https://arxiv.org/abs/2101.09624
A Review of Speaker Diarization: Recent Advances with Deep Learning
Speaker diarization is a task to label audio or video recordings with classes that correspond to speaker identity, or in short, a task to identify "who spoke when". In the early years, speaker diarization algorithms were developed for speech recognition on
arxiv.org
해당 survey paper를 보고 작성했습니다.
Abstract
speaker diarization는 audio나 video recording에 speaker identity에 대한 class를 label하는 task입니다. 간단히 말하면 "누가 언제 말을 했냐"를 식별하는 작업입니다. 초기에, speaker diarization algorithm은 multispeaker audio recording에 대해 음성 인식을 위해 발전되었습니다. 이러한 algorithm들은 시간이 지남에 따라 독립적인 응용 프로그램으로써 가치를 갖게 되었습니다. 더욱 최근에는, deep learning 기술이 발전하면서, speech application domain의 변화를 이끌어냈습니다. speaker diarization의 경우, 빠르게 발전되고 있습니다. 이 논문에서는, speaker diarization system의 발전 역사뿐만 아니라, neural speaker diarization 접근법의 발전에 대해서 이야기합니다. 추가적으로, 저자들은 어떻게 speaker diarization system을 speech recognition application에 적용할 수 있는지에 대해서도 이야기합니다.
Introduction
"Diarize"는 일기에 기록하거나 이벤트를 기록하는 것을 의미합니다. event를 기록하는 것과 같이 speaker diarization은 "누가 언제 말을 하는지"에 대한 질문을 multi-speaker audio data에서 speaker별로 event를 기록하는 것을 의미합니다. diarization process를 통해, audio data는 동일한 speaker identity/label을 가진 speech segment group으로 나눠지고 cluster됩니다. 결과적으로 비음성에서 음성으로 변환되거나 반대로 음성에서 비음성으로 변환될 때, 또는 speaker가 변하는 것과 같은 주요한 event가 자동으로 감지됩니다. 일반적으로, 이러한 process는 많은 speaker에 대한 prior knowledge가 필요하지 않으며, 예를 들어 real identity나 audio data에 등장하는 speaker들의 수와 같은 간단한 prior knowledge를 필요로 하지 않습니다. 이러한 speaker별 event로 audio stream을 분리할 수 있기 때문에, speaker diarization은 다양한 audio data에 indexing을 하거나 분석을 할 때 사용될 수 있습니다. 예를 들어 방송국에 사용되는 audio/video 방송, 회의에서의 대화, 온라인 소셜 미디어나 휴대용 장치에서의 개인 video, 법정 절차 등 다양한 유형의 audio data에 사용할 수 있습니다.

전통적인 speaker diarizatio nsystem은 위 그림과 같이 여러 개의 독립적인 sub-module로 구성됩니다. 음향 환경의 artifact를 개선하기 위해, speech enhancement, speech separation, target speaker extraction과 같은 다양한 front-end processing 기술들을 사용합니다. Voice or speech activity detection (SAD)는 non-speech와 speech event를 분리할 때 사용됩니다. 선택된 부분의 raw speech signals은 acoustic feature 또는 embedding vector로 변환됩니다. clustering 단계에서는, 변환된 음성 부분들이 group화 되고 speaker class에 대해 label을 생성합니다. 그리고 그 이후 후처리 단계에서, clustering 결과는 더 정제됩니다. 일반적으로 각 sub-module은 서로 독립적으로 최적화됩니다.
Historical Development of Speaker Diarization
diarization 기술 초기에는(1990년대), 공항 교통 관제 대화 및 방송 뉴스 녹음에서 각 speaker의 segment를 분리하고 acoustic model의 speaker-adaptive training하는 것을 가능하게 함으로써 automatic speech recognition (ASR)을 향상시키는 것이었습니다. 이때, speaker change detection과 clustering에서 사용되는 speech segment 사이의 거리를 측정하는 몇몇 기본적인 approach들(generalized likelihood ratio, Bayesian information criterion 등)은 개발되어 표준이 되었습니다. 다양한 기관에서 발전을 위해 노력을 했으며, 그에 따라 다양한 data domain에서 speaker diarization technique의 추가적인 발전이 이뤄졌습니다. 이러한 발전으로 인해 새로운 approahc에는 beamforming, information bottleneck clustering (IBC), variational Bayesian (VB) 접근법, joint factor analysis (JFA) 등이 있습니다.
JFA에서 파생된 total variability space에 존재하는 speaker specific representation, 즉 i-vector는 speaker recognition에서 큰 성공을 거두었으며, speaker diarization task에 존재하는 짧은 speech segment의 feature representation으로 i-vector가 사용되었습니다. i-vector가 이전에 사용되었던 MFCC나 speaker factor를 성공적으로 대체하였으며, principal component analysis (PCA), variational Bayesian Gaussian mixture model (VB-GMM), mean shift, probabilistic linear discriminant analysis (PLDA)와 같은 다양한 기술과 결합되어 speaker diarization 성능을 향상시켰습니다.
2010년 대에 deep learning이 등장하면서, speaker diarization에 사용하는 neural network의 능력을 활용하기 위한 다양한 연구가 진행되었습니다. 대표적인 예시로 d-vector나 x-vector가 있습니다. 이는 neural network를 이용해 speaker embedding을 추출하는 기술을 의미합니다. i-vector가 이러한 neural embedding으로 대체되면서 성능 향상, 더 많은 data를 쉽게 이용하여 학습, speaker variability와 acoustic condition에 대해 강건성으로 이어졌습니다. 최근에는, end-to-end neural diarization (EEND)가 등장했습니다. 이는 전통적인 speaker diarization system에 존재하는 각 sub-module들을 하나의 neural network로 대체하는 것을 의미합니다. 아직 이러한 연구가 완전하지는 않지만, 다른 음성 응용 program과의 공동 최적화, 중첩된 음성이 있는 경우와 같은 speaker diarization task의 challenge들을 해결하기 위한 해결책이 될 수 있는 가능성이 생겼습니다.
Diarization Evaluation metrics
- Diarization Erro Rate
speaker diarization system의 정확도는 diarization error rate (DER)을 사용하여 측정됩니다. DER은 3가지 error type의 summation입니다. 3가지 error type은 speech에 대한 False alarm (FA), speech missed detection, confusion between speaker label입니다.
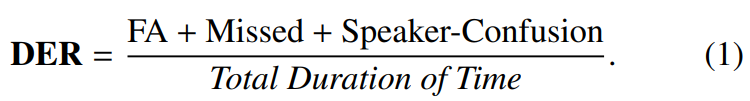
hypothesis output과 reference script의 일대일 mapping을 설정하기 위해, Hungarian algorithm을 사용했습니다.
- Jaccard Error Rate
Jaccard error rate (JER)은 DI-HARD Ⅱ evaluation에서 처음 등장했습니다. JER의 목표는 각 speaker를 동일한 weight에서 평가하는 것입니다. 전체 발화에 대해 추정되는 DER과 다르게, JER은 speaker 별 error rate를 구한 후 평균 내어 계산됩니다. 식은 다음과 같습니다.

위 식에서 TOTAL_i는 i번째 speaker의 reference와 hypothesis에 등장하는 utterance time을 의미합니다. N_ref는 reference script에 존재하는 speaker 수를 의미합니다. DER에 등장하는 Speaker-confusion이 FA_i가 됩니다. JER은 reference와 hypothesis의 합을 이용하기 때문에, JER은 절대 100%를 초과하지 않습니다. 하지만 DER은 100%를 훨씬 초과할 수 있습니다. DER과 JER은 서로 매우 연관이 있지만, audio recording이 몇 명의 speaker에 의해 지배적인 경우, JER은 일반적인 경우보다 높은 값을 갖습니다.
- Word-level Diarization Error Rate
DER은 각 speaker의 speaking time을 기반으로 하지만, word-level DER (WDER)은 어휘 측면에서 발생하는 오류를 측정하기 위해 설계되었습니다. WDER은 DER과 마지막 transcript out 사이의 차이를 줄이기 위해 개발되었습니다. 최근에는 WDER 형식으로 ASR 및 speaker diarization system을 평가하고 있습니다. 연구마다 WDER 계산 방식이 다를 수는 있지만, 기본적인 mechanism은 올바르게 또는 잘못 labeling된 단어를 count하여 diarization error를 계산하는 것입니다.
Modular Speaker Diarization Systems
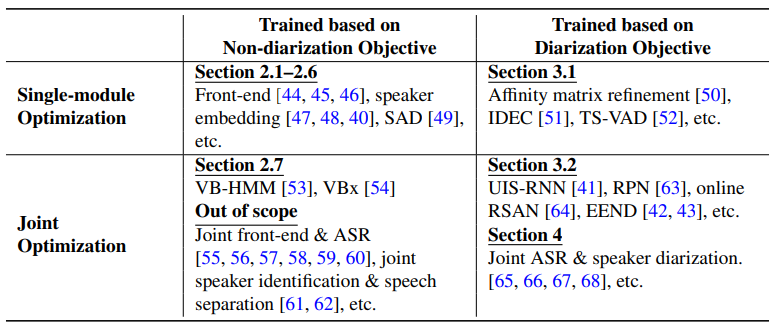
Non-diarization objective class에 속하는 algorithm들에 대해 보겠습니다. 각 subsection들은 전통적인 diarization system에 존재하는 각 module에 대한 설명들과 연관이 있습니다.
1. Front-end Processing
speaker diarization pipline의 일부로 사용되는 speech enhancement, dereverberation, speech separation, speech extraction을 위한 전처리 과정에 대한 내용입니다. s_(i, f, t) ∈ C를 source speaker i에 대해 frame t에 frequency bin f를 이용하는 STFT 표현이라고 하겠습니다. 관측된 noisy signal x_(t, f)는 source signal, room impulse response h_(i, f, t) ∈ C, additive noise n_(t, f) ∈ C의 혼합으로 표현할 수 있습니다.
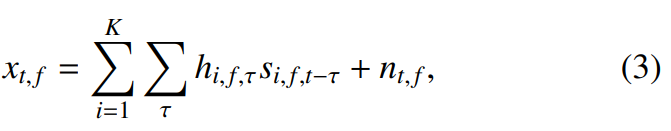
여기서 K는 audio signal에 있는 speaker 수를 나타냅니다.
front-end 기술의 목표는 관측치 X = ({x_(t,f)}_f)_t에 주어진 original source signal x_(i, t)^를 downstream diarization task로 추정하는 것입니다.
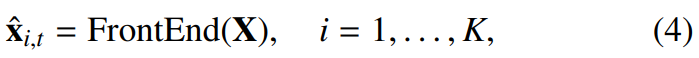
여기서 X_(i, t)^ ∈ C^D는 i번째 speaker의 추정된 frame t에서의 D frequency bin을 가 STFT spectrum을 의미합니다. 즉 audio에서 speaker에 대한 source만 뽑아내서 diarization task에 사용합니다.
1.1. Speech Enhancement and Denoising
speech enhancement 기술은 noise가 섞인 speech의 noise component를 억제하는 것이 목표입니다. 이는 주로 deep learning을 통해 효과적으로 진행할 수 있습니다. 예를 들어 LSTM-based speech enhancement를 front-end technique으로 사용했었습니다.

위 식과 같은 형태이며, 위 식은 single source example입니다.
1.2. Dereverberation
다른 front-end (전처리) 기술과 비교했을 때, 다양한 task에서 사용되는 주요 dereverberation 기술들은 통계적 신호 처리 method를 기반으로 합니다. 가장 널리 쓰이는 기술들 중 하나는 weighted prediction error (WPE) 기반 dereverberation입니다.
noise가 없는 single source에 대한 WPE의 기본 idea는 original signal model을 early reflection과 late reverberation으로 분해하는 것입니다. 식은 다음과 같습니다.
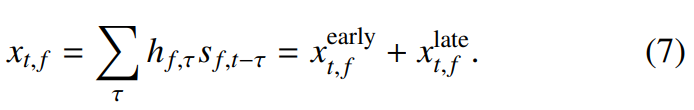
WPE는 early reflection을 유지하면서 late reverberation을 likelihood maximize하는 방식으로 억제합니다. filter coefficients h_(f, t)^(WPE) ∈ C를 추정합니다.

위 식에서 Δ는 early reflection과 late reverberation을 분리하는 frame 수를 나타내며, L은 filter isze를 의미합니다. early reflection은 소리가 발생한 직후 비교적 짧은 시간 내에 듣는 사람에게 도달하는 첫 번째 몇 차례의 reflection을 의미합니다. early reflection은 소리의 방향성과 공간감을 제공하는 데 중요한 역할을 합니다. early reflection은 일반적으로 원래 소리 신호와 비슷한 형태를 유지하며, 소리의 명료도와 존재감을 강화시킬 수 있습니다. late reverberation은 early relfection 이후에 발생하는 반사로, 소리가 여러 번 반사되어 생성되는 잔향 현상을 말합니다. 이는 실내 공간의 크기와 형태, 재질에 따라 달라지며, 일반적으로 소리가 더욱 퍼지고, 합쳐지며, 시간이 지남에 따라 점차 사라지는 특성을 갖습니다. late reverberation은 공간의 울림과 음향적 특성을 나타내지만, 과도하게 많을 경우 음성의 명료도를 떨어뜨리고 소리의 세부 정보를 흐립니다.
즉 WPE는 early reflection은 유지하면서 late reverberation을 억제하는 방식입니다.
1.3. Speech Separation
overlapping speech의 경우, speech separation은 매우 중요한 기술 중 하나입니다. beamforming 기반 multichannel speech separation의 효과는 널리 확인되었습니다. 예를 들어, CHiME-6 challenge에서, guided source separation (GSS) 기반 multichannel speech extraction 기술은 가장 높은 결과를 보였습니다. 반면에, single-channel speech separation은 현실적인 multispeaker scenario에서 큰 효과를 보이지 못하기도 합니다. single-channel speech separation system은 종종 중첩되지 않는 영역에 대해 불필요한 비음성 신호나 중복된 음성 신호를 생성하기도 합니다. 즉 많은 거짓된 경보가 발생되기도 합니다.
2. Speech Activity Detection
voice activity detection (VAD)라고도 알려진 SAD는 background noise와 같은 non-speech로부터 speech를 구별하는 기술입니다. SAD는 speaker diarization 뿐만 아니라 speaker recognition과 speech recognition system에서 중요한 역할을 합니다. SAD가 전처리 step에서 error를 만들 수 있으며, error가 존재하는 input을 사용하는 pipeline이 될 수 있기 때문에 특히 중요한 역할입니다.
SAD는 크게 2가지 part로 구성됩니다. 첫 번째, feature extraction front-end입니다. 그다음은, model이 input frame에 speech가 있는지 없는지를 예측하고 결정하는 part입니다. SAD는 spectrum, GMM 및 HMM에 기반한 통계 모델을 사용한 시스템이 전통적으로 사용합니다. 최근에는 deep learning 방식들이 기존 기술들보다 더 우수한 성능을 보이고 있습니다.
SAD의 성능은 상당량의 거짓 event를 생성하거나 speech segment를 놓칠 수 있기 때문에 speaker diarization system의 전체적인 성능에 영향을 줍니다.
3. Segmentation
speaker diarization 맥락에서, speech segmentation은 input audio stream을 여러 segment로 나누어 speaker 별 통일된 segment를 얻는 과정입니다. 따라서, speaker diarization system의 output unit은 segmentation process를 통해 결정됩니다. 일반적으로, speaker diarization을 위해 사용하는 speech segmentation method는 두 가지 category로 나눌 수 있습니다. speaker-change point detection과 uniform segmentation입니다.
speaker-change point detection을 이용한 segmentation은 초기 diarization system의 표준처럼 여겨졌습니다. speaker-change point는 speaker 변경 지점의 왼쪽과 오른쪽 speech window가 동일한 화자로부터 왔다고 가정하는 H_0와 서로 다른 speaker로부터 왔다고 가정하는 H_1을 비교하여 감지됩니다. 두 가설을 평가하기 위해, meetric-based approach는 가장 널리 사용되었습니다. metric-based approach는 speech feature의 분포가 N(μ, Σ) Gaussian distribution을 따른다고 추정합니다. 이 상황에서 두 가설 H_0와 H_1은 다음처럼 표현할 수 있습니다.
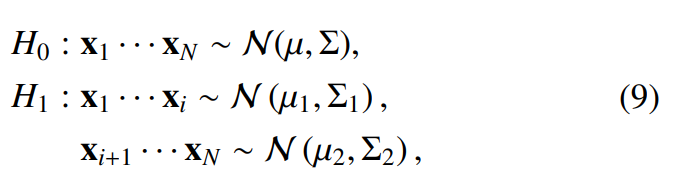
여기서 (x_i | i = 1, ... , N)은 가설을 평가할 speech feature의 sequence를 의미합니다. 두 가설의 likelihood를 정량화하여 평가하기 위해 다양한 metric-basd approach들이 제안되었습니다. KL divergence, Generalized Likelihood Ratio, BIC 등이 있습니다. 이러한 평가지표들 중에서 BIC는 수많은 변형을 거치면서 다양한 방식으로 사용되어 왔습니다. 만악 위 식에 BIC를 적용한다면 다음과 같습니다.
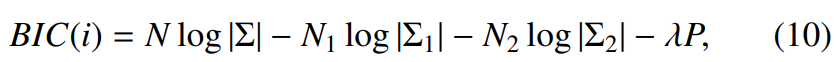
위 식은 두 가설 사이의 BIC value는 위와 같습니다. 여기서 Σ는 {x_1, ... , x_N}으로부터 구해지는 값이고, Σ_1은 {x_1, ... , x_i}로부터 구해지는 값이며, Σ_2는 {x_(i+1), ... , x_N}으로부터 구해지는 값입니다. 그리고 P는 penalty term이며 다음과 같습니다.
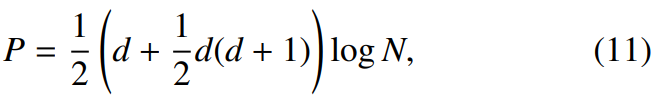
위 식에서 d는 feature의 dimension을 의미합니다. N은 N_1과 N_2의 합이며, N_1과 N_2는 각 window의 frame length를 의미합니다. penalty weight λ는 일반적으로 1로 설정합니다. 다음 식이 true가 된다면, change point가 true입니다. 즉 해당 point에서 speaker가 변했다는 뜻을 의미합니다.
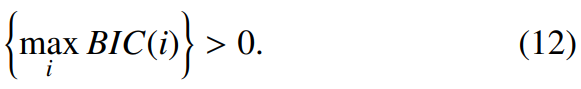
일반적으로, speech segmentation이 speaker change point detection method를 이용하여 진행되었다면, 각 segment의 length는 일관적이지 않습니다. 그렇기 때문에, i-vector와 DNN 기반 embedding의 등장 이후, speaker change point detection 기반의 segmentation은 uniform segmentation으로 대체되었습니다. 왜냐하면, segment의 다양한 길이들은 speaker representation의 추가적인 variability를 생성하고 speaker representation의 fidelity를 저하시켰기 때문입니다.
uniform segmentation 방식에서는, 주어진 audio stream input을 고정된 크기의 window length와 고정된 크기의 overlap length로 segment 합니다. 그러므로, speaker diarization output의 unit duration이 일정하게 유지됩니다. 그러나, diarization에서 input signal의 uniform segmentation 과정은 몇 가지 문제점을 갖게 됩니다. 왜냐하면 segment length와 관련된 trade-off error가 생기기 때문입니다. uniform segmentation을 이용해 얻은 segment는 multiple speaker를 포함하지 않기 위해 충분히 짧은 길이가 되어야 합니다. 하지만, 짧은 길이의 segmentation을 사용하게 된다면, speaker representation을 추출하기에 충분한 acoustic information을 추출하기 어려울 수 있습니다. 그래서 적당한 길이의 segmentation을 사용하는 것이 중요합니다.
4. Speaker Representations and Similarity Measure
speaker representation은 speech segment 사이의 similarity를 측정하는 speaker diarization system에서 매우 중요한 역할을 합니다.
4.1. Metric Based Similarity Measure
1990년대 후반부터 2000년대 초반까지, metric-based approaceh들이 similarity를 측정할 때 주로 사용되었습니다. speaker segmentation에 사용되는 방법들은 KL distance, GLR, BIC와 같은 segment사이의 similarity를 측정 방식들을 사용했습니다. metric-based 방식들은 주로 speaker-change point detection 기반 segmentation 방식과 함께 사용되었습니다.
4.2. Joint Factor Analysis, i-vector and PLDA
i-vector 또는 x-vector와 같은 speaker representation을 사용하기 이전에는 GMM-UBM을 이용해 acoustic feature를 얻었습니다. UBM은 speaker에 independent한 acoustic feature의 분포를 표현하도록 학습된 large GMM으로 구성되어 있습니다. 그러므로, GMM-UBM model은 mixture weigt, 평균값과 공분산 matrix으로 표현할 수 있습니다. speaker-adapted GMM과 speaker-independent GMM-UBM 사이의 log-likelihood ratio를 이용해 speaker verification을 진행했습니다. speaker identity에서의 성공에도 불구하고, GMM-UBM 기반 speaker verification system은 intersession variability에 의해 어려움을 겪었습니다. 동일한 speaker가 녹은한 sample들 사이의 variability에 의한 어려움을 의미합니다. 이러한 문제들은 GMM-UBM 기반 speaker verification system에서 speaker enrollment 과정 중에 이루어지는 MAP adaptation 단계가 speaker information 뿐만 아니라 channel noise와 acoustic environment와 같은 원치 않는 방해 요소들도 포착하기 때문에 발생합니다.
그래서 inter-speaker variaibility와 channel variability를 분리하여 modeling하는 Joint Factor Analysis (JFA)이 등장했습니다. JFA는 GMM supervector를 사용합니다. JFA를 이용한 speaker verification의 성능은 크게 향상했습니다. 하지만 여전히 문제가 있었습니다. channel variaibility에 speaker information이 존재한다는 문제가 있었습니다. 그래서 이를 해결하기 위해 등장한 방법이 i-vector입니다. i-vector는 LDA, WCCN, PLDA와 같은 다양한 기술들과 함께 사용되어 큰 성공을 얻었습니다.
4.3. Neural network Based Speaker Representations
speaker diarization에 사용되는 speaker representation 또한 deep learning 방식에 의해 크게 영향을 받았습니다. d-vector, x-vector, ECAPA-TDNN 등 다양한 방식들이 등장하며 큰 발전이 있었습니다.
5. Clustering
clustering algorithm은 speaker representation을 기반으로 하는 speech segments의 cluster를 만들 때 사용됩니다.
5.1. Agglomerative Hierarchical Clustering
AHC는 많은 speaker diarization system에서 BIC, KL, PLDA와 같은 distance matrix들과 함께 꾸준히 사용되고 있습니다. AHC는 존재하는 cluster들을 병합하는 반복적인 과정으로, clustering 결과가 특정 기준을 만족할 때까지 계속됩니다. AHC는 N개의 cluster들 사이의 similarity를 계산합니다. 그다음 가장 높은 similarity를 보이는 cluster의 쌍을 합병하는 step을 계속 진행합니다. 이러한 반복적인 합병 과정은 다음과 같습니다.
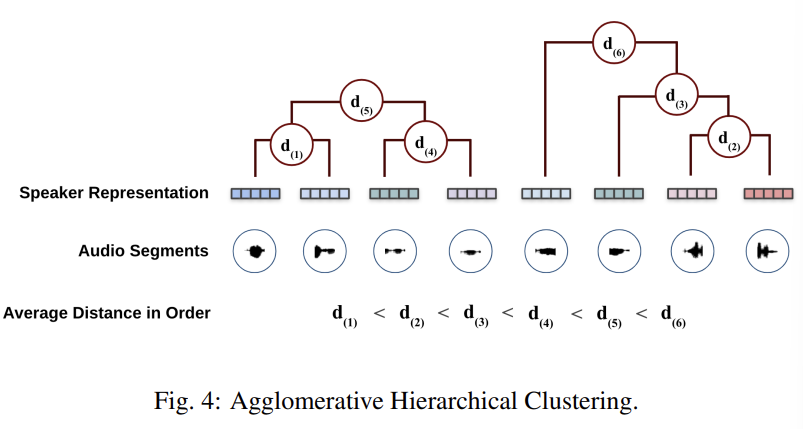
AHC의 가장 중요한 측면 중 하나는 정지 기준입니다. speaker diarization task에서, AHC은 similarity의 threshold를 이용하거나 cluster의 target number를 이용해 멈출 수 있습니다. 이상적으로는, 만약 PLDA를 distance metric으로 사용한다면, AHC는 s(Φ_1, Φ_2) = 0일 때 멈추게 됩니다. 그러나, stopping metric은 정확한 clustering을 하기 이해선 조절되어야만 합니다. 대조적으로, speaker의 수를 알고 있거나 추정할 수 있다면, AHC는 사전에 정한 speaker 수 k가 된다면 멈출 수 있습니다.
5.2. Spectral Clustering
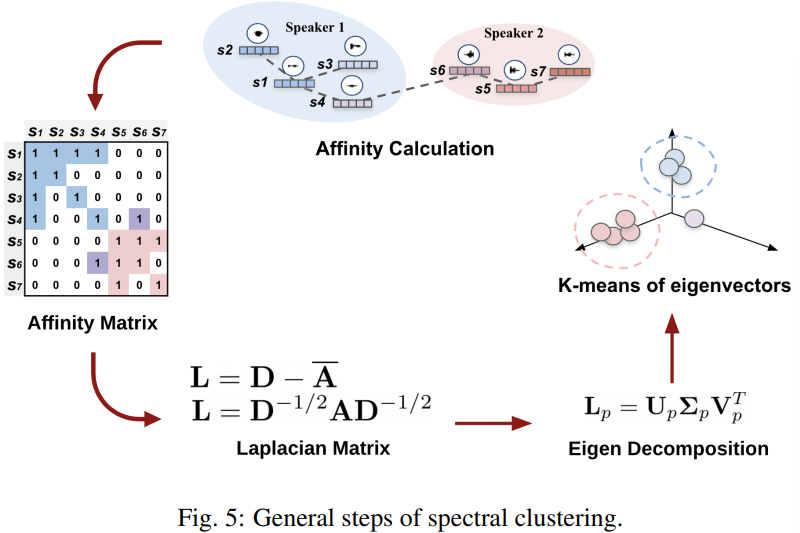
spectral clustering은 speaker diarization에서 널리 사용되는 clustering 방식입니다. 다양한 변형된 spectral clustering들이 있지만, 대부분의 spectral clustering은 다음 step을 거칩니다.
- Affinity matrix calculation: affinity value에 따라 affinity matrix A를 만드는 데 다양한 방식들이 존재합니다. raw affinity value d는 scaling parameter σ를 사용하는 exp(-d^2 / σ^2)와 같이 kernel을 이용해 구할 수 있습니다. 반면에, raw affinity value d는 threshold 아래의 값들은 0으로 만들어서 두드러진 value들만 남기도록 하여 만들 수도 있습니다.
- Laplacian matrix caculation: graph Laplacian은 normalized & unnormalized 방식으로 계산될 수 있습니다. degree matrix D가 affinity matrix의 각 열들의 합을 대각행렬 d로 가지고 있는 형태라 하겠습니다. 이때 graph Laplacian은 다음과 같이 구할 수 있습니다.
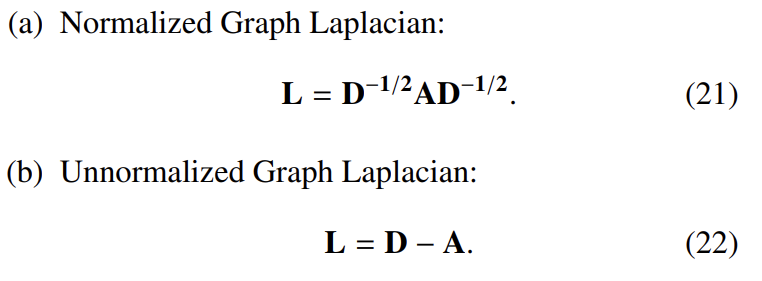
- Eigen decomposition: graph Laplacian matrix L을 eigenvector matrix X와 eigenvalue를 가지고 있는 diagonal matrix로 분해합니다. 그래서 L = XΛXT가 됩니다.
- Re-normalizaion (optional): X의 열을 normalize합니다.
- Speaker counting: maximum eigengap을 찾아 speaker 수를 추정합니다.
- Spectral embedding clustering: 가장 작은 eigenvalue들과 그 value에 해당하는 eigenvector들을 stack하여 matirx U를 만듭니다. U ∈ R^(nxk)입니다. U의 행 vector는 k차원의 spectral embedding입니다. 마지막으로, spectral embedding들을 clustering algorithm으로 clustering합니다. 일반적으로 k-mean clustering을 사용하여 spectral embedding을 clustering합니다.
spectral clustering algorithm의 다양한 변형된 version들 중에 NG-Jordan-Weiss (NJW) algorithm은 affinity value를 계산하기 위해 kernel의 다양한 변형과 함께 speaker diarizaiton task에서 종종 사용됩니다. AHC 방식과는 다르게, spectral clustering은 cosine distance와 함께 가장 많이 쓰입니다. 추가적으로, LSTM 기반 similarity을 사용하는 spectral clustering 또한 비교 가능한 정도의 성능을 보여줍니다. dataset에 따라 spectral clustering을 cosine distance와 함꼐 사용했을 때, AHC를 PLDA와 사용했을 때보다 더 좋은 성능을 보이기도 합니다.
5.3. Other Clustering Algorithms
k-mean algorithm은 간단하고 사용하기 용이하기 때문에 speaker diarization에서 종종 사용됩니다. 그러나, k-mean algorithm은 일반적으로 spectral clustering이나 AHC와 같이 잘 알려진 clustering algorithm에 비해 성능이 떨어집니다. 몇몇 speaker diarization 연구에서는 mean-shifting clustering algorithm을 사용합니다. 이는 주어진 data point를 non-parametric distribution의 mode를 찾아 clustering을 반복적으로 진행하는 방식입니다. mean-shifting clustering algorithm은 KL distance와 함께 speaker diarization에 사용되기도 하며, i-vector와 cosine distance와 함꼐 사용되거나, i-vector와 PLDA와 함께 사용되기도 합니다.
6. Post-processing
6.1. Resegmentation
resegmentation은 clustering을 사용하여 대략적으로 추정된 speaker boundary를 정제하는 과정입니다. Baum-Welch algorithm을 사용하여 Viterbi resegmentation method가 등장하기도 했습니다. Viterbi resegmentation method는 각 speaker에 해당하는 GMM을 추정과 추정된 speaker GMM을 사용하는 Viteribi-algorithm 기반 resegmentation을 번갈아 적용하는 방식입니다.
6.2. System Fusion
post processing의 다른 방법으로, diarization 정확도를 향상시키기 위해 여러 개의 diarization 결과를 fusion하는 방식입니다. system combination이 일반적으로 다양한 system (e.g., speech recognition, speaker recognition)에서 더 좋은 결과를 만들어준다고 널리 알려져 있지만, 다양한 diarization hypotheses를 결합하는 것은 몇 가지 고유한 문제를 발생시킵니다. 먼저, speaker labeling은 다른 diarization system간에 표준화되지 않습니다. 두 번째, 추정된 speaker 수는 다른 diarization system마다 다를 수 있습니다. 마지막으로, 추정된 time boundaries는 다른 diarization system마다 다를 수 있습니다. speaker diarization에서 system combination method는 multiple hypotheses의 fusion 과정에서 이러한 문제들을 해결해야만 합니다.
많은 diarization system들 중에 가장 놓은 diarization result를 고르는 방식으로 문제를 해결하기도 했습니다. 이 방식에서는, 각 diarization system에서 녹음에 대한 diarization result의 전체 sequence를 하나의 객체로 취급하여 clustering합니다. 그다음 두 cluster 간의 거리가 두 cluster에 속한 diarization result 간의 대칭 DER을 사용하여 측정되는 diarization 결과의 집합에 AHC를 적용합니다. 마지막으로, 각 cluster 내 element 수에 따라 두 최종 cluster 중 더 큰 cluster에서, 모든 다른 diarization result들에 대한 distance가 가장 작은 diarization result를 최종 output으로 선택하는 방식입니다.
그 다음 DOVER method도 등장했습니다.
7. Joint Optimization of Segmentation and Clustering
VB-HMM 기반 diarization technique에 대해 말해보겠습니다. 이는 segmentation과 clustering을 동시에 optimization할 수 있는 방식입니다. VB-HMM framework는 VB 기반 speaker clustering의 확장된 version입니다. VB-HMM framework는 speech feature X = (x_t | t = 1, ... , T)를 HMM에 의해 만들어진 것으로 여기며, 각 HMM state는 K명의 가능한 speaker 중 하나에 해당됩니다. M 개의 HMM state가 있다고 가정했을 때, M 차원 variable Z = (z_t | t = 1, ... , T)에서 k번째 speaker가 time index t때 말을 했다면 z_t의 k번째 element는 1이 되고 나머지는 0이 됩니다. x_t의 분포는 hidden variable Y = (y_k | k = 1, ... , K)에 의해 modeling되며, y_k는 k번째 speaker의 저차원 vector를 의미합니다. 이때 X, Y, Z의 결합 분포는 다음과 같이 표현할 수 있습니다.
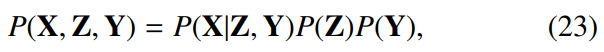
P(X|Z, Y)는 Y에 의해 표현된 평균 vector를 가지고 있는 GMM에 의해 modeling된 발생 확률을 의미하고, P(Z)는 HMM의 전환 확률, P(Y)는 Y의 prior 분포입니다. Z는 speaker의 경로를 나타내기 때문에, diarization은 P(Z|X) = ∫P(Z, Y|X)dY를 maximize하는 Z의 inference 문제로 표현될 수 있습니다. 이 문제를 직접적으로 구할 수 없기 때문에 VB method를 사용하여 P(Z, Y|X)를 근사하는 model parameter를 추정하는 방식으로 해결합니다.
최근에는 x-vector에서 동작하는 VB-HMM의 간소화된 version인 VBx가 제안되었습니다. VBx에서 P(X|Z, Y)는 PLDA model을 기반으로 하는 x-vector르 사용하여 계산됩니다. original VB-HMM은 frame-level feature에서 동작하는 반면, VBx는 x-vector에 동작하며 speaker 전환과 speaker 지속 시간을 공동으로 modeling하는 clustering 방식으로 볼 수 있습니다.
VB-HMM diarization은 원래 독립적인 diarization framework로 설계되었습니다. 하지만, VB 추정을 시작하기 위해 parameter 초기화가 필요하며, parameter는 일반적으로 다른 speaker clustering의 결과를 기반으로 초기화됩니다. 그 맥락에서, VB-HMM은 speaker diarization에서의 마지막 step에 주로 사용됩니다. AHC를 먼저 사용하여 x-vector를 clustering합니다. 그다음 AHC을 통해 얻은 얻은 clustering 결과를 초기 parameter로 사용하여 VBx를 진행합니다. 그 다음 VB-HMM을 사용하여 VBx에서 얻은 boundary를 refine하는 방식으로 진행됩니다.


