https://ieeexplore.ieee.org/document/7953094
Speaker diarization using deep neural network embeddings
Speaker diarization is an important front-end for many speech technologies in the presence of multiple speakers, but current methods that employ i-vector clustering for short segments of speech are potentially too cumbersome and costly for the front-end ro
ieeexplore.ieee.org
해당 논문을 보고 작성했습니다.
Abstract
speaker diarization은 다수의 speaker가 존재할 때, 많은 음성 기술에 있어 중요한 front-end입니다. 그러나 현재 등장한 방식들은 speech의 짧은 segment에 i-vector clustering을 하는 방식인데, 이는 front-end 역할에 있어서 너무 번거롭고 비용이 많이 듭니다. 그래서 저자들은, i-vector를 추출하는 과정을 제거하기 위해 deep neural network을 통해 representation을 학습하는 접근법을 제안합니다. 저자들이 제안한 구조는 가변 길이의 acoustic segment의 고정도니 차원의 embedding을 학습하면서 같은 speaker로부터 녹음된 segment인지에 대한 likelihood를 구하는 scoring function을 동시에 학습합니다. CALLHOME를 이용한 test를 통해, 저자들이 제안한 system이 diarization system의 구조를 간소화할 뿐만 아니라 최신 baseline의 성능과 비슷하거나 뛰어넘는다는 것을 보여줍니다.
Introduction
speaker diarization은 speech에서 speaker에 해당하는 segment를 grouping하는 task입니다. speaker diarzation은 "who is speaking when"이라고 종종 표현되기도 합니다. speech recognition, speaker recognition과 같은 많은 음성 처리 기술들이 현재 오직 1명의 speaker에 대해 추정하기 때문에, diarization은 single-speaker가 아닌 경우에 매우 중요한 front-end scenario가 될 수 있습니다.
최근 등장한 많은 diarization의 발전들은 speech의 short segment에서 i-vector를 추출하여 사용합니다. 최근 i-vector 구조는 2개의 분리된 처리로 구성됩니다. i-vector를 추출한 후 PLDA scoring function을 학습해 두 i-vector가 동일한 speaker에서 왔는지 아닌지를 결정합니다. i-vector를 추출하는 것은 GMM과 projection matrix T를 사용하는 factor analysis를 필요로 합니다.
이 논문에서, 저자들은 고정된 차원의 embedidng을 학습하는 것과 scoring metric을 동시에 학습하는 DNN을 사용하여 위 2 단계를 대체하는 방식을 제안합니다. 이러한 특정한 구조는 최근에 speaker recognition에서 효과를 보였습니다. 그리고 학습된 embedding은 전통적인 i-vector보다 speech의 더 짧은 영역도 효과적으로 표현할 수 있습니다. 그래서 저자들은 DNN을 이용해 speaker diarization을 해결하는 방식을 제안합니다.
Background
I-vector는 speaker recognition을 위해 개발된 후 곧바로 speaker diarization에 적용되었으며, 그 이후로 꾸준한 발전이 있었습니다. 초기에는 세분화된 음성에 대해 i-vetor를 사용하여 block 간의 유사도를 cosine score로 평가하고, k-mean or spectral clustering을 이용해 clustering했습니다. diarization을 위한 i-vector에 적용하는 다른 clustering algorithm들로 VB-GMM, mean shift, agglomerative hierarchical clustering (AHC)가 있습니다. 저자들도 AHC를 사용해 연구를 진행했다고 합니다.
최근에는 PLDA를 이용한 cosine scoring은 기존 방식들보다 더 좋은 성능을 보였으며, AHC clustering에 speaker prior를 통합함으로써 error를 줄일 수 있다는 것도 밝혀졌습니다. 전통적인 unsupervised GMM-UBM은 최근에 DNN으로 대체되기도 했습니다.
segmentation based 접근법들의 단점 중 하나는, diarization 결과 표시가 segmentation boundary에 따라 시작과 끝이 제한된다는 점입니다. 이를 해결하기 위해, resegmentation이라 불리는 diarization의 다음 단계가 추가되었습니다. resegmentation은 clustering의 결과를 이용해 frame-level diarization system을 초기화하며, speaker turn의 boundary를 반복적으로 refine합니다. 이전에는 대부분의 resegmentation들은 acoustic feature space에서 HMM을 이용해 수행되었지만, 최근 연구에서는 subspace에서 resegmentation하는 기술들이 더 효과적이라는 것을 보이고 있습니다.
이 논문에서, 저자들은 고정된 차원의 embedding과 scoring metric를 동시에 학습하는 훈련된 DNN을 제안합니다. 이 방식은 최근에 speaker recognition에서 유망한 결과를 보였습니다. 개념적으로 유사한 DNN embedding은 최근 중첩된 여러 speaker의 unsupervised speech separation에 대한 가치를 보여주었습니다. 저자들이 제안한 방식과 동일하게, DNN은 unsupervised clulstering을 위한 feature를 제공하기 위해 train되었으며, 이 과정은 deep clustering으로 불립니다. 저자들의 방식과는 다르게, deep clustering은 RNN을 이용해 각 frequency bin에서 동작하며, 각 bins의 embedding을 학습합니다.
Diarization System
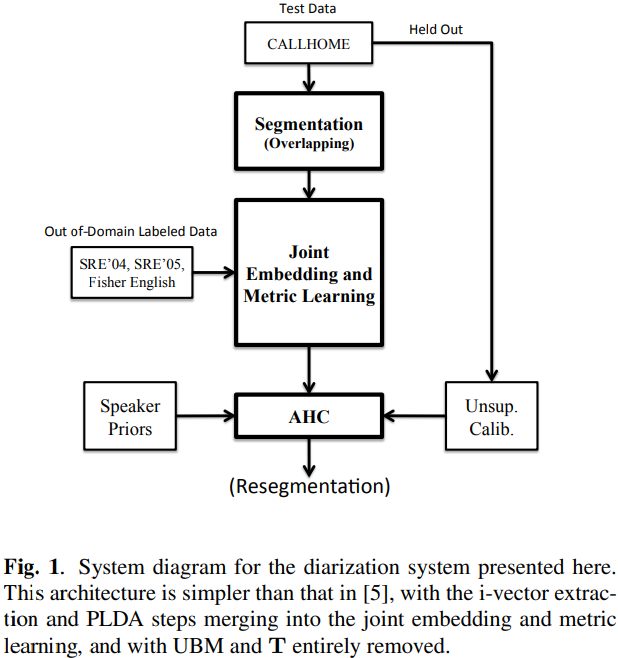
저자들의 방식은 2초 segment로의 시간적 세분화로 시작됩니다. 이러한 segment들은 DNN을 이용해 고정된 차원의 embedding으로 embedding됩니다. DNN은 embedding하는 것과 embedding 쌍을 구분하는(동일한 speaker 쌍인지 다른 speaker 쌍인지 분류) scoring metric을 동시에 학습합니다. embedding과 socring metric은 PCA를 사용하여 conversation dependent space로 투영됩니다. conversation dependent PCA는 scoring metric을 conversation의 고유한 특성으로 적응시킵니다. 투영된 segment embedding은 scoring metric을 사용하는 AHC를 통해 clustering됩니다. unlabeled data로 학습된 threshold는 clustering을 멈출지 말지에 대해 사용됩니다. diarization 결과는 VB resegmentation을 사용해 추가적인 refine을 거칩니다.
Temporal Segmentation
저자들은 500ms의 overlap을 하여 2초 segment를 사용했습니다. 그래서 한 segment는 총 1초의 overlap 구역을 갖게 됩니다. 이러한 방식으로 segmententation하여 저자들의 clustering 성능을 향상시켰습니다.
Joint Learning of Embedding and Similarity Metric
- Overview
저자들이 제안한 system은 가변 길이의 acoustic segment로부터 embedding을 추출하기 위해 temporal pooling layer와 feed forward DNN을 사용했습니다. network 구조는 speaker recognition 분야에서 최근에 소개된 구조를 기반으로 합니다.
- Features
features는 25ms 길이의 frame-length에서 구한 40차원의 MFCCs입니다.
- Neural Network Architecture
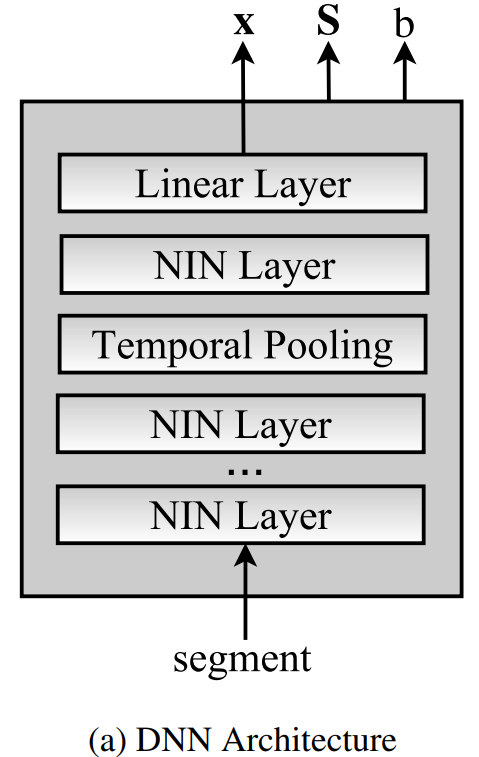
network 구조는 위와 같이 5개의 hidden layer와 temporal pooling layer, affine output layer로 구성되어 있습니다. short-term temporal context는 time-delay 구조를 사용하여 network의 처음 4개 layer로 통합됩니다. segment의 총 frame 수를 T라고 하고 0 ≤ t ≤ T일 때, t는 frame의 index를 의미합니다. input layer는 [t-1, t+1]의 feature frame을 함께 연결합니다. [t-2, t+1], [t-3, t, t+3], [t-3, t, t+3]에서의 activation은 함께 연결되어 4번째 layer는 [t-9, t+8]의 context를 다루게 됩니다. 즉 각 layer를 거칠수록 좀 더 넓은 temporal range를 고려해서 output을 만들어냅니다. temporal pooling layer는 4번째 layer의 output을 input segment의 전체 길이 [0, T]에 대해 집계하고, 그 평균을 계산한 다음 다섯 번째 hidden layer로 전달합니다. 마지막으로, affine layer를 거쳐 최종 400차원의 embedidng x를 output합니다. 대칭 matrix S와 offset b는 embedding과 scoring metric을 동시에 학습한 network의 상수 output입니다. detail한 수식은 이후에 확인해 보겠습니다.
hidden layer activation은 Network-in-Network (NIN) nonlinearity로 최근에 소개된 방식입니다. nonlinearity는 d_i차원 input을 d_0차원 output으로 mapping해줍니다. 해당 nonlinearity 내에서, n개의 micro neural network는 input을 d_h차원 공간으로 투영합니다. micro neural network는 3개의 ReLU가 affine layer와 함께 stack되어 있는 구조입니다. 이 연구에서 NIN은 {n = 50, d_i = 150, d_h = 1000, d_o = 500}을 사용합니다.
- Training
embedding x와 y가 동일한 speaker에 속할 확률은 다음과 같은 식으로 표현됩니다.
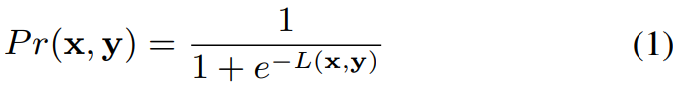
아래 식은 두 embedidng사이의 거리를 정의합니다.

P_diff는 다른 speaker일 확률, P_same은 동일한 speaker일 확률을 의미한다고 하겠습니다. 이때 objective function은 2개 class의 cross-entropy입니다. 식은 다음과 같습니다.
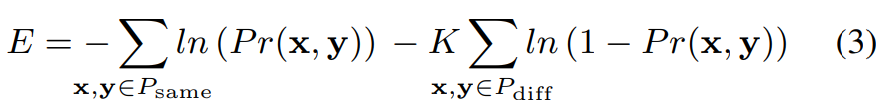
동일한 경우보다 다른 경우가 더 많기 때문에 K를 이용해 동일한 weight를 갖도록 만들었습니다.
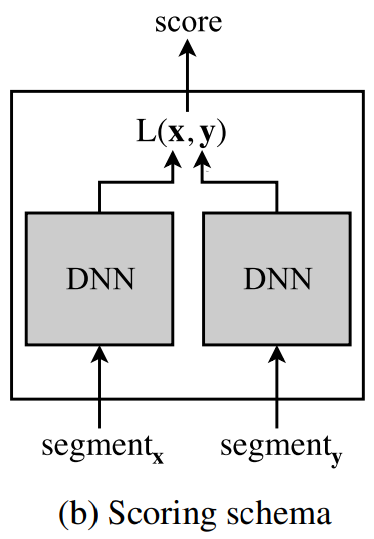
최종 scoring schema는 위와 같습니다.
Train에 사용할 data들은 동일한 speaker에 속하고 같은 recording에서 추출된 segment 쌍으로 구성됩니다. segment들은 2초의 speech이며 overlap이 없다고 하겠습니다. minibatch는 동일한 화자에서 오지 않은 N개의 쌍을 선택하여 형성됩니다. 각 쌍 간에 segment를 결합하여 different-speaker pair가 N(N+1)개 생성된다고 합니다(아니지 않나...?). 저자들은 minibatch size N을 16으로 두고 진행했습니다. minibatch에 존재하는 2N개의 segment들은 DNN에 propagte되어 2N개의 embedding x_1, x_2, ... , x_2N과 constant output b와 S를 만듭니다. 그리고 해당 결과들이 objective function으로 input됩니다. 다양한 speaker와 segment가 비교되도록 보장하기 위해, 각 training data들은 반복 후에 섞입니다.
Clustering with Prior Specification
speaker 수 m에 대한 prior 확률은 AHC diarization에 통합될 수 있다는 연구가 등장했었습니다. 그 연구에서는 합리적인 prior의 사용은 보정 오류의 부정적인 영향을 줄여준다는 것을 보였습니다. 그래서 저자들은 실험을 할 때, 2가지 baseline을 제안합니다. AHC의 prior이 지정되지 않는 경우(speaker 수의 기하급수적 증가함을 보여줌), 또는 명시적으로 지정된 경우(기하급수적으로 감소하는 prior 확률 2^(-m))을 baseline으로 사용합니다.
Experiments
Data
저자들은 DNN을 10K 개의 cut을 이용해 학습했습니다. UBM과 T matrix를 37K 개의 cut으로 학습했습니다. PLDA scoring은 DNN에 사용했단 dataset을 그대로 이용해 학습했습니다. 또한, senone i-vector system은 1600 시간 dataset을 사용하여 DNN을 훈련시켜 senone을 분류했습니다.
저자들은 CALLHOME을 이용해 저자들이 제안한 system을 평가했습니다. 각 conversation에서, 모든 speaker는 단일 채널로 녹음됩니다. 대화에는 2명에서 7명 사이의 speaker(대부분의 대화는 2명에서 4명 사이)가 있으며, corpus는 6가지 언어로 분포되어 있습니다(Araib, English, German, Japanese, Mandarin, Spanish)
Performance Metrics
저자들의 방식을 DER로 평가했습니다. DER은 모든 type의 error를 결합한 형태이지만, speaker labeling error에 대해서만 결과로 사용합니다.

Results
위 table은 두 baseline system가 저자들이 제안한 구조에 대한 DER 결과를 요약해 보여줍니다. unsupervised 보정을 통해 결정된 threshold을 이용한 DER, speaker 수에 대한 prior를 기하급수적으로 감소시켰을 때의 DER, oracle 보정을 사용했을 때의 DER을 보여줍니다. VB refine을 했을 때와 안 했을 때에 대한 결과가 비슷한 것을 알 수 있습니다. speaker prior와 oracle 결과를 보면, DNN embedding이 acoustic i-vector보다 좋은 결과를 보여줍니다. 그리고 senone i-vector와 유사한 성능을 보이지만 연산량이 훨씬 적습니다.
Conclusion
이 연구에서, 저자들은 i-vector를 기반으로 하는 diarization system의 대안책인 DNN을 제안합니다. 저자들이 제안한 구조는 가변 길이의 acoustic segment에 대한 고정된 차원의 embedding을 만드는 학습과 scoring metric을 동시에 학습합니다. CALLHOME dataset에서, 저자들이 제안한 구조는 기존 방식들과 비슷하거나 더 뛰어난 성능을 보여줍니다.
'연구실 공부' 카테고리의 다른 글
| [논문] End-to-End Neural Speaker Diarization with Self-Attention (0) | 2024.03.18 |
|---|---|
| [논문] Integrating End-to-End Neural and Clustering-based Diarization: Getting the Best of Both Worlds (0) | 2024.03.17 |
| [논문] End-to-End Speaker Diarization as Post-Processing (0) | 2024.03.14 |
| [survey 논문] A Review of Speaker Diarization: Recent Advances with Deep Learning (0) | 2024.03.13 |
| Speaker Diarization (0) | 2024.03.11 |



