Neural network 기반 end-to-end text to speech (TTS)는 합성된 speech의 quality를 상당히 향상시켰습니다. Tacotron 2와 같이 유명한 method들은 주로 text로부터 mel-spectrogram을 생성한 다음, WaveNet과 같은 vocoder를 이용해 mel-spectrogram을 speech로 합성합니다. 전통적인 concatenative 방식과 statistical parametric 방식과 비교했을 때, neural network 기반 end-to-end model들은 inference speed가 느리고, 합성된 speech가 robust (몇몇 단어를 생략하거나 반복) 하지 않으며 control (voice speed나 운율을 조절) 하기 힘듭니다.
이 논문에서, Transformer 기반 feed-forward network를 사용해 mel-spectrogram을 병렬적으로 생성합니다. 구체적으로, 저자들은 encoder-decoder 기반 teacher model을 사용해 attention alignment를 추출합니다. 추출한 attention alignment를 이용해 phoneme duration prediction합니다. phoneme duration predict 결과를 length regulator에 사용해서 source phoneme sequence를 target mel-spectrogram sequence의 길이에 맞게 확장하여 병렬적으로 mel-spectorgram을 생성 가능하게 만듭니다. 실험을 통해 저자들의 parallel model이 autoregressive model과 비슷한 quality의 speech를 생성하고, 단어를 생략하거나 반복하는 문제를 거의 해결했습니다. 그리고 voice speed도 자연스럽게 조절가능하게 만들었습니다. 그리고 저자들이 제안한 model은 autoregressive TransformerTTS에 비해 mel-spectrogram 생성 속도가 270배 빠르고, end-to-end speech 합성과는 38배 빠릅니다. 그래서 저자들의 model을 FastSpeech라고 부릅니다.
Introduction
TTS는 최근 몇 년동안 deep learning의 발전에 의해 많은 주목을 받았습니다. Tacotron, Tacotron2, Deep Voice3, fully end-to-end ClariNet과 같은 Deep neural network 기반 TTS system들이 점점 더 유명해지고 있습니다. 이러한 model들은 text input을 이용해 mel-spectrogram을 autoregressive하게 만들고, mel-spectrogram을 Griffin-Lim, WaveNet, Parallel WaveNet, WaveGlow와 같은 vocoder를 사용해 speech로 합성합니다. neural network 기반 TTS들은 이전의 concatenative 방식이나 statistical parametric 방식보다 더 speech quality가 좋습니다.
최근에 등장한 neural network 기반 TTS system들은 mel-spectrogram을 autoregressive하게 만듭니다. mel-spectrogram sequence는 길고 autoregressive 방식의 특성 때문에, 이러한 system들은 몇 가지 문제점이 존재합니다.
mel-spectrogram을 생성하는 inference 속도가 느립니다. CNN과 Transformer 기반 TTS들은 RNN기반 model들보다 training 속도가 더 빠르지만, 결국 이전에 생성한 mel-spectrogram을 condition으로 하여 mel-spectrogram을 생성하기 때문에 inference 속도가 느립니다. 그리고 mel-spectrogram sequence는 보통 100에서 1000 정도의 길이이기 때문에 생성속도가 느립니다.
합성된 speech는 robust하지 않습니다. speech를 autoregressive하게 생성할 때 error propagation과 text와 speech 사이의 wrong attention alignment이 생기며, 생성된 mel-spectrogram은 보통 단어를 생략하거나 반복하는 문제들이 발생합니다.
합성된 speech는 controllability가 떨어집니다. 이전에 등장한 autoregressive model들은 text와 speech 사이의 alignment를 명시적으로 활용하지 않고 mel-spectrogram을 하나씩 자동으로 생성합니다. 따라서 autoregressive model은 voice speed와 prosody를 직접 제어하는 것이 어렵습니다.
text와 speech 사이의 단조로운 alignment를 고려하여, 저자들은 mel-spectrogram 생성 속도를 향상시키는 FastSpeech를 제안합니다. 이는 text (phoneme) sequence를 input으로 받아 mel-spectrogram을 non-autoregressive하게 생성합니다. 이는 Transformer에 self-attention을 적용하고 1D convolution을 사용하는 feed-forward network입니다. mel-spectrogram sequence가 그에 대응하는 phoneme sequence보다 훨씬 더 길기 때문에, 두 sequence의 길이기 맞지 않은 문제를 해결하기 위해 FastSpeech는 length regulator를 사용합니다. length regulator는 phoneme sequence를 phoneme duration에 맞춰 upsample 합니다(예를 들어, 각 phoneme에 대응하는 mel-spectrogram 수를 이용해 upsample하는 방식이 있습니다). 이를 통해 mel-spectrogram과 동일한 length가 되도록 만들 수 있습니다. regulator는 phoneme duration predictor를 이용해 구현되는데, 이는 각 phoneme의 duration 길이를 예측하는 model입니다.
저자들의 FastSpeech는 위에서 언급한 3가지 문제를 다음과 같이 다룹니다.
병렬적으로 mel-spectrogram을 생성하여, FastSpeech는 합성 속도를 매우 향상시켰습니다.
phoneme duration predictor는 phoneme과 mel-spectrogram 사이의 강력한 alignment를 보장하며, 이는 autoregressive model에 존재하는 soft하고 automatic한 alignment와는 매우 다릅니다. 그러므로, FastSpeech는 error propagation 문제와 wrong attention alignment 문제를 피할 수 있었으며, 결과적으로 생략되는 단어나 반복되는 단어 비율을 줄일 수 있었습니다.
length regulator는 phoneme durtation의 길이를 조절하여 생성된 mel-spectrogram의 길이를 조절할 수 있으며, 이를 통해 voice speed를 조절할 수 있습니다. 그리고 length regulator는 인접한 음소 사이에 break를 추가하여 운율의 일부를 control할 수 있습니다.
Background
Text-to-Speech
TTS는 주어진 text에 대해 자연스럽고 인지할 수 있을 정도의 speech를 만드는 것이 목표이며, AI 연구 분야에서 오랜 기간 동안 주목받는 주제였습니다. TTS에 대한 연구는 concatenative synthesis, statistical parametric synthesis에서 neural network 기반 parametric synthesis나 end-to-end model로 변하고 있습니다. 합성된 speech의 quality는 인간과 유사한 quality를 보이고 있습니다. neural network 기반 end-to-end TTS model은 text를 acoustic feature (e.g., mel-spectrogram)으로 변환하고 난 후 mel-spectrogram을 audio sample로 변환합니다. 그러나 대부분의 neural TTS system은 mel-spectrogram을 autoregressive하게 생성하기 때문에, inference speed가 느리고 합성된 speech의 robustness가 부족하며 controllability가 부족하다는 문제가 있습니다. 이 논문에서는 FastSpeech를 제안하며, 이는 mel-spectrogram을 non-autoregressive하게 생성하며, 언급한 문제들을 해결합니다.
Sequence to Sequence Learning
Sequence to sequence learning은 주로 encoder-decoder framework로 구현됩니다. encoder는 source sequence를 input으로 받아서 representation set을 생성합니다. 그다음 decoder는 주어진 source representation와 이전 element를 condition으로 하는 각 target element의 조건부 확률을 추정합니다. attention mechanism은 현재 element를 예측하기 위해 어떤 source representation을 focus해야하는지 찾기 위해 encoder와 decoder에 사용됩니다. 그리고 이는 sequence to sequence learning에서 중요한 역할을 합니다.
이 논문에서, 저자들은 sequence to sequence learning을 할 때 conventional encoder-attention-decoder framework를 사용하는 대신, feed-forward network를 이용하며 sequence를 병렬적으로 생성할 수 있습니다.
Non-Autoregressive Sequence Generation
autoregressive sequence generation과 다르게, non-autoregressive model은 sequence를 병렬적으로 생성합니다. 이는 이전 element에 명시적으로 depend하지 않으며 inference process의 속도를 매우 향상시킬 수 있습니다. non-autoregressive generation은 neural machine translation, audio synthesis와 같이 sequence를 생성하는 task에서 연구되어 왔습니다. 저자들의 FastSpeech는 2가지 측면의 차이가 있습니다. 1) 이전에 등장한 neural machine translation 또는 audio synthesis의 non-autoregressive generation은 주로 inference speed를 향상시키기 위해 사용되었습니다. 하지만 FastSpeech는 inference speed 향상뿐만 아니라, 합성된 speech의 robustness와 controllability를 향상시키는 것에 초점을 맞춰 non-autoregressive method를 사용했습니다. 2) TTS에서, parallel WaveNet, Clarinet, WaveGlow는 audio를 병렬적으로 생성하지만, 다 mel-spectrogram을 condition으로 사용합니다. 결국, 여전히 autoregressive하게 audio를 생성하게 됩니다(mel-spectrogram을 생성할 때는 autoregressive하게 생성되기 때문!). 그러므로, 해당 model들은 저자들이 고려하는 challenge를 해결하지 못합니다. 물론 mel-spectrogram을 병렬적으로 생성하는 연구도 있습니다. 하지만, 이는 attention mechanism을 적용한 encoder-decoder를 사용합니다. 결국 teacher model에 비해 2배에서 3배 정도 parameter가 더 많으며, inference speed가 FastSpeech보다 느립니다. 그리고 해당 연구는 단어를 생략하거나 반복하는 문제를 거의 해결하지 못했습니다. 하지만 FastSpeech는 거의 해결했습니다.
FastSpeech
target mel-spectrogram sequence를 병렬적으로 생성하기 위해, 저자들은 encoder-attention-decoder based 대신 feed-forward structure를 제안합니다. autoregressive model이든 non-autoregressive model이든 대부분의 model들은 encoder-attention-decoder based입니다. 저자들의 model은 다음과 같습니다.
Feed-Forward Transformer
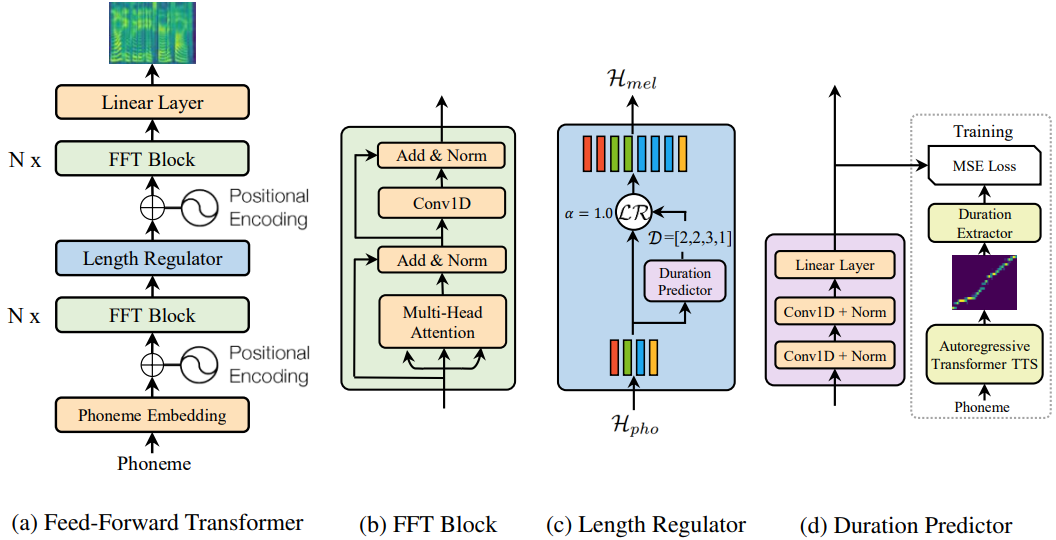
FastSpeech 구조는 self-attention Transformer, 1-D convolution 기반 feed-forward structure입니다. 저자들은 이 구조를 Feed-forward Transformer (FFT)라고 부릅니다. 구조는 위 그림 (a)와 같습니다. Feed-Forward Transformer는 여러 개의 FFT block을 stack하여 phoneme을 mel-spectrogram으로 변환합니다. N개의 FFT block을 phoneme 쪽에 사용하고, N개의 block을 mel-spectrogram 쪽에 사용합니다. 그리고 length regulator를 이용해 phoneme sequence length와 mel-spectrogram sequence length 차이를 연결합니다. 각 FFT block은 self-attention과 1D convolutional network로 구성됩니다. (b)와 같습니다. self-attention network는 multi-head attention을 이용해 cross-position information을 추출합니다. Transformer의 2-layer dense network와 다르게, 저자들은 2-layer 1D convolutional network와 ReLU를 사용합니다. speech task에서 character/phoneme sequence와 mel-spectrogram sequence들은 인접한 hidden state들이 더 밀접한 관련이 있기 때문에 이와 같은 구조를 적용했습니다. 저자들은 1D convolutional network의 효과를 실험을 통해 평가했습니다. Transformer를 따라, self-attention network와 1D convolutional network 뒤에 residual connection, layer normalization, dropout을 추가했습니다.
Length Regulator
위 그림 (c)는 length regulator를 보여줍니다. length regulator는 phoneme sequene length와 spectrogram sequence length의 차이가 존재하는 문제를 해결하기 위해 사용됩니다. 그리고 voice speed와 일부 prosody를 control하기 위해서도 사용되었습니다. phoneme sequence의 길이는 mel-spectrogram sequence의 길이보다 일반적으로 더 짧고, 각 phoneme은 몇 개의 mel-spectrogram에 대응됩니다. 저자들은 phoneme에 대응하는 mel-spectrogram의 length를 phoneme duration으로 정의했습니다. phoneme duration d를 기반으로, length regulator는 phoneme sequence의 hidden state를 d배 확장하며, 그로 인해 hidden state의 최종 length는 mel-spectrogram의 length와 일치하게 됩니다. phoneme sequence의 hidden states를 H_pho = [h_1, ... , h_n]으로 표기하겠습니다. 여기서 n은 sequence의 length입니다. phoneme duration sequence는 D = [d_1, ... , d_n]으로 표기하겠습니다. 여기서 d_i의 합은 m이 되며, m은 mel-spectrogram sequence의 length가 됩니다. 이러한 length regulator는 다음과 같이 정의합니다.
여기서 α는 확정된 sequence H_mel의 length를 결정하기 위해 사용되는 hyperparameter이며, 이를 통해 voice speed를 조절할 수 있습니다. 예를 들어 H_pho = [h_1, h_2, h_3, h_4]가 주어지고 이에 대응하는 phoneme duration sequence D = [2, 2, 3, 1]이고 α = 1 (normal speed) 일 때, 확장된 sequence H_pho는 [h_1, h_1, h_2, h_2, h_3, h_3, h_3, h_4]가 됩니다. 만약 α = 1.3 (slow speed)이면 duration sequence D = [2.6, 2.6, 3.9, 1.3] → [3, 3, 4, 1]이 됩니다. 만약 α = 0.5 (fast speed)라면 duration sequence D = [1, 1, 1.5, 0.5] → [1, 1, 2, 1]이 됩니다. 이를 토대로 확장된 sequence는 [ h_1, h_1, h_1, h_2, h_2, h_2, h_3, h_3, h_3, h_3, h_4]와 [h_1, h_2, h_3, h_3, h_4]가 됩니다. 또한 저자들은 sentence에서 공백 문자의 duration을 조절하여 단어 사이의 침묵을 control하며, 이를 통해 합성된 speech의 운율의 일부를 조절할 수 있습니다.
Duration Predictor
phoneme duration prediction은 length regulator에서 중요합니다. 위 그림 (d)와 같이, duration predictor는 2-layer 1D convolutional network with ReLU로 구성됩니다. 각 layer 뒤에는 layer normalization과 dropout layer가 있습니다. 그리고 추가적인 linear layer가 존재하며 이는 scalar를 output합니다. 이 scalar 값은 예측된 phoneme duration입니다. duration predictor는 phoneme 부분의 FFT block의 마지막 부분에 stack되어 있으며, phoneme의 mel-spectrogram length를 예측하기 위해 mean square error를 이용해 FastSpeech model과 함께 학습됩니다. 저자들은 log domain에서 length를 예측하는데, 이는 훈련하기 더 쉬운 Gaussian distirbution에 가까워집니다. 학습된 duration predictor는 TTS inference에서만 사용됩니다. 왜냐하면 training 할 때는 autoregressive teacher model로부터 추출된 phoneme duration을 바로 사용하기 때문입니다.
duration predictor를 학습하기 위해, 저자들은 ground-truth phoneme duration을 autoregressive teacher TTS model에서 추출합니다. 자세한 과정은 다음과 같습니다.
autoregressive encoder-attention-deocder 기반 Transformer TTS model을 먼저 학습합니다.
각 sequence pair를 학습하기 위해, 저자들은 학습된 teacher model에서 decoder-to-encoder attention alignment를 추출합니다. multi-head self-attention 때문에 여러 개의 attention alignment이 생기며, 모든 attention heads가 대각 성질을 갖는 것은 아닙니다(phoneme sequence와 mel-spectrogram sequence가 단조적으로 alignment되는 것이 아닙니다). 그래서 저자들은 attention head가 대각선에 얼마나 가까운지 측정하기 위해 focus rate F를 제안합니다.
F는 위와 같습니다. 여기서 S는 ground-truth spectrogram length를 의미하고, T는 ground-truth phoneme length를 의미합니다. a_s,t는 attention matrix의 s번째 행의 t번째 열 element를 의미합니다. 저자들은 각 head에서 focus rate F를 계산하고, 가장 F가 큰 ehad를 선택해 attention alignment로 사용합니다.
마지막으로, duration extractor d_i에 따라 phoneme duration sequence D = [d_1, ... , d_n]을 추출합니다. 여기서 duration extractor는 다음과 같습니다.
phoneme의 duration은 위 step에서 선택된 attention head에 따라 attend된 mel-spectrogram의 수를 의미합니다.
Experimental Setup
Details
저자들은 LJSpeech dataset을 이용해 실험했습니다. 해당 dataset은 13100개의 english audio clip으로 구성되며, 각 clip에 맞는 transcript이 있습니다. 총 audio length는 약 24시간 정도입니다. 저자들은 dataset을 random하게 3개의 set으로 나눴습니다. 12500개의 sample은 training을 위해 사용하고, 300개의 sample은 validation을 위해 사용하고, 나머지 300개의 sample은 test를 위해 사용했습니다. mispronunciation 문제를 피하기 위해, 저자들은 grapheme-to-phoneme conversion tool을 이용해 text sequence를 phoneme sequence로 변환했습니다. speech data의 경우, 저자들은 raw waveform을 mel-spectrogram으로 변환했습니다. 저자들은 1024 frame size를 사용하고 hop size는 256으로 설정했습니다.
FastSpeech의 robustness를 평가하기 위해, 저자들은 TTS system이 다루기 힘든 50개의 문장을 선택했습니다.
Model configuration
- FastSpeech model
FastSpeech model은 phoneme 쪽과 mel-spectrogram 쪽 모두 6개의 FFT block을 사용했습니다. phoneme vocabulary size는 문장 부호를 포함해 51입니다. phoneme embedding 차원, self-attention의 hidden size, FFT block에 있는 1D convolution 모두 384로 설정했습니다. attention head 수는 2로 설정했습니다. 2-layer convolutional network에 있는 1D convolution의 kernel size는 3으로 설정했으며, 첫 layer의 input size는 384, output size는 1536으로 설정했고, 두 번째 layer의 input size는 1536, output size는 384로 설정했습니다. output linear layer는 384차원 hidden을 80차원 mel-spectrogram으로 변환하도록 설정했습니다. duration predictor에서는 2-layer 1D convolution의 kernel size를 모두 3으로 설정했으며, input size는 384, output size는 384로 설정했습니다.
- Autoregressive Transformer TTS model
저자들의 연구에서 autoregressive Transformer TTS model은 2가지를 목적이 있습니다. 1) duration predictor를 학습하기 위해 phoneme duration을 target으로 추출해 줍니다. 2) sequence-level knowledge를 distil할 때 mel-spectrogram을 생성합니다. 저자들이 사용한 autoregressive transformer TTS model에 대해 알아보겠습니다. 이 model은 6-layer encoder와 6-layer decoder로 구성되며, 1D convolution network를 사용하도록 만들었습니다. 이 teacher model의 parameter 수는 FastSpeech model과 비슷합니다.
Training and Inference
먼저 autoregressive Transformer TTS model을 학습합니다. 학습된 model에 text, speech pair를 다시 feed하여 model은 encoder-decoder attention alignment를 만들며, 이는 duration predictor를 학습하기 위해 사용됩니다. 또한, non-autoregressive machine translation에서 좋은 성능을 달성한 sequence-level knowledge distillation을 사용하는데, teacher model이 student model로 knowledge를 전이하는 방식입니다. 각 source text sequence에 대해, 저자들은 autoregressive Transformer TTS model로 mel-spectrogram을 생성합니다. 그리고 source text와 생성된 mel-spectrogram을 paired data로 만들어 FastSpeech model을 학습하는 데 사용합니다.
저자들은 FastSpeeh model을 duration predictor와 같이 학습합니다. Inference 과정에서, FastSpeech의 output mel-spectrogram은 pretrained된 WaveGlow을 사용해 audio sample로 변환됩니다.
Results
Audio Quality
저자들은 test set으로 측정한 MOS로 audio quality를 평가했습니다. 다른 model 간에 text content는 일관되게 유지하여 다른 간섭 요소들을 배제했습니다. 이를 통해 오직 audio quality를 비교할 수 있었습니다. 각 audio는 적어도 20명에게 들려주었으며, 다들 native english speaker였습니다. 위 표에서 GT는 ground truth audio를 의미합니다. GT (Mel + WaveGlow)는 ground truth audio를 mel-spectrogram으로 변환한 후, WaveGlow를 활용해 다시 audio로 변환한 결과입니다. FastSpeech는 Transformer TTS model과 Tacotron 2와 비슷한 quality의 audio를 만들어낸다는 것을 볼 수 있습니다.
Inference Speedup
저자들은 FastSpeech의 inference latency를 FastSpeech와 비슷한 수의 parameter로 이루어진 autoregressive Transformer TTS model과 비교했습니다. mel-spectrogram을 생성하는 inference speed는 다음과 같습니다.
FastSpeech가 mel-spectrogram을 생성하는 속도는 Transformer TTS model보다 269.4배 더 빠른 것을 볼 수 있습니다. 그리고 WaveGlow를 vocoder로 사용하는 end-to-end 속도도 보였습니다. 이는 FastSpeech가 여전히 38.3배 더 빠른 것을 볼 수 있습니다.
Robustness
autoregressive model에서의 encoder-decoder attention mechanism은 phoneme과 mel-spectrogram 사이의 wrong attention alignment를 유발할 수도 있습니다. 결과적으로 단어를 반복하거나 단어를 생략하는 instability가 생깁니다. FastSpeech의 robustness를 평가하기 위해, 저자들은 TTS system이 다루기 힘든 50개의 sentence를 골랐습니다. word error가 발생하는 결과는 다음과 같습니다.
FastSpeech는 단어를 반복하거나 생략하는 문제를 효과적으로 제거했으며, intelligibility를 향상시켰습니다.
Length Control
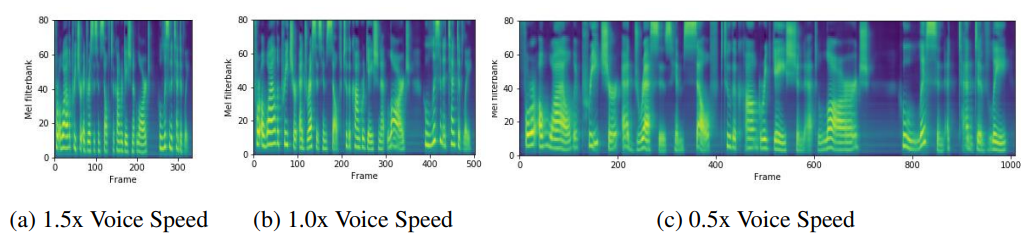
이전에 언급했듯이, FastSpeech는 voice speed를 조절할 뿐만 아니라 일부 prosody까지 조절할 수 있습니다. phoneme duration을 조절하여 해당 기능들을 수행할 수 있으며, 다른 end-to-end TTS system들은 할 수 없습니다. 저자들은 length control를 하기 이전과 control한 후의 mel-spectrogram을 보였습니다.
생성된 mel-spectrogram은 위와 같습니다. 이는 phoneme duration의 길이를 조절하여 voice speed를 조절한 모습입니다. voice speed를 조절해도 안정적이며 pitch가 변하지 않는 것을 볼 수 있습니다.
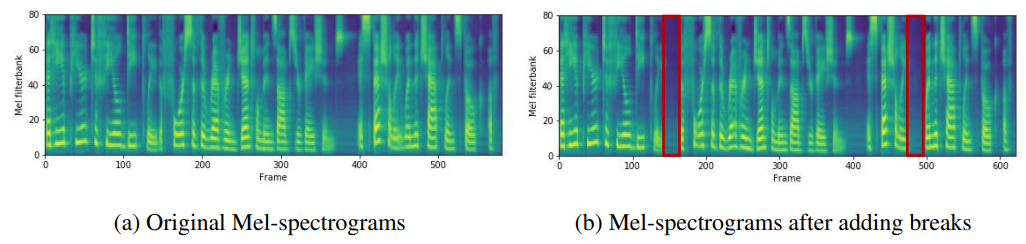
이번에는 단어 사이의 공백을 조절한 결과입니다. FastSpeech는 인접한 단어 사이의 공백 문자의 duration을 조절하여 공백을 추가할 수 있습니다. 이를 통해 voice의 운율을 조절할 수 있습니다.
Ablation Study
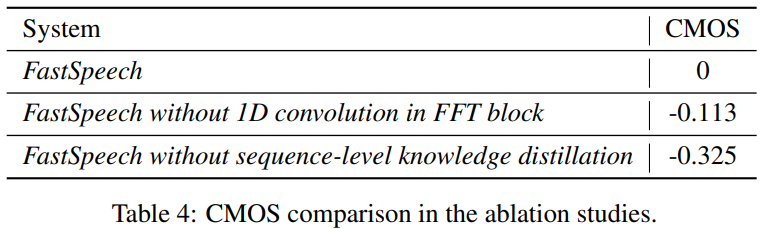
저자들은 FastSpeech의 component들의 효과를 입증하기 위해 ablation study를 진행했습니다. 1D convolutionn, sequence-level knowledge distillation에 대한 ablation study를 진행했습니다. 평가는 CMOS로 진행했습니다. CMOS는 두 개의 audio를 비교하여 상대적인 quality 차이를 측정하는 방식입니다.
먼저, 1D convolution 대신 original fully connected layer를 사용한 결과입니다. parameter 수는 비슷하게 설정하고 진행했습니다. 1D convolution을 fully connected layer로 대체하는 것은 -0.113 CMOS를 보였습니다. 즉, 1D convolution이 효과가 있다는 것을 의미합니다.
이번에는 sequence-level knowledge distillation에 대해 보겠습니다. sequence-level knowledge distillation을 제거했을 때, -0.325 CMOS가 나왔습니다. sequence-level knowledge distillation 또한 효과가 있다는 것을 보여주었습니다.
Conclusion
이 연구에서, 저자들은 FastSpeech를 제안했습니다. 빠르고 robust하며 controllable한 neural TTS system입니다. FastSpeech는 mel-spectrogram을 병렬적으로 생성하기 위해 feed-forward network를 사용했으며, feed-forward Transformer block, length regulator, duration predictor라는 key component를 포함하고 있습니다. LJSpeech dataset을 가지고 실험을 했으며, speech quality는 autoregressive Transformer TTS model과 유사했습니다. mel-spectrogram을 생성하는 속도는 FastSpeech가 270배 정도 빨랐으며 end-to-end speech synthesis를 했을 때는 38배 빨랐습니다. 그리고 FastSpeech는 단어를 생략하거나 반복하는 문제를 거의 해결했으며, voice speed도 자연스럽게 조절할 수 있습니다.