https://arxiv.org/abs/2011.02678
BW-EDA-EEND: Streaming End-to-End Neural Speaker Diarization for a Variable Number of Speakers
We present a novel online end-to-end neural diarization system, BW-EDA-EEND, that processes data incrementally for a variable number of speakers. The system is based on the Encoder-Decoder-Attractor (EDA) architecture of Horiguchi et al., but utilizes the
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 BW-EDA-EEND라는 online end-to-end neural diarization system을 제안합니다. 이 system은 speaker 수가 변동하는 data를 점진적으로 처리합니다. system은 Encoder-decoder-attractor (EDA)를 기반으로 하지만, incremental transformer encoder를 이용합니다. 이는 left context에만 집중하고, block에서 block으로 정보를 전달하기 위해 hidden state에서 block-level recurrence를 사용합니다. 이를 통해 algorithm의 시간 복잡도를 linear하게 만듭니다. 저자들은 2가지 변형을 제안합니다. 먼저 unlimited-latency BW-EDA-EEND입니다. 이는 input을 linear time에 처리하며, 10초 길이의 context를 사용하는 two speaker에 대한 성능이 offine EDA-EEND보다 약간 좋지 않습니다. speaker가 2명보다 많을 때 online과 offline의 정확도 차이가 늘어나지만, 1명에서 4명까지 speaker가 존재하는 unlimited context size를 다루는 baseline offline clustering diarization system보다는 여전히 성능이 좋습니다. limited-latency BW-EDA-EEND는 audio가 들어옴에 따라 block별로 speaker diarization output을 만들어내며, offline clustering-based system과 비교할만한 정확도를 보입니다.
Introduction
End-to-end nueral diarization (EEND) with self-attention은 multiple speaker의 speech activity를 model할 수 있는 방식 중 하나입니다. 이는 voice activity와 overlap detection을 통합하여 진행합니다. 그리고 이는 diarization error를 직접 minimize할 수 있으며, two speaker telephone conversation에서의 좋은 성능을 보였습니다.
하지만, EEND는 고정된 speaker 수에서만 동작합니다. neural network의 output 차원이 미리 정의되어야만 하기 때문입니다. 최근에 등장한 몇몇 방식들은 EEND의 한계를 극복했습니다. 그 중 하나로, 이전에 추정된 speech activity를 condition으로 하여 반복적으로 speaker 별 speech activity를 decode하는 speaker 별 chain rule을 사용하는 방식이 있습니다. 다른 방식으로 encoder-decoder based attractor calculation이 있습니다. multiple speaker의 embedding은 audio input의 시간 경과에 따라 누적되고, 그 후에 분리되어 하나씩 speech frame별로 speaker identity를 할당합니다. 하지만, 이러한 최신 EEND method들은 offline 상황에서만 동작합니다. 즉 diarization output이 생성되기 전에 완전한 recording이 사용 가능해야 함을 의미합니다. 이는 잠재적으로 long multi-speaker recording이 점진적으로 처리(streaming fashion)되어야 하는 상황에서 사용불가능한 접근 방식임을 의미합니다.
이 논문에서, 저자들은 offline system과 비교했을 때 큰 성능 저하 없이 새로운 audio가 도착하자마자 낮은 지연시간으로 speaker identity를 track할 수 있도록, block 별 online방식으로 EEND를 수행하는 새로운 방법을 제안합니다. 저자들은 incremental transformer encoder를 사용하여 block 별 online 처리가 가능하게 합니다. 저자들은 incremental transformer encoder가 left context에만 집중하게 하면서 right context는 무시하도록 만듭니다. 이를 통해 block 별 online처리가 가능해집니다. 그리고 incremental transformer encoder는 hidden state의 block-level recurrence를 사용하여 정보를 block별로 전달하므로, 이전 block을 처리하면서 연산 시간을 단축할 수 있습니다.
Prior Work
이전 연구에서 제안한 EEND의 새로운 version은 multiple speaker embedding을 작은 수의 attractor로 집계함으로써 speaker 수를 추정할 수 있습니다(EEND with Encoder Decoder Attractor, EDA-EEND). 가변 길이의 speaker embedding sequence로부터 flexible number of attractor를 계산하기 위해, LSTM 기반 encoder-decoder를 사용했습니다. 주어진 T길이의 F차원 audio feature가 X = [x_1, ... , x_T], x_t ∈ R^F일 때, transformer encoder는 D차원 diarization embedding E = [e_1, ... , e_T], e_t ∈ R^D을 구합니다. 그다음 embedding을 unidirectional LSTM encoder에 feed하여 final hidden state과 ceel state (h_0, c_0)를 구합니다. X에 S명의 speaker가 있다고 가정했을 때, 이상적으로 S개의 D차원 attractor A = [a_1, ... , a_S], a_s ∈ R^D가 decode됩니다. decoding 과정도 unidirectional LSTM decoder를 사용하며 initial state으로 (h_0, c_0)를 사용하여 진행됩니다.

위와 같이 표현할 수 있습니다. 여기서 0은 D차원 zero vector이며 이는 decoder의 상수 input으로 사용됩니다. Attractor existence probabilities p_s는 fully connected layer와 sigmoid function을 이용해 구해집니다. 정해진 threshold보다 낮은 확률 값이 나타난다면, 모든 attractor가 등장했다는 것을 의미합니다. 이와 같은 방식으로 speaker 수를 암시적으로 결정할 수 있습니다. S명의 speaker의 speech activity Y^은 embedding과 attractor의 matrix 곱을 한 후에 sigmoid를 적용해 구해집니다.
Blockwise EDA-EEND
original EDA-EEND algorithm은 offline inference 방식입니다. all input frame을 encoding 한 다음 speaker embedding을 만듭니다. 그 다음 attractor를 decoding 하는 방식입니다. 즉 이는 online (responsive) speaker diarization에는 적합하지 않습니다. 저자들은 새로운 blockwise EDA-EEND를 제안합니다. 저자들이 제안한 방식은 online speaker diarization을 처리할 수 있습니다. 이 방식은 latency의 제한이 필요하거나 input length의 linear한 연산량만 사용가능할 때 적합합니다. 이를 위해, 저자들은 각각 몇 초에 불과한 duration time을 가진 input audio block 별로 다양한 encoding과 decoding 과정을 점진적으로 수행함으로써 blockwise EDA 및 EEND 작업을 수행합니다.
먼저, 점진적 연산을 가능하게 하기 위해, 저자들은 transformer encoder가 block의 left context에만 focus 하도록 제한합니다. 그리고 저자들은 transformer encoder의 hidden state을 구할 때 blockwise recurrence computation을 수행하여 한 block에서 다음 block으로 정보를 전달합니다. Transformer XL에서 state를 재사용하는 기술을 사용해 segment-level recurrence를 수행하는데, 저자들은 이를 motive로 사용했습니다. transformer encoder에 존재하는 blockwise recursive 연산은 상당한 overall inference time을 줄이면서 memory 사용량도 줄일 수 있습니다. 왜냐하면 이전 block의 hidden state이 cache 되고 다음 block에서 다시 사용하기 때문입니다. 이를 통해 저자들이 제안한 method는 제한된 context size에서, 주어진 transformer의 연산 복잡도는 audio length의 선형적인 시간이 됩니다. 각 block이 local dependency information만 model할 수 있지만, encoder의 top node는 recurrence를 통해 long-term dependency를 model할 수 있습니다. 또한, block 별로 speaker permutation을 줄일 수 있음을 실험을 통해 보였습니다.
저자들의 algorithm은 다음과 같습니다.
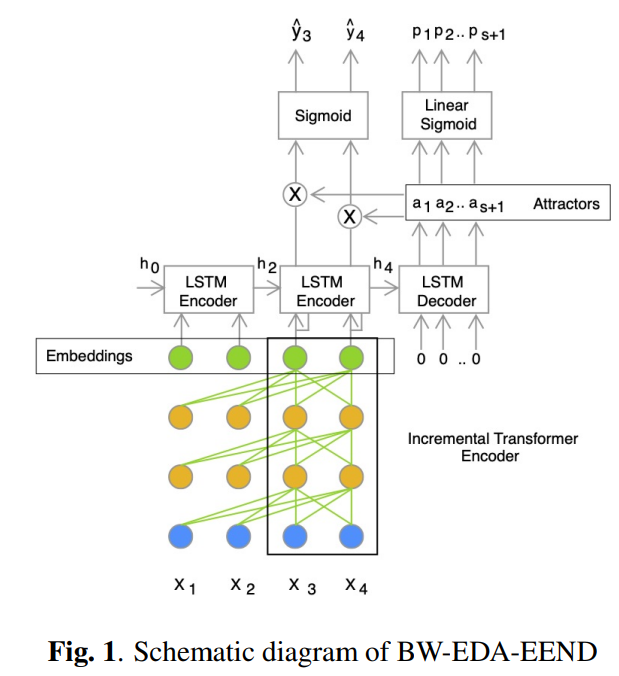
T length의 F차원 audio feature X = [x_1, ... , x_T]가 주어졌을 때, X_B = [x_(b,1), ... , x_(b,W)]가 b번째 W크기의 block input sequence를 나타냅니다. n개의 layer로 이루어진 transformer encoder가 주어졌을 때, E_b^i = [ E_(b,1)^i, ... , E_(b,W)^i]가 i번째 layer의 hidden state을 나타냅니다. transformer encoder는 b번째 block에서 W크기의 D차원 diarization embedding sequence를 구합니다(E_b = [e_(b,1), ... , e_(b,W)]). 즉 input feature를 묶어서 block으로 만들어 사용하며, 위와 같은 방법으로 진행을 합니다.
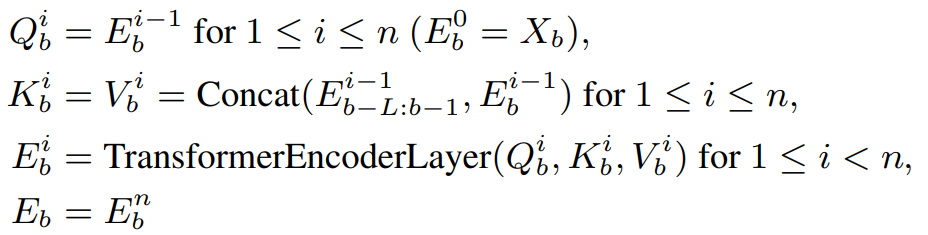
위 식에서 E_b-L:b-1은 hidden state의 sequence를 의미합니다. 이는 b번째 block을 기준으로 이전 L block부터 생성된 hidden state입니다. Concat의 경우, 두 hidden block sequence를 time dimension에 따라 concatenate하는 function입니다. key K_b^i vector와 value V_b^i vector를 의미합니다. 만약 L = ∞라면, 모든 이전 block들에서 구한 모든 hidden state을 사용해 E_b^(i-1)를 구합니다.
transformer encoder 연산이 점진성을 갖고 linear 하도록 만들기 위해, 저자들은 attractor를 구하는 방법을 다르게 하여 2가지 BW-EDA-EEND를 제안합니다. 먼저, limited-latency BW-EDA-EEND (BW-EDA-EEND-LL)입니다. 이는 attractor를 각 block에서 구하고 limited-latency (according to the block size)에서 output을 생성합니다. 이는 output을 online으로 만들어내기에 적합합니다.
그다음은 unlimited-latency BW-EDA-EEND (BW-EDA-EEND-UL)입니다. 이는 input의 마지막에 attractor를 구합니다. 이는 unlimited latency이지만, limited context size를 사용해 input length에 linear한 embedding 연산량을 갖도록 제한합니다. BW-EDA-EEND-LL의 경우, block에 의존하는 D차원 attractors A_b = [a_(b,1), ... , a_(b,S)]는 blockwise unidirectional LSTM을 사용해 decoding됩니다.
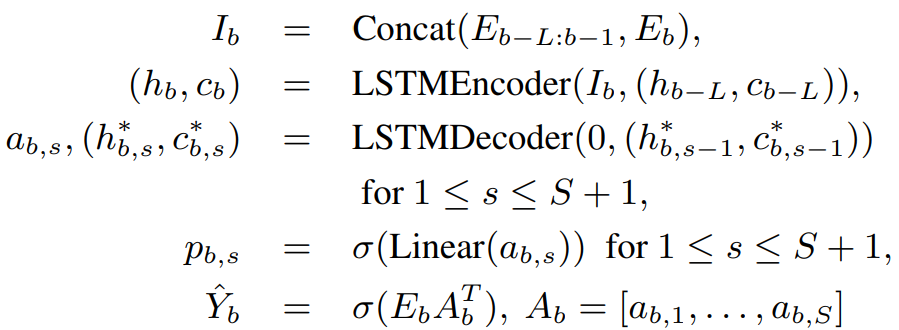
(h_b, c_b)는 b번째 block의 LSTM encoder의 마지막에 해당하는 hidden state와 cell state입니다. 그리고 E_(b-L:b-1)은 이전 L개의 block으로 구한 diarization embedding sequence입니다. (h*_(b,0), c*_(b,0)) = (h_b, c_b)는 LSTM encoder의 마지막 hidden state이 LSTM decoder의 initial hidden state으로 사용된다는 것을 의미합니다. L = ∞일 때, LSTM encoder에서 (h_(b-L), c_(b-L)) 대신 (h_0, c_0)을 사용합니다.
다시 말해, I_b는 L번째 이전 block들부터 바로 직전 block까지의 transformer encoder output과 현재 block의 transformer encoder output을 concatenate하여 구합니다. 그리고 h_b, c_b는 LSTM encoder의 최종 output입니다. hidden state과 cell state를 의미합니다. LSTM decoder는 attractor, hidden state, cell state들을 구해줍니다. attractor를 이용해 확률을 구하고 해당 값을 기준으로 그 다음 attractor를 구할 지 결정하게 됩니다. 그 다음 attractor를 구할 때는, attractor를 구할 때 같이 output되는 h*와 c*를 사용합니다. 최종 attractor들의 집합은 A_b입니다. 그리고 해당 block의 speaker diarization result는 Y^_b가 됩니다.
BW-EDA-EEND-UL의 경우, 모든 blockwise LSTM encoding과 decoding 연산은 BW-EDA-EEND-LL과 유사합니다. 하지만 block에 독립적인 D차원 attractor A = [a_1, ... , a_S]가 마지막 block에서 구해진다는 점이 다릅니다. 여기서 block 수 m = T/W로 정해집니다.
inference 과정에서, speaker 수 S는 모릅니다. 그래서 저자들은 첫 S개의 attractor existence probabilities가 선택한 threshold τ 이상이 되도록 S를 추정합니다. 이는 EDA-EEND와 유사한 방식입니다. 저자들은 이후에 BW-EDA-EEND-UL에서 downstream 연산을 위해 첫 S개의 attractor를 사용합니다. BW-EDA-EEND-LL의 blockwise attractor 추정을 위해, 저자들은 각 block에서 speaker 수 S_b를 구하고, S_b >= S_(b-1)처럼 감소하지 않도록 강제하여 model이 현재 block에서는 active하고 있지 않지만 이전에 등장했었던 speaker를 잊지 않도록 만듭니다. S_b가 감소하지 않도록 강제하는 것은 speaker가 나중에 다시 나타날 때 가능한 matching을 위해 모든 attractor를 memory에 유지하는 데 도움이 됩니다.
각 block 이후에 모든 attractor를 re-decode하기 때문에, 저자들은 order와 value의 일관성을 유지해야만 합니다. 그래서 저자들은 attractor의 일관성을 유지하기 위해 inference phase에서 몇 가지 heuristic을 사용합니다.

위 표를 통해, 저자들이 각각의 heuristic이 점진적으로 BW-EDA-EEND algorithm의 전체 performance를 향상시키는 것을 볼 수 있습니다. 먼저, attractor를 reorder (permute)하여 이전 block과 현재 block의 cosine similarity를 maximize하도록 만듭니다. 추가적으로, 저자들은 이전 block과 현재 block의 attractor value의 평균을 구해 speaker representation이 더 많은 audio information을 처리함에 따라 더 부드럽게 변화하도록 했습니다.
마지막으로, 저자들은 diarization embedding (LSTM encoder의 input으로 사용되는 output of transformer encoder)을 block 간 shuffle을 했습니다. 목적은 speaker embedding을 memory representation에 점진적으로 추가하는 것입니다. 저자들은 LSTM encoder로 speaker embedding을 보내기 전에 L_S개의 context block 내에서 diarization embedding을 무작위로 shuffle합니다. 저자들은 L이 유한하다면, L_s = L로 설정하고, L이 무한하다면, L_s = 0으로 설정합니다.
Experiments
EDA-EEND를 위해, 저자들은 1명에서 4명 speaker의 meeting mixture를 생성했습니다. input audio feature는 25ms frame length와 10ms frame shift를 사용해 구한 23차원 log-scaled Mel filterbank입니다. 각 feature vector는 이전 7 frame과 이후 7 frame을 concatenate하여 총 15 frame을 concatenate하였습니다. 그다음 concatenate된 feature를 subsample하였습니다. 결과적으로 매 100ms마다 sample된 (23x15) dimensional input feature을 transformer encoder block에 feed했습니다.
저자들은 4개의 256 attention unit을 가진 trasnformer encoder를 stack하였습니다. 저자들은 먼저 two speaker로 이루어진 simulation data를 이용해 3개 system을 학습했습니다. 그다음 1명에서 4명 speaker가 존재하는 simulated data를 이용해 two-speaker model을 finetuning했습니다. 마지막으로, CALLHOME adaptation data (2명에서 7명 사이의 speaker로 이루어진 250개 record)를 이용해 finetuning한 후 CALLHOME test data (2명에서 6명의 speaker가 존재하는 data)로 평가를 진행했습니다.
저자들은 모든 system을 DER로 평가했습니다.
Results
위 표는 이전에 설명한 BW-EDA-EEND의 다양한 algorithm입니다. 저자들은 CALLHOME dataset을 이용해 실험을 진행했습니다. 저자들은 transformer encoder가 left context에만 focus하도록 하고, attention weight를 계산하기 위해 전체 utterance를 사용하는 (Train = offline) 대신 이전 block의 hidden state을 재사용 (Train = causal) 하였습니다. inference에서는, 저자들은 이전 block으로부터 구한 hidden state을 재사용(Inference = causal)하거나 모든 block마다 다시 계산(Inference = offline)하였습니다. 위 표를 보면, transformer encoder를 점진적으로 학습하는 것은 training과 inference mechanism이 일관되기 때문에 정확도를 향상시켰습니다. unlimited-latency BW-EDA-EEND의 경우, 정확도가 2.7% 향상된 것을 볼 수 있으며 limited-latency BW-EDA-EEND는 정확도가 6.2% 향상된 것을 볼 수 있습니다(row 4 vs row 5).
그다음 BW-EDA-EEND의 attractor inference 과정에서, 저자들은 정확도를 향상시키는 몇 가지 heuristic을 비교했습니다(row 4 - 8). attractor를 reordering함으로써, 정확도가 3.8% 향상된 것을 볼 수 있습니다(row 5 vs row 6). attractor averaging을 통해, 정확도가 1.3% 향상된 것을 볼 수 있습니다(row 6 vs row 7). block 간 embedding을 shuffle함으로써 정확도를 1.1% 향상된 것을 볼 수 있습니다(row 7 vs row 8).
이제는 다양한 speaker 수를 포함한 simulated data에 대한 BW-EDA-EEND의 성능을 평가하겠습니다. 먼저 two speaker simulated mixture를 이용해 model을 학습한 후, 4명 speaker까지 존재하는 mixture를 추가적으로 사용해 finetuning했습니다.
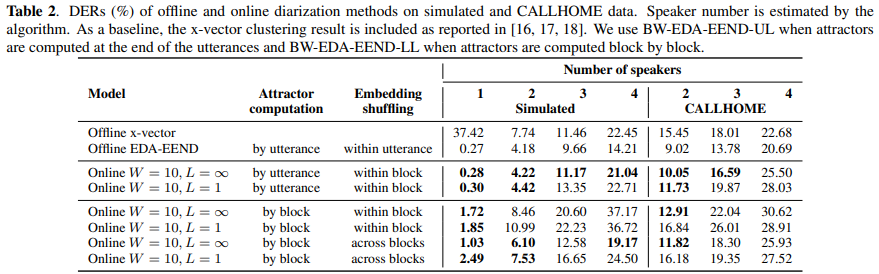
위 결과에서 왼쪽은 context size에 따른 결과입니다. 저자들은 BW-EDA-EEND-UL (attractor가 utterance의 마지막에 계산됨)의 성능을 확인하기 위해 Table1의 row 3번째 algorithm을 사용했습니다. 그리고 BW-EDA-EEND-LL (attractor를 block 별로 계산)의 성능을 확인하기 위해 Table1의 row 7, 8 algorithm을 사용했습니다. 먼저, attractor가 utterance의 마지막에 구해졌을 때, unlimited 또는 10 seconds (L = 1) context를 사용하면 two speaker 까지는 약간의 성능 감소가 있습니다. conversation에서 2명 이상의 speaker가 존재할 때, online과 offline 사이의 정확도 차이는 증가되지만, left context에 대한 제한이 존재하지 않는 BW-EDA-EEND-UL은 여전히 모든 speaker condition에서 baseline clustering based system보다 더 좋은 성능을 보여줍니다.
attractor가 block별로 게산되는 경우, diarization embedding이 across block으로 shuffle되지 않는 경우 BW-EDA-EEND-LL의 성능은 좋지 않습니다. 즉 이를 통해 LSTM이 encoding에서 order-invariance을 학습하기 위해 embedding을 shuffle하는 것이 중요하다는 것을 알 수 있습니다. frame-level embedding이 block 간 shuffle이 이루어진다면, offline clustering based (x-vector) system과 비교할만한 성능을 보여줍니다. 저자들은 EDA가 모든 speaker의 embedding을 받는 것이 정확하게 모든 speaker의 attractor를 계산하는 데 중요하다는 결론을 내렸습니다. 만약 주어진 block에서 speaker 중 일부만 active하고 있다면, 이전 speaker의 정보는 잊혀지는 경향이 있습니다. simulation data에서, conversation의 끝부분에는 몇 명의 speaker만 active하고 있었기 때문에, block별 attractor를 구하는 실험에서는 성능이 감소하는 것을 확인했습니다.
추가적으로, 저자들은 BW-EDA-EEND를 real conversation data로 평가했습니다. real recording을 평가하기 위해, 저자들은 simulated data로 학습된 model을 CALLHOME adaptation set으로 finetuning했습니다. 다양한 block size에 대한 결과는 위 표의 오른쪽과 같습니다. context가 unlimit이거나 10 초일 때, 2명의 speaker까지의 BW-EDA-EEND-UL은 offline EDA-EEND과 비슷한 성능을 보여줍니다. attractor를 각 block마다 구했을 때, diarization embedding이 block 내에서 shuffle되는 경우 BW-EDA-EEND-LL은 좋지 않은 결과를 보여줍니다. 하지만 frame-level embedding이 across block으로 shuffle되는 경우, speaker 수가 3명까지이며 left context unlimit이거나 10 sec (L=1)일 때 BW-EDA-EEND-LL은 clustering-based system과 비교할만한 성능을 보입니다. simulation data와 유사하게, 저자들은 speaker의 subset이 conversation의 일부에서만 등장하는 것을 찾아냈으며, attractor를 block마다 구하는 것은 정확도를 감소시킨다는 것을 보여줬습니다.
Conclusion
저자들은 BW-EDA-EEND-UL (unlimited latency)와 BW-EDA-EEND-LL (limited latency)을 제안했습니다. blockwise online 처리는 incremental transformer encoder를 사용하여 left context에만 집중하고 right context를 무시하며, block 간 정보를 전달하기 위해 hidden state의 block-level recurrence를 사용하여 algorithm의 시간 복잡도가 linear하게 됩니다. BW-EDA-EEND-UL은 two speaker unlimited or 10 second context에 대해 offline EDA-EEND보다 약간의 정확도 감소가 있습니다. BW-EDA-EEND-LL은 frame-level embedding이 across block에서 shuffle되었을 때, offline clustering based system과 비교할만한 정확도를 보여줍니다.



