https://arxiv.org/abs/1910.06711
MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
Previous works (Donahue et al., 2018a; Engel et al., 2019a) have found that generating coherent raw audio waveforms with GANs is challenging. In this paper, we show that it is possible to train GANs reliably to generate high quality coherent waveforms by i
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이전 연구에서는 GAN을 이용해 일관성 있는 raw audio waveform을 생성하는 것이 어렵다고 했습니다. 이 논문에서는, 구조적 변화와 간단한 학습 기술로 고품질의 일관성 있는 waveform을 생성하는 GAN을 연구했습니다. 해당 연구에서 개발한 GAN은 음성 합성, 음악 domain 변환, 음악 합성에서 좋은 결과를 보여줍니다. 연구에서 제안한 model은 non-autoregressive, fully convolutional하고, 다른 model들에 비해 더 적은 parameter로 구성된다고 합니다.
Introduction
raw audio를 modeling하는 것은 data의 높은 temporal resolution(적어도 1초에 16000개의 sample)과 short and long-term dependencies를 가진 다른 timescale에서의 구조가 존재하기 때문에 어렵습니다. 그래서 raw temporal audio를 직접적으로 modeling하는 대신, 대부분의 방법들은 lower-resolution representation을 modelling하여 문제를 단순화합니다. lower-resolution representation을 사용하여 raw temporal signal을 사용했을 때보다 연산적 효율성을 갖게 됩니다. 일반적으로 raw audio를 사용했을 때보다 더 쉽게 modeling할 수 있어야 하며, 충분한 information을 가지고 있어서 audio로 inversion할 수 있는 lower resolution representation을 사용합니다. speech의 경우, linguistic feature 또는 mel-spectrogram을 일반적으로 사용합니다.
audio modelling은 일반적으로 2가지 step으로 나눠집니다. 첫번째, text를 input으로 받아 representation을 modeling합니다. 그다음, representation을 다시 audio로 변환합니다. 이 논문에서는 representation을 다시 audio로 변환하는 것에 focusing합니다. 그리고 저자들은 mel-spectrogram을 이용합니다. 최근에는 mel-spectrogram을 다시 audio로 inversion하는 것은 크게 3가지로 분류됩니다. pure signal processing techniques, autoregressive, non-autoregressive neural network입니다.
Pure signal processing approaches
쉽게 모델화할 수 있고 audio로 변환할 수 있는 저해상도의 audio 표현방법을 찾는 연구들이 진행되었습니다. 예를 들어 Griffin-Lim algorithm은 STFT(Short Time Fourier Transform) sequence를 signal로 decoding할 수 있지만, 비자연스럽게 들린다는 한계가 존재합니다. 그 이후 더 정교한 기술들들이 연구되었습니다. 예를 들어 'WORLD vocoder'가 있습니다. WORLD vocoder는 mel-spectrogram과 유사한 중간 표현을 원본 audio로 mapping하는 신호 처리 algorithm을 사용했습니다. pure signal processing 방식들은 중간 feature를 audio로 mapping하는 것이 주로 눈에 띄는 artifact가 존재한다는 문제가 있습니다.
Autoregressive neural-networs-based models
WaveNet은 fully convolutional autoregressive sequence model이고, 이는 linguistic feature을 부여하여 그에 맞는 매우 real한 음성 sample을 생성합니다. 또한 고품질의 unconditional speech와 음악을 생성할 수 있습니다. SampleRNN은 multi-scale RNN을 사용하여 다양한 시간 해상도에서 unconditional waveform을 생성합니다. 이 외에도 다양한 model들이 존재합니다. 이러한 model들은 text-to-speech synthesis와 다른 audio 생성 task에서 좋은 결과를 보여줍니다. 하지만, autoregressive 방식의 model들은 순차적으로 audio sample을 생성하기 때문에, inference는 본질적으로 느리고 비효율적입니다. 그렇기 때문에 autoregressive model은 실시간 합성에 대해서는 적합하지 않습니다.
Non autoregressive models
최근에는 저해상도의 오디으 표현을 다시 음성으로 변환하는 non-autoregressive model들이 연구되고 있습니다. auto-regressive 에 비해 수십 배 빠른 속도를 보입니다. 왜냐하면 병렬화 하기 용이하고 deep learning hardware들이 개발되었기 때문입니다. Non-autoregressive model을 학습하기 위한 2가지 방법이 등장했습니다.
Parallel Wavenet과 Clarinet은 train된 auto-regressive decoder를 flow-based convolutional student model에 distill합니다. student model은 Kullback-Leibler divergence를 기반으로 하여 distillation 합니다. student model은 KL[P_student | P_teacher]와 추가적인 perceptual loss를 사용하여 학습됩니다. 다른 방식으로 WaveGlow라는 연구도 존재합니다. WaveGlow는 flow-based 생성 model입니다.
GANs for audio
GAN이 computer vision 분야에서 큰 성공을 거둔 반면, audio modelling에서는 자주 사용되지 않았습니다. 2019년 GAN을 이용해 음악적 음색을 생성하는 연구가 등장했습니다. 해당 연구에서는 raw waveform을 직접 modelling하지 않고 STFT의 크기와 위상을 가지고 modelling했습니다. 또 다른 연구에서는 mel-spectrogram을 간단한 크기 spectrogram으로 mapping을 학습하기 위해 GAN을 사용하고, 이를 위상 추정과 결합하여 raw audio waveform을 복원합니다. 다른 연구에서는 raw speech audio를 생성하는 autoregressive model을 distill하기 위해 GAN을 사용하지만, adversarial loss만 사용하는 것이 high quality waveform을 생성하기에 불충분하다는 연구 결과를 얻었습니다.
Main Contribution
- MelGAN은 non-autoregressive feed-forward convolutional 구조이며, audio waveform을 생성할 수 있습니다. 저자들의 연구가 추가적인 distillation 또는 perceptual loss function 없이 성공적으로 raw audio를 생성하는 첫 GAN 연구라고 합니다. MelGAN을 이용해 high quality text-to-speech synthesis를 할 수 있다고 합니다.
- autoregressive model은 빠르고 병렬처리가 가능한 MelGAN decoder에 의해 대체가능하며, music translation, text-to-speech generation, unconditional music synthesis와 같은 다양한 분야에 사용하지만 약간의 품질 저하가 존합니다.
- 또한 MelGAN은 다른 mel-spectrogram inversion 방식들보다 더 빠르다고 합니다. 특히, audio 품질 저하 없이 10배가량 빠른 속도를 보여준다고 합니다.
The MelGAN Model
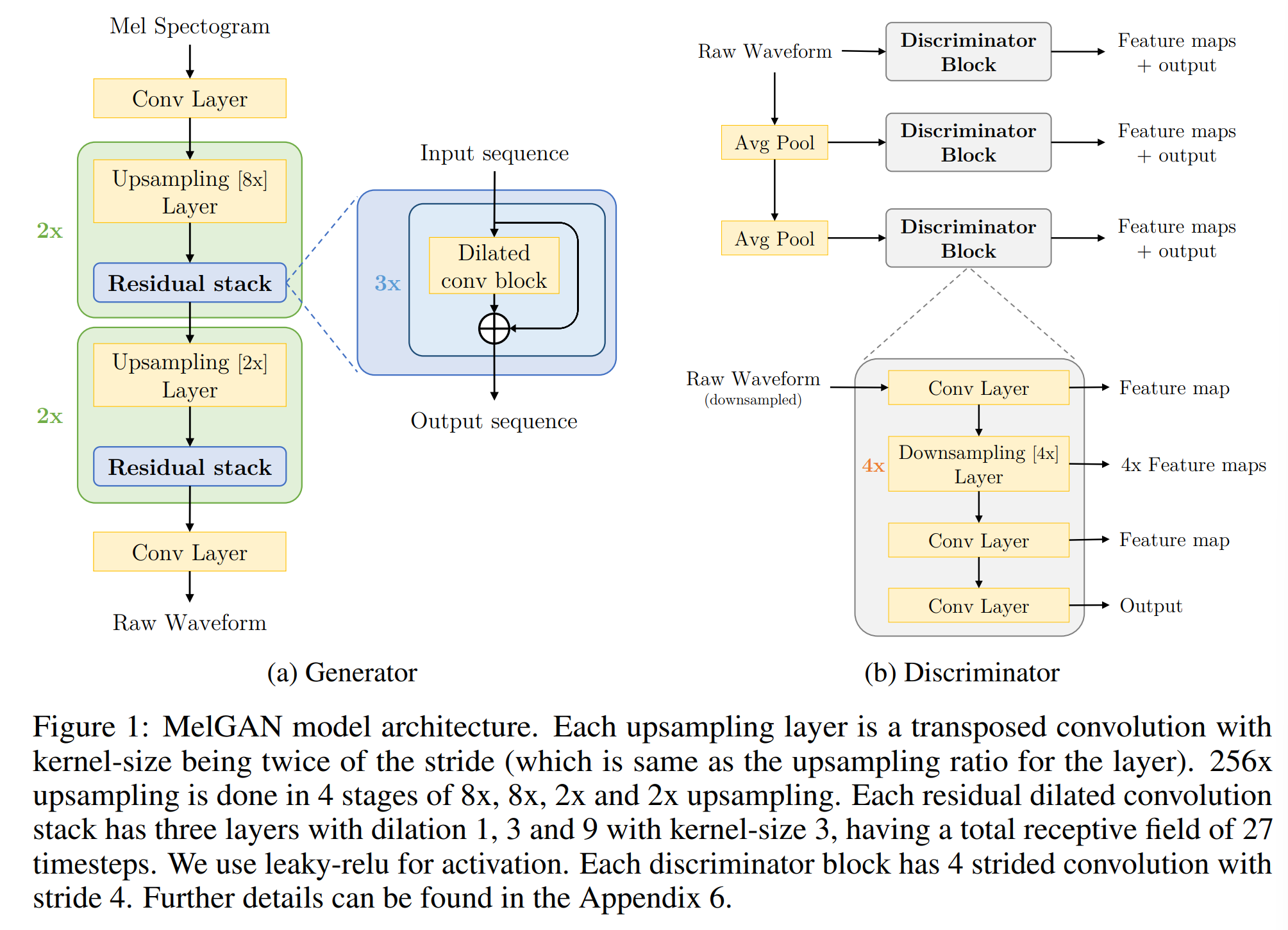
Generator
- Architecture
generator는 fully convolutional feed-forward network 구조이며, mel-spectrogram s를 input으로 사용하고 raw waveform x가 output으로 나옵니다. mel-spectrogram이 시간 해상도가 256배 낮기 때문에, transposed convolutional layer stack을 사용해 input sequence를 upsample합니다. 각 transposed convolutional layer 뒤에 dilated convolution으로 이루어진 residual stack이 붙습니다. 일반적인 GAN과 다르게, generator가 global noise vector를 input으로 사용하지 않습니다. noise가 generator의 input으로 들어갔을 때 생성된 waveform과 차이가 거의 없다는 것을 발견했습니다.
- Induced receptive field
image를 생성하는 convolutional neural network 기반 generator의 경우, 인접한 pixel들이 induced receptive field가 많이 겹치기 때문에 상관관계가 있다는 inductive bias가 존재합니다. induced receptive field가 겹치는 이유는, kernel들과 계산되는 pixel들이 겹치기도 하고, layer가 깊어질수록 많은 kernel들이 수용하는 영역이 더 넓어지기 때문입니다.
저자들은 audio timestep에 따라 긴 범위의 상관관계가 있다는 inductive bias를 가지도록 generator를 설계했습니다. 각각의 upsampling layer 뒤에 dilation residual block를 추가하면서, 각 후속 layer의 시간적으로 먼 output activation이 중첩 입력을 갖도록 하였습니다(residual). dilated convolution layer stack의 receptive field는 layer 수에 따라 지수적으로 증가하도록 설계하였습니다. 이를 통해 효과적으로 output time-step의 receptive field를 늘렸습니다. 먼 timestep의 induced receptive field에서 더 많이 중첩되는 것을 의미하며, 이를 통해 더 나은 long range correlation을 갖게 됩니다.
- Checkboard artifacts
transposed convolutional layer의 kernel size와 stride를 잘못 설정하면 deconvolutional generator는 '체크판' 패턴을 생성합니다. raw waveform을 생성할 때, 반복적인 pattern은 고주파 휘파람 소리를 야기할 수 있는데, 저자들은 deconvolutional layer의 kernel size와 stride를 잘 조절해 문제를 해결했다고 합니다. kernel size를 stride의 배수로 설정했다고 합니다. 그리고 kernel size와 dilation을 잘못 선택하게 되면, 반복적인 패턴이 생겨 noise가 형성될 수 있다고 합니다. 저자들은 dilation 크기를 kernel size의 제곱으로 증가하도록 하여, stack의 receptive field가 균형적이고 대칭적인 tree로 보이도록 설정했습니다.
- Normalization technique
generator에 대한 normalization technique이 sample quality에 매우 중요합니다. image를 생성하는 conditional GAN의 경우, generator의 모든 layer에 instance normalization을 사용했습니다. 그러나, audio 생성 모델의 경우, instance normalization을 적용하면 중요한 음정 정보를 없애고 금속 소리가 나도록 합니다. 또한 spectral normalization을 적용했을 때도 좋지 않은 결과를 얻게 됩니다. 실험을 통해 weight normalization이 가장 좋은 결과를 보였으며, discriminator의 크기를 제한하지 않고 activation을 normalization하지 않기 때문에 좋은 결과를 얻을 수 있었습니다. 단순히 weight vector의 scale을 direction에서 분리하여 weight matrices를 reparameterize하여 더 나은 훈련 dynamic을 갖도록 만듭니다. 따라서 generator의 모든 layer에 weight normalize를 적용합니다.
Discriminator
- Multi-Scale Architecture
저자들은 multi-scale 구조를 discriminator에 적용했습니다. 3개의 discriminator(D1, D2, D3)를 사용하는데, 3개의 discriminator는 같은 구조이지만 서로 다른 audio scale에 동작합니다. D1은 raw audio에서 동작하고, D2, D3는 각각 raw audio를 2배와 4배 downsample된 raw audio에서 작동한다. kernel size가 4인 stride average pooling을 사용해 downsampling됩니다. audio가 다양한 level의 구조를 가지고 있기 때문에 각자 다른 scale에서 동작하는 multiple discriminator들을 사용합니다. 이 구조는 각 discriminator가 audio의 다른 frequency 영역에 대한 feature를 학습한다는 inductive bias가 있다는 사실에 기인합니다. 예를 들어, downsampled audio에서 동작하는 discriminator는 high frequency 성분에 접근할 수 없기 때문에, low frequency 성분 feature에 대해서만 학습합니다.
- Window-based objective
각 discriminator는 Markovian window-based discriminator로, 큰 kernel size인 strided convolutional layer로 구성되어 있습니다. kernel 크기를 크게 하여 적은 수의 parameter를 사용하도록 하였습니다. 기존 GAN의 discriminator가 전체 audio의 분포 사이를 구분하도록 학습되지만, window based discriminator는 작은 audio chunk의 분포 사이를 구분하도록 학습됩니다. window based discirminator를 사용함으로써 필수적인 높은 frequency를 포착하고, 적은 수의 parameter를 사용하며, 더 빠르게 실행되고, 가변 길이의 audio sequence에 적용할 수 있게 됩니다. generator와 마찬가지로 discriminator에 weight normalization을 적용했습니다.
Training objective
GAN을 학습하기 위해, 저자들은 hinge loss를 사용합니다.

식은 위와 같습니다. 여기서 x는 raw waveform을 의미하고, s는 conditioning information(eg. mel-sepctrogram)을 의미합니다. 그리고 z는 gaussian noise vector입니다.
- Feature Matching
discriminator의 signal에 추가적으로, 저자들은 feature matching objective를 사용해 generator를 학습합니다. 이는 real audio에 대한 discriminator feature map과 synthetic audio의 discriminator feature map 사이의 L1 distance를 줄이도록 만듭니다. 직관적으로, 이는 학습된 similarity metric로써 볼 수 있으며, discriminator는 fake data와 real data를 구분하는 feature space를 학습한다고 볼 수 있습니다. raw audio space에서 loss를 사용하지 않는다는 점에서 주목할 만한 방식입니다. 다른 conditional GAN의 경우, 조건에 맞춰 생성된 image와 ground-truth 사이의 L1 loss를 사용합니다. 이는 전역적인 일관성을 강조하게 만듭니다. 그래서 저자들은 audio space에서 L1 loss를 추가하는 것이 audio quality를 해칠 수 있는 청각적인 noise를 추가할 수 있다고 생각했습니다.
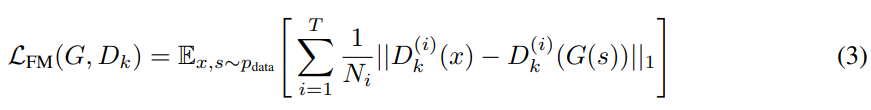
D_k^(i)는 k번째 discriminator block의 i번째 layer의 feature map output을 의미합니다. N_i는 각 layer의 unit 수를 나타냅니다. feature matching은 perceptual loss와 유사합니다. 저자들은 모든 discriminator block의 각 중간 layer에 feature matching을 적용합니다.
그래서 저자들이 generator를 학습할 때 사용하는 최종 objective는 다음과 같습니다. 여기서 λ는 10으로 설정했습니다.
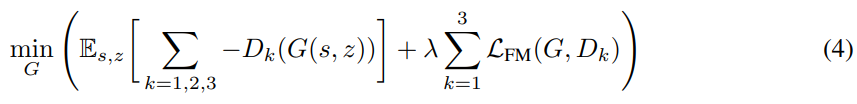
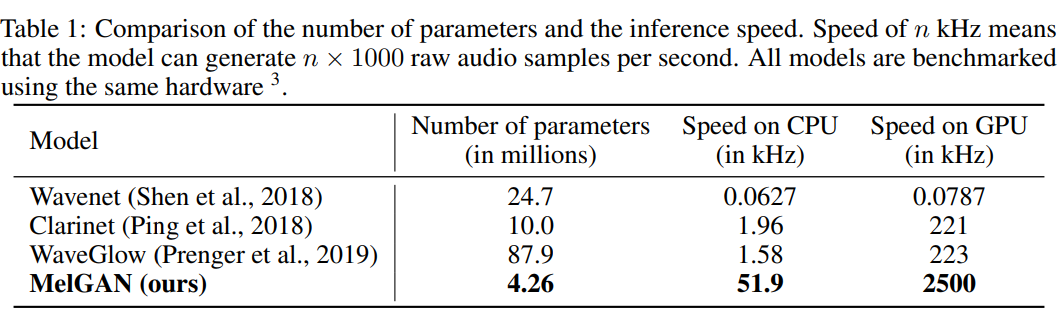
Number of parameters and inference speed
저자들의 architecture에 통합되는 inductive bias는 다른 model들에 비해 전체 parameter 수가 상당히 작게 만듭니다. non-autoregressive and fully convolutional한 저자들의 model은 inference time이 매우 빠르며(다른 model들에 비해 약 10배 더 빠릅니다), 2500kHz로 생성할 수 있습니다. 표로 나타내면 다음과 같습니다.
Results
Ground truth mel-spectrogram inversion
- Ablation study
저자들이 제안한 model의 다양한 구성 요소들의 중요도를 평가하기 위해 ablation study를 진행합니다.
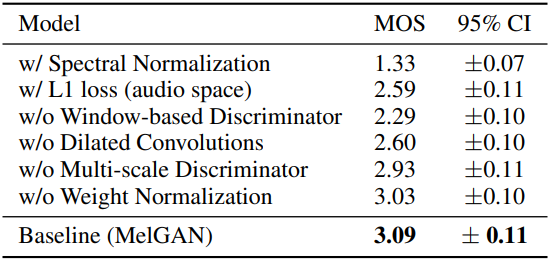
결과는 위와 같습니다. generator에 dilated convolutional stack을 사용하지 않거나 weight normalization을 제거하는 것이 high frequency artifact를 유도합니다. multi-scale discriminator를 사용하는 대신 single discriminator를 사용하는 경우 기계음이 들리는 audio를 생성하게 되며, 특히 speaker가 숨을 쉴 때 더욱 그렇습니다. 또한, 특정 발성 부분을 skip하기도 하며, 몇몇 단어를 완전히 놓치기도 합니다. spectral normalization을 사용하거나 window-based discriminator loss를 사용하지 않는 경우, high frequency pattern을 학습하기 어렵도록 만들며, 상당히 noise가 있는 sample을 만들어냅니다. real raw waveform과 generated raw waveform 사이에 추가적인 L1 penalty를 추가하는 것은 기계음을 만들며 high frequency artifact를 만듭니다.
- Benchmarking competing models
ground truth mel-spectrogram을 raw audio로 변환하는 MelGAN의 성능을 비교하기 위해, WaveNet vocoder, WaveGlow, Griffin-Lim과 비교합니다. 결과는 다음과 같습니다.
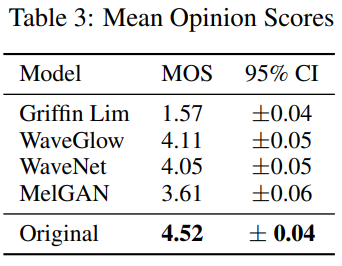
위 실험은 MelGAN이 WaveNet, WaveGlow와 같은 WaveNet 기반 model과 비교할만한 성능을 가진다는 것을 보여줍니다. 다른 model들과의 성능 차이는 앞으로의 연구를 통해 빠르게 줄어들 수 있다고 저자들은 생각한다고 합니다.
- Generalization to unseen speakers
MelGAN을 multiple speaker dataset(6명의 speaker이며, 3명의 남성과 3명의 여성으로 구성되며 각 speaker당 대략 10시간의 data입니다)에서 학습했을 때, 학습된 model이 train dataset 외부의 완전히 새로운 speaker에게 일반화할 수 있습니다. MelGAN이 mel-spectrogram에서 raw waveform으로의 speaker invariant mapping을 학습할 수 있음을 검증합니다.
저자들은 train에서 사용하지 않은 speaker에 대한 mel-spectrogram을 raw waveform으로 변환했을 때, MOS를 비교했습니다.
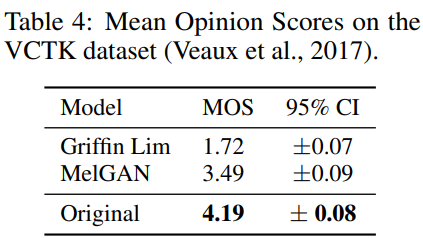
결과는 위와 같습니다.
End-to-end speech synthesis

End-to-end speech synthesis는 위 그림과 같습니다. 저자들은 mel-spectrogram을 inversion하는 end-to-end speech synthesis 성능을 MelGAN과 다른 model들을 비교합니다. 저자들은 MelGAN model을 위 그림과 같이 사용했으며, text-to-speech sample의 quality에 대해 다른 model들과 비교합니다.
구체적으로, spectrogram inversion에 MelGAN을 사용하거나 WaveGlow를 사용했을 때 생성되는 sample의 quality를 비교합니다. 이때 Text2mel을 사용하는데, char2wav model의 향상된 version입니다. Text2mel은 phoneme을 input으로 받아 mel-spectrogram을 생성합니다. 생성된 mel-spectrogram을 WaveGlow와 MelGAN에 넣어주는 방식으로 진행됩니다. 추가적으로, 저자들은 Tacotron2 model을 WaveGlow와 함께 사용해 baseline으로 사용했습니다. 결과는 다음과 같습니다.
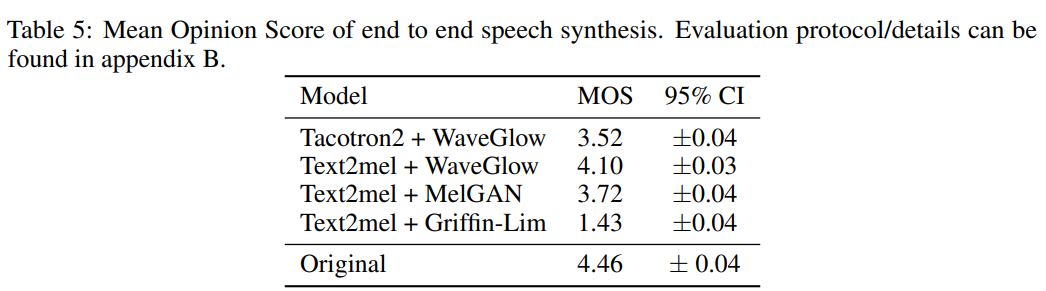
MelGAN이 TTS pipeline의 vocoder로 사용되는 최신 model들과 비슷한 성능을 보이는 것을 알 수 있습니다.
Conclusion and future work
저자들은 conditional audio synthesis에 GAN 구조를 사용했습니다. 그리고 저자들이 제안한 방식의 성능을 입증했습니다. 저자들의 model은 매우 가볍기 때문에 빠르게 학습될 수 있습니다. 그리고 매우 빠른 inference time을 보여줍니다. 저자들은 generator가 higher-level audio related task에 사용되는 연산량 많은 model들의 대체자가 될 수 있다고 생각합니다.



