https://arxiv.org/abs/2010.05646
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
Several recent work on speech synthesis have employed generative adversarial networks (GANs) to produce raw waveforms. Although such methods improve the sampling efficiency and memory usage, their sample quality has not yet reached that of autoregressive a
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
최근 몇 년 동안의 음성 합성 연구는 GAN을 이용해 raw waveform을 만들고 있습니다. 비록 이러한 방법들이 sampling 효율성과 memory 사용량을 효율적으로 만들고 있지만, sampling quality는 아직 autoregressive generative model과 flow-based generative model에 비해 부족합니다.
그래서 저자들은 HiFi-GAN을 제안합니다. HiFi-GAN은 음성 합성의 효율성과 high-fidelity를 향상시켰습니다. speech audio가 다양한 주기를 가진 sin파 신호로 구성되어 있기 때문에, 저자들은 audio의 주기적 pattern을 modeling하는 것이 sample quality를 향상시킬 수 있는 중요한 요소라는 것을 증명합니다. HiFi-GAN은 MOS에서 좋은 성능을 보여주며, V100 GPU 1개를 사용하였을 때 real-time보다 167.9배 더 빠른 속도로 22.05kHz audio를 생성할 수 있습니다. 그리고 HiFi-GAN의 일반성을 보여주기 위해, unseen speaker의 mel-spectrogram inversion에도 적용하고 end-to-end speech synthesis에도 적용했습니다. 마지막으로, 가벼운 version의 HiFi-GAN은 CPU에서 real-time보다 13.4배 더 빠르게 autoregressive model과 비교할 수준의 sample을 생성할 수 있습니다.
Introduction
최근에 인간이 기계와 대화하는 수요가 증가함에 따라, 인간과 유사하게 자연스러운 음성을 합성하는 기술이 활발히 연구되고 있습니다.
neural network의 발전에 따라, 최근 음성 합성 기술들은 빠르게 발전하고 있습니다. 대부분의 neural speech synthesis model은 2단계의 pipeline을 사용합니다. 1) mel-spectrogram이나 linguistic feature와 같은 low resolution intermediate representation을 만듭니다. 2) intermediate representation을 가지고 raw waveform audio를 합성합니다.
첫 번째 단계는 text로부터 인간 음성의 low-level representation을 model하는 단계입니다. 반면에, 두 번째 단계에서는 1초에 24000개 이상의 sample과 최대 16bit의 품질을 가진 raw waveform을 합성하는 단계입니다. 저자들은 mel-spectrogram을 이용해 high-fidelity waveform을 효율적으로 합성하는 model을 연구하는 두 번째 단계에 대해 연구합니다.
audio 합성 quality와 두번째 단계의 효율성을 향상시키는 다양한 연구들이 진행되고 있습니다. WaveNet은 autoregressive(AR) convolutional neural network입니다. WaveNet은 neural network 기반 method가 기존 방식보다 quality가 우월하다는 것을 보여줬습니다. 하지만 AR 구조 때문에, WaveNet은 각 forward 연산을 해야지 하나의 sample을 만들어냅니다. 이는 높은 temporal resolution audio 합성하기에 너무 오랜 시간이 걸리게 됩니다. Flow-based generative model은 이 문제를 해결하기 위해 제안된 방식입니다. 동일한 크기의 noise sequence를 병렬로 변환하여 raw waveform을 합성할 수 있는 능력을 가지고 있기 때문에, flow-based generative model은 hardware의 병렬처리 능력의 발전에 따라 sampling 속도가 빨라졌습니다. Parallel WaveNet은 inverse autoregressive flow(IAF)입니다. 이는 teacher라 불리는 pre-trained WaveNet과의 Kullback-Leibler divergence를 minimize하도록 학습됩니다. teacher model과 비교했을 때, Parallel WaveNet은 품질 저하 없이 1000배 더 빠르게 합성을 할 수 있었습니다. WaveGlow는 teaher model을 이용해 model을 학습하는 과정이 없습니다. WaveGlow는 Glow에 기반한 효율적인 bijective flow를 사용하여 MLE 방식으로 train 과정을 단순화시켰습니다. 그리고 WaveGlow는 WaveNet과 비교할 수 있는 정도의 고품질 audio를 생성할 수 있습니다. 하지만, WaveGlow는 90개보다 더 많은 layer를 사용하는 deep architecture이기 때문에 parameter 수가 매우 많습니다.
그 이후에 GAN 기반 음성 합성 deep generative model들이 등장했습니다. MelGAN의 경우, generator가 CPU에서도 real-time으로 음성 합성을 할 수 있습니다. 그 이후에 등장한 model은 multi-resolution STFT loss functoin을 사용해 GAN의 학습 안정성을 향상시켰으며 parameter 효율성도 향상시키고 training time도 줄였습니다. mel-spectrogram을 대신해 GAN-TTS는 linguistic feature를 사용해 고품질의 raw audio waveform을 성공적으로 생성합니다. 하지만 현재 등장한 GAN 기반 model들은 AR or flow-based model과의 sample quality 사이의 gap이 여전히 존재합니다.
그래서 저자들은 Hi-Fi-GAN을 제안합니다. 이는 높은 연산 효율성을 가지고 있으며, AR과 flow-based model보다 더 좋은 sample quality를 보여줍니다. speech audio는 다양한 주기의 sin signal로 구성되어 있기 때문에, 주기적인 pattern을 modeling하는 것이 실제 같은 speech audio를 생성하는 데 중요한 부분입니다. 그렇기 때문에 저자들은 작은 sub-discriminator로 구성된 discriminator를 제안합니다. 각 discriminator는 raw waveform의 특정 주기 부분만 이용합니다. 이러한 구조는 저자들이 제안한 model이 실제 같은 speech audio를 합성할 수 있었던 주된 이유입니다. audio의 다양한 부분들을 추출하여 discriminator에 사용하기 때문에, 저자들은 병렬로 다양한 길이의 pattern을 다루는 여러 residual block을 배치한 module을 설계하여 generator에 적용합니다.
HiFi-GAN은 WaveNet과 WaveGlow보다 더 높은 MOS 점수를 보입니다. HiFi-GAN은 V100 GPU 1개를 사용했을 때, 3.7MHz의 인간과 유사한 quality의 speech audio를 합성할 수 있습니다. 나아가 저자들은 HiFi-GAN의 일반성을 보이기 위해 unseen speaker의 mel-spectrogram을 inversion하는 데 HiFi-GAN을 사용하며, end-to-end speech synthesis에도 사용합니다. 그리고 경량화된 HiFi-GAN은 0.92M parameter만을 가지고 있지만, CPU에서 real-time보다 13.44배 더 빠르게 sample을 만들 수 있으며, V100 GPU 1개를 사용했을 때 real-time보다 1186배 더 빠르게 sample을 만들 수 있습니다. 그리고 sampling quality도 autoregressive model과 비교 가능한 수준입니다.
HiFi-GAN
Overview
HiFi-GAN은 1개의 generator와 2개의 discriminator로 구성되어 있습니다. discriminator는 multi-scale & multi-period discriminator입니다. generator와 discriminator는 학습 안정성과 model의 성능을 향상시키기 위해 두 개의 추가적인 loss를 사용하여 adversarial 하게 학습됩니다.
Generator
Generator는 fully convolutional neural network입니다. 이는 mel-spectrogram을 input으로 사용하며,
raw waveform의 temporal resolution과 일치하는 output sequence length를 만들도록 transposed convolution을 적용하여 upsampling합니다. 모든 transposed convolution 뒤에 multi-receptive field fusion (MRF) module이 존재합니다. 아래 그림과 같은 형태입니다.
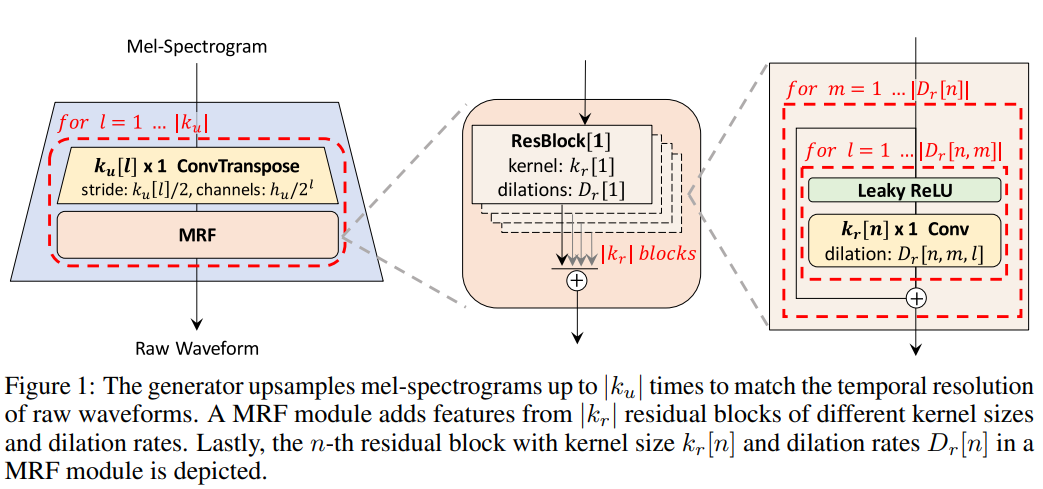
저자들의 generator는 이전에 등장한 연구와 같이, noise를 generator의 추가적인 input으로 사용하지 않습니다.
- Multi-Receptive Field Fusion
저자들은 multi-receptive field fusion module을 generator에 사용합니다. 이를 통해 병렬적으로 다양한 length의 pattern을 관측할 수 있습니다. 특히, MRF module은 multiple residual block으로부터 output을 받아 더한 후에 return합니다. 각 residual block은 서로 다른 kernel size와 dilation rate를 사용하여 다양한 receptive field pattern 형태를 만듭니다. MRF module의 구조와 residual block은 위와 같습니다. 저자들은 generator에 조절 가능한 몇 가지 parameter를 남겨두었습니다. hidden dimension h_u, transposed convolution의 kernel size k_u, kernel size k_r, 그리고 MRF module의 dilation rate D_r을 합성의 효율성과 sample의 quality 사이의 trade-off를 맞출 때 조정할 수 있습니다.
Discriminator
실제같은 speech audio를 modeling하기 위해서는 long-term dependencies를 식별하는 것이 key입니다. 예를 들어 phoneme(음소)의 지속 시간은 100ms를 넘길 수 있으며, 이는 raw waveform에서 2200개 이상의 인접 sample 간의 높은 상관관계를 초래합니다. 이러한 문제를 generator와 discriminator의 receptive field를 증가시키는 방법으로 해결했습니다. 저자들은 아직 해결하지 못한 치명적인 또 다른 문제점에 focusing합니다. speech audio는 다양한 주기를 가진 sin 신호로 구성되기 때문에, audio data에 존재하는 다양한 주기의 pattern을 식별할 필요가 있습니다.
이를 위해, 저자들은 multi-period discriminator (MPD)를 제안합니다. MPD는 몇 개의 sub-discriminator로 구성되며, 각 discriminator는 input audio의 각 주기 신호 부분을 처리합니다. 또한, 연속적인 pattern과 long-term dependencies를 capture하기 위해, 저자들은 MelGAN에서 제안한 multi-scale discriminator (MSD)을 사용합니다. 이를 통해 다양한 level에서 audio sample을 연속적으로 평가합니다. 저자들은 간단한 실험들을 통해 MPD와 MSD가 주기적 pattern을 capture 하는 능력을 보여줍니다.
- Multi-Period Discriminator
MPD는 여러 개의 sub-discriminator로 구성되며, 각 discriminator는 input audio와 동일한 spaced sample만 accept합니다. 여기서 말하는 space는 period p를 의미합니다. 다시 말해, 각 discriminator는 서로 다른 period를 정의하고 있으며, input sample 중 p에 해당하는 sample들이 discriminator에 input됩니다. sub-discriminator들은 input audio의 서로 다른 part를 보면서 서로 다른 암묵적 구조를 capture합니다. 저자들은 period를 [2, 3, 5, 7, 11](이는 소수)로 설정해 가능한 overlap을 피했습니다.

위 그림과 같은 구조입니다. T 길이의 1D raw audio를 T/p height를 갖고 p width를 갖는 2D data로 reshape합니다. 그리고 난 후에 2D convolution을 적용합니다. MPD에 있는 모든 convolutional layer에서, 저자들은 width 축 kernel size를 1로 제한합니다. 이를 통해 주기성을 띄는 sample들을 독립적으로 처리할 수 있게 됩니다. 각 sub-discriminator는 leaky ReLU와 함께 strided convolutional layer를 stack합니다. 그 이후에, weight normalization을 MPD에 적용합니다. audio의 주기적 signal을 sampling하는 대신에 input audio를 2D data로 reshape했기 때문에, MPD로부터 얻어지는 기울기는 input audio의 모든 time step으로 전달됩니다.
- Multi-Scale Discriminator
MPD에 있는 각 sub-discriminator들은 분리된 sample만 accept하기 때문에, 저자들은 MSD도 사용해 audio sequence를 연속적으로 평가합니다. MSD 구조는 MelGAN에서 사용되었니다. MSD는 3개의 sub-discriminator로 이루어져 있으며, 각 discriminator는 서로 다른 input scale에서 동작합니다. raw audio, x2 average-pooled raw audio, x4 average-pooled raw audio와 같은 형태로 3가지 서로 다른 scale에서 동작합니다. 모습은 다음과 같습니다.

MSD에 있는 각 sub-discriminator는 strided and grouped convolutional layer와 leaky ReLU의 stack으로 구성되어 있습니다. discriminator size는 stride를 줄이고 layer를 추가함으로써 증가시켰습니다. raw-audio를 처리하는 첫 번째 sub-discriminator를 제외하고 나머지 discriminator들은 weight-normalization을 이행합니다. 그 대신, 첫 번째 sub-discriminator에는 spectral normalization을 적용하여 학습을 안정적으로 만들었습니다.
MPD는 raw waveform에서 분리된 sample에서 동작하며, MSD는 smoothed waveform에서 동작합니다.
저자들이 제안한 discriminator 구조는 discriminator의 혼합체라는 점에서 MPD, MSD와 유사하지만, MPD와 MSD는 Markovian window-based fully unconditional discriminator인 반면에 저자들의 방식은 output의 평균을 사용하며 conditional discriminator입니다.
Training Loss Term
- GAN Loss
저자들은 MSD와 MPD discriminator들을 하나의 discriminator로 표현해 수식을 작성합니다. generator와 discriminator는 LS-GAN의 형태로 학습됩니다. original GAN의 경우 binary cross-etnropy term을 사용하지만, LS-GAN은 least square loss를 사용해 gradient vanishing을 해결합니다. discriminator는 ground truth sample은 1로, synthesized sample은 0으로 구분하도록 학습되니다. generator는 sample quality를 update하면서 최대한 discriminator가 1에 가깝게 분류할 수 있도록 학습합니다. generator는 G로 표기하고 discriminator는 D로 표기합니다. 수식은 다음과 같습니다.
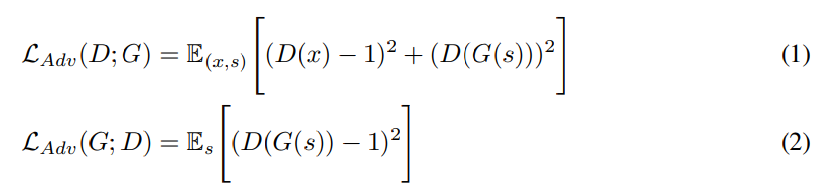
여기서 x는 ground truth audio를 의미하고 s는 input condition을 의미하며, 이는 ground truth audio의 mel-spectrogram입니다.
- Mel-spectrogram Loss
저자들은 GAN objective에 mel-spectrogram loss를 추가하여 generator의 학습 효율성을 향상시키고, 생성된 audio의 fidelity를 향상시켰습니다. reconstruction loss를 GAN model에 적용하면 더 사실적인 예시를 만드는 데 도움을 주며, multi-resolution spectrogram와 adversarial loss function 동시에 최적화하면 time-frequency distribution을 효율적이게 capture하도록 만들어줍니다. 저자들은 input condition에 대응하는 mel-spectrogram loss을 사용했으며, 이를 통해 인간의 청각 system의 특성으로 인해 인간이 지각하는 품질을 개선하는 데 더욱 효과적으로 focusing할 수 있을 것이라고 생각하기 때문에 mel-spectrogram loss를 사용합니다. mel-spectrogram loss는 generator가 생성한 waveform으로부터 얻은 mel-spectrogram과 groud truth waveform의 mel-spectrogram 사이의 L1 distance를 의미합니다. 식은 다음과 같습니다.

여기서 Φ는 waveform을 mel-spectrogram으로 변환하는 함수를 의미합니다. mel-spectrogram loss는 generator가 input condition에 대응하는 사실적인 waveform을 만들 수 있도록 도와주며, adversarial training 과정을 초기 단계부터 안정적으로 만들어줍니다.
- Feature Matching Loss
feature matching loss는 discriminator가 구한 ground truth sample과 generated sample의 feature 사이의 차이에 의해 측정되는 similarity metric를 학습하게 만듭니다. 음성 합성에서도 성공적으로 사용되었었기 때문에, 저자들은 generator를 학습할 때 feature matching loss를 추가적으로 사용합니다. discriminator의 모든 중간 feature를 추출하고, 각 feature space에서 ground truth sample과 conditionally generated sample 사이의 L1 distance를 구하면 됩니다. feature matching loss는 다음과 같이 정의됩니다.
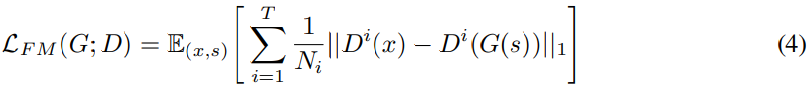
여기서 T는 discriminator에 존재하는 layer 수를 의미합니다. D^i는 discriminator의 feature를 의미하고, N_i는 discriminator의 i번째 layer의 feature 수를 의미합니다.
- Final Loss
최종적인 loss function은 다음과 같습니다.
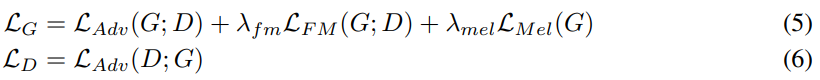
저자들은 λ_fm = 2, λ_mel = 45로 설정했습니다. 저자들의 discriminator는 MPD와 MSD의 sub-discriminator 집합이기 때문에, sub-discriminator를 고려한 식은 다음과 같이 다시 작성할 수 있습니다.
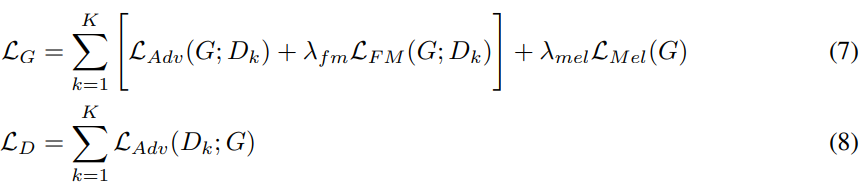
여기서 D_k는 MPD와 MSD에 존재하는 k번째 sub-discriminator를 의미합니다.
Experiments
저자들은 다른 모델들과의 비교를 위해 LJSpeech dataset을 이용합니다. 이는 많은 음성 합성 model을 학습할 때 사용되었던 dataset입니다. LJSpeech는 13,100개의 짧은 audio clip으로 구성되어 있으며, 이는 단일 speaker의 약 24시간 길이의 발화입니다. audio는 16-bit PCM의 22kHz sampling rate로 녹음되어 있습니다. 저자들은 dataset에 추가적인 작업없이 사용했습니다. 저자들은 HiFi-GAN을 WaveNet (MoL), WaveGlow, MelGAN과 비교합니다.
unseem speaker의 mel-spectrogram inversion에 대한 HiFi-GAN의 일반성을 평가하기 위해, 저자들은 VCTK multi-speaker dataset을 사용했습니다. 해당 dataset은 약 44,200개의 short audio clip으로 구성되며, 109명의 원어민 영어 speaker들이 다양한 악센트로 녹음했습니다. 총 길이는 약 44시간입니다. audio format은 16-bit PCM이며, sampling rate는 44kHz입니다. 저자들은 sampling rate를 22kHz로 변환하여 사용했습니다. 저자들은 random하게 선택된 9명의 speaker를 제외한 모든 audio clip을 training set으로 사용했습니다. 저자들의 비교 대상 model들도 동일한 환경에서 학습을 했습니다.
audio quality를 평가하기 위해, 저자들은 5-scale MOS를 진행했습니다. 모든 audio clip은 audio volume의 차이에 따른 영향을 막기 위해 normalize했습니다.
합성 속도는 GPU와 CPU 환경에서 측정했습니다. 저자들은 1개의 NVIDIA V100 GPU와 MacBook Pro laptop (Intel i7 CPU 2.6GHz)를 사용했습니다.
저자들은 합성 효율성과 sample quality 사이의 trade-off를 확인하기 위해, 3가지 다른 generator를 사용해 실험했습니다. 각 generator는 동일한 discriminator를 사용합니다. 첫 번째 generator V1은 h_u = 512, k_u = [16, 16, 4, 4], k_r = [3, 7, 11], D_r = [[1, 1], [3, 1], [5, 1]] x 3으로 설정했으며, 두 번째 generator V2는 V1보다 약간 더 작은 version입니다(hidden dimension h_u = 128이지만, receptive field size는 동일). 마지막 더 축소된 version인 V3는 동일한 receptive field를 갖도록 kernel size와 dilation rate를 잘 조정했습니다. detail은 다음과 같습니다.

저자들은 80band mel-spectrogram을 input condition으로 사용했습니다. FFT = 1024, window size = 1024, hop size = 256으로 설정했습니다. nework는 AdamW optimizer를 사용해 학습했습니다.
Results
Audio Quality and Synthesis Speed
저자들은 model의 quality와 speed를 평가하기 위해 spectrogrma inversion에 MOS test를 했으며, speed도 측정했습니다. MOS test의 경우, 저자들은 LJSpeech dataset에서 랜덤하게 50개의 utterance를 선택하였습니다.

결과는 위와 같습니다. HiFi-GAN의 다양한 version들 모두 다른 model보다 더 높은 MOS 결과를 보여줍니다. V1의 경우, 13.92M 개의 parameter를 사용하면서 ground truth와 0.09밖에 차이 안나는 MOS 결과를 보입니다. 이는 합성된 음성이 사람의 voice와 거의 구분 불가능한 수준이라는 것을 의미합니다. 합성 속도를 볼 때, V1은 WaveGlow와 WaveNet (MoL) 보다 더 빠른 속도를 보여줍니다. V2 또한 MOS 결과가 사람의 voice와 매우 유사한 결과를 보이면서 inference time를 많이 줄였습니다. V3의 경우, MelGAN보다 훨씬 바른 속도를 보이면서도 WaveNet과 비슷한 quality를 보여줍니다. V3는 CPU 환경에서 효율적으로 합성할 수 있으며, on-device application에 적합한 model이 될 수 있습니다.
Ablation Study
저자들은 HiFi-GAN의 각 요소들이 합성된 음성의 quality에 영향을 주는 것을 증명하기 위해 MPD, MRF, mel-spectrogram loss에 대해 ablation study를 적용해 결과를 비교합니다. V3를 generator로 사용해 ablation study를 진행합니다.
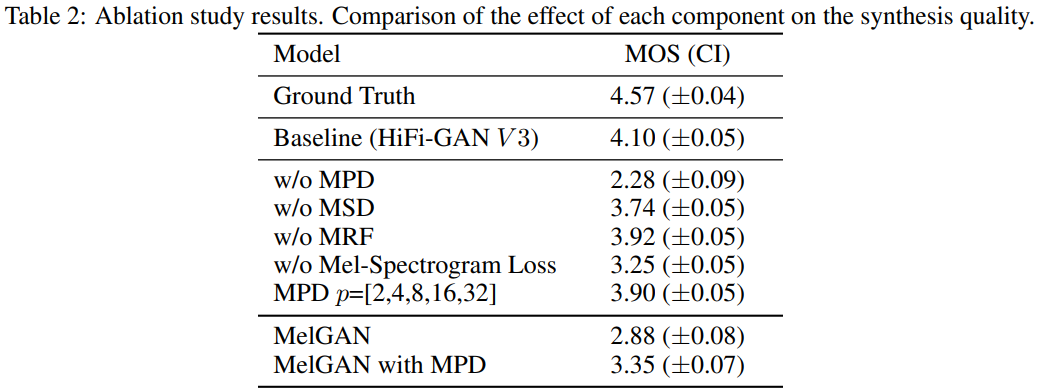
결과는 위와 같습니다. MPD를 제거하면 perceptual quality가 현저히 감소되며, MSD를 제거하면 MPD를 제거했을 때 생기는 감소폭은 아니지만 감소하는 것을 알 수 있습니다. MRF의 효과를 조사하기 위해, 각 module에서 가장 넓은 receptive field를 가진 한 개의 residual block을 남겨두었습니다. 결과는 baseline보다 나빠집니다. mel-spectrogram loss에 대한 실험을 통해 mel-spectrogram loss가 quality에 영향을 준다는 것을 알아냈으며, loss를 사용했을 때 quality가 더 안정적으로 향상된다는 것을 알아냈습니다.
다른 GAN model에서도 MPD의 효과를 입증하기 위해, 저자들은 MelGAN에 MPD를 적용했습니다. MPD를 사용한 MelGAN은 original version보다 MOS가 0.47 상승한 것을 볼 수 있습니다.
저자들은 period set을 소수로 설정한 것의 효과를 입증하기 위해, period를 2의 거듭제곱으로 두고 실험을 진행했습니다. baseline에 비해 MOS가 0.20 감소한 것을 볼 수 있습니다.
Genralization to Unseen Speakers
저자들은 unseen speaker에 대한 일반화 능력을 보기 위해, MOS test에 사용될 data는 학습에서 사용된 VCTK data를 제외한 50개의 random하게 선택된 발화들을 골랐습니다. 50개의 발화는 9명의 speaker에 의해 녹음되었습니다.
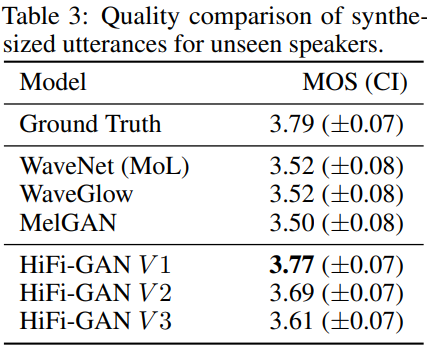
결과는 위와 같습니다. 저자들이 제안한 HiFi-GAN이 auto-regressive model과 flow-based model에 비해 더 좋은 결과를 보여주며, 이를 통해 HiFi-GAN이 unseen speaker에 대한 일반화 성능이 좋다는 것을 알 수 있습니다. 또한, VCTK dataset에서도 좋은 결과를 보이는 것을 통해, 다양한 dataset에 대한 일반화 성능이 좋다는 것도 알아볼 수 있습니다.
End-to-End Speech Synthesis
저자들이 제안한 model이 text to mel-spectrogram을 거쳐 mel-spectrogram to waveform 합성까지 이르는 end-to-end 음성 합성 pipeline에 적용될 때의 효과를 확인하기 위해 추가적인 실험을 진행했습니다. 저자들은 Tacotron2를 사용해 text에서 mel-spectrogram을 생성했습니다. 추가적인 수정 없이, 저자들은 가장 자주 사용되는 사전 학습된 weight를 이용하는 Tacotron2를 이용해 mel-spectrogram을 합성했습니다. 그 이후에 저자들은 mel-spectrogram을 input condition으로 두 번째 stage로 넣습니다.
MOS score는 다음과 같습니다.
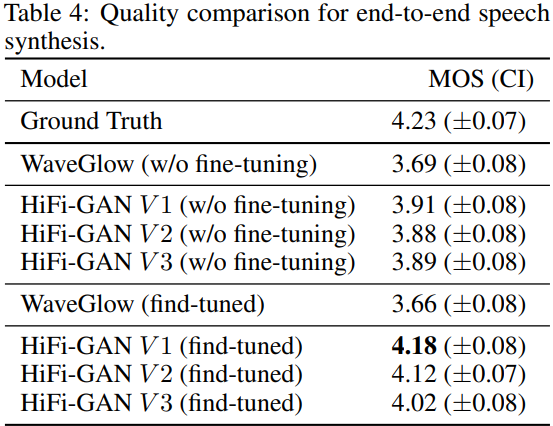
저자들이 제안한 HiFi-GAN에 fine-tuning을 하지 않았을 때, WaveGlow보다 더 뛰어난 결과를 보여줍니다. 하지만 모든 model들의 audio quality는 ground truth audio와 비교했을 때, 불만족스러운 결과입니다.
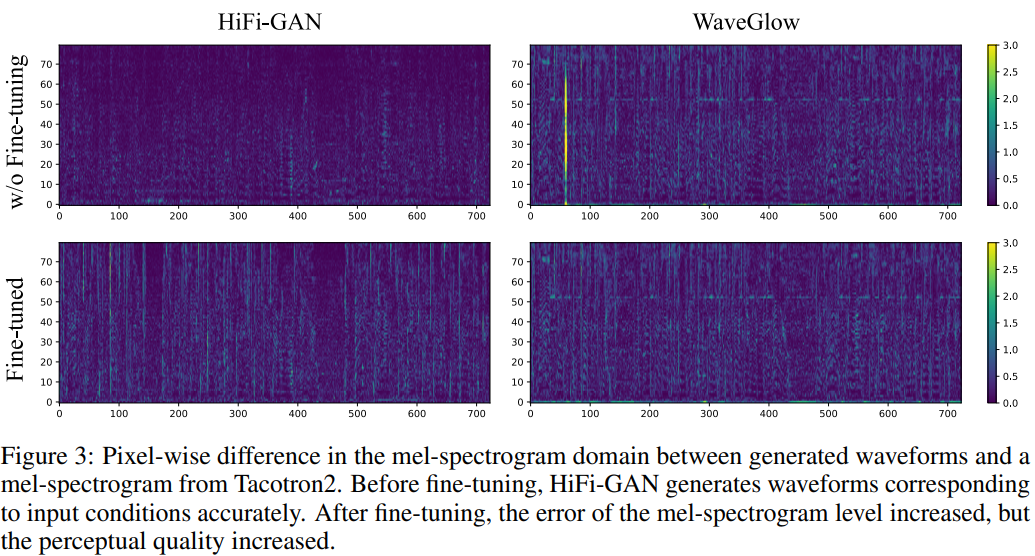
하지만, Tacotron2에 의해 생성된 mel-spectrogram과 생성된 waveform으로 생성한 mel-spectrogram 사이의 pixel-wise차이는 미미한 것을 볼 수 있습니다. 즉, Tacotron2가 생성한 mel-spectrogram이 애초에 noisy하다는 것을 의미합니다. end-to-end setting에서의 audio quality를 향상시키기 위해, 저자들은 Tacotrn2의 mel-spectrogram에 맞춰 fine-tuning을 했습니다. 저자들이 제안한 모든 model들의 MOS score는 4를 넘지만, fine-tuned WaveGlow는 성능 향상을 보이지 못했습니다. 이를 통해 저자들은 HiFi-GAN이 end-to-end setting에서 fine-tuning 했을 때 잘 adapt된다는 장점도 있다고 생각합니다.
Conclusion
이 논문에서, 저자들은 HiFi-GAN을 소개합니다. 이는 high quality speech audio를 효과적으로 합성할 수 있습니다. 저자들이 제안한 model은 합성 quality 관점에서 봤을 때 가장 좋은 performance를 보여주며, 사람의 quality와 비교가능할 정도입니다. 그리고 HiFi-GAN가 합성 속도를 매우 향상시켰습니다. 저자들은 speech audio가 다양한 주기의 pattern으로 구성되어있다는 특성에서 영감을 받아 연구를 진행했으며, 저자들이 제안한 discriminator가 음성 합성 quality를 크게 향상시켰습니다. HiFi-GAN은 end-to-end setting에서도 좋은 성능을 보이며 unseen speaker에 대해서도 좋은 일반화 성능을 보여줍니다. 저자들이 제안한 model의 경량화 version은 가장 성능이 좋은 autoregressive model과 비교할만한 성능을 보였으며, CPU에서 real-time에 비해 훨씬 더 빠르게 sample을 생성합니다. 마지막으로, 저자들이 제안한 discriminator에 다양한 generator를 적용했을 때 좋은 성능을 보였습니다. 즉 상황에 맞게 generator를 유동적으로 선택하여 discriminator와 함께 사용할 수 있음을 시사합니다.


