https://arxiv.org/abs/2012.10055
End-to-End Speaker Diarization as Post-Processing
This paper investigates the utilization of an end-to-end diarization model as post-processing of conventional clustering-based diarization. Clustering-based diarization methods partition frames into clusters of the number of speakers; thus, they typically
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문에서 저자들은 전통적인 clustering 기반 diarization의 post-processing으로 end-to-end diarization model의 활용성에 대해 연구합니다. clustering기반 diarization 방식은 frame을 speaker 수의 cluster로 분할하기 때문에, 일반적으로 overlapping speech를 다룰 수 없습니다. 왜냐하면 각 frame마다 1명의 speaker로 할당되기 때문입니다. 반면에 end-to-end diarization 방식은 multi-label classification을 활용해 overlapping speech를 다룰 수 있습니다. 몇몇 방식들은 speaker 수를 flexible하게 다룰 수 있는 반면, speaker 수가 많다면 잘 동작하지 않습니다. 서로의 약점을 보완하기 위해, 저자들은 two-speaker end-to-end diarization method를 제안합니다. two-speaker end-to-end diarization을 clustering based method를 이용해 얻은 결과에 post-processing으로 사용하는 방식입니다. 저자들은 반복적으로 2명의 speaker를 선택하고 두 speaker의 결과를 update하여 overlapped region을 개선합니다.
Introduction
"누가 언제 말을 했는지"를 구분하는 speaker diarization은 많은 speech관련 application에서 중요한 역할을 합니다. speaker diarization은 speaker 특성을 추가함으로써 transcription을 풍부하게 만드는데 사용되기도 하고, speech separation & recognition의 성능을 향상시키기 위해서 사용되기도 합니다.
Speaker diarization method는 크게 2개로 나눌 수 있습니다: clustering based method, end-to-end method입니다. 일반적인 clustering based method는 다음과 같은 순서로 진행됩니다.
1. frame을 speech와 non-speech로 분류합니다.
2. 각 speech frame에서 speaker characteristics을 표현하는 embedding을 추출합니다.
3. 추출된 embedding에 clustering을 적용합니다.
대부분의 방식들은 agglomerative hierarchical clustering (AHC)과 k-means clustering과 같은 hard clustering 방식을 사용합니다. 그에 따른 결과로 각 frame은 speaker cluster 중 하나나 non-speech cluster에 속하게 됩니다. 이러한 clustering 기반 방식들은 각 frame들이 최대 1명의 speaker를 포함하고 있다고 기본적으로 가정합니다. 즉, speaker diarization을 집합 분할 문제로 취급합니다. 그렇기 때문에, 여러 명의 speaker가 동시에 말하고 있는 speech에는 적용할 수 없습니다. 이러한 가정에도 불구하고, DIHARD 2 dataset과 같이 많은 수의 speaker를 포함한 dataset에서는 end-to-end method보다 cluster-based method들이 여전히 baseline으로 사용되고 있습니다. 이는 train data로 어떠한 음성 혼합도 사용하지 않고 unsupervised clustering을 기반으로 multi-speaker problem을 다루기 때문입니다. 따라서, 특히 많은 수의 speaker에 대해서는 overlap speech가 부족하기 때문에 overfitting되지 않습니다.
반면에, EEND라고 불리는 end-to-end method는 speaker diarization을 multi-label classification문제처럼 다룹니다. end-to-end method는 각 frame에서 각 speaker가 말을 했는지 안했는지에 대해 예측을 합니다. 그래서 speaker overlap을 다룰 수 있습니다. 초기 model의 평가는 speaker 수를 2명으로 고정했습니다. 최근에는 speaker 수를 모르는 case에 대해서도 다루도록 확정되었습니다. 예를 들어, encodoer-decoder 기반의 attraction calculation과 speaker conditioned model을 이용하는 one-by-one perdiction이 있습니다. 그러나, 이러한 방법들은 여전히 speaker 수가 많은 경우에 성능이 좋지 않습니다. 이러한 이유 중 하나로 training dataset이 있습니다. 여러 명의 speaker가 섞인 data는 다양한 dataset에서도 드물기 때문에, end-to-end model가 적은 수의 speaker의 data에 overtraining되어 speaker 수가 많은 data에 대해 diarization을 잘 수행할 수 없습니다. 만약 다양한 speaker가 혼합된 data수가 많다고 하더라도, EEND는 순열 불변 훈련(어떤 time에 어떤 speaker가 말을 했는지 고정되어 있는 상태이며, 이를 다 예측할 수 있도록 학습해야 한다)에 의존하기 때문에, 많은 수의 mixture data로 model을 학습하는 것은 연산량이 너무 많이 필요합니다. 이러한 이유들로 인해, 여러 명의 speaker가 overlapping되고 있는 speech를 포함하고 있는 data를 다루는 것은 end-to-end 방식이나 clustering 방식 모두 여전히 해결되지 않은 문제입니다.
이 논문에서, 저자들은 clustering based method와 end-to-end method를 결합하여 speaker 수에 영향을 받지 않으면서 overlapping speech를 효율적으로 다루는 방법을 제안합니다. overlapping result를 생성하지 않는 x-vector clustering을 사용하여 초기 diarization을 얻습니다. 그 다음 저자들은 두 단계를 반복적으로 진행합니다. 1) 2명의 speaker만 존재하거나 침묵인 frame을 선택. 2) 2명의 speaker에 대한 EEND model을 사용해 overlap을 추정. frame 선택은 2명 이상의 speaker가 존재하는 dataset으로 EEND model을 적응시키는 데에도 사용됩니다.
Related Work
Clustering-based diarization
몇몇 방식들은 speaker embedding의 supervised clustering을 제공하지만, 제일 흔한 접근법은 unsuperivsed 상황에서의 x-vector clustering입니다. 기본적인 x-vector clustering 성능은 좋지 않기 때문에, PLDA rescoring, VB-HMM resegmentation과 같은 다양한 기술들이 성능을 향상시키기 위해 등장했습니다. overlap 처리를 보면, 대부분의 method들은 먼저 overlapped frame들을 찾아냅니다. 그다음 heuristic 기반 frame 탐지나 VB resegmentation 결과를 기반으로 second speaker를 할당합니다.
또 다른 방식은 overlap된 segment의 clustering을 기반으로 하는 방식입니다. 이 방법은 먼저 overlapped segment를 추출합니다. 그다음 각 segment에서 추출된 embedding에 clustering을 진행합니다. 이 방법은 sliding window를 사용하여 embedding을 추출하지만, end-to-end method와 비교 못할 정도의 좋지 않은 정확도를 보여줍니다.
End-to-end diarization for overlapping speech
end-to-end 접근법 중 하나는 EEND입니다. 이는 각 단일 speaker에 해당하는 multipler speaker activity를 계산합니다. 최근 model은 encoder-decoder 기반 attractor calcuation module (EDA)나 speaker-conditional EEND (SC-EEND)를 사용하여 speaker의 activity 수에 flexible한 output을 만들 수 있습니다. RSAN이라고 불리는 다른 접근법은 time-frequency domain에서 speaker를 하나씩 추출하기 위해 residual mask를 기반으로 합니다.
EEND와 RSAN은 acoustic feature만 input으로 받지만, 이러한 방식들의 변형은 target-speaker를 결정하기 위해 speaker embedding을 input으로 받으며 his/her speech activity를 output으로 합니다. 예를 들어, target-speaker voice activity detection (TS-VAD)는 speaker의 voice activity에 대응하는 output으로 i-vector를 사용합니다. 하지만 speaker 수는 model 구조에 의해 고정됩니다. Personal VAD와 VoiceFilter-Lite는 d-vector를 기반으로 하며, 이는 speaker 수에 대한 한계는 없지만 각 speaker의 d-vector가 database에 저장되어 있어야 한다고 가정하기 때문에, speaker-independent diarization에는 적합하지 않습니다.
Proposed Method
Overview
주어인 acoustic feature (x_t), t= 1, ... , T에서 t는 frame index를 의미합니다. diarization은 각 speaeker k ∈ {1, ... , K}에 대한 active frames T_k ⊆ {1, ... , T}을 예측하는 문제입니다. K는 추정된 speaker 수를 의미합니다.
clustering 기반 방식은 input recording에 speaker overlap이 없다고 가정합니다. 반면에 EEND는 diarization을 overlapping speech에 대한 multi-label classification으로 다룹니다. 그렇기 때문에 각 speaker의 active frame이 겹쳐도 됩니다. EEND는 speaker들이 동시에 말하는 실제 대화에 적합합니다. 그러나 이는 문제를 해결하기에 너무 어렵게 만듭니다. K가 10처럼 크다면, K명의 speaker가 동시에 말하는 것은 흔하지 않습니다. 그러므로, 최대 K'(<K) speaker가 동시에 말한다고 가정하고, 최대 K' speaker를 처리할 수 있도록 학습된 end-to-end model을 사용하는 clustering 기반 결과를 refine합니다. 이 연구에서는 K' = 2로 두고 진행합니다.
Algorithm
주어진 초기 diarization results는 {T_k | ∅ ≠ T_k ⊆ [T]}, k = 1, ... , K입니다. 여기서 저자들은 diarization results에서 K 명 중에 2명 speaker를 반복적으로 선택하여, EEND model을 사용하여 두 speaker 사이의 diarization 결과를 update합니다. EEND model f_EEND : R^(DxL) ⇒ (0, 1)^(2xL)은 D차원의 acoustic feature의 L 길이의 sequence로부터 두 speaker의 posterior 확률을 추정하기 위해 학습됩니다. 그림은 다음과 같습니다.
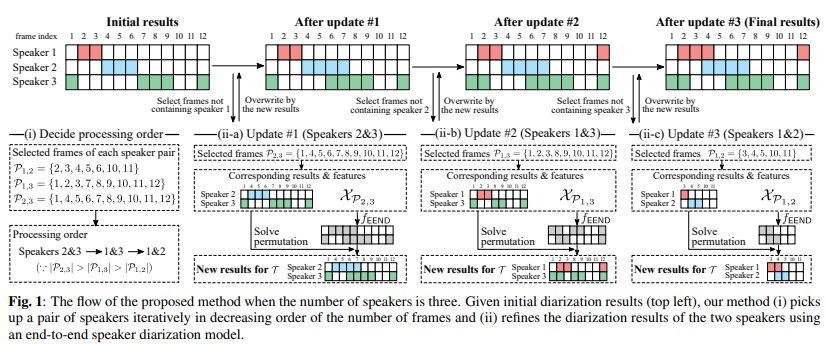
위 그림은 K = 3일 때의 모습입니다.
- Processing order determination
각 speaker pair에 반복적인 refinement를 적용하기 위해, 처리 순서는 마지막 diarization result의 정확도에 영향을 줍니다. 추정된 diarization result를 기반으로 2명의 speaker만 포함된 frame을 선택하고 싶지만, diarization result에는 error가 있기 때문에 이는 불가능합니다. 예를 들어 저자들이 위 그림에서 speaker 1을 포함하지 않는 frame을 처음으로 선택한다면, 마지막 result를 보면 4번째 frame에는 speaker 1이 존재하게 됩니다. 선택된 frame 중 이러한 impurity의 비율이 높다면, EEND를 사용한 refinement의 결과는 좋지 않을 것입니다. 저자들은 선택된 쌍에 존재하는 frame 수를 내림차순으로 하여 순서대로 진행한다면 이러한 문제를 간단하게 해결할 수 있다는 것을 알아냈습니다. 각 speaker 쌍 {i, j} ∈ K_C_2에 대해, 저자들은 i와 j speaker를 제외한 다른 speaker들이 포함되지 않는 frame set P_(i, j)를 먼저 선택합니다. 식으로 표현하면 다음과 같습니다.
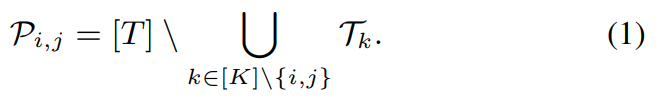
그다음 저자들은 P_i, j의 크기에 내림 차순으로 speaker 쌍을 선택하여 refinement를 진행합니다.
- Iterative update of diarization results
speaker i와 j에 대한 diarization result를 update하기 위해, 저자들은 set of frame P_(i, j)를 (1) 식과 같은 방식으로 다시 선택합니다. diarization results는 각 refinement step마다 update되기 때문에 계속 새로 선택해야 합니다. 그다음 대응하는 feature X_P_(i,j)을 EEND model에 input하여 두 speaker에 대한 posterior (a), (b)를 다음 식을 이용해 얻습니다.
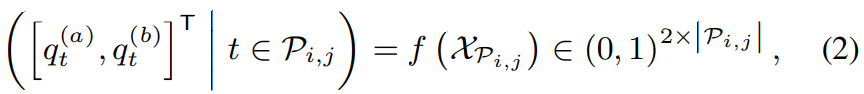
여기서 q_t^(a)와 q_t^(b)는 t번째 frame의 첫번째 speaker와 두 번째 speaker의 posterior를 의미합니다. 저자들은 threshold value를 0.5로 설정하여 두 speaker의 active frame의 index를 얻습니다. 식은 다음과 같습니다.
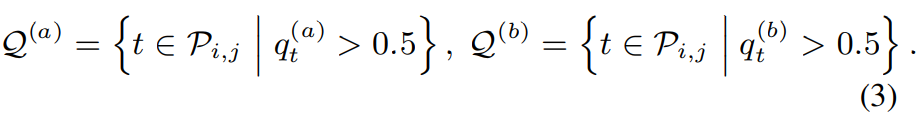
(a)-(b)와 i-j 사이에 speaker 순열에 대한 모호성이 있으며, 저자들은 다음과 같은 식을 통해 순열 문제를 해결하여 (T_i, T_j)와 (Q^(a), Q^(b)) 사이의 optimal correspondence를 찾습니다.
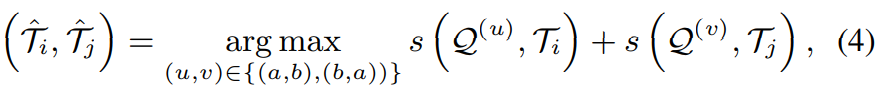
여기서 s(u, v)는 두 집합 u와 v에서 speech activities와 non-speech activities 사이의 유사도를 계산하는 함수를 의미하며 식은 다음과 같습니다.

마지막으로, 저자들은 speaker i와 j의 diarization 결과를 update합니다. 새로운 result speaker i와 j에 대한 연산 결과 T_i^와 T_j^를 확인하기 위해, 저자들은 다음 condition을 만족하는지 아닌지 확인합니다.

여기서 α는 새로운 결과 T_i^(또는 T_j^)와 이전 결과 T_i∩P_(i,j)(또는 T_j∩P_(i,j)) 사이의 교차 비율의 lower bound를 의미합니다. 저자들은 α = 0.5로 설정하고 진행했습니다. 만약 위 (6) condition만 만족한다면, 저자들은 speaker i와 j의 결과를 update합니다. K = 2일 때, 저자들은 다음 식을 이용해 간단하게 결과를 update합니다.
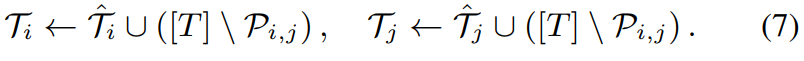
반면에 K가 3보다 크거나 같다면, 선택된 frame의 impurity 때문에 performance가 감소되게 됩니다. 그래서, 저자들은 위 식 대신 다음과 같이 overlapped frame만 update합니다.
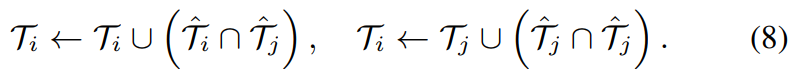
(위 식에서 오른쪽 T_i를 보면 T_j로 수정해야 할 것 같고, 괄호 안에도 하나는 T_i가 되야 할 것 같습니다...)
end-to-end model f_EEND에 대해, 저자들은 self-attentive EEND model을 encoder-decoder attractor calculation module와 함께 사용해 구현했습니다 (SA-EEND-EDA). 각 frame의 embedding을 추출하기 위해 4 layer로 구성된 transformer encoder를 사용하고 EDA module을 사용하여 추출된 embedding의 attractor를 계산했습니다. EDA는 LSTM을 포함하고 있지만, embedding 순서를 섞은 후에 EDA로 들어옵니다. 이를 통해 diarization performance를 향상시킬 수 있었습니다. 그러므로 저자들은 f_EEND의 모든 요소들을 embedding 순서와는 독립적으로 만들었으며, model은 선택된 frame의 input feature를 처리할 수 있게 됩니다.
Training strategy of the SA-EEND-EDA model
original EEND는 model adaptation을 위해 matched dataset을 사용했습니다. 예를 들어 original dataset에서 2명의 speaker가 말하고 있는 subset만 이용하여 model을 two-speaker에 대해 finetune하는 방식입니다. 이러한 전략은 dataset이 2명의 speaker의 mixture를 포함하고 있지 않다면 fine-tuned model을 사용할 수 없게 됩니다. 만약 dataset에 2명의 speaker mixture가 존재하더라도, dataset 전체를 사용하지 않기 때문에 성능 저하를 야기할 수 있습니다.
그래서 저자들은 frame-selection 기술을 사용해 model adaptation에 사용합니다. 만약 input chunk가 2명 이상의 speaker를 포함하고 있다면, 저자들은 2명의 지배적인 speaker를 선택한 다음 다른 speaker들이 active하고 있는 다른 frame들을 제거합니다. model은 두 speaker의 speech activities를 output하기 위해 선택된 frame만을 사용하여 학습됩니다. 이를 통해 어떠한 multi-speaker dataset에서 mixture-wise selection 없이 2 speaker model을 finetuning할 수 있게 됩니다.
Experiment
Settings
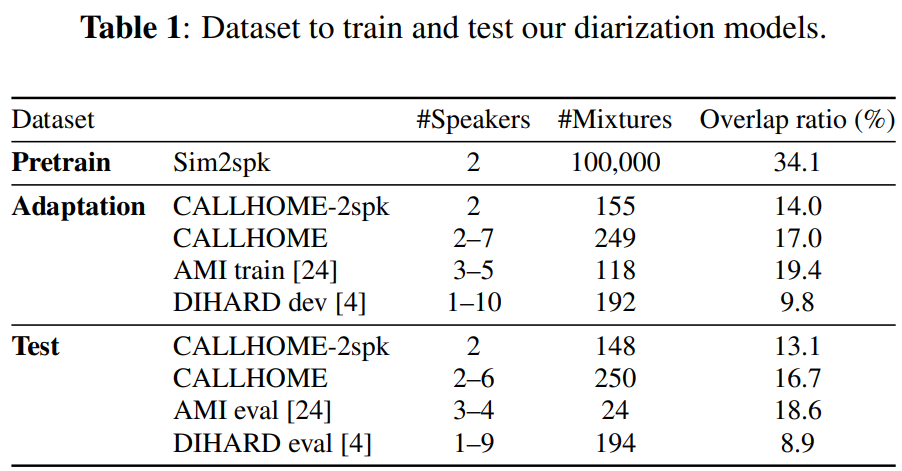
위 table은 저자들이 실험에 사용한 dataset을 보여줍니다. model은 2명의 speaker가 섞여있는 Sim2spk data를 이용해 pretrain 되어 있습니다. 각 mixture는 2명의 speaker audio로 섞여있는 형태입니다. 그리고 noise와 room impulse response를 추가하였습니다.
pretrain 이후에, model은 CALLHOME, AMI, DIHARD Ⅱ dataset에 adapt 했습니다. 저자들은 DER과 JER을 이용해 평가를 진행합니다.
Preliminary evaluation of the training using frame selection
저자들이 제안한 post-processing method를 평가하기 전에, 저자들은 먼저 SA-EEND와 SA-EEND-EDA model의 training 전략에 대해 평가합니다. CALLHOME-2spk를 사용해 학습했지만, 저자들은 CALLHOME dataset에 존재하는 2명 speaker의 mixture datapoint보다 더 많이 2명 speaker mixture datapoint를 사용합니다.
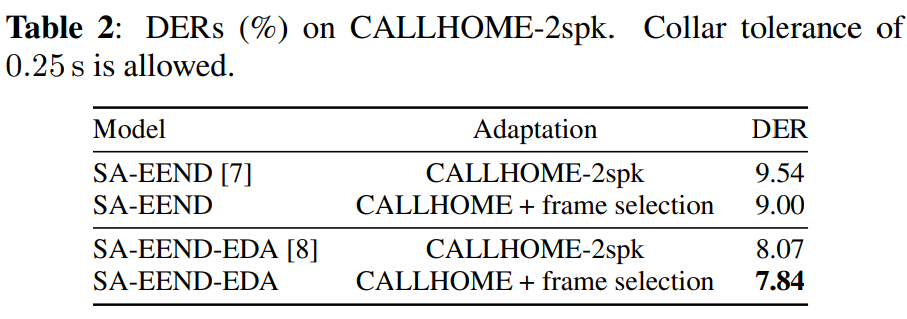
위 표는 CALLHOME-2spk test set에 대한 DER score입니다. SA-EEND의 경우, frame-selection을 했을 때 DER 수치가 더 좋아진 것을 볼 수 있으며, SA-EEND-EDA에 frame-selection을 적용했을 때도 성능이 좋아진 것을 볼 수 있습니다. 이러한 결과를 토대로, frame-selection 기반 training 전략의 효율성을 확인할 수 있습니다.
Results
- CALLHOME
먼저 저자들은 CALLHOME dataset을 이용해 실험을 진행합니다. CALLHOME dataset은 전화 통화 datda입니다. x-vector를 AHC와 PLDA랑 함께 사용한 clustering based baseline은 TDNN-based speec hactivity detection와 함께 사용되었습니다. 그리고 저자들은 VB-HMM resegmentation을 사용한 결과도 준비했습니다.
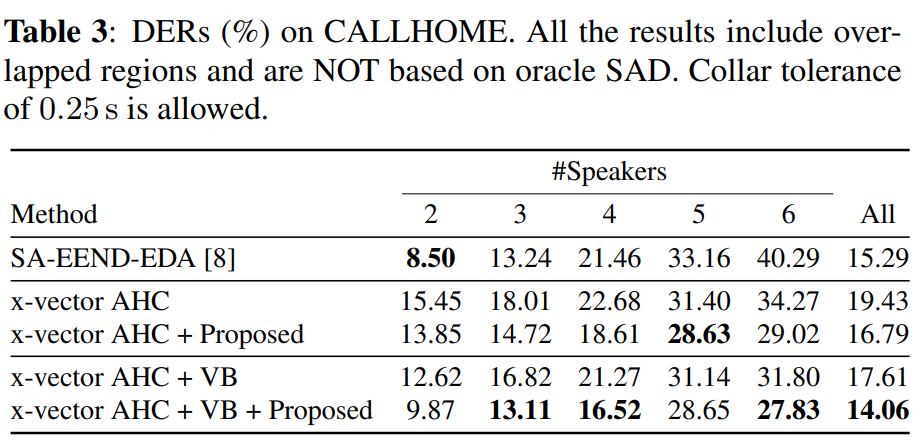
위 표는 실험 결과를 보여줍니다. x-vector clustering과 SA-EEND-EDA를 비교한 DER 결과입니다. SA-EEND-EDA는 화자 수가 flexible한 경우에서는 outperform하지는 않습니다. 그러나, clustering based method가 4명 이상의 speaker일 때 더 좋은 결과를 보입니다. 즉, 2, 3명일 때는 SA-EEND-EDA가 더 좋은 결과를 보여줍니다.
- AMI
그다음 저자들은 AMI dataset 결과입니다. AMI dataset은 meeting recording 결과입니다.

위 결과를 보면, 저자들이 제안한 방식을 사용했을 때, 결과가 더 좋아진 모습을 볼 수 있습니다.
Conclusion
이 논문에서, 저자들은 clustering based diarization에 end-to-end diarization model을 사용하는 post-processing method를 제안합니다. 저자들은 2명의 speaker를 고르고, 해당 speaker가 포함된 frame을 고른 후 end-to-end model로 처리해 diarization result를 update하는 과정을 여러 번 반복합니다. 저자들이 제안한 방식이 다양한 dataset에서 clustering based diarization result를 개선시킨다는 것을 보여줍니다.


