https://arxiv.org/abs/1703.10135
Tacotron: Towards End-to-End Speech Synthesis
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module. Building these components often requires extensive domain expertise and may contain brittle design c
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
text-to-speech synthesis system은 일반적으로 text analysis frontend, acoustic model, audio synthesis module과 같은 multiple stage로 구성됩니다. 이렇게 component를 build하는 것은 광범위한 전문지식을 필요로 합니다. 이 논문에서, 저자들은 Tacotron이라 불리는 end-to-end generative text-to-speech model을 제안합니다. Tacotron은 chracter로부터 speech를 바로 생성합니다. <text, audio> 쌍이 주어지면, model은 random initialization을 통해 처음부터 훈련될 수 있습니다. 저자들은 challenging task에서 sequence-to-sequence framework가 잘 동작하도록 만드는 몇 가지 key techniques을 제안합니다.
Introduction
현대 text-to-speech (TTS) pipeline은 복잡합니다. 예를 들어, statistical parametric TTS는 다양한 linguistic feature를 추출하는 text frontend, duration model, acoustic feature prediction model을 사용하고 복잡한 signal-processing based vocoder를 사용합니다. 이러한 component들은 광범위한 domain 전문 지식을 필요로 하고 design하기 상당한 노력이 필요합니다. 각 component들은 독립적으로 학습되기 때문에 각 component에서 발생하는 error들이 누적될 수 있습니다. 그렇기 때문에 새로운 TTS system을 설계할 때 상당한 노력이 필요합니다.
<text, audio> 쌍을 가지고 human annotation을 최소로 하여 학습된 end-to-end TTS system은 몇 가지 이점이 있습니다. 먼저, 이러한 system들은 heuristic이나 design을 choice하는 것과 같은 번거로운 feature engineering의 필요성을 줄입니다. 둘째로, speaker, language와 같은 다양한 특성이나 감정과 같은 high-level features에 대한 풍부한 condition 설정을 더 쉽게 할 수 만듭니다. conditioning은 특정 component가 아니라 model의 초반부에만 적용할 수 있기 때문입니다. 비슷하게, 새로운 data로의 adaptation도 쉽게 진행될 수 있습니다. 마지막으로, single model은 각 component의 error가 누적될 수 있는 multi-stage model보다 더 robust합니다. 이러한 장점들이 end-to-end model을 real world에 있는 풍부하고 표현력이 있으나 종종 noise가 많은 대량의 data에 대해 훈련할 수 있게 만들어줍니다.
TTS는 large-scale inverse problem이 있습니다. 매우 압축된 source (text)를 audio로 decompress해야 합니다. 같은 text에 대해 다른 발음과 다른 speaking style로 발음될 수 있기 때문에, end-to-end model의 학습이 어려워집니다. 즉 signal level의 input에 대해 큰 variation을 다룰 수 있어야만 합니다. 그리고 end-to-end speech recognition이나 machine translation과 다르게, TTS는 연속적인 output을 만들어주고, output sequence는 주로 input보다 더 긴 length를 보입니다. 이러한 특성 때문에 prediction error가 빠르게 누적됩니다. 이 논문에서 저자들은 Tacotron이라는 end-to-end generative TTS model을 제안합니다. 이는 sequence-to-sequence (seq2seq)에 attention paradigm을 적용하여 구현됩니다. 저자들의 model은 character를 input으로 사용하고, raw spectrogram을 output합니다. 그리고 몇 가지 technique들을 사용하여 기본적인 seq2seq model의 성능을 향상시켰습니다. <text, audio> 쌍이 주어졌을 때, Tacotron은 random initialization을 통해 완전히 처음부터 학습될 수 있습니다. Tacotron은 phoneme-level alignment를 사용하지 않기 때문에, transcript이 있는 많은 양의 acoustic data를 사용하여 쉽게 scale할 수 있습니다. 간단한 waveform synthesis technique을 이용하여, Tacotron은 자연스러운 speech를 생성할 수 있습니다.
Related work
WaveNet은 audio를 생성하는 powerful한 model입니다. 이는 TTS에서도 잘 동작하지만, sample-level autoregressive 하기 때문에 생성 속도가 느립니다. 그리고 WaveNet은 기존 TTS frontend에서 linguistic feature를 condition으로 사용하기 때문에 end-to-end 방식이 아닙니다. WaveNet은 단지 vocoder와 acoustic model로 사용되었을 뿐입니다. 또 다른 최근에 개발된 neural model인 DeepVoice는 TTS pipeline에 존재하는 모든 component를 neural network로 대체하는 model입니다. 그러나 각 component들이 독립적으로 학습되기 때문에, end-to-end 방식으로 system을 학습하기 위해 변경하는 것은 쉽지 않습니다.
저자들이 알기로는, attention방식으로 구현된 seq2seq를 사용한 것이 가장 처음 등장한 end-to-end TTS입니다. 하지만, 이는 seq2seq model이 alignment (text, audio)를 학습하는 것을 돕기 위해 pre-train된 hidden Markov model (HMM) aligner가 필요로 합니다. seq2seq를 통해 얼마나 alignment가 학습되었는지 말하기 어렵습니다. 둘째, model을 학습하기 위해 몇 가지 trick이 사용되는데, 이는 운율을 해친다고 합니다. 세 번째, vocoder parameter를 예측하기 때문에 vocoder를 필요로 합니다.
Char2Wav는 독립적으로 개발된 end-to-end model이며, 이는 character를 이용해 학습됩니다. 하지만 Char2Wav는 여전히 SampleRNN neural vocoder를 사용하기 이전에 vocoder parameter를 예측하는 방식입니다. 하지만 Tacotron은 raw spectrogram을 바로 predict합니다. 또한, seq2seq와 SampleRNN model은 분리된 pre-trained model이지만, Tacotron은 한 번에 모든 component들이 학습됩니다.
Model Architecture
Tacotron의 backbone은 seq2seq model with attention입니다. 구조는 다음과 같습니다.
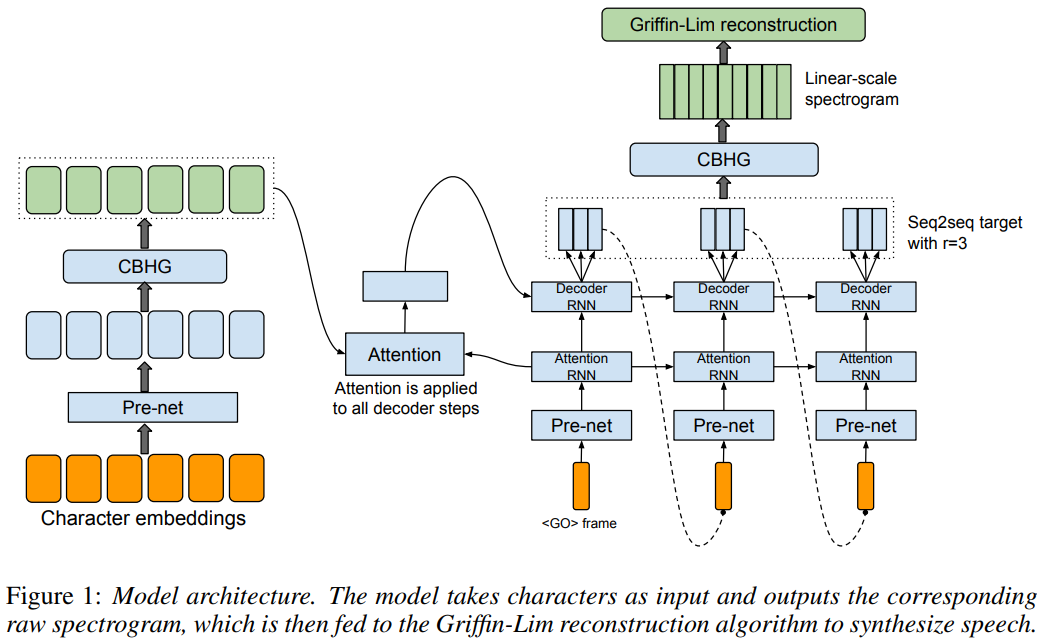
위 구조는 encoder와 attention-based decoder, post-processing network로 구성됩니다. character를 input으로 받아 spectrogram frame을 output하며, 이 spectrogram은 waveform으로 변환됩니다.
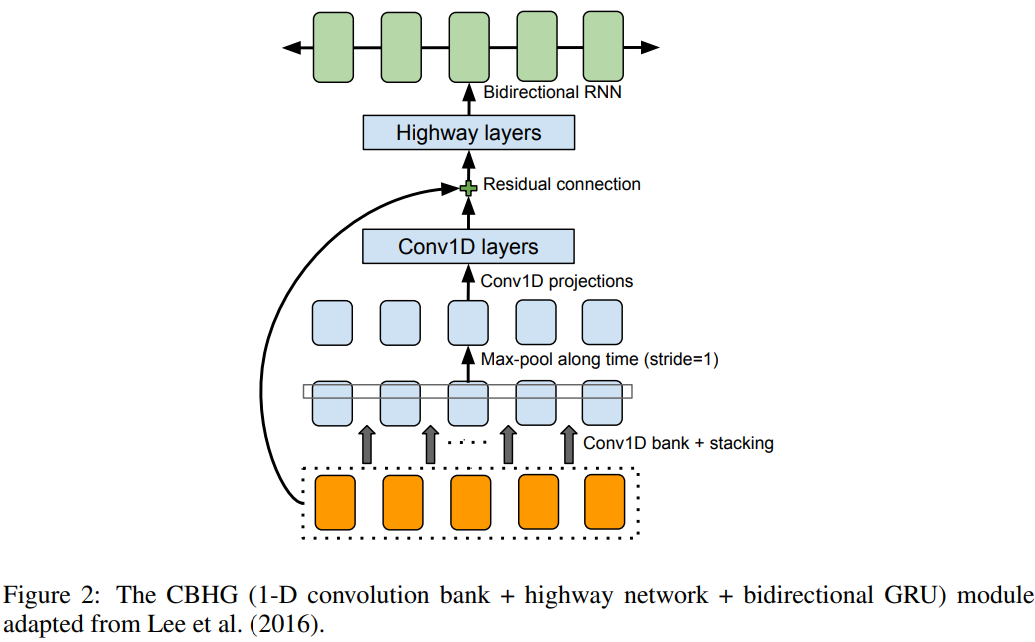
CBHG는 위와 같습니다.
CBHG module
CBHG라는 block에 대해 먼저 알아보겠습니다. CBHG는 1-D convolutional filter bank와 그 뒤에 따라오는 highway network와 bidirectional gated recurrent unit (GRU) recurrent neural net (RNN)으로 구성됩니다. CBHG는 sequence로부터 representation을 추출하는 powerful한 module입니다. input sequence는 K개의 1D convolutional filter를 가지고 convolution됩니다. 여기서 k번째 set은 width가 k인 C_k개 filter를 가지고 있습니다. 이러한 filter들은 local information과 contextual information을 model할 수 있습니다. convolution output은 stack되고 local invariance를 증가시키기 위해 시간에 따라 max pooled 됩니다. original time resolution을 보존하기 위해 stride는 1로 설정했습니다. 처리된 sequence를 몇 개의 fixed-width 1-D convolution에 feed합니다. output은 residual connection을 통해 original input sequence과 더해집니다. Batch normalization은 모든 convolutional layer에서 사용됩니다. convolution output은 multi-layer highway network에 feed 됩니다. 이를 통해 high-level feature를 추출합니다. 마지막으로, forward context와 backward context의 sequential feature를 추출하기 위해 bidirectional GRU RNN을 stack합니다.
Encoder
encoder의 goal은 text의 robust sequential representation을 추출하는 것입니다. encoder의 input은 character sequence이며, 각 character들은 one-hot vector로 표현되고 continuous vector로 embedding됩니다. 그다음 "pre-net"이라 불리는 non-linear transformation을 각 embedding에 적용합니다. pre-net은 dropout이 있는 bottleneck layer로 구현되며, 이를 통해 수렴할 수 있도록 도와주며 generalization을 향상시켜줍니다. CBHG module은 attention module을 이용해 prenet output을 final encoder representation으로 변환됩니다. 이러한 CBHG기반 encoder는 overfitting을 방지할 뿐만 아니라, standard multi-layer RNN encoder에 비해 더 적은 mispronuciation을 만듭니다.
Decoder
저자들은 content-based tanh attention decoder를 사용합니다. 이는 각 decoder time step에서 stateful recurrent layer가 attention query를 생성합니다. 저자들은 context vector와 attention RNN cell output을 concatenate하여 decoder의 RNN의 input을 만듭니다. 그리고 decoder에서 수직으로 residual connection이 있는 GRU stack을 사용합니다. residual connection이 수렴 속도를 향상시켜줍니다. decoder target을 선택하는 것은 매우 중요합니다. 저자들은 raw spectrogram을 바로 output하도록 만들었지만, 이는 speech signal과 text 사이의 alignment를 학습하는 목적에서는 매우 중복된 representation입니다(decoder가 생성한 raw spectrogram을 이용해 speech와 text의 alignment를 학습하는 건 비효율적임을 의미. raw spectrogram이 훨씬 많은 정보량을 포함하고 있기 때문입니다). 이러한 중복 때문에, 저자들은 seq2seq decoding, waveform synthesis을 위해 다른 target을 사용했습니다. seq2seq target은 inversion process에 충분한 이해도와 prosody information을 제공하는 한 매우 압축될 수 있으며, 이는 고정되거나 train될 수 있습니다. 그래서 저자들은 seq2seq의 target으로 80-band mel-scale spectrogram을 사용합니다. 물론 더 적은 band를 사용하거나 cepstrum과 같은 더 간결한 target을 사용해도 됩니다. 저자들은 post-processing network이 seq2seq target을 waveform으로 변환하도록 만들었습니다.
저자들은 fully-connected output layer를 사용해 decoder target을 생성하도록 만들었습니다. 중요한 trick으로, 각 decoder step에서 여러 개의 non-overlapping output frame을 predict하도록 하는 것입니다. 한 번에 r개의 frame을 예측하는 것은 총 decoder step 수를 r로 나누어 model size를 줄일 수 있고 training time과 inference time도 줄일 수 있습니다. 더 중요한 것은 attention을 통해 학습된 alignment가 훨씬 더 빠르고 안정적이기 때문에, 상당한 수렴 속도의 향상을 이끌어냈다는 점입니다. 인접한 speech frame들이 연관성이 있고 각 character가 주로 여러 frame에 연관이 있기 때문에 이러한 결과가 가능합니다. 한번에 하나의 frame을 emit하는 것은 model이 여러 timestep에 걸쳐 동일한 input token에 attend하도록 만듭니다. multiple frame을 emit하는 것은 train초기에 빠르게 forward하도록 허용합니다.
첫 decoder step은 all-zero frame을 condition으로 사용하며, <GO> frame으로 표현됩니다. inference에서는, decoder step t에서 r개 prediction의 마지막 frame은 decoder의 t+1번째 step의 input으로 feed됩니다. last prediction을 feeding하는 것은 임시적인 선택지입니다. r개 prediction 전부를 사용하여 다음 step의 input으로 feed해도 됩니다. training에서는, 저자들은 모든 r번째 ground truth frame을 decoder에 feed합니다. input frame은 encoder에서 수행된 것처럼 pre-net에 전달됩니다. scheduled sampling은 audio quality를 저하시키기 때문에 사용하지 않았습니다. pre-net에 dropout을 사용하는 것은 output distribution의 다양한 mode를 해결하기 위한 noise source를 제공해 주기 때문에 model이 generalize되는 데 중요한 역할을 합니다. 그래서 pre-net에 dropout을 적용했습니다.
Post-processing Net and Waveform Synthesis
post-processing network는 seq2seq target을 waveform을 합성할 수 있는 target으로 변환하는 것입니다. Griffin-Lim을 synthesizer로 사용하기 때문에, post-processing network가 linear-frequency scale로 sample된 spectral magnitude를 예측하도록 학습됩니다. seq2seq는 항상 left에서 right 방향으로 동작하는데, post-processing network는 모든 decoded sequence를 볼 수 있습니다. 그래서 각 individual frame에 대한 prediction error를 수정하기 위해 forward information과 backward information 모두 사용할 수 있습니다. 저자들은 post-processing network로 CBHG moduel을 사용했지만, 더 간단한 architecture도 잘 동작합니다. post-processing network는 vocoder parameter와 같은 target을 예측하거나, WaveNet과 같은 neural vocoder를 사용해 waveform sample을 바로 합성하기도 합니다.
저자들은 Griffin-Lim algorithm을 사용해 예측된 spectrogram을 waveform으로 합성했습니다. 저자들은 예측된 magnitude를 Griffin-Lim에 feed하기 전에 1.2의 제곱으로 키웠습니다. 이를 통해 artifact를 줄일 수 있었으며, harmonic 향상 효과 때문인 것으로 보입니다. Griffin-Lim은 50번의 반복을 한다면 수렴하는 걸 알아냈습니다. 이 정도면 충분히 빠른 속도라 합니다. Griffin-Lim은 미분 가능하지만, 어떠한 loss도 부여하지 않았습니다. 저자들은 Griffin-Lim을 단순화를 위해 사용하였으며, 이미 좋은 결과를 제공해 주기 때문에 어떠한 loss도 사용하지 않았다고 합니다.
Model Details
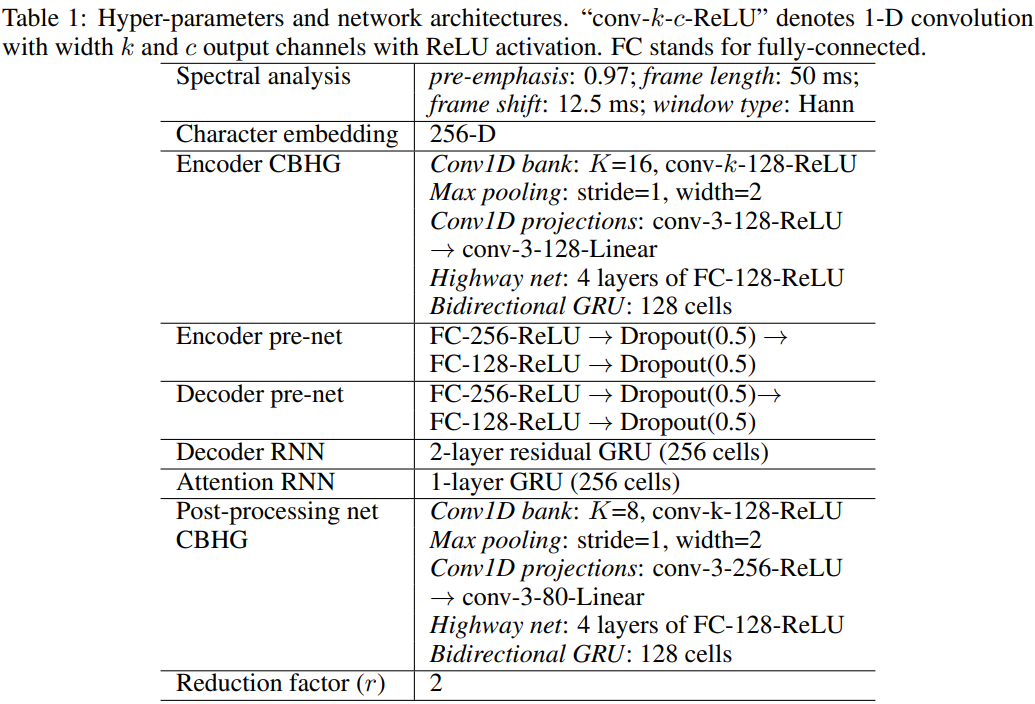
위 표는 network architecture의 hyper-parameter를 보여줍니다. 50ms frame length, 12.5ms frame shift, 2048-point fourier transform을 통해 log magnitude spectrogram을 구했습니다. 그리고 모든 실험에서 24kHz sampling rate를 사용했습니다.
저자들은 r = 2로 설정했습니다. r = 5처럼 큰 value로 사용해도 잘 동작합니다. 저자들은 L1 loss를 seq2seq decoder (mel-scale spectrogram)과 post-processing net (linear-scale spectrogram)에 사용했습니다. 두 loss에 동일한 weight를 두어 loss function을 정의했습니다.
Experiments
저자들은 internal North American English dataset을 이용해 Tacotron을 학습했습니다. 해당 dataset은 약 24.6시간의 speech data이며, 전문적인 여성 speaker가 녹음했습니다.
Ablation Analysis
저자들의 model에서 사용하는 key component들의 이해를 위해 ablation study를 진행합니다. 일반적인 generative model의 경우, objective metric를 기반으로 하는 model들과 비교하기 어렵습니다. 그래서 저자들은 결과를 visualize하여 비교했습니다.
먼저, vanilla seq2seq model과 비교합니다. encoder와 decoder 모두 2개의 residual RNN layer을 사용하며, 각 layer는 256 GRU cell을 사용합니다.
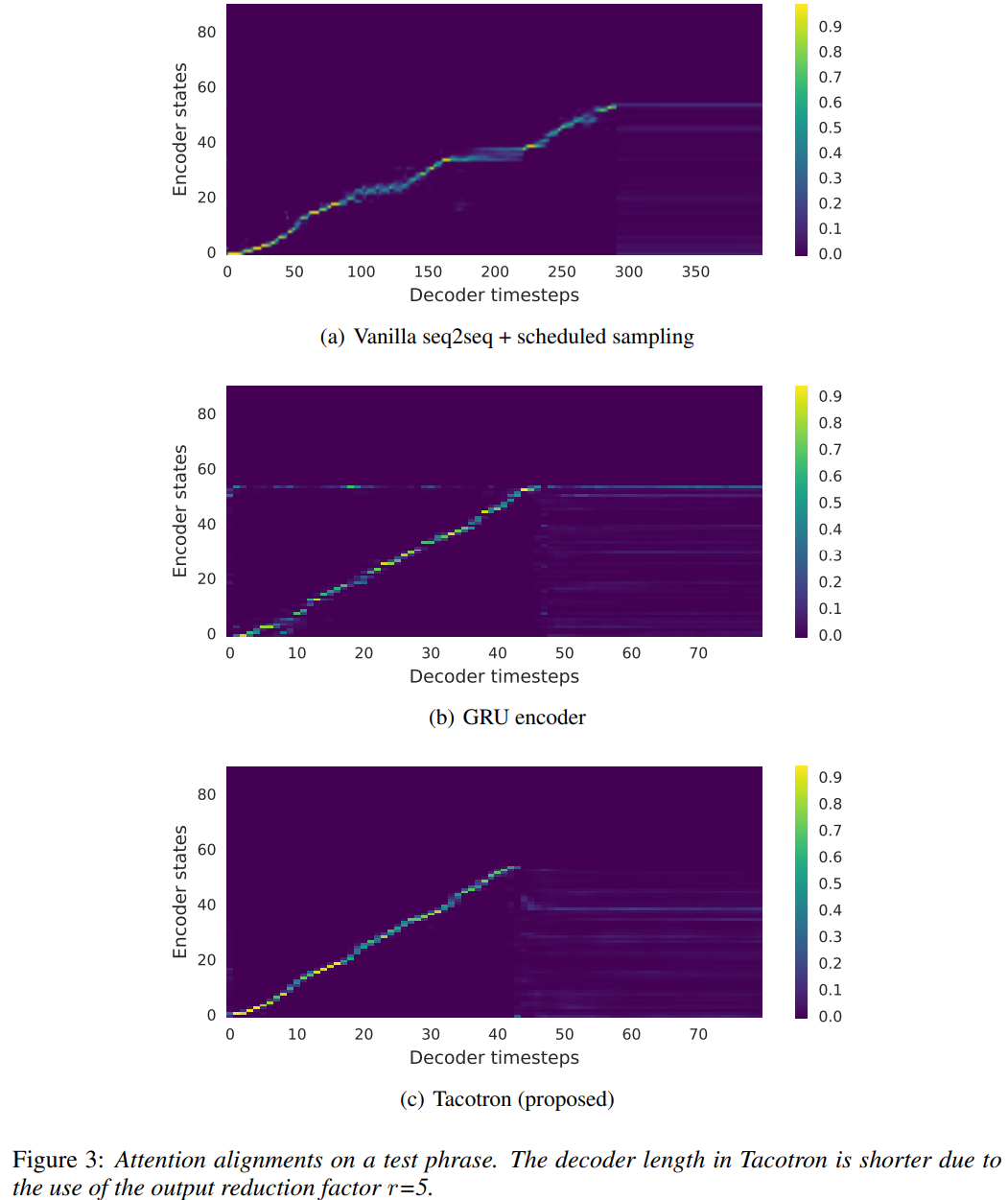
위 그림은 학습된 attention alignment를 보여줍니다. (a)는 vanilla seq2seq가 alignment를 잘 학습하지 못한다는 것을 보여줍니다. attention은 forward하기 전에 많은 frame이 멈추는 경향이 있기 때문에(input text의 특정 부분에 지나치게 focus하게 되어 해당 부분에 대응하는 음성 frame이 반복되거나 멈추는 현상이 발생), 합성된 signal이 좋지 않은 speech intelligibility를 갖게 됩니다. 자연스러움과 전체 duration이 결과에서 붕괴되는 모습을 보여줍니다. 대조적으로, 저자들이 제안한 model은 명료하고 자연스러운 alignment를 학습합니다.
둘째로, 저자들은 CBHG encoder를 2-layer residual GRU encoder로 대체하는 model과 비교했습니다. 다른 network들은 동일하게 사용했습니다. 위 그림 (b)와 (c)를 보면, GRU encoder가 더 noise가 존재하는 걸 볼 수 있습니다. 합성된 signal을 들어보면, noisy alignment가 mispronunciation하다는 것을 볼 수 있었습니다. CBHG encoder는 overiftting을 줄이거나 길고 복잡한 phrase에 대한 일반화 성능도 괜찮습니다.

위 그림 (a), (b)를 보면 post-processing network의 이점을 확인할 수 있었습니다. post-processing network를 제외하고 다른 component들은 그대로 유지했습니다. 그 대신, decoder RNN이 linear-scale spectrotram을 생성하도록 만들었습니다. post-processing network를 이용해 예측한 결과가 더 많은 contextual information을 담고 있으며, harmonic 문제를 해결하고 high frequency structure를 잘 복원할 수 있었습니다.
Mean Opinion Score (MOS) Test
저자들은 mean opinion score test를 진행했습니다. 이를 통해 자연스러움을 확인할 수 있었습니다. 결과는 다음과 같습니다.
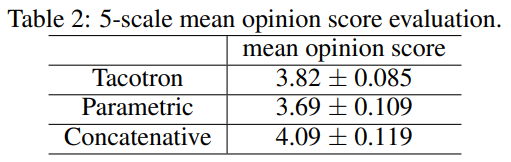
parametric (based on LSTM)과 concatenative system을 이용해 Tacotron의 성능을 비교했습니다. Tacotron에서 사용되는 Griffin-Lim은 artifact를 생성하는 경향이 있지만 위와 같은 MOS test 결과를 보였으며, 매우 유망한 결과임을 확인할 수 있습니다.
Discussion
저자들은 Tacotron을 제안했으며, 이는 end-to-end generative TTS model입니다. 이는 character sequence를 input으로 받으며 그에 대응하는 spectrogram을 output하는 model입니다. 매우 간단한 waveform synthesis module을 사용하여 좋은 MOS 성능을 보였습니다. Tacotron은 frame-base이기 때문에, inference는 autoregressive method에 비해 빠릅니다. 이전 연구들과 다르게, Tacotron은 hand-engineered linguistic feature나 HMM aligner와 같은 complex component를 사용하지 않습니다. 간단한 text normalization을 Tacotron과 같이 사용했습니다.



