 perception을 학습하는 것입니다. 위에서 말했듯이 새로운 idea는 아니지만, unsupervised, self-supervised, weakly supervised, supervised 등 다양한 접근 방식들입니다.
결국 이런 연구들에서 공통적으로 강조하는 것은 natural language를 training signal로 사용한다는 것입니다. 이러한 접근 방식들은 전부 natural language supervision을 통해 학습됩니다.
natural langugae로 학습하는 것은 다른 방식들보다 몇몇 잠재된 강점이 있습니다. standard crowd sourced label과 비교하여 natural alnguag esupervision을 scale하는 것은 훨씬 더 쉽습니다. natural language에서 동작하는 method들은 방대한 양의 text를 포함하고 있는 supervision에서 수동적으로 학습합니다. natural language로부터 학습하는 것은 대부분의 unsupervised or self-supervised learning approach에 비해 중요한 이점이 있는데, 이는 단지 representation을 학습하는 것 뿐만 아니라, representation을 language로 connect합니다. 이를 통해 유연한 zero-shot transfer가 가능해집니다.
Selecting an efficient pre-training method
좋은 성능을 보이는 computer vision system들은 매우 많은 연산량을 사용합니다. 예를 들어 ResNeXt101-32x48d의 경우 19개의 GPU를 사용합니다. 이러한 system은 오직 1000 ImageNet class를 예측하기 위해 학습되었다는 걸 생각해 보면, natural language로부터 시각적 개념을 학습하는 것은 어려워 보입니다. 그래서 저자들은 training efficiency가 natural language supervision을 성공적으로 scaling하는 데 중요한 key라고 생각했으며, 이를 고려하여 pre-training method를 선택했습니다.
저자들의 초기 접근법은 VirTex와 유사했는데, image CNN과 text tranformer를 처음부터 동시에 학습하여 image의 caption을 예측하는 방식이었습니다. 그러나, 저자들은 이 방법을 효율적으로 scaling하는 데 어려움을 겪었습니다.

위 그래프에서 알 수 있듯이, 저자들은 6300만 개의 parameter를 가진 transformer language model이 ResNet-50 image encoder의 두 배에 해당하는 연산을 사용함에도 훨씬 간단한 baseline(동일한 bag-of-words encoding을 예측하는)보다 ImageNet class를 인식하는 데 3배 더 느린 속도를 보여줍니다.
baseline과 transformer language model은 중요한 유사점을 공유합니다. 두 방식 모두 각 이미지에 포함된 정확한 단어를 예측하려고 합니다. image에 대응하는 설명, 댓글, 관련된 text 들의 다양성 때문에 정확한 단어를 예측하는 것은 어려운 task입니다. 최근에 등장한 image에 대한 contrastive representation learning은 contrastive objectives가 더 나은 표현을 학습할 수 있다는 것을 발견했습니다. 다른 연구들에선, image 생성 모델이 높은 quality의 image representation을 학습할 수 있지만, contrastive model과 동일한 성능일 때 contrastive model보다 더 많은 양의 연산이 필요하다는 문제를 발견했습니다.
그래서 저자들은 text의 정확한 단어가 아닌 전체 text가 어떤 image와 짝을 이루는지만 예측하는, 잠재적으로 더 쉬운 proxy 작업을 해결하기 위해 system을 훈련시키는 방법을 연구했습니다. bag-of-words encoding baseline을 시작으로, 저자들은 predictive objetive를 contrastive objective로 변경하여 ImageNet으로의 zero-shot transfer에서 4배 더 빠른 속도를 보입니다.

N개 (image, text)쌍의 batch가 주어졌을 때, CLIP은 NxN 크기의 가능한 (image, text) 쌍들을 예측하도록 학습됩니다. 이를 위해 CLIP은 image embeddings와 text embeddings의 cosine similarity를 maximize하고 서로 맞지 않은 N^2 - N개의 image embeddings와 text embeddings의 cosine similarity는 minimize하도록 image encoder와 text encoder를 동시에 학습하여 multi-modal embedding space를 학습합니다. 이 similarity score에 대해 대칭 cross entropy loss를 최적화하여 진행됩니다. 위 그림과 같이 (image embeddings, text embeddings) 쌍 중 올바른 쌍들에 대한 cosine similarity는 maximize하고, 다른 pair에 대한 cosine similarity는 minimize하는 방식입니다.

위 pseudocode는 CLIP에 대한 core를 나타냅니다. 이와 같은 contrastive (text, image) representation learning은 medical image domain에서도 사용되었습니다.
pre-training dataset의 size가 크기 때문에, overfitting이 주된 문제는 아니며, CLIP의 train 방식은 기존 방식들에 비해 더 단순화된 형태입니다. 저자들은 pre-trained weight를 사용하지 않고, image encoder인 ImageNet과 text encoder를 처음부터 학습합니다. 그리고 representation과 contrastive embedding space 사이에 non-linear projection을 사용하지 않습니다. 대신에, 저자들은 linear projection만 사용하여 각 encoder의 representation을 multi-modal embedding space로 mapping합니다. 저자들은 non-linear projection이 있거나 없는 두 version의 train 효율성 차이를 발견하지 못했으며, non-linear projection은 self-supervised representation learning 방식에서만 현재 image의 detail과 함께 적용될 것이라고 추측했습니다. 그리고 저자들은 text transformation function t_u를 제거했습니다. CLIP의 pretraining dataset은 단일 문장 형태이므로 text에서 단일 문장을 균일하게 sampling하는 t_u를 제거했습니다. 그리고 저자들은 image transformation function t_v도 단순화했습니다. training시에 data augmentation하기 위해 resized image를 random하게 정사각형으로 crop했습니다. 마지막으로, softmax에 존재하는 logits의 범위를 control하는 temperature parameter τ는 training 중에 직접적으로 최적화됩니다.
Choosing and scaling a model
저자들은 image encoder로 다른 2개의 구조를 고려했습니다. 먼저, ResNet-50입니다. 이를 image encoder의 base architecture로 사용했는데, 이미 좋은 성능을 입증한 구조이기 때문에 사용했습니다. 저자들은 ResNet-50에 ResNet-D를 기반으로 여러 개선사항을 적용했습니다. 이를 통해 encoding 과정에서 세부 정보를 보존하면서도 noise를 줄일 수 있었습니다. 또한 global average pooling layer를 attention pooling mechanism으로 대체했습니다. attention pooling은 multi-head QKV(query, key, value) attention을 이용했습니다. image의 global average-pooled representation를 condition으로 하는 query에 대한 QKV attention입니다. query와 key 사이의 상호작용을 통해 attention weight를 계산하고, 이 weight를 사용하여 value를 가중합 하여 최종 output을 만드는 방식입니다.
그다음 구조로, 좀 더 최근 구조인 Vision Transformer(ViT)를 사용했습니다. 저자들은 ViT의 기본 구조를 크게 따르지만, 추가적인 layer normalization을 추가했습니다. patch와 position embedding에 layer normalization을 추가하고 transformer 앞에 약간의 수정된 initialization scheme을 사용했습니다.

text encoder로 수정된 transformer를 사용했습니다. 63M-parameter, 12-layer, 512-wide, 8 attention heads를 가진 model을 사용했습니다. transformer는 49152개의 어휘 크기를 가진 text의 lower-cased byte pair encoding(BPE) representation에서 동작합니다. 연산의 효율성을 위해, 최대 sequence 길이는 76으로 제한했습니다. text sequence는 [sos]와 [eos] 토큰으로 묶여 있으며, [EOS] 토큰에서 transformer의 가장 높은 layer의 activation은 text의 feature representation으로 다뤄지고 layer normalized된 후에 multi-modal embedding space로 선형 projection됩니다. pre-trained language model의 초기화 능력을 보존하거나 추가적인 보조 목적으로 masked self-attention(text의 일부를 masking하여)을 text encoder에 사용했습니다.
이전 computer vision 연구에서는 widht나 depth를 단독으로 증가시키는 방법으로 model의 크기를 키웠습니다. 하지만 저자들은 ResNet image encoder를 사용할 때, model의 width, depth, resolution 전체를 동일 비율로 향상시켜서 사용했습니다. text encoder로, 저자들은 ResNet의 width가 늘어난 만큼 model의 width만 늘렸습니다. depth는 늘리지 않았는데, CLIP의 성능이 text encoder의 크기에 덜 sensitive하기 때문입니다.
Training
저자들은 5개의 ResNet 종류와 3개의 Vision Transformer를 이용했습니다. ResNet-50, ResNet-101, ResNet-50의 크기를 키운 3가지 model을 사용했습니다. ViT-B/32, ViT-B/16 그리고 ViT-L/14를 사용했습니다. 그리고 32 epoch으로 model을 adam으로 학습했습니다. 저자들은 학습 가능한 temperature parameter τ을 0.07로 설정했고, 100을 넘지 않도록 설정하여 train을 안정적으로 할 수 있도록 만들었습니다.
Experiments
Zero-shot transfer
- Motivation
computer vision 분야에서, zero-shot learning은 주로 이미지 classification을 할 때 train 때 보지 못한 object categories를 일반화하는 연구를 의미합니다. 저자들은 zero-shot learning을 더 넓은 범위의 용어로 사용하여, 보지 못한 dataset에 대한 일반화하는 연구를 진행합니다. unsupervised learning 분야에 있는 많은 연구들은 machine learning system의 representation learning 능력에 focusing하지만, 저자들은 zero-shot transfer를 공부하는 것이 machine learning system의 task-learning 능력을 측정하는 한 가지 방법이 될 수 있다고 주장합니다. 이러한 관점에서, dataset은 특정 분포에서 task의 성능을 평가합니다. 그러나, 많은 computer vision dataset은 특정 task의 성능을 측정하기보다는 일반적인 image classification의 발전을 위해 주로 만들어졌습니다. 그래서 zero-shot transfer는 CLIP의 분포 shift에 대한 강건함과 domain 일반화를 평가하는 데 더 적합합니다. 저자들은 zero-shot transfer를 task learning의 평가로 연구하는 데 집중합니다.
- Using CLIP for zero-shot transfer
CLIP은 image와 text 단편이 dataset 내에서 같은 쌍을 이루었는지 예측하기 위해 pre-training되었습니다. zero-shot classification을 하기 위해, 저자들은 CLIP의 기능을 사용합니다. 각 dataset에 대해, 저자들은 dataset에 있는 모든 class의 이름을 잠재적인 text 쌍의 집합으로 사용하고, CLIP에 따라 가장 가능성이 높은 (image, text)쌍을 예측합니다. 좀 더 자세히 말하면, 먼저 image의 feature embedding과 가능한 text 집합의 feature embedding을 각각의 encoder로 계산합니다. 이 embedding들의 cosine 유사도를 계산하고, temperature parameter τ로 scaling합니다. 그다음 softmax를 통해 구한 확률분포 정규화됩니다. 이 prediction layer는 L2 normalized input, L2-normalized weight, no bias, temperature scaling을 통한 다항 logistic regression classifier입니다. 이와 같은 방식으로 해석할 때, image encoder는 image의 feature representation을 계산해주는 computer vision backbone을 사용합니다. 그리고 text encoder는 hypernetwork인데, 이는 class가 나타내는 시각적 개념을 지정하는 text를 기반으로 선형 classifier의 가중치를 생성합니다.
CLIP pre-training의 모든 step은 natural language 설명으로 정의된 총 32768 class로 이루어지고 각 class마다 1개의 예제만 포함하고 있는 computer vision dataset에 무작위로 생성된 proxy의 성능을 최적화하는 것으로 볼 수 있습니다.
- Analysis of zero-shot CLIP performance
task에 무관한 zero-shot classifier는 아직 연구가 많이 되지 않았기에, CLIP은 이러한 model의 이해도를 높이는 데 도움이 될 것입니다. 그래서 저자들은 CLIP의 zero-shot classifier의 다양한 속성에 대한 연구를 진행합니다.
먼저, zero-shot classifier가 잘 동작하는지 알아보겠습니다. 저자들은 CLIP's zero-shot classifer을 ResNet-50을 이용한 classifier와 비교합니다.

위 표를 보면 27가지 dataset에 대한 결과를 보여줍니다. CLIP's zero-shot classifier가 16가지 dataset에서 더 좋은 모습을 보여줍니다.
dataset을 각각 살펴보았을 때, 몇 가지 흥미로운 결과를 볼 수 있습니다. 세밀한 classification task에서, 저자들의 성능은 다양하게 분포합니다. Stanford Cars와 Food101에선 더 뛰어난 결과를 보이지만, Flowers102와 FGVCAircraft에서는 더 낮은 결과를 보입니다. 저자들은 이에 대한 이유로 WIT(Web Image Text)와 ImageNet의 양 차이가 주된 원인이라고 생각합니다(WIT가 더 많음). 일반적인 물체에 대한 classification dataset(ImageNet, CIFAR10/100, STL10, PascalVOC2007)에 대해서는 CLIP과 ResNet50 classifier의 성능이 비슷하거나 CLIP이 약간 더 높습니다. STL10의 경우, 해당 dataset을 사용하지도 않고 새로운 최고 기록을 세운 모습을 보입니다.
그리고 CLIP은 video에서 행동 인식을 측정하는 두 dataset(Kinetics700, UCF101)에서 ResNet-50을 크게 능가하는 모습을 보입니다. 저자들은 natural language가 동사를 포함하여 시각적 concept에 더 넓은 supervision을 제공하기 때문이라고 생각합니다.
여러 전문적이고 복잡한 dataset에서 CLIP은 상대적으로 좋지 않은 모습을 보입니다. 위성 이미지 분류(EuroSAT, RESISC45), 림프절 종양 감지(PatchCamelyon), 합성 장면에서 객체 수 계산(CLEVRCounts), 가장 가까운 차량과의 거리 인식과 같은 자율 주행 관련 작업(KITTI Distance), 독일 교통 표지판 인식(GTSRB)과 같이 전문적이고 복잡한 dataset에서는 좋은 결과를 보이지 못합니다. 즉 CLIP's zero-shot은 복잡한 task에서 좋은 모습을 보이지 못합니다. 그래도 추가적인 학습 없이도 일반적인 표현 학습만으로 풀 수 있는 task에서 좋은 결과를 보여줍니다.

이번에는 CLIP에도 linear probe를 붙인 결과를 보여줍니다. 즉 CLIP으로 학습한 image encoder와 text encoder는 그대로 두고 뒤에 classifier layer만 붙여서 학습을 새로 진행합니다(image embedding과 text embedding을 다 input으로 사용). 위 표를 보면, x축은 각 class당 존재하는 sample 수를 의미합니다. 모든 경우에서 CLIP이 가장 좋은 성능을 보입니다. 즉 CLIP은 few-shot logistic regression에서도 좋은 성능을 보입니다. 그리고 zero-shot이 4-shot과 동일한 성능을 보이며 1-, 2-shot에서는 오히려 zero-shot의 성능이 더 높습니다.
CLIP's zero-shot classifier의 경우, natural language를 통해 visual concept을 직접적으로 지정할 수 있었습니다. 하지만 일반적인 supervised leraning은 training example을 통해 concept을 간접적으로 추론해야 합니다. 문맥이 없는 example 기반 학습은 특히 one-shot case에서, 하나의 data로 많은 가능한 해석들이 존재하게 된다는 단점이 존재합니다. 즉, 정확히 하나의 class라고 구분하기엔 정보가 부족합니다. 그래서 오히려 CLIP's zero-shot classifier가 더 나은 성능을 보여줍니다.

위 그래프는 zero-shot classifier의 효율성을 보여줍니다. 각 dataset마다 몇 개의 sample을 사용해야 zero-shot classifier와 동일한 성능이 되는지 비교한 결과입니다. 위 결과는 CLIP을 이용해 zero-shot classifier와 few-shot classifier를 구현해 비교했습니다. 확실히 zero-shot이 모든 dataset에서 더 data 효율성을 보여줍니다.
Robustness to natural distribution shift
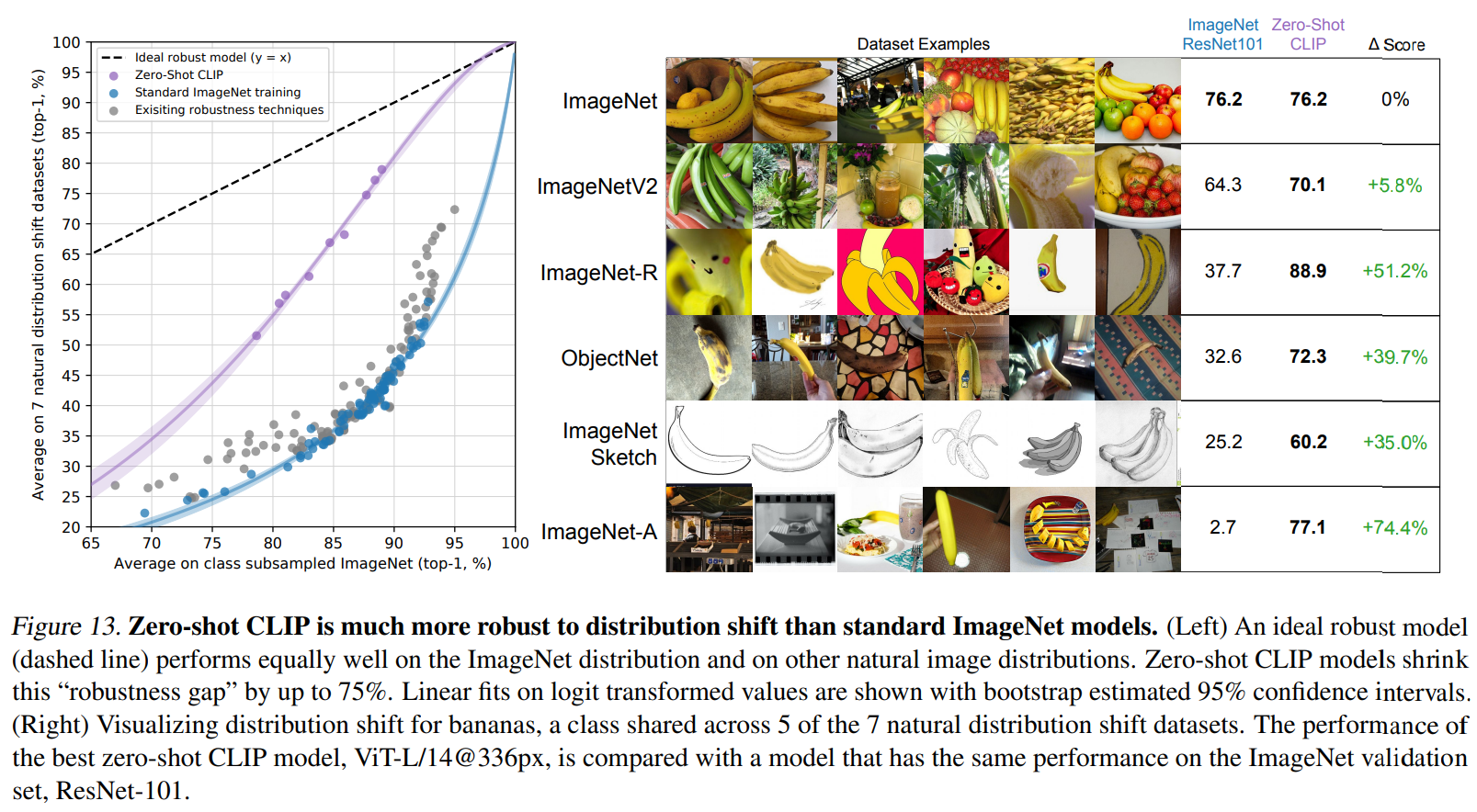
이번에는 model의 강건함에 대해 비교합니다. 그래서 저자들은 zero-shot CLIP과 ImageNet model과 비교합니다. 이때 natural distribution shift에 대해 정확도를 비교합니다. 이상적인 robustness model의 경우, natural distribution shift가 있든 없든 성능이 비슷해야 합니다. 그래서 위 그래프에 점선은 ideal한 model을 의미합니다. natural distribution shift는 위 그림과 같이 banana image가 다양하게 변형된 모습을 의미합니다. 이러한 상황에서도 CLIP's zero-shot classifier는 좋은 결과를 보여줍니다. 특히 original image에서 많은 변화가 있을 때, ImageNet의 성능은 큰 폭으로 감소하지만 CLIP's zero-shot classifier는 크게 떨어지지 않는 모습을 보여줍니다. 이를 통해 CLIP zero-shot은 더 강건하며, 일반화된 표현을 (image, text)를 통해 학습한다는 것을 알 수 있습니다.
Conclusion
Advantages
- 다양한 image와 text data에 대한 이해력이 좋습니다. CLIP은 대규모 image와 text pair를 통해 학습되며, 이를 통해 다양한 유형의 image와 관련된 text를 이해하는 능력을 갖춥니다.
- Zero-shot 능력이 좋습니다. CLIP은 zero-shot을 통해 본 적 없는 새로운 data에 대해서도 classification 및 recognition task를 수행할 수 있습니다. 이를 통해 새로운 condition에 빠르게 적응할 수 있으며, 학습 없이도 효과적으로 task를 수행할 수 있습니다.
- natural language model과 image model의 결합입니다. CLIP은 image 인식과 natural language 처리를 결합하여, image에 대한 설명을 natural language로 생성할 수 있습니다. 반대로 text를 통해 image를 분류하는 등의 task를 수행할 수 있습니다.
- 대규모 dataset을 효율적으로 학습할 수 있는 방법을 제안했습니다.
- 다양한 task에 대해 flexible합니다. CLIP은 image classification, object detection 등 다양한 computer vision task에 적용될 수 있습니다.
Disadvantages
- CLIP의 zero-shot 성능의 한계가 존재합니다. 어느 정도의 zero shot 성능을 보여주긴 하지만, 다른 방식들에 비해 성능이 떨어지는 모습을 보이기도 합니다. 특히 복잡하거나 세부적인 classification task에서는 한계가 드러날 수 있습니다.
- 대규모 dataset의 의존성이 존재합니다. CLIP을 효과적으로 학습하기 위해선 대규모 image, text pair dataset이 필요합니다.
- CLIP은 computation & resource cost가 많이 필요합니다.
- 수집한 대규모 dataset에 따라 결과가 달라집니다. internet에서 모은 image, text pair dataset에 내재된 사회적 편향을 학습할 위험이 있습니다. 이를 통해 model이 편향된 output을 생성할 수 있습니다.
'연구실 공부' 카테고리의 다른 글
| spectrum, spectrogram, Mel-spectrogram, MFCC (0) | 2024.02.27 |
|---|---|
| [논문] Learning Strides in Convolutional Neural Network (0) | 2024.02.25 |
| [논문] LoRA: Low-Rank Adaptation of Large Language Models (0) | 2024.02.20 |
| [논문] Deep Residual Learning for Image Recognition (0) | 2024.02.19 |
| [논문] Generative Adversarial Net (0) | 2024.02.17 |



