https://arxiv.org/abs/1609.03499
WaveNet: A Generative Model for Raw Audio
This paper introduces WaveNet, a deep neural network for generating raw audio waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 raw audio waveform을 생성해 내는 deep neural network인 WaveNet을 소개합니다. WaveNet은 이전의 audio sample을 조건으로 하여 각 audio sample의 분포를 예측하는 확률론적이며 autoregressive model입니다. 저자들이 제시한 model은 초당 수만 개의 sample을 포함한 data에서 효율적으로 훈련될 수 있습니다. text-to-speech에 사용될 때, 당시에 가장 좋은 성능 지표를 보였으며, 이는 청자들이 영어 및 중국어에서 가장 잘 parametric, concatenative system보다 훨씬 더 자연스럽다고 느꼈습니다. 단일 WaveNet은 많은 다른 speaker의 특징을 동일한 정확도로 잡아낼 수 있으며, 각 speaker에 맞는 condition을 조절하여 speaker 전환이 가능하다고 합니다. music modeling을 할 수 있도록 학습할 때, 저자들은 훨씬 더 사실적인 음악적 fragment를 잘 생성하는 것을 알아냈습니다. 또한, 저자들이 제안한 WaveNet은 discriminative model로 사용할 수 있으며 phoneme recognition에 대한 유망한 결과를 return한다는 것도 알아냈습니다.
Introduction
이 논문은 raw audio를 생성하는 기술에 관한 것으로, neural autoregressive generative model에 영감을 받아 제작되었습니다. neural autoregressive model은 image와 text같은 복잡한 분포를 modeling합니다. pixel들 또는 단어들의 결합 분포를 조건부 확률의 곱으로 modeling하는 것은 좋은 성능을 보여줍니다.

이러한 구조는 64x64 pixel과 같은 수 천개의 random variable의 분포를 modeling하는 것을 가능하게 해 줍니다. 이 논문에서 다루는 question은 '이와 같은 접근법들이 적어도 시간당 16000개의 sample을 만들어내는 매우 높은 시간 resolution을 가진 wideband raw audio waveform을 만드는 데도 성공할 수 있을까?'입니다.
이 논문은 WaveNet이라는 PixelCNN 구조를 기반으로하는 audio 생성 model을 소개합니다. 저자들이 제안한 WaveNet의 주된 contribution은 다음과 같습니다.
- WaveNet은 text-to-sppech(TTS) 분야에서 이전에는 본 적 없는 자연스러운(사람들이 평가하기에) raw speech signal을 생성할 수 있습니다.
- raw audio 생성에 필요한 장기간 시간 의존도를 다루기 위해 저자들은 dilated causal convolution을 기반으로 하는 새로운 architecture를 개발했습니다. dilated causal convolution은 매우 넓은 receptive field를 갖습니다.
- speaker identity를 조건으로 받았을 때, 단일 model을 사용하여 다양한 voice를 생성하는 데 사용될 수 있습니다.
- small speech recognition dataset에서 test했을 때, 상당히 뛰어난 결과를 보이며, 음악과 같은 다른 audio modality를 생성하는 데 사용될 수 있습니다.
저자들은 WaveNet이 audio generation에 의존되는 다양한 application을 처리할 수 있는 일반적이고 유연한 framework를 제공할 수 있다고 생각합니다.
WaveNet
저자들이 제안한 WaveNet은 raw audio waveform에 직접 작동하는 새로운 생성 모델을 소개합니다. waveform x = {x_1, ... , x_T}의 결합 확률은 조건부 확률의 곱으로 분해됩니다. 다음과 같습니다.
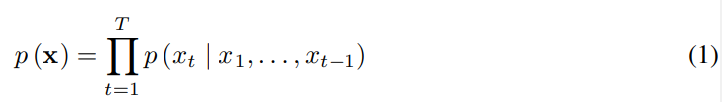
각 audio sample x_i는 이전에 존재하는 모든 timestep의 sample을 condition으로 하게 됩니다. PixelCNNs와 유사하게 조건부 확률 분포는 convolutional layer의 stack으로 modelling될 수 있습니다. network에는 pooling layer가 존재하지 않고, model의 output은 input의 time dimension과 동일한 크기입니다. model은 softmax layer를 이용해 다음 value인 x_t에 대한 범주형 분포를 출력하며, data의 log likelihood를 parameter에 대해 최대화하도록 최적화됩니다(p(y|parameter)를 maximize). log likelihood는 계산 가능하기 때문에, 저자들은 validation set을 이용해 hyperparameter를 조정하고 model이 overfitting인지 underfittung인지 쉽게 측정할 수 있습니다.
Dilated Causal Convolutions

WaveNet의 주요 구성 요소는 causal convolution입니다. causal convolution을 사용함으로써, data를 modeling할 때 순서를 위반하는 일을 막을 수 있습니다. timestep t에서 model에 의해 구해진 예측 p(x_(t+1) | x_1, ... , x_t)은 미래의 시간 단계(x_(t+1), x_(t+2) , ... x_T)에 의해 영향을 받지 않습니다. 위 그림과 같이 이전 timestep만 이용해 현재 timestep의 output을 만들어내는 방식입니다. image의 경우, causal convolution 대신 masked convolution을 사용할 수 있으며, masked convolution은 mask tensor를 만들고 mask와 convolution kernel의 elementwise 곱셈을 한 후 적용하는 방식입니다. audio와 같은 1D data는 몇 개의 timestep만큼 normal convolution의 output을 shifting함으로써 이를 더 쉽게 적용할 수 있습니다.
학습할 때, 모든 timestep에 대한 조건부 예측은 병렬적으로 구할 수 있습니다. 왜냐하면, 모든 timestep의 ground truth x를 이미 알고 있기 때문입니다. model을 이용해 생성할 때, 예측기는 순차적입니다. 각 sample이 예측된 후에, 최종 output을 network의 input으로 넣어 다음 sample을 예측해야 합니다.
causal convolution이 recurrent connection이 없기 때문에, RNN에 비해 학습 속도가 빠르며 특히 긴 sequence에서 더 그렇습니다. causal convolution의 문제 중 하나는 receptive field를 증가시키기 위해 layer를 많이 사용하거나 large filter가 필요하다는 점입니다.
위 그림과 같다고 생각할 때, receptive field는 5입니다(layer 수 + filter length -1). 이 논문에서 저자들은 dilated convolution을 이용해 연산량을 크게 늘리지 않고 receptive field를 수십 배 증가시킵니다.
dilated convoltuoin은 filter가 특정 step을 skip함으로써 filter의 lenth보다 더 넓은 영역에 적용되는 convolution 방식입니다. 이는 원본 filter를 0으로 확장하여 더 큰 filter로 만든 convolution과 동등하지만 훨씬 효과적입니다. dilated convolution은 효과적으로 network가 일반 convolution보다 더 coarser scale에서 동작할 수 있도록 만들어 줍니다. 이는 pooling 또는 strided convolution과 유사하지만, input과 동일한 크기의 output을 만듭니다.
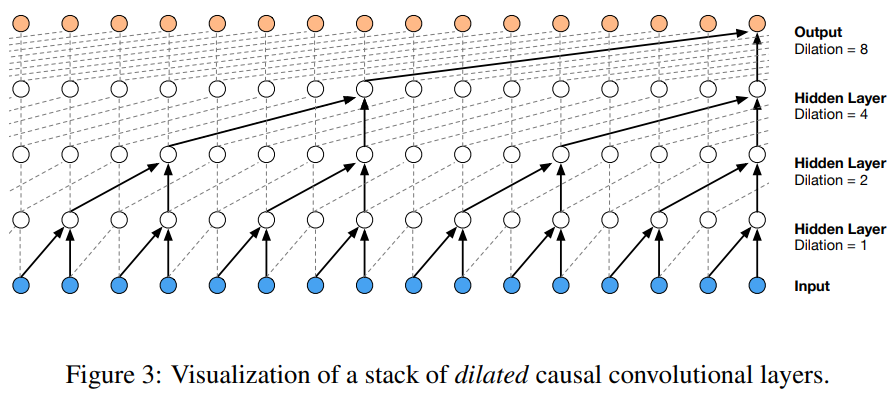
dilation 1을 가진 dilated convolution은 standard convolution과 동일합니다. 위 그림은 dilated causal convolution의 dilation은 1, 2, 4, 8로 설정한 예시입니다. dilated convolution은 다양한 context(신호처리, image segmentation 등)에서 사용되어 왔습니다.
쌓아진 dilated convolution은 network가 적은 수의 layer로도 매우 넓은 receptive field를 갖도록 만들어주며, input resolution을 보존하고 연산 효율성도 유지할 수 있습니다. 이 연구에서 dilation은 각 layer를 지날 때마다 2배씩 증가되며, limit에 다다르면 다시 반복합니다. 아래와 같은 방식입니다.

이와 같은 구조를 하는 2가지 직관적 이유가 있습니다.
먼저, dilation factor를 지수적으로 증가하는 것은 receptive field가 depth에 따라 지수적 성장하는 것을 초래할 수 있습니다. 예를 들어, 각 (1, 2, 4, ... , 512) block이 1024 receptive field를 갖습니다. 이는 1x1024 convolution과 비교하여 더 효율적이고 구별력 있는(non-linear) 대안으로 볼 수 있습니다.
그리고, 이러한 block을 쌓는 것은 model의 capacity와 receptive field size를 늘릴 수 있습니다.
이러한 이유로 block을 쌓는 방식으로 구현했습니다.
Softmax Distributions
각 audio sample에 대한 조건부 분포 p(x_t | x_1, x_2, ... , x_(t-1))을 modeling하는 방법 중 하나는 mixture density network나 mixture of conditional Gaussian scale mixtures(MCGSM)과 같은 mixture model을 사용하는 것입니다. 그러나, data가 암묵적으로 연속적일 때(image pixel의 강도 또는 audio sample 값 등) softmax 분포가 더 잘 동작하는 것을 보여준 연구가 있었습니다. 분포에 대한 shape를 가정하지 않기 때문에, categorical distribution(한정된 범주 중 하나에 속할 확률을 modeling하는 분포)이 더 유연하며 임의의 분포를 더 쉽게 model할 수 있어서 softmax distribution이 더 잘 동작합니다.
raw audio가 일반적으로 16-bit 정수 value(timestep의 1개)의 sequence로 저장되어 있기 때문에, softmax layer는 각 timestep마다 65536개의 확률 output을 출력해야 합니다. 이를 더 tractable하게 만들기 위해, 저자들은 data에 μ-law companding transformation을 적용한 후 256개의 가능한 값으로 양자화(raw audio signal을 256개의 구별 가능한 값으로 축소하는 과정을 의미, 이를 통해 더 적은 bit로 표현할 수 있게 됨)합니다.
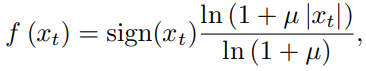
식은 위와 같습니다. 여기서 -1 <x_t <1이고 μ = 255입니다. 여기서 sign()은 부호를 의미합니다. μ-law는 특히 작은 signal에 대해 더 높은 resolution을 제공하고, 큰 signal에 대해서는 낮은 signal을 제공합니다. 이 non-linear 양자화는 일반적인 linear 양자화 방식보다 훨씬 더 뛰어난 reconstruction을 생성합니다. 특히 speech의 경우, 양자화 이후의 reconstructed signal은 original과 매우 유사하게 들립니다.
Gated Activation Units
저자들은 gated PixelCNN에 사용된 gated activation unit과 동일한 gated activation unit을 사용합니다.

위 식과 같습니다. 위 식에서 *은 convolution 연산을 의미하며, ⊙는 element-wise 곱 연산을 의미하며, σ는 sigmoid function을 의미하며, k는 layer의 index를 의미하며, f와 g는 filter와 gate를 의미합니다. W는 학습 가능한 convolution filter를 의미합니다. 저자들의 초기 실험에서, 저자들은 tanh가 ReLU보다 audio signal을 modeling하는 성능이 훨씬 좋다는 것을 알아냈습니다.
Residual and Skip connection
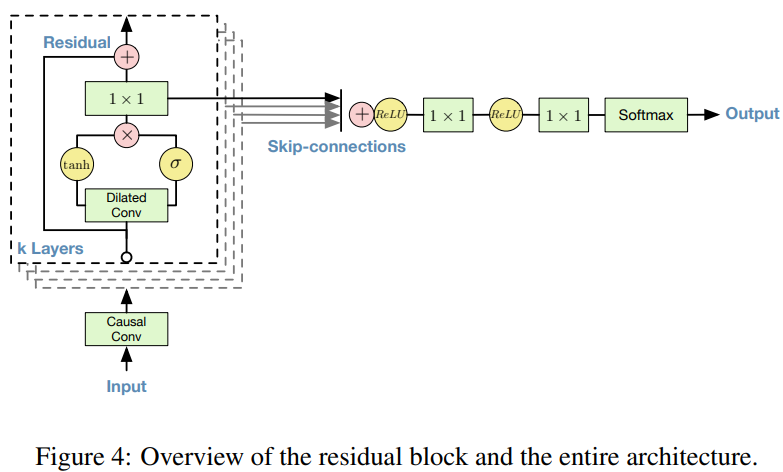
residual과 parameterised skip connection은 network에서 사용되며, 수렴 속도를 높여주고 model의 depth를 늘릴 수 있게 만들어줍니다. 위 그림과 같이 저자들은 residual block을 구현했으며, network에서 여러 번 stack했습니다.
Conditional WaveNets
추가적인 input h가 주어졌을 때, WaveNet은 input으로 주어진 audio의 조건부 분포 p(x|h)를 modeling할 수 있습니다.
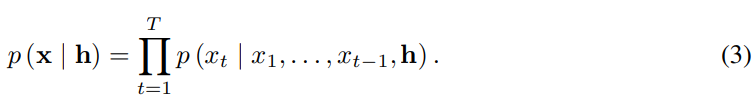
이와 같이 새로운 input h에 대한 조건부 확률을 modeling할 수 있습니다.
다른 input variable을 model의 condition으로 부여함으로써, 저자들은 요구되는 특징을 가진 audio를 생성할 수 있습니다. 예를 들어, multi-speaker setting에서, 저자들은 model에 extra input으로 speaker identity를 넣어 speaker를 고를 수 있습니다. 비슷하게 TTS의 경우, 추가적 input으로 text 정보를 넣어야 합니다.
저자들은 model에 다른 input을 condition하는 2가지 방식을 제안합니다. global conditioning과 local conditioning입니다.
global conditioning은 단일 latent representation h가 모든 timestep에 걸쳐 output distribution에 영향을 주는 방식입니다. 예를 들어 TTS model에 있는 speaker embedding과 같은 경우입니다. activation function은 다음과 같습니다.
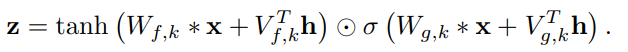
여기서 V_(*, k)는 학습 가능한 linear projecion이며, vector V_(*, k)^Th는 time dimension에 걸쳐 broadcast됩니다.
local conditioning은 audio signal보다 더 낮은 sampling 주파수를 가질 수 있는 두 번째 timeseries h_t를 가지고 진행합니다. 예를 들어 TTS model의 linguistic feature입니다. time series를 tansposed convolution network(learned upsampling)을 이용해 변환합니다. 이는 audio signal과 동일한 resolution을 가지고 있는 새로운 time series y = f(h)로의 mapping을 수행합니다. 그다음 activation unit에 사용됩니다. 식은 다음과 같습니다.
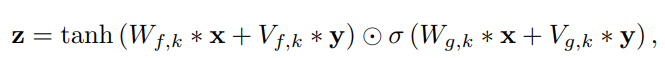
즉 timeseries h_t가 upsampling된 다음 V와 convolution되는 방식입니다. 여기서 V_(f,k) * y는 1x1 convolution입니다. transposed convolutional network를 대신해 V_(f,k) * h를 사용하고 이 값들을 시간에 걸쳐 반복하는 것도 가능합니다. 하지만 실험에서 더 좋지 않은 결과를 얻었습니다.
Context Stacks
WaveNet의 receptive field를 늘리기 위해 몇 가지 방법들에 대해 이미 말했습니다. dilation stage의 수를 늘리거나, 더 많은 layer를 사용하거나, 더 큰 filter를 사용하거나, dilation factor를 키우거나, 이들을 결합하면 됩니다. 보완적인 접근법은 분리된 더 작은 context stack을 사용하는 것입니다. 이는 audio signal의 긴 부분을 처리하고, 더 큰 WaveNet이 audio signal의 더 작은 부분만을 처리하도록 지역적으로 조건을 부여합니다(마지막에 crop). 다양한 길이와 다양한 hidden unit 수를 가진 여러 context stack을 사용할 수 있습니다. 더 넓은 receptive field로 stack한 것은 더 적은 layer가 있으면 됩니다. context stack은 더 낮은 frequency에서 동작할 수 있도록 pooling layer를 가질 수도 있습니다. 이는 요구되는 연산량을 합리적인 수준으로 유지하고, 더 긴 시간 척도에서의 시간적 상관관계를 모델링하는 데 더 적은 용량이 요구됩니다.
Experiments
WaveNet의 audio modeling 성능을 측정하기 위해 저자들은 3가지 task를 평가합니다. multi speaker speech generation(not conditioned on text), TTS, music audio modeling 이렇게 3가지입니다.
Multi-speaker Speech Generation
이 실험에서는 text에 condition이 없는 free-form speech 생성을 합니다. 저자들은 CSTR 음성 복제 도구(VCTK)에서 제공하는 영어 multi-speaker corpus를 사용하고 WaveNet에 speaker에 대한 condition만 부여했습니다. 조건을 주는 것은 speaker ID를 one-hot vector형태로 model에게 feed하여 이행됩니다. dataset은 109명의 speaker로 이루어진 44시간 data로 구성됩니다.
model이 text에 condition하지 않기 때문에, model은 존재하지 않지만 인간의 언어와 비슷한 단어를 현실적인 억양으로 자연스럽게 만들어냅니다. language or image 생성 모델과 비슷하며, 처음에는 현실적으로 보이지만 자세히 살펴보면 비현실적입니다. model의 receptive field의 사이즈(약 300ms)가 한정적이기 때문에 장기적인 일관성의 부족이 생기며, 이는 결국 마지막 2~3개의 phoneme만 기억할 수 있다는 것을 의미합니다.
단일 WaveNet은 one-hot encoding vector를 condition으로 제공받기 때문에 109명의 speaker의 speech를 modeling할 수 있습니다. 즉 단일 model이 dataset에 존재하는 109명의 특성을 충분히 capture할 수 있음을 의미합니다. 저자들은 단일 speaker만 이용하여 학습했을 때보다 speaker를 추가하는 것이 더 좋은 validation set 성능을 보인다는 것을 실험으로 알아냈습니다. 즉 WaveNet의 내부적 representation은 화자 간에 공유된다는 것을 의미합니다.
마지막으로, 저자들은 model이 voice 자체 이외에도 audio의 다른 특성을 포착했다는 것을 알아냈습니다. 예를 들어 speaker의 호흡, 입 움직임뿐만 아니라 음향과 녹음 품질도 모방한 결과를 만들어냈습니다.
Text-To-Speech
이번엔 TTS에 대해 알아보겠습니다. Google's North American English와 Mandarin Chinese로 이루어진 single-speaker speech database를 이용해 TTS system을 만듭니다. North American English dataset은 24.6시간짜리의 speech data를 포함하고 있으며, Mandarin Chinese dataset은 34.8시간을 포함하고 있습니다. 두 dataset은 전문적인 여성 speaker가 녹음했습니다.
TTS에 사용되는 WaveNets은 linguistic feature에 local condition화 되어있으며, linguistic feature는 input text로부터 얻어집니다. 또한, 언어적 특성에 추가로 기본 주파수(log f_0)값을 조건으로 WaveNet에 부여해 학습시켰습니다. linguistic feature로부터 log F_0 값과 음소 지속 시간을 예측하는 추가적인 model을 학습시켰습니다. WaveNet의 receptive field size는 240ms입니다. 저자들은 baseline과 WaveNet을 동일한 dataset과 동일한 linguistic feature를 이용해 학습시켜 음성 합성을 비교했습니다.
TTS task에서의 WaveNet의 성능을 비교하기 위해, subjective paired comparison test와 mean opinion score(MOS) test를 사용했습니다. paired comparison test에서, sample의 각 pair를 들려준 후 어떤 것을 더 선호하는지 선택하라고 했으며, 선호하는 것이 없으면 중립을 선택하라고 했습니다. MOS test에서는, 자연스러운 정도를 (1: bad, 2: poor, 3: fair, 4: good, 5: excellent)로 선택해 달라고 했습니다.

위 그림을 통해 subjective paired comparison test 결과를 확인할 수 있습니다. WaveNet이 baseline보다 두 언어에서 좋은 성능을 보인다는 것을 알 수 있습니다. WaveNet이 linguistic feature condition을 받았을 때 자연스러운 단편적 품질의 음성 샘플을 합성할 수 있었지만, 때때로 문장에서 잘못된 단어를 강조하여 비자연스러운 억양을 가지기도 했습니다. 이는 WaveNet의 receptive field의 크기는 240ms인데, long-term 의존성을 capture하기에 충분히 긴 시간은 아니기 때문입니다. WaveNet이 linguistic feature와 F_0 value를 condition으로 받았을 땐 문제가 없었습니다. 추가적인 F_0 예측 model은 낮은 주파수(200Hz)에서 동작하기 때문에 F_0 contour에 존재하는 long-range 의존성을 학습할 수 있습니다.
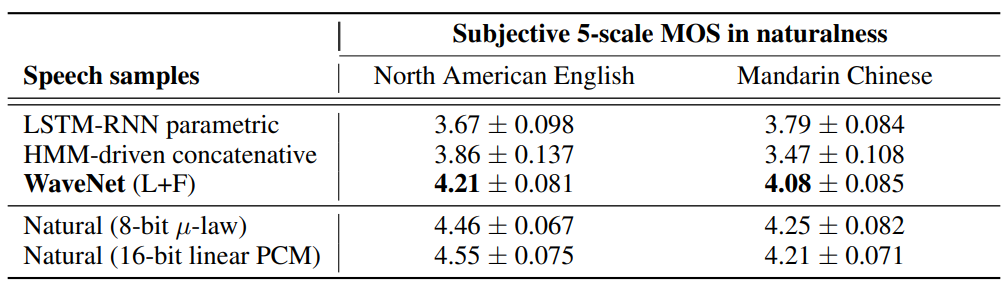
위 table은 MOS test 결과를 보여줍니다. baseline system보다 더 좋은 평가를 받는다는 것을 알 수 있습니다.
Music
저자들은 2가지 music dataset을 이용해 WaveNet을 학습시켰습니다.
MagnaTagAtune dataset과 YouTube piano dataset입니다. MagnaTagAtune dataset은 200시간의 music audio로 이루어져 있습니다. 각 29초 clip은 음악의 장르, 악기, 템포, 볼륨, 분위기를 설명하는 188개의 tag가 주석으로 표시되어 있습니다.
YouTube piano dataset은 60 시간의 solo piano music으로 구성되어 있습니다. 이는 단일 악기이기 때문에, modeling하는 것이 더 용이합니다.
model을 정량적으로 평가하는 데 어려움이 있지만, 주관적인 평가는 가능합니다. 저자들은 receptive field을 확장하는 것이 음악적으로 들리는 sample을 얻는 데 중요하다는 것을 발견했습니다. 몇 초의 receptive field를 가진 model들조차도 장기적인 일관성을 강제하지 않아 장르, 악기 사용, 볼륨 및 음질에서 초마다 변화가 발생할 수 있었습니다(즉 시간이 지남에 따라 일관된 스타일, 장르, 볼륨, 음질 등을 유지 못한다는 뜻). 그럼에도 불구하고 종종 조화롭고 미적으로 만족스러운 결과였으며, 조건 없는 모델에 의해 생성되었을 때도 마찬가지였다고 합니다.
그리고 저자들이 제안한 model은 주어진 condition에 맞춰 음악을 생성할 수 있었습니다. 예를 들어 악기를 지정하거나 장르를 지정하는 방식으로 condition을 부여할 수 있습니다. conditional speech model과 유사하게, 저자들은 training clip에 연관된 binary vector representation을 insert했습니다. 이게 model의 output의 다양한 측면을 다룰 수 있도록 만들어주었다고 합니다.
WaveNet이 생성 모델이긴 하지만, speech recognition과 같이 discriminative audio task에도 충분히 사용할 수 있다고 합니다.
Conclusion
이 논문은 WaveNet을 소개합니다. 이는 audio data를 생성하는 deep 생성 모델이며 이는 waveform level에서 바로 연산하는 방식입니다. WaveNet은 autoregressive하며 causal filter를 dilated convolution과 결합하여 사용합니다. 이를 통해 depth에 따라 receptive field가 지수적으로 증가하게 됩니다. receptive field가 넓어짐에 따라 audio signal의 long-range temporal 의존성을 modeling할 수 있게 됩니다. 저자들은 WaveNet에 global(speaker identity) or local way(linguistic features)을 condition으로 input하는 방법도 보여줍니다.
저자들이 제안한 WaveNet은 당시에 존재하는 TTS system들보다 더 뛰어난 성능을 보여주며, 자연스러운 결과를 보여줍니다. 그리고 WaveNet은 music audio modeling과 speech recognition에 적용했을 때도 매우 유망한 결과를 보여주었습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis (0) | 2024.03.06 |
|---|---|
| [논문] WaveGlow: A Flow-Based Generative Network for Speech Synthesis (0) | 2024.03.03 |
| Source Filtering (0) | 2024.02.27 |
| 음성학 관련 공부 (0) | 2024.02.27 |
| spectrum, spectrogram, Mel-spectrogram, MFCC (0) | 2024.02.27 |



