source filtering model이란, 사람이 말을 하는 과정을 그대로 수학적으로 modeling하는 방식을 의미합니다.
사람의 음성은 폐에서 시작된 신호가 발생기관(성대)을 통과하면서 주기적 신호로 만들어지고, vocal tract(성도)를 거치며 조음을 통해 만들어 지게 됩니다.

그림으로 표현하면 위와 같습니다. 폐로부터 만들어진 공기가 성대를 통과하여 주기적인 신호를 갖는 공기의 흐름으로 바뀌는데, 이때 일정한 주파수를 갖고 떨린다면 이를 fundamental frequency(기본 주파수)라고 부릅니다.
또한 성대에서 만들어진 signal이나 noise와 같은 신호를 excitation이라고 부르게 됩니다.
Vocal fold(성대)는 진동을 하며 harmonics(배음)와 noise를 만들게 되고, 이때 harmonics을 voiced sound, noise를 unvoices sound라 합니다. 위 그림에서 vocal fold로부터 발생한 source spectrum을 보면, 가장 큰 amplitude를 가진 수파수를 fundamental frequency(f_0)라 합니다. 그 이후 주파수들은 기본 주파수의 배음들인 harmonics입니다. 기본 주파수 f_0 이후 신호들은 발음 기관의 특성에 따라 고주파로 갈수록 amplitude가 작아지는 것을 볼 수 있습니다.
Vocal tract(성도)는 성대에서 생성된 source를 통과시켜 보낼 때, 해당 기관의 형태에 따라 말하고자 하는 음성의 형태를 결정합니다. 이때, 인두(pharynx), 구강 (oral cavity), 비강(nasal cavity)가 해당 기관에 포함됩니다. 그래서 vocal tract의 경우 수학적으로 filter의 역할을 가지게 됩니다. 소리는 vocal tract를 지나며 formant(소리가 공명되는 특정 주파수)를 만나 소리가 증폭되거나 감쇠되는데, 해당 formant들을 연결한 것이 spectrum envelope이라는 포락선입니다. 그렇기 때문에 vocal tract는 수학적으로 filter의 역할을 합니다.
최종 output spectrum은 source spectrum이 filter function을 거쳐서 만들어집니다. 성대에서 만들어지는 source model, 각 vocal cord의 filter를 통해 output spectrum을 구할 수 있기 때문에 이 둘을 합쳐 source-filter model이라고 부릅니다.
그럼 이제 source에 대해 알아보겠습니다.
Source: Glottal Waveform
vocal fold(성대)를 거쳐서 나온 voiced sound는 fundamental frequency와 harmonic으로 이루어집니다. 이때 가장 기본적인 주파수를 fundamental frequency(f_0)라 합니다. fundamental frequency는 사람이 느끼는 음의 높낮이(pitch)와는 차이가 있습니다. fundamental frequency와 pitch는 mel-scaled 관계에 있습니다. 즉, 높은 주파수보다 낮은 주파수에서 음의 변화를 잘 구분하는 인간의 귀에 맞추어 mel-scale을 씌워 변환시킨 것이 pitch입니다(인간은 주파수 크기와 linear하게 음의 높낮이를 구분하지 않음).
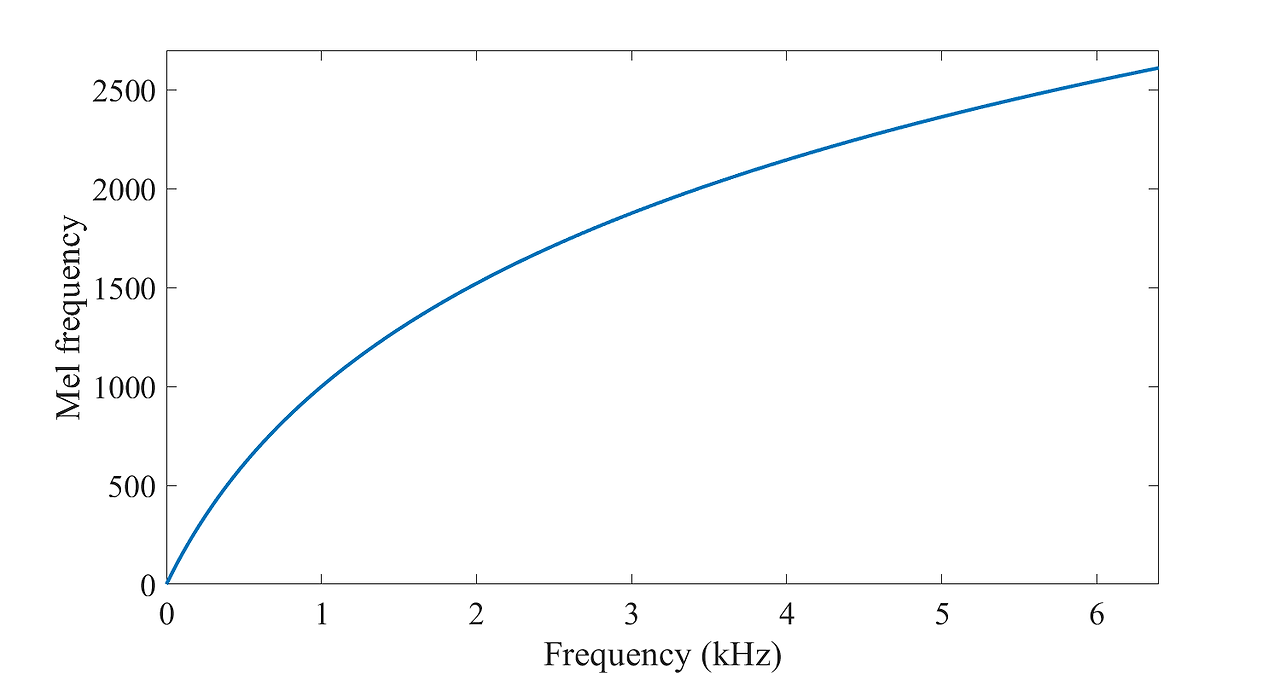
위 그림이 인간의 귀와 같이 저주파에 더 잘 반응하도록 변환시켜주는 mel-scale입니다.
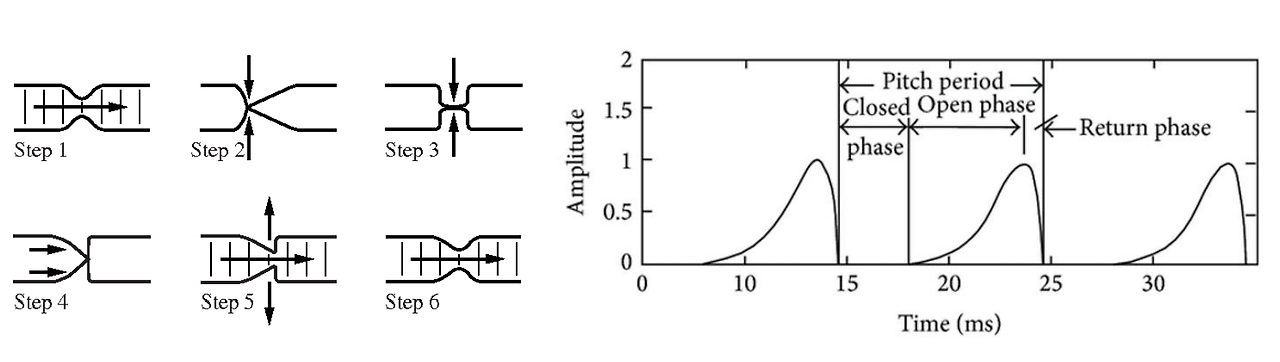
위 그림은 voiced sound가 만들어지는 과정을 그린 모습입니다. voiced sound를 만들 때 성대의 모습과 그때의 소리를 표현한 것입니다. 성대가 열리고 닫히는 과정에서의 통과하는 공기를 시간에 따라 바라본 것입니다.
time domain에서 각 주기별 glottal(glot: 성문) wave form이 형성되는 것을 볼 수 있습니다. glottal wave form은 발성을 어떤 방식으로 하는지(정상, 속삭임, 강제 등)를 나타낼 수 있습니다. 위 그래프에서 pitch period는 한 주기를 나타냅니다. closed phase는 성대가 닫혀있을 때를 의미하며, open phase는 성대가 열려있을 때를 의미합니다.
성대가 열리고 닫히는 하나의 pitch period를 기반으로 전체 glottal wave form은 다음과 같이 수학적 modeling을 할 수 있습니다.
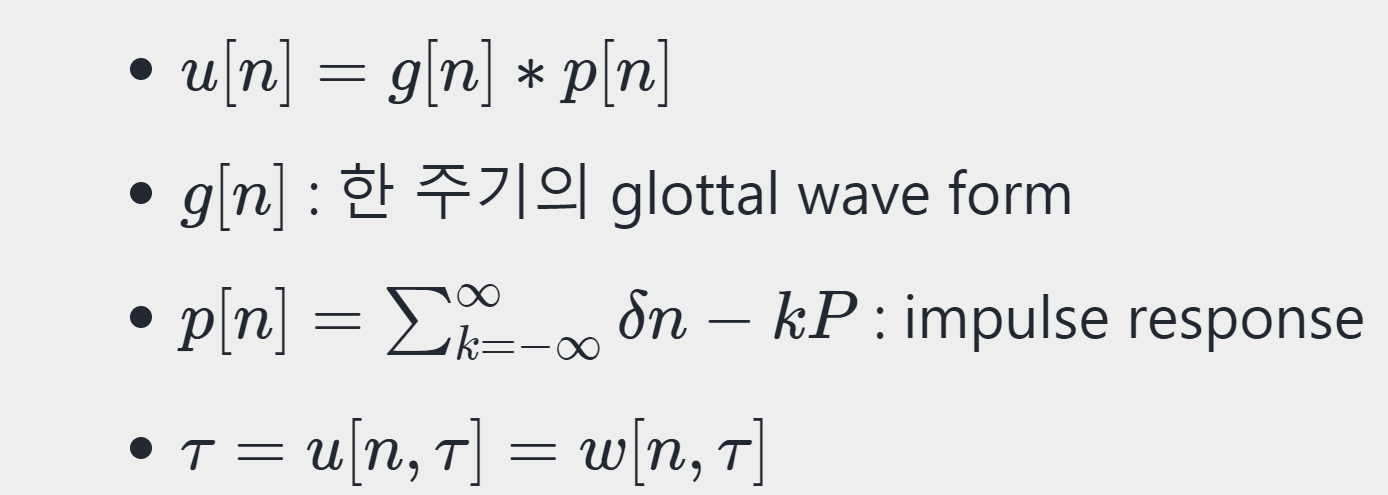
위 식에서 g[n]*p[n]의 의미를 보겠습니다. g[n]은 한 주기의 glottal wave를 나타내며 p[n]은 impuse response입니다. impulse response의 식을 보면 delta function을 사용함을 알 수 있는데, 여기서 delta function은 특정 시점에서 값이 1이 되는 함수입니다. delta function을 shift히면 δ(n - kP)가 되는데, 이는 P 만큼의 주기를 갖는 signal을 kP마다 활성화시켜준다는 것을 의미합니다. g[n]과 p[n]을 convolution하는 것은, input signal(g[n])에 이산화된 각 값 k마다 활성화되는 각 impulse 신호를 convolution하여 해당 함수를 frequency domain에서 분해하여 표현하는 것을 가능하게 해줍니다(즉 한 주기의 glottal wave에 주기성을 갖는 impulse response를 convolution하여 주기성을 갖게 만들며, frequency domain으로의 분해가 가능해짐). 한 주기의 glottal wave와 impuse response를 convolution하여 glottal wave form u[n]을 modeling할 수 있습니다.
Filter
source-filter model에서 filter 역할을 하는 vocal tract에 대해 보겠습니다.
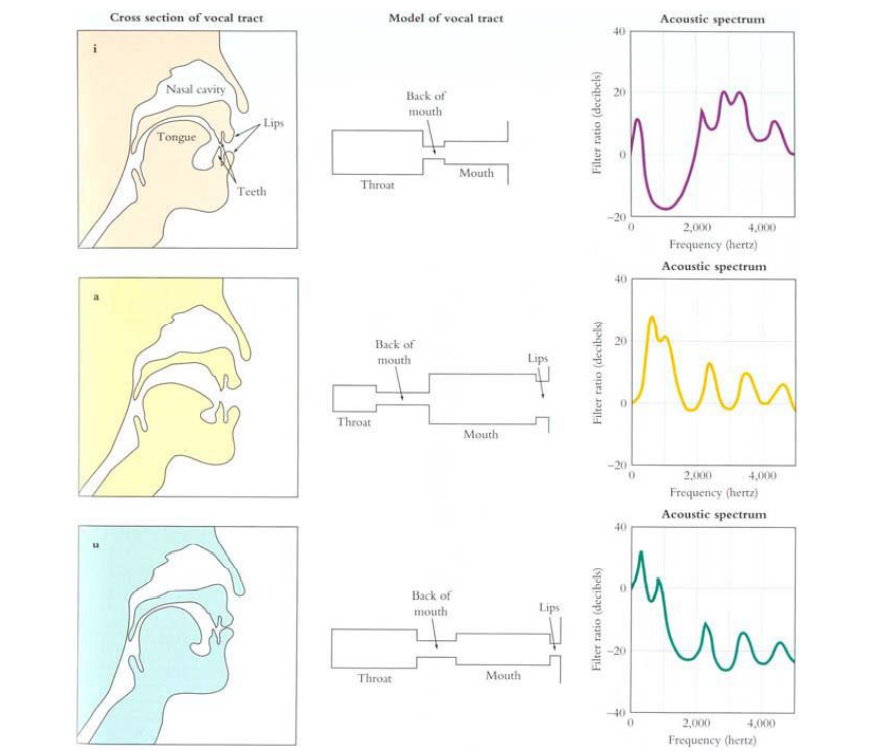
위 그림과 같이 vocal-tract의 구조를 tube 형태로 근사시켰을 때, 각 tract의 형태에 따라 공진주파수(response frequency)가 변하게 됩니다. 각 filter의 형태는 극점들만 이용한 all-pole model로 근사할 수 있는데, 이때 transfer function의 각 극점들을 통해 formant를 측정할 수 있습니다. fundamental frequency의 경우, 음의 높낮이를 결정하는 특성(source)를 나타내며 formant의 경우는 어떠한 소리를 만들 것인가에 대해 영향을 줍니다.
source의 signal이 filter를 거쳐 나오는 output은 X[n]이며 아래 식과 같습니다.

Fourier transform을 통해 frequency domain에서 보면 다음과 같습니다.
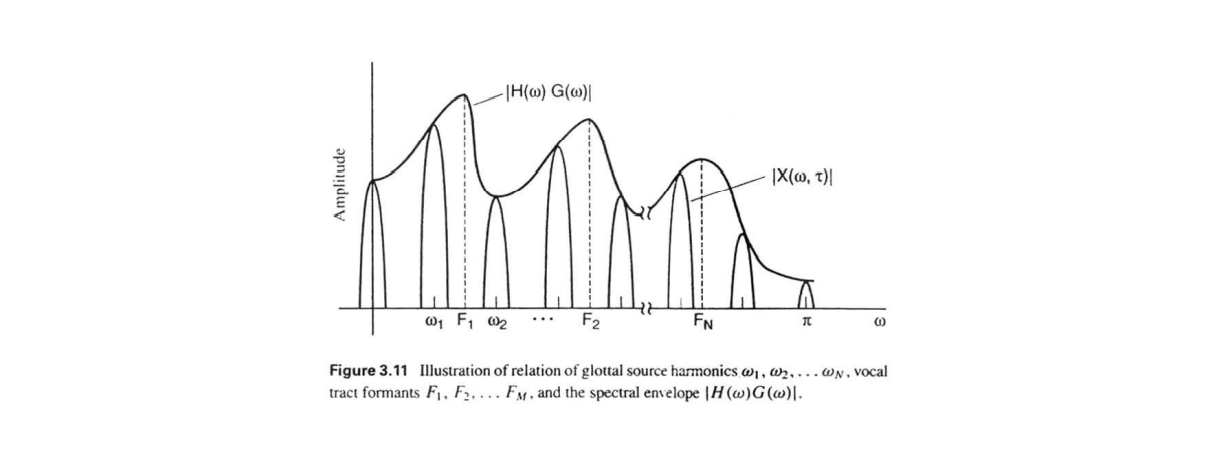
Frequency domain에서 각 frequency의 성분 크기는 높낮이가 다른 주기 함수꼴로 나타나져 있습니다. 기본적으로 source는 p[n]이나 noise로 modeling됩니다. 하지만 여기선 vocal tract에서 나온 h[n]을 추정해야하며 이를 추정해야 source-filter modeling을 할 수 있습니다.
그래서 filter를 추정해야 합니다. 여기서 h[n](impulse response)은 어떤 신호에서 활성화되는 값들이라고 할 수 있습니다.
즉, 이 값을 알면 filter function을 알 수 있게 됩니다. 특정 신호에서 활성화된 값이니, h[n]을 안다면 어떤 function을 거쳐 그런 output이 나왔는지 구할 수 있기 때문입니다.
즉, 우리는 filter가 all-pole model이라고 근사를 한 상태입니다. 이 상태에서 impulse signal이 들어와 filter를 거쳐서 나온 output이 impulse response h[n]입니다. h[n]을 알면 우리는 근사했던 filter를 구할 수 있게 됩니다.
Linear prediction analysis
source-filter model의 filter를 linear prediction analysis로 구하는 방법에 대해 알아보겠습니다. filter는 all-pole model로 근사가 가능하며, 각각의 peak들로 인해 formant가 구성됩니다. pole zero model에서 영점인 zero는 입술로 인한 진동, 비음 등의 상대적인 noise signal입니다. 그래서 all-pole model을 사용해 근사를 하는 linear prediction analysis는 비음, 파열음 등을 표현하는 데에 약점이 있습니다.
filter를 all-pole model로 근사한 상태이며, 해당 all-pole model을 통해 filter H(z) 값을 추정합니다. 방법은 다음과 같습니다.

model을 time domain에서 나타낸 s[n]의 현재 값은 이전 time들의 linear combination을 통해 계산됩니다. 이와 같이 현 시점의 sample을 이전 time들의 관계값으로 나타내는 것이 auto-regressive model이라 합니다.
linear predictive coding(LPC)에서는 n에서의 s[n]을 추정하는 predictor를 기반으로 prediction error를 줄여나가는 방향으로 envelope function을 추정했습니다. s[n]을 추정했을 때의 error를 줄이기 위해서 mean square error를 minimize하는 방식을 사용합니다. 위 식에서 P는 얼마나 많은 이전 time을 볼 것인지를 나타내는 값입니다. 여기서 s[n]을 추정한다는 것은, source-filter의 output인 s[n]을 추정하여 구한 후 filter인 H(z)를 추정하는 것입니다.
그럼 추정을 할 때, P를 최대한 크게 하여 최대한 많은 이전 시간의 정보를 가지고 추정하는 것이 좋을 것 같지만, 오히려 overfitting된 결과를 얻기도 합니다. 즉 LPC의 차수를 너무 높게 잡는 것 보단, 10에서 20 정도의 차수로 설정하는 것이 좋다고 합니다.

그래프 (d)를 보면 overfitting된 것을 볼 수 있습니다.
Cepstrum analysis
source-filter model의 filter를 cepstrum analysis를 통해 구하는 방법입니다.
이 전에 봤던 것과 같이 source-filter model은 source와 filter가 convolution을 통해 합쳐져 있는 형식이었습니다. cepstrum analysis는 convolution으로 합쳐져 있는 신호를 두 신호의 덧셈으로 변경하는 방식입니다.
Linear prediction의 경우 all-pole model을 가정하기 때문에 비음, 입술음, noise 등에 취약하다는 단점이 있었습니다. 하지만 cepstrum analysis는 all-pole model이라는 가정이 없기 때문에 취약점이 없다는 장점이 있습니다.
cepstrum analysis는 signal의 log에 적용하고 inverse DFT를 적용하는 방식입니다.

위와 같습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] WaveGlow: A Flow-Based Generative Network for Speech Synthesis (0) | 2024.03.03 |
|---|---|
| [논문] WaveNet: A Generative Model for Raw Audio (0) | 2024.02.29 |
| 음성학 관련 공부 (0) | 2024.02.27 |
| spectrum, spectrogram, Mel-spectrogram, MFCC (0) | 2024.02.27 |
| [논문] Learning Strides in Convolutional Neural Network (0) | 2024.02.25 |



