https://ieeexplore.ieee.org/abstract/document/9003959
Request Rejected
ieeexplore.ieee.org
해당 논문을 보고 작성했습니다.
Abstract
Speaker diarization은 speaker embedding을 clustering하는 방식으로 주로 발전되어 왔습니다. 그러나, clustering 기반 방식들은 2가지 문제가 존재합니다. (1) diarization error를 직접적으로 minimize하는 방식으로 최적화할 수 없습니다. (2) speaker overlap을 정확하게 다룰 수 없습니다. 이러한 문제를 해결하기 위해, bidirectional long short-term memory (BLSTM) network를 사용하여 주어진 multi-talker recording에 대한 speaker diarization을 직접적으로 output하는 End-to-End Neural Diarization (EEND)가 최근에 등장했습니다. 이 논문에서 저자들은 BLSTM block을 사용하는 대신 self-attention block을 적용하여 EEND를 발전시켰습니다. 이전 state과 다음 hidden state에만 의존하는 BLSTM과 다르게 self-attention은 모든 다른 frame에 직접적으로 의존하기 때문에 speaker diarization 문제를 다루기에 훨씬 더 적합합니다. 저자들은 제안한 방식을 mixture, real telephone call, real dialogue recording에서 test했습니다. 실험을 통해 얻은 결과를 통해 self-attention이 conventional BLSTM-based method보다 더 좋은 결과를 얻도록 만들어주는 key라는 것을 보입니다. 제안한 방식은 가장 성능이 좋은 x-vector clustering based method보다 훨씬 좋은 성능을 보입니다. 마지막으로, latent representation을 시각화함으로써, self-attention이 global speaker characteristic 뿐만 아니라 local speech activity도 capture할 수 있음을 보여줍니다.
Introduction
Speaker diarization은 audio recording을 speaker identity에 따라 동일한 구간으로 분할하는 과정을 의미합니다. speaker diarization은 다양한 분야에서 활용됩니다. 또한 multi speaker conversation scenario에서의 automatic speech recognition 성능에도 도움을 줍니다.
일반적인 speaker diarization system은 speaker embedding을 clustering하는 것을 기반으로 합니다. 예를 들어, i-vector, d-vector, x-vector들을 speaker diarization task에서 주로 사용했었습니다. 이러한 짧은 segment에 대한 embedding들은 GMM, AHC, mean shift clustering, k-means clustering, Links, spectral clutsering과 같은 clustering algorithm을 사용하여 speaker cluster로 분할합니다. 이러한 clustering 기반 diarization method들은 다양한 dataset에서 효과적임을 입증했습니다.
하지만, clustering 기반 method들은 몇 가지 문제점이 존재합니다. 먼저, diarization error를 직접적으로 minimize할 수 없습니다. clustering 과정은 unsupervised learning 방식이기 때문입니다. 그다음, speaker overlap을 다루는 데 문제가 있습니다. clustering algorithm은 각 segment당 1명의 speaker가 있다고 가정하고 진행하기 때문입니다. 게다가, speaker embedding model을 speaker overlap이 되어있는 real audio recording에 적응시키는 데 어려움이 있습니다. speaker embedding model은 non-overlapping segment의 single-speaker에 대해 optimize되어 있기 때문입니다. 이러한 문제들로 인해 speaker diarization application이 overlapping segment를 주로 포함하고 있는 real audio recording에서 동작하는 데 어려움을 겪게 됩니다.
이러한 문제들을 해결하기 위해, 저자들은 Self-Attention End-to-End Neural Diarization (SA-EEND)를 제안합니다. 대부분의 방법들과 달리 저자들이 제안한 방식은 clustering에 의존하지 않습니다. 대신에 self-attention 기반 neural network가 multi-speaker audio recording의 각 frame 마다 모든 speaker에 대한 speech activities를 직접 output합니다. 저자들의 방식은 multi-label classification framework를 활용하여 training과 inference time동안에 speaker overlap을 자연스럽게 처리할 수 있습니다. neural network는 최근에 제안된 permutation 없는 objective function을 사용하여 end-to-end 방식으로 학습됩니다.
이 논문은 저자들이 제안한 방식이 EEND 보다 훨씬 성능이 향상된 것을 보여줍니다. 특히, self-attention mechanism이 좋은 speaker-diarization 성능의 key라는 것을 입증합니다. 이전 state과 다음 state에만 의존적인 BLSTM과 대조적으로, self-attention layer는 모든 frame pair의 similarity를 계산하여 모든 input frame을 고려합니다. 저자들은 이러한 방식이 global speaker characteristic 뿐만 아니라 local speech activity dynamic도 capture할 수 있기 때문에 speaker diarization의 key라고 생각한다고 합니다.
학습된 representation을 시각화하여, 몇 개의 self-attention head는 speaker-dependent global characteristic을 capture하고 나머지 head들은 temporal feature를 표현하는 것을 보였습니다.
Related Work
Clustering-based method
x-vector clustering 기반 system은 일반적으로 speaker diarization에서 사용되었습니다.
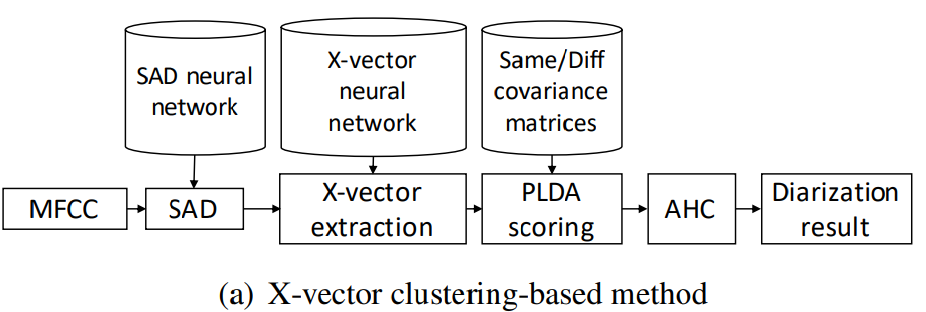
위와 같은 방식으로 system을 묘사할 수 있습니다. system을 build하기 위해, 3가지 독립적인 model을 준비해야 합니다. 1) speech activity detection (SAD) neural network, 2) x-vector extraction neural network, 3) 동일한/다른 speaker covariance matric을 가지고 있는 PLDA model입니다. 이러한 model들을 diarization error를 직접적으로 minimize하도록 학습시킬 수 있는 방법은 존재하지 않습니다. model들 간의 의존성을 고려하고 복잡한 준비 과정을 완화하기 위해 공동 modeling 방식들이 연구되었습니다. 예를 들어, x-vector extraction와 PLDA scoring을 동시에 modeling하거나 SAD와 speaker embedding을 동시에 modeling 하는 방식입니다. 그러나 clustering은 unsupervised process이기 때문에 clustering 과정은 여전히 변하지 않고 남아있었습니다.
이러한 방식들과 대조적으로, EEND 방식은 1개의 neural network만을 사용합니다.
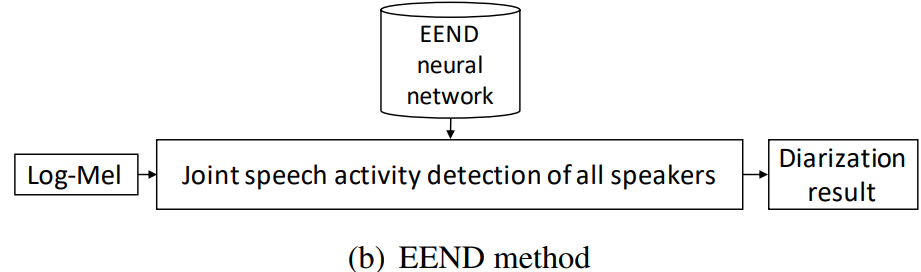
위와 같은 방식입니다. 이 방식은 clustering에 의존하지 않으며, model이 training data의 diarization result를 reference로 하여 직접적으로 최적화됩니다.
이러한 1개 neural network model을 사용하여 바로 final output을 계산하는 neural-network 기반 end-to-end 방식은 다양한 task에서 성공적인 모습을 보였습니다.
Direct optimization minimizing diarization errors
fully supervised diarization 방식은 diarization error minimization 방식을 기반으로 최적화되도록 제안되었습니다. 이는 speaker embedding을 cluster하지 않으며 성공적인 결과를 얻은 첫 방식이었습니다. 이 방식은 speaker change, speaker assignment, feature generation이라는 module로 구성된 확률 모델을 기반으로 speaker diarization 문제를 제시합니다. 이러한 model들은 input feature와 대응하는 speaker label을 사용해 동시에 학습됩니다. 그러나, SAD model과 speaker embedding (d-vector) model은 분리되어 학습되었습니다. 게다가, speaker change model은 각 segment에서 1명의 speaker가 말하고 있다고 가정했기 때문에 speaker-overlapping speech에서는 적합하지 않습니다.
이전에 제시된 fully supervised diarization method와 대조적으로, EEND method는 audio feature를 input으로 사용하는 end-to-end neural network를 사용합니다. end-to-end neural network는 multiple speaker의 speech activity를 output합니다. network는 non-speech와 speech overlap을 포함한 전체 recording과 diarization error oriented objective를 사용해 optimize됩니다. 이 end-to-end model은 이전 연구에서 등장했었으며, 이 논문은 end-to-end model에 self-attention mechanism을 적용하여 발전시켰습니다.
Self-attention mechanism
self-attention mechanism은 text processing을 하기 위해 setence embedding을 추출하는 목적으로 처음 소개되었습니다. 최근에는, self-attention mechanism이 다양한 task에서 상당히 뛰어난 성능을 보여주고 있습니다. audio processing에서는, self-attention mechanism이 ASR, sound event detection, speaker recognition에 사용되는 acoustic model로 사용되고 있습니다. speaker diarization에서는, self-attention mechanism은 clustering based method의 speaker embedding extraction model과 scoring model에 사용되고 있습니다. 이 논문에서는, clustering이 없는 speaker diarization에 self-attention mechanism을 적용합니다.
Proposed Method: Self-Attentive End-to-End neural Network
End-to-end neural diarization: review
먼저 이전에 등장한 EEND method에 대해 소개하겠습니다. speaker diarization task는 multi-label classification problem으로 표현할 수 있습니다.
audio signal로부터 T 길이의 observation sequence X = (x_t ∈ R^F | t = 1, ... , T)이 주어졌을 때, speaker diarization 문제는 observation sequence에 대응하는 speaker label sequence Y = (y_t | t = 1, ... , T)를 추정하는 것입니다. 여기서 x_t는 time index t에서의 F차원 observation feature vector입니다. Speaker label y_t = [y_(t,c) ∈ {0, 1} | c = 1, ... , C]는 time index t에서의 multiple (C) speaker activity를 의미합니다. 즉, 해당 time에서 C명의 speaker에 대한 activity를 classification하는 task라고 볼 수 있습니다. 예를 들어, y_(t, c) = 1이고 y_(t, c') = 1 (c ≠ c')은 time index t에서 speaker c와 c'이 overlap situation에 있다는 것을 표현합니다.
가장 확률적으로 가능한 speaker label sequence Y^는 모든 가능한 speaker label sequence y로부터 선택됩니다. 식으로 나타내면 다음과 같습니다.

P(Y|X)는 조건부 독립 가정을 사용하여 곱셈으로 표현할 수 있습니다.

frame-wise posterior가 모든 input을 조건부로 사용한다고 가정하고, 각 speaker는 독립적으로 존재한다고 가정합니다. frame-wise posterior P(y_(t,c) | X)는 neural network 기반 model을 사용해 추정할 수 있습니다.
Self-attention-based neural network
BLSTM 기반 neural network는 frame-wise posterior P(y_(t,c) | X)를 추정하는 데 사용됩니다. 이 논문에서, 저자들은 BLSTM 대신 self-attention-based encoding block을 사용하는 self-attentive end-to-end neural diarization (SA-EEND)를 제안합니다.
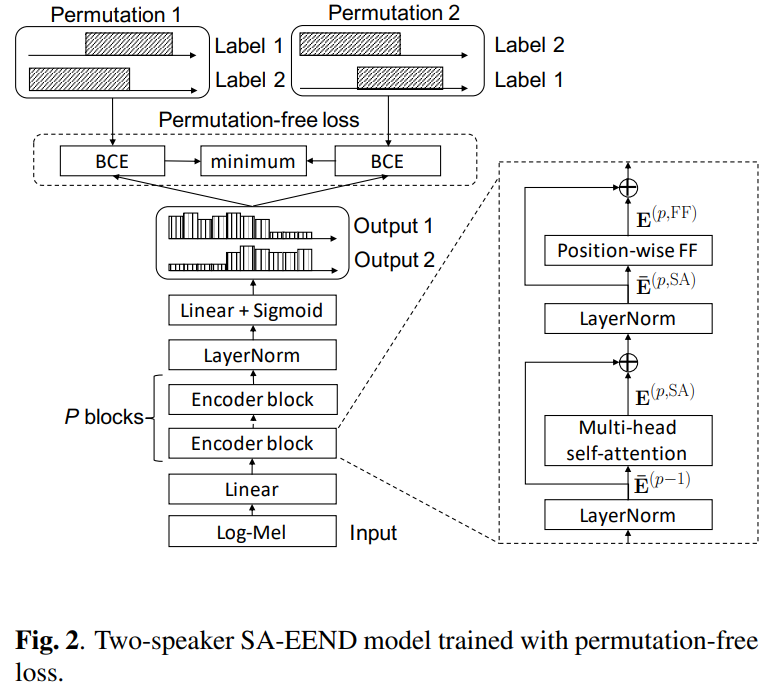
위 그림과 같은 형태입니다. input feature는 다음과 같은 형태입니다.
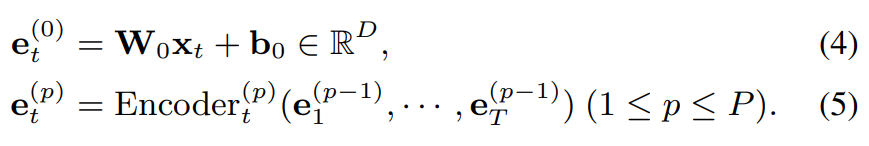
여기서 W_0 ∈ R^(DxF)와 b_0 ∈ R^D는 input feature를 D 차원의 vector로 투영합니다. Encoder_t^(p)는 time index t에서의 D차원 vector sequence input을 accept하고 D차원 output vector e_t^(p)를 output하는 p번째 encoder block입니다. 저자들은 P개의 encoder block을 사용하며, frame-wise posterior를 위한 output layer가 뒤에 붙습니다.
encoder block의 구조는 위 그림과 같습니다. encoder block은 2개의 sub layer를 가지고 있습니다. 첫 번째는 multi-head self-attention layer이고, 두 번째는 position-wise feed-forward layer입니다.
- Multi-head self-attention layer
multi-head self-attention layer는 input vector sequence를 변환합니다.
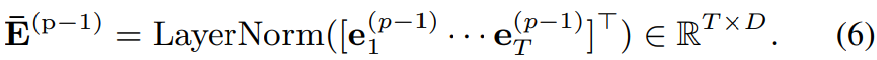
vector sequence (e_t^(p-1) | t = 1, ... , T)는 위 layer normalization을 이용해 R^(TxD) matrix로 변환됩니다. 그다음 각 head에서 pairwise similarity matrix A_h^(p)를 구합니다. 이는 query vector와 key vector의 dot product를 이용해 구해집니다.

위 식과 같은 형태입니다. 여기서 E_barQ_h가 query vectors를 의미하고, E_barK_h는 key vectors를 의미합니다. 각 vectors는 R^(Txd) 차원의 형태입니다. 그렇기 때문에 최종 pairwise similarity matrix은 R^(TxT) shape가 됩니다.
여기서 Q_h, K_h ∈ R^(Dxd)이며, 각각은 h번째 head의 query projection matrix와 key projection matrix입니다. d = D/H는 각 head의 차원을 의미하며, H는 head의 수를 의미합니다.
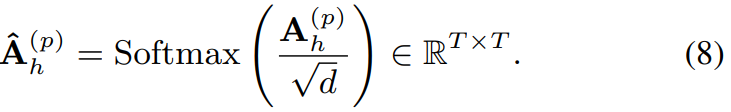
pairwise similarity matrix A_h는 1/d^(0.5)에 의해 scale되며 softmax를 적용해 attention weight matrix 형태가 됩니다. 위 식이 attention weight matrix입니다.
그다음 attention weight matrix를 weight로 이용해 weighted value vector의 합인 context vectors C_h를 구합니다. 식은 다음과 같습니다.
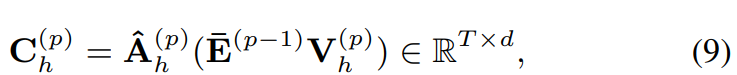
위 식에서 E_barV_h가 value vectors를 의미합니다. value vectors ∈ R^(Txd)입니다.
V_h ∈ R^(Dxd)는 value projection matrix입니다. 마지막으로, 모든 head에 대한 context vector는 concat된 후에 output projection matrix O^(p) ∈ R^(DxD)를 사용하여 project됩니다.
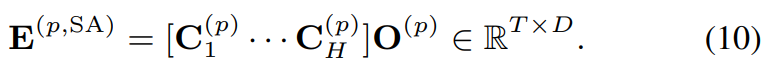
위 식과 같은 형태입니다. 이렇게 구한 self-attention layer는 residual connection과 layer normalization에 사용됩니다.
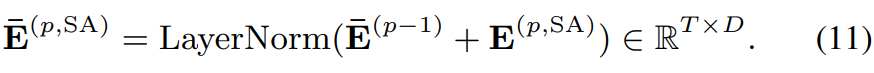
- Position-wise feed-forward layer
position-wise feed-forward layer는 E^(p, SA)를 변환합니다. 식은 다음과 같습니다.
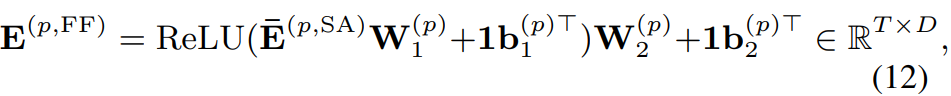
W_1^(p) ∈ R^(Dxd_ff)이고 b_1^(p) ∈ R^(d_ff)이며, 이는 첫 번째 linear projection matrix와 bias입니다. 1 ∈ R^T는 모든 값이 1인 vector입니다. d_ff는 이 layer의 unit 수를 의미합니다. W_2^(p) ∈ R^(d_ff x D)와 b_2^(p) ∈ R^D는 두 번째 linear projection matrix와 bias입니다.
마지막으로 각 time frame의 encoder block output e_t^(p)는 residual connection을 이용해 구해집니다. 다음과 같은 형태로 구해집니다.

- Output layer for frame-wise posteriors
frame-wise posterior z_t는 e_t^(P)를 이용해 계산됩니다. 다음과 같은 식으로 구해집니다.
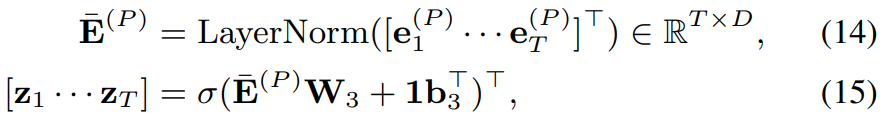
위 식에서 W_3 ∈ R^(DxC)와 b_3 ∈ R^C는 linear projection matrix와 bias입니다. 그리고 σ은 element-wise sigmoid function입니다. 이를 통해 각 frame 별로 output이 구해집니다.
Permutation-free training
model은 무조건 speaker permutation을 다뤄야 하기 때문에 model을 학습하는 데 어려움이 존재합니다.

위 그림의 경우, 2명의 speaker에 대한 permutation 예시입니다. 저자들은 이 permutation problem을 "label ambiguity"라고 부릅니다. 이 label ambiguity는 일반적인 binary cross entropy loss function을 사용하여 neural network를 학습할 때 어려움을 겪게 합니다.
이 label ambiguity problem을 해결하기 위해, permutation free tranining scheme은 speaker label의 모든 permutation을 고려합니다. permutation free training scheme은 source separation 연구에서 등장했었던 방법입니다. 저자들은 permutation-free loss function을 speaker label의 temporal sequence에 적용합니다. neural network는 output z_t와 reference speaker label l_t 사이의 permutation free loss를 minimize하는 방식으로 학습됩니다. 식은 다음과 같습니다.
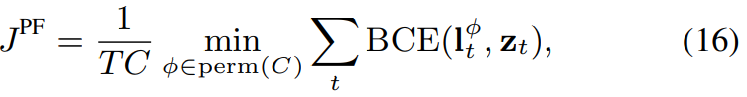
perm(C)는 (1, ... , C)의 가능한 모든 permutation set을 의미합니다. 그리고 l_t^Φ은 Φ번째 reference speaker label permutation을 의미합니다. BCE는 binary cross entropy function을 의미합니다. 즉 l_t와 z_t 사이의 binary cross entropy가 가장 작은 permutaiton을 골라 loss function으로 사용하는 방식입니다.
Experimental Setup
Data
다양한 overlap simulation에서의 SA-EEND method의 효율성을 입증하기 위해, 저자들은 2개의 training set과 5개 test set을 사용합니다. 이 dataset에는 simulated dataset과 real dataset이 존재합니다. overlap 비율은 전체 audio time 중에 2명 또는 그보다 많은 speaker가 동시에 active된 audio 시간과 1명 이상의 speaker가 활성화된 audio 시간의 비율로 계산됩니다. 즉 non-speech는 ratio를 계산할 때 고려하지 않습니다.
EENd method에 사용되는 training data는 x-vector clustering based method와는 다릅니다. x-vector clustering based method는 single speaker segment를 이용해 x-vector neural network를 학습하는 반면, EEND method는 여러 명의 speaker mixture를 이용해 학습됩니다. 이러한 mixtures는 single-speaker segment의 조합으로 무수히 생성할 수 있습니다. 추가적으로, EEND model은 simulated mixture 뿐만 아니라 real audio mixture를 이용해 학습됩니다.
- Simulated mixtures
mixture algorithm은 다음과 같습니다.

source separation 연구의 mixture simulation과 다르게, 저자들은 diarization-style mixture를 사용했습니다. diarization style이란, 각 speech mixture가 speaker 당 수십 개의 utterance를 포함하고 있어야 하며, utterance 간에는 합리적인 침묵 간격이 있어야 합니다. 침묵 간격은 평균 간격 β에 의해 control됩니다. 큰 β를 사용하면 less overlap speech를 생성합니다.
simulation에 사용되는 utterance 집합은 Swithboard-2, Switchboard Cellular, NIST Speaker Recognition Evaluation dataset으로 구성됩니다. 모든 recording들은 8kHz의 telephone speech입니다. 총 6381명의 speaker로 이루어져 있습니다. 저자들은 5743명의 speaker를 training set으로 사용했고, 638명의 speaker를 test set으로 사용했습니다. training set의 utterance 집합은 Kaldi CALLHOME diarization v2 recipe과 동일하며, 이를 통해 x-vector clustering based method와 공정한 비교가 가능해집니다.
background noise로는 MUSAN corpus를 사용했습니다. 저자들은 37개의 noise recording을 사용했습니다. Simulated Room Impulse Response Database로부터 10000개의 room impulse response를 사용했습니다.
저자들은 2명 speaker mixture를 생성했습니다. 각 speaker는 10~20 utterance를 말하도록 생성했습니다. simulated training set은 β = 2인 100,000개의 mixture입니다. simulated test set은 β = 2, 3, 5로 설정하여 생성한 500개의 mixture입니다. simulated mixture의 overlap ratio는 19.5~34.4%입니다.
Model configuration
- Clustering-based systems
저자들은 2가지 conventional clustering based system을 proposed method와 비교합니다. Kaldi CALLHOME diarization v1과 v2 recipe을 이용해 만들어진 i-vector system과 x-vector system입니다.
이러한 recipes는 AHC와 PLDA를 이용합니다. cluster 수는 2로 고정했습니다. original recipe은 oracle speech/non-speech mark를 사용하지만, 저자들은 SAD model을 이용합니다.
- BLSTM-based EEND system
BLSTM-based EEND method (BLSTM-EEND)에 대해 알아보겠습니다. input features는 25ms frame length를 가지고 10ms frame shift하여 얻은 23차원 log-Mel filterbank입니다. 각 feature는 이전 7 frame과 이후 7 frame들을 concatenate하였습니다. long audio sequence를 다루기 위해, (23x15) 차원 input feature가 매 100ms마다 neural network의 input으로 feed 됩니다.
각 layer마다 256개의 hidden unit을 가지고 있는 5개의 BLSTM layer를 사용합니다. 두 번째 BLSTM layer는 256차원 embedding 형태의 output을 만드는 데 사용되었으며, 해당 embedding으로 different speaker를 구분하도록 하는 deep clustering loss를 계산했습니다. Adam optimizer를 사용하여 학습을 진행했으며, batch size는 10으로 설정했습니다.
neural network의 output은 각 speaker에 대한 speech activity를 확률값으로 output하기 때문에, 각 frame마다 speech activity 결정을 얻기 위해서는 threshold를 필요로 합니다. 그래서 저자들은 0.5로 threshold를 설정했습니다.
domain adaptation을 할 때, neural network는 CALLHOME adatation set을 이용해 재학습되었습니다. 그리고 postprocessing을 할 때, 저자들은 threshold를 0.6으로 설정하여 adaptation set에 대한 DER을 minimize하였습니다.
- Self-attentive EEND system
BLSTM-EEND system과 동일한 input을 사용했습니다. training 때 sequence length를 500으로 (50초의 audio) 제한했습니다. 이를 통해 저자들의 system이 BLSTM-based network 보다 더 많은 memory를 사용하기 때문입니다. 저자들은 input audio recording을 non-overlapping 50 second segment로 나눴습니다. inference를 할 때는 각 recording의 전체 sequence를 사용했습니다.
4개의 head (P = 2, D = 256, H = 4)로 이루어진 2개의 encoder block을 사용했습니다. 저자들은 position-wise feed-forward layer의 internal unit을 1024로 설정했습니다(d_f = 1024). Adam optimizer를 사용해 학습했습니다. batch size는 64로 설정했습니다.
domain adaptation을 할 때, averaged model이 CALLHOME adaptation set으로 재학습되었습니다.
Performance metric
저자들은 diarization error rate (DER)을 이용해 system을 평가했습니다. 저자들은 overlapping speech segment도 포함하여 error를 구했습니다.
Results
Evaluation on simulated mixtures
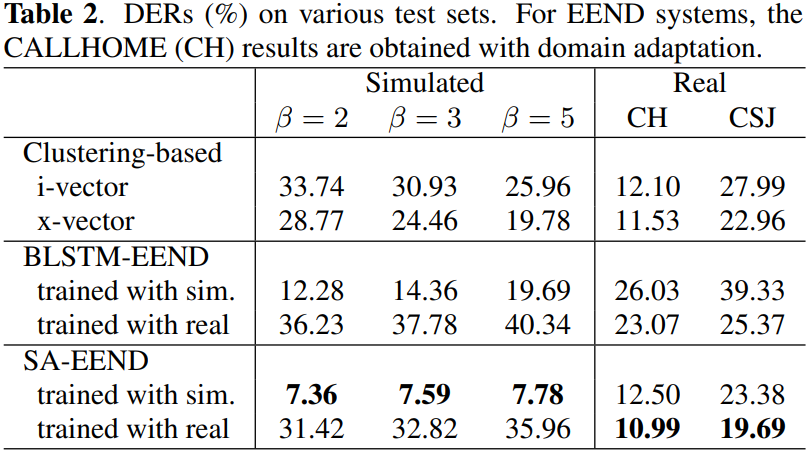
위 표를 통해 다양한 test set에 대한 DER을 확인할 수 있습니다. clustering 기반 system은 overlapped simulated mixture에서 상당히 좋지 않은 모습을 보입니다. clustering 기반 system은 speaker overlap을 고려하지 않기 때문에 이와 같이 overlap이 더 될수록 더 안 좋은 결과를 보였습니다.
simulated training set에서 학습된 BLSTM-EEND system은 clustering based system에 비해 상당한 성능 향상을 보입니다. overlap ratio ratio를 비교했을 때, BLSTM-EEND system은 가장 높은 overlap ratio condition에서 가장 좋은 결과를 보였습니다.
저자들이 제안한 SA-EEND system에 대해 보겠습니다. simulated trainng set으로 학습된 SA-EEND system은 BLSTM-EEND보다 모든 test set에서 상당한 성능 향상을 이끌어냈습니다. BLSTM-EEND system과 같이, 가장 높은 overlap ratio 상태에서 가장 좋은 성능을 보였습니다. 하지만 BLSTM-EEND에 비해 overlap ratio가 낮은 condition에서의 성능 저하 폭이 적었습니다. 즉 self-attention block이 다양한 overlap condition에 대한 강건함을 향상시켜준다고 볼 수 있습니다.
Evaluation on real test sets
simulated mixture에서 좋은 성능을 보인 반면, BLSTM-EEND system은 real test set으로 평가한 clustering based system 성능보다 좋지 않은 모습을 보였습니다.
저자들이 제안한 SA-EEND를 real train set으로 학습한 후에 real test set에 대해 성능을 확인했을 때 가장 좋은 성능을 보였습니다. 하지만 real train set으로 학습하고 simulated set으로 실험했을 때, DER 수치는 좋지 않은 것을 볼 수 있습니다. real training set에는 적은 수의 mixture가 있고 overlap ratio도 낮기 때문에 이러한 결과를 보인다고 저자들은 생각합니다. 그래서 training set으로 더 많은 speaker overlap을 넣거나, simulated data와 섞는다면 성능이 향상될 것이라고 생각한다고 합니다.
Effect of domain adaptation
simulated training set으로 학습된 EEND model들은 training set의 특정 overlap ratio로 overfitting되어 있습니다. 그래서 저자들은 domain adaptation을 이용함으로써 overfitting을 완화시킬 수 있을 것이라고 기대합니다.
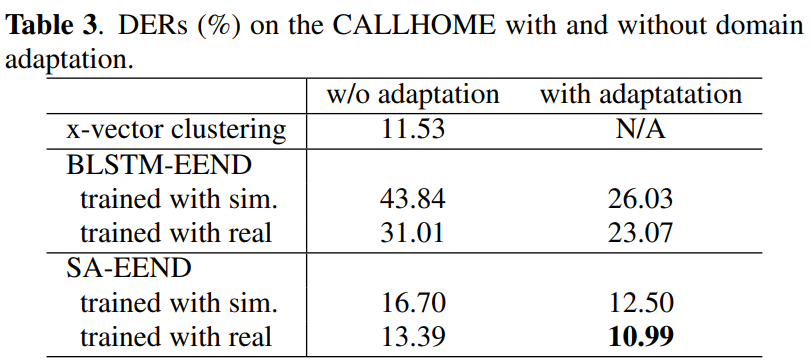
저자들은 CALLHOME에 adaptation을 하거나 안 했을 때의 DER 결과를 위와 같이 보였습니다. 기대했던 것과 같이, domain adaptation은 상당한 DER 감소를 보였습니다. 저자들의 system은 x-vector based system보다도 더 좋은 성능을 보였습니다.
Visualization of self-attention
저자들은 diarization system에서의 self-attention mechanism의 행동을 분석하기 위해 다음과 같이 2번째 encoder block의 attention weight matrix를 visualize했습니다.
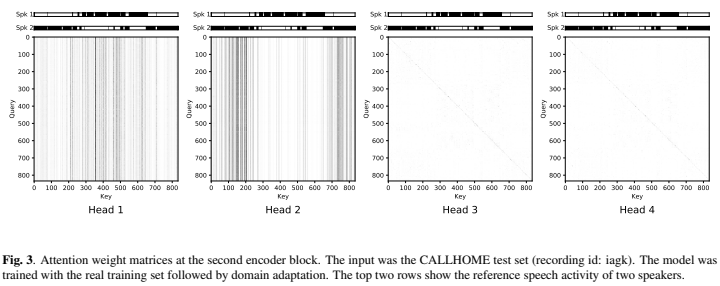
head 1, 2를 보면 서로 다른 위치에 수직 선들이 존재합니다. 수직 선은 각 speaker의 activity를 의미합니다. 이러한 수직 선을 가지고 있는 attention weight matrix는 input feature를 동일한 speaker frame의 weighted mean으로 변환합니다. 이러한 head들은 멀리 있는 frame 간의 similarity를 계산함으로써 global speaker characteristic을 capture할 수 있습니다. 흥미롭게도, head 3, 4는 항등 행렬처럼 보이며, 이는 position에 독립적인 linear transform을 결과로 합니다. 이러한 head들은 speech/non-speech detection을 합니다. 저자들은 multi-head self-attention mechanism이 global speaker chracteristic 뿐만 아니라 local speech activity dynamic도 capture한다고 결론 내렸습니다.
Conclusion
저자들은 self-attention mechanism을 end-to-end neural diarization model에 적용했습니다. 저자들은 제안한 model을 simulated mixtrue과 2개의 real dataset에 대해 실험을 진행했습니다. 실험 결과를 통해, 저자들은 self-attention mechanism이 DER을 상당히 감소시킨다는 것을 보였습니다. 그리고 BLSTM-based neural diarization sysetm에 비해 더 높은 generalization quality를 갖는다는 것도 보였습니다. self-attention based system은 x-vector clustering-based system보다도 더 좋은 결과를 보였습니다. 그리고 저자들은 latent representation을 visualize하여 self-attention block이 global speaker characteristic 뿐만 아니라 local speech activity dynamic도 capture한다는 것을 보였습니다.



