https://arxiv.org/abs/2106.09685
LoRA: Low-Rank Adaptation of Large Language Models
An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes le
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
자연어 처리 분야에서 중요한 패러다임 중 하나는 general domain data로 대규모 pretraining과 특정한 task 또는 domain으로 adaptation하는 것으로 이루어져 있습니다. 더 큰 model을 pre-train한다면, model의 전체 parameter를 재학습하는 full fine-tuning은 덜 용이해집니다. 예를 들어 GPT-3 175B의 경우, 175B개의 parameter를 학습해야 하며, 이에 대한 cost는 매우 높습니다. 그래서 저자들은 Low-Rank Adaptation(LoRA)를 제안합니다. 이는 pretrained model의 weight를 고정시키고, transformer architecture의 각 layer에 학습가능한 rank decomposition matrices을 적용하여 학습해야 할 parameter 수를 크게 줄이는 방식입니다. GPT-3 175B를 Adam으로 fine-tuning하는 것과 비교했을 때, LoRA는 학습해야 할 parameter 수를 10,000배 줄일 수 있습니다. 그리고 GPU memory는 3배 줄일 수 있습니다. LoRA는 fine-tuning보다 더 적은 parameter를 학습하지만, 동등하거나 더 나은 성능을 보여줍니다.
Introduction
많은 자연어 처리 방식들은 1개의 large scale, pretrained language model을 이용해 특정 task 또는 문제에 adapting합니다. 이러한 adaptation은 주로 fine-tuning을 통해 진행됩니다. fine-tuning은 pre-trained model의 전체 parameter를 update합니다. 이러한 fine-tuning의 주된 문제는 새로운 model이 original model과 동일한 parameter를 갖는다는 점입니다. GPT-3의 경우 1750억 개의 parameter를 가지기 때문에 큰 문제가 됩니다.
그래서 이러한 문제를 해결하기 위해 몇 개의 parameter만 adapting하거나 추가적인 module을 이용해 새로운 task에 적용하는 방식이 등장했습니다. 이러한 방식들은, 각 task에 대해 pretrained model 외에 각 task에 맞는 적은 수의 parameter를 저장하고 load 하기 때문에 배포 시 상당한 효율성을 보입니다.
그러나, 기존 기술들은 model의 depth를 늘리거나 사용 가능한 sequence의 길이를 줄여 inference 지연을 보이는 경향이 있으며, 종종 fine-tuning보다 성능이 떨어지는 모습을 보이곤 합니다. 저자들은 이러한 문제를 해결하기 위해 LoRA를 제시합니다.
저자들은 과도하게 parameterized된 model이 실제로는 낮은 내재된 차원(intrinsitc dimension, 복잡한 data나 model이 사실은 더 간단한 구조를 가지고 있으며, 이를 적은 수의 차원으로도 충분히 설명할 수 있다는 개념, 고차원 data가 실제로는 낮은 차원의 manifold에 위치할 수 있음을 의미)에 위치한다는 연구에서 영감을 받아 LoRA를 개발했습니다. 저자들은 model adaptation 동안 weight의 변화 또한 낮은 intrinsic rank를 갖는다고 가정했으며, 이를 통해 Low-Rank Adaptation(LoRA)를 제안합니다.

LoRA는 adaptation 할 때 pretrained weight를 고정된 상태로 유지하지만, dense layer의 weight의 rank decomposition matrices를 최적화함으로써 기존 pretrained model에 존재하는 dense layer의 weight를 간접적으로 학습할 수 있습니다.
즉 adaptation할 때, pre-trained weight W는 고정시켜 둡니다. 그중 직접적으로 update하진 않지만, 학습에 사용할 weight를 몇 개 선택합니다. 이 weight들은 변하지 않습니다. 해당 weight matrix의 크기를 dxd라고 하겠습니다. 우리는 해당 weight matrix를 low rank로 decomposition하는 것이 목적입니다. 이를 위해 weight matrix의 input을 r차원으로 축소시키는 A matrix를 이용합니다. A matrix의 크기는 dxr입니다. 그다음 다시 weight matrix와 크기를 맞추기 위해 B matrix를 곱합니다. B matrix의 크기는 rxd입니다. 그렇게 최종 output을 구해 original weight matrix의 output과 더해줍니다. 우리는 학습을 통해 잘 low rank decomposition해주고 복원해 주는 matrix A, B를 찾는 것이 목표입니다. 여기서 r은 d보다 훨씬 작은 차원이며, 이를 통해 학습할 parameter 수를 크게 줄일 수 있습니다.
GPT-3의 경우 전체 rank(위 d)가 12288이지만, 1 또는 2처럼 매우 낮은 rank(위 r)만 이용해 tuning 해도 충분하며, 저장 공간과 계산 효율성 측면에서 매우 효과적입니다.
LoRA는 pre-trained model을 공유할 수 있으며, 여러 개의 작은 LoRA module을 build하여 다양한 task에 사용할 수 있습니다. 그리고 공유된 model(pre-trained model)을 고정시킨 상태로 matrices A와 B만 변경하여 task를 효과적으로 변환할 수 있습니다. 그리고 LoRA는 학습을 더 효율적으로 만들어주고 하드웨어가 매우 많이 필요하지는 않습니다. 그리고 간단한 linear design이기 때문에 full fine-tuning model에 비해 inference latency가 생기지 않습니다.
앞으로 transformer architecture에 대해 다룰 것이기 때문에 transformer의 차원들에 대한 표현법을 정의하겠습니다. input과 output dimension size를 d_model이라 하겠습니다. self-attention module에 존재하는 W_q, W_k, W_v, W_o는 query/key/value/output projection matrices를 의미합니다. W 또는 W_0는 pretrained weight matrix를 나타내며, ΔW는 adaptation 과정에서 gradient update를 의미합니다. r은 LoRA module의 rank를 나타냅니다. 그리고 transformer MLP feed forward dimension은 d_model의 4배로 설정합니다.
Related work
Prompt engineering and fine-tuning
GPT-3 175B는 몇 개의 추가적인 training example만 사용하여 adaptation할 수 있지만, 결과는 input prompt에 크게 의존적입니다. 그래서 원하는 task에서 model의 성능을 향상시키기 위해 prompt를 구성하고 형식을 지정하는 기술을 필요로 합니다. fine-tuning은 일반적인 domain에서 pre-train된 model을 특정 task에 맞추기 위해 다시 학습하는 것을 의미합니다. 그러나 GPT-3 175B의 크기는 pre-training 시와 동일한 memory 사용량을 요구하므로, 일반적인 fine-tuning을 수행하기 어렵습니다.
Parameter-efficient adaptation
neural network에 존재하는 layer 사이에 adapter layer를 추가하는 연구들이 많이 존재합니다. 저자들의 방식은 low rank 제약을 weight update 시 부과합니다. 저자들의 방식에서 학습된 weight는 inference 과정에 main weight와 합쳐질 수 있으며, adapter layer를 사용하는 것과 달리 추가적인 latency가 존재하지 않습니다. 최근에는 fine-tuning 대신 input words embedding을 최적화하는 방법이 제안되었습니다.
Low-rank structures in deep learning
low-rank 구조는 machine learning에서 매우 흔합니다. 많은 machine learning 문제들은 특정한 intrinsic low-rank structure를 갖습니다. 게다가, 많은 deep learning task에서 사용되고 있으며 특히 매우 over parameterized된 neural network을 사용하는 deep learning task에서는 train된 neural network가 train 후 low rank 속성을 갖게 됩니다. 몇몇 이전 연구들에서 origina neural network를 학습할 때 low-rank 제약을 부여했습니다. 하지만 pre-trained model에 low rank update를 사용하여 downstream task에 adaptation하는 연구는 존재하지 않았습니다.
Problem Statement
저자들이 제안한 방식은 train 목적에 구애받지 않지만, 저자들은 language modeling에 focus를 맞춰 설명한다고 합니다. language modeling problem은 task-specific prompt가 주어졌을 때에 대한 조건부 확률을 maximize하는 것에 관련 있습니다. 그래서 task-specific prompt가 주어졌을 때에 대한 조건부 확률을 maximize하는 것에 대해 알아보겠습니다.
parameter Φ로 이루어진 pre-trained autoregressive language model P_Φ(y|x)가 주어졌다고 가정하겠습니다. 예를 들어 P_Φ(y|x)는 GPT처럼 transformer architecture를 기반으로 하는 multi-task learner로 볼 수 있습니다. 이때, 이 pre-trained model을 조건부 text generation task(summarization, machine reading comprehension, natural language to SQL 등)에 adaptation해야 하는 상황이라고 보겠습니다. 각 task는 context-target 쌍으로 이루어진 train dataset으로 표현될 수 있습니다. context-target 쌍은 Z = {(x-i, y_i}_i = 1, ... , N이고 x_i와 y_i는 token sequence입니다. 예를 들어 NL2SQL의 경우, x_i는 natural language query이며, y_i는 이에 대응하는 SQL command입니다. summarization의 경우, x_i는 기사의 내용을 의미하고 y_i는 그에 맞는 요약을 의미합니다. full fine-tuning을 하는 동안에, model은 pre-trained weight Φ_0로 초기화되고 Φ_0 + ΔΦ로 update됩니다. 그리고 conditional language modeling objective를 maximize하기 위해 기울기를 따라 반복적으로 Φ_0 + ΔΦ를 update해 나갑니다.
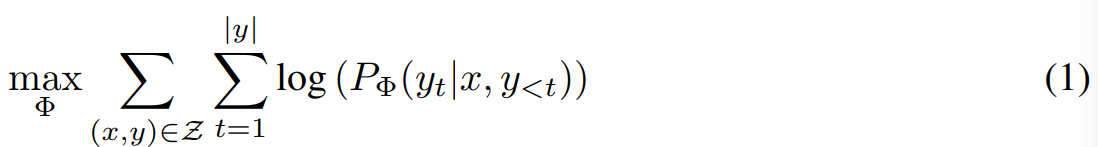
full fine-tuning의 주된 문제 중 하나로, 각 task에 맞춰 다른 parameter ΔΦ를 학습해야 한다는 점이며, ΔΦ와 Φ_0 의 차원은 동일합니다. 그러므로, pre-trained model의 크기가 크다면, 저장하고 배포하는 데 어려움이 생깁니다.
그래서 저자들은 more parameter-efficient 접근법을 사용합니다. Φ_0보다 훨씬 크기가 작은 parameter θ를 이용해 task-specific parameter를 ΔΦ = ΔΦ(θ) 형태로 encoding하는 방식입니다. 그래서 ΔΦ를 찾는 task가 θ를 최적화하는 형태로 변하게 됩니다.

이제는 computing 및 memory 효율이 높은 low-rank representation을 이용해 ΔΦ를 encoding하는 것을 보이겠습니다. 이러한 방식을 사용하면 GPT-3 175B의 경우, 학습해야 할 parameter 수가 0.01%로 감소되기도 합니다.
Aren't existing solutions good enough?
language model의 경우, 2가지 저명한 효율적인 adaptation 전략이 있습니다. adapter layer를 추가하는 방식과 input layer activation의 형태를 최적화하는 방식이 있습니다. 하지만, 두 방식 모두 한계가 존재하며, 특히 large-scale인 경우와 latency에 예민한 scenario에서 더욱 한계가 명확합니다.
Adapter layers introduce inference latency
현재 여러 종류의 adapter가 존재합니다. 2019년에 등장한 방식에서는, 각 transformer block에 2개 adapter layer가 존재하는 형태입니다. 2020년에 등장한 방식에서는, 각 block에 1개의 layer가 존재하지만 LayerNorm을 추가하는 형태였습니다. layer를 pruning하여 전체 latency를 줄이기도 하지만, adapter layer에서 직접적으로 추가적인 연산을 피하는 방법은 존재하지 않습니다. 물론 adapter layer에 존재하는 parameter 수가 적기 때문에 큰 문제가 되지는 않았습니다. 하지만, large neural network에서는 latency 시간을 줄이기 위해 hardware를 병렬적으로 처리하며, adapter layer는 순차적으로 처리되어야 합니다. 이로 인해 batch size가 일반적으로 작은 online inference에서는 차이가 발생하게 됩니다. 병렬 처리가 없는 model scenario에서는, latency시간이 눈에 띄게 증가됩니다.
Directly optimizing the prompt is hard
prefix tuning은 adapter layer와는 다른 문제점이 있습니다. prefix tuning은 최적화하기 어렵습니다. 그리고 그 성능이 학습 가능한 parameter에 대해 단조적으로 변하는 형태가 아닙니다. 그리고 adaptation을 위해 sequence 길이의 일부를 reserve하면 task를 처리하는 데 사용할 수 있는 sequence의 길이가 무조건 줄어들게 됩니다. 이를 통해 prompt tuning 성능이 떨어집니다.
Our method
저자들은 LoRA의 간단한 design과 이점에 대해 설명합니다. 저자들이 제안한 방식은 deep learning model에 존재하는 어떠한 dense layer에도 적용 가능합니다만, 저자들은 transformer language model에 있는 특정한 weight에 focusing하여 진행합니다.
Low-rank-parametrized update matrices
neural network는 많은 dense layer를 포함하고 있습니다. dense layer에 있는 weight matrices는 full rank입니다. Aghanjanyan et al(2020) 연구에서는 특정 task에 adapting할 때, pre-trained language models은 low intrinsic dimension을 가지고 있으며 더 작은 subspace로의 random projection을 했을 때도 효율적으로 학습할 수 있음을 보였습니다. 그래서 저자들은 adaptation 과정 중에서 weight update도 intrinsic rank가 낮다는 가설을 세웠습니다. pre-trained weight matrix W_0∈R^(dxk)가 있을 때, low-rank decomposition W_0 + ΔW = W_0 + BA 을 이용해 W_0의 update에 제약을 두었습니다. 이때 B∈R^(dxr), A∈R^(rxk)이며, rank r은 min(d, k) 보다 현저히 작은 값입니다. training 중에 W_0는 고정되고 gradient update를 하지 않습니다. 하지만 A와 B는 학습 가능한 parameter를 담고 있습니다.

W_0와 ΔW = BA 둘 다 같은 input을 받아 곱해지며, output vector는 coordinate-wise summation하면 됩니다. 식으로 표현하면 위와 같습니다.
위 그림과 같이, 저자들은 A를 standard gaussian으로 초기화했으며 B는 0으로 초기화했습니다. 그래서 학습을 시작할 때ΔW = BA는 0입니다. 그다음 ΔWx를 α/r로 scale하는데, 여기서 α은 r에 대한 상수입니다(보통 저자들은 r, α을 (8, 16) 또는 (16, 32)로 설정했습니다).

위 형태와 같은 느낌이라고 이해하면 될 것 같습니다.
- A generalization of full fine-tuning
더 일반적인 fine-tuning 형태는 pre-trained parameter의 subset을 학습하도록 하는 것입니다. LoRA는 더 나아가, adaptation 과정에서 weight matrices가 full rank를 갖도록 하기 위해 gradient를 축적하여 update할 필요가 없습니다. 이는 LoRA를 모든 weight matrices와 bias에 적용했을 때, pre-trained weight matrices에 LoRA rank r을 설정함으로써 전체 fine-tuning 표현을 대략적으로 복원할 수 있음을 의미합니다. 즉 다시 말해, trainable parameter 수를 늘리면 LoRA는 original model training으로 대략적인 수렴이 가능합니다. 하지만 adapter-based method는 MLP에 수렴하고 prefix-based method는 긴 input sequence를 처리할 수 없는 model로 수렴합니다.
- No additional inference latency
model을 배포할 때, W = W_0 + BA를 명시적으로 계산하고 저장할 수 있으며 추론을 잘 수행할 수 있습니다. 다른 task로 변환하기 위해선, W_0에서 BA를 빼서 W_0를 복원하고 다른 B'A'를 더해 적은 양의 추가적 memory를 이용하여 빠르게 변환할 수 있습니다. 이는 기존에 존재하는 fine-tunning 방식들에 비해 더 느린 결과를 절대 보이지 않습니다.
Applying LoRA to transformer
transformer architecture의 경우, 4개의 weight matrices(W_q, W_k, W_v, W_o)와 2개의 MLP module로 이루어져 있습니다. 저자들은 W_q와 W_k or W_v만 이용해 adapting을 제한합니다. 즉 다른 weight matrix와 MLP module의 parameter는 그대로 유지합니다. 이를 통해 adaptation이 간단해지고 parameter-efficiency해집니다.
이와 같은 방식으로 LoRA를 적용했을 때, VRAM 사용량을 최대 2/3까지 줄일 수 있었습니다. GPT-3 175B의 경우, 학습할 때 1.2TB 크기의 VRAM을 사용했는데, adaptation 시 350GB까지 줄일 수 있었습니다.
그리고 배포 중에 task를 변환할 때, LoRA weight만 변경하여 훨씬 저렴한 cost로 진행할 수 있었습니다. 그리고 전체 fine-tuning을 진행했을 때보다 25% 속도 향상을 보였습니다.
Experiments

저자들은 large language model을 다양한 fine-tuning technique을 이용해 결과를 비교합니다. 위 표는 GLUE benchmark score입니다. 적은 수의 parameter로 좋은 결과를 보이는 것을 알 수 있습니다.

GPT-2에 대한 fine tuning technique 결과입니다. 적은 수의 parameter로 좋은 성능을 내는 것을 알 수 있습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Learning Strides in Convolutional Neural Network (0) | 2024.02.25 |
|---|---|
| [논문] Learning Transferable Visual Models from Language Supervision (0) | 2024.02.22 |
| [논문] Deep Residual Learning for Image Recognition (0) | 2024.02.19 |
| [논문] Generative Adversarial Net (0) | 2024.02.17 |
| [논문] Large-Scale Self-Supervised Speech Representation Learning for Automatic Speaker Verification (0) | 2024.02.08 |



