https://arxiv.org/abs/2006.03575
End-to-End Adversarial Text-to-Speech
Modern text-to-speech synthesis pipelines typically involve multiple processing stages, each of which is designed or learnt independently from the rest. In this work, we take on the challenging task of learning to synthesise speech from normalised text or
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
현대 text-to-speech synthesis pipline은 일반적으로 multiple processing stage를 포함합니다. 각 stage를 design 하거나 서로 독립적으로 학습합니다. 이 논문에는 end-to-end 방식으로 normalized text 또는 phoneme으로 speech를 합성하도록 학습하는 방식을 제안합니다. 결과적으로 model은 character나 phoneme을 input sequence으로 받아서 raw speech audio output을 생성합니다. 저자들이 제안한 generator는 feed-forward이며, training과 inference에서 효과적입니다. 그리고 token length prediction을 기반의 미분 가능한 alignment 방식을 사용합니다. 저자들의 model은 adversarial feedback과 prediction loss를 결합하여 high fidelity audio를 생성할 수 있습니다. 여기서 prediction loss는 생성된 audio가 ground truth의 total duration과 mel-spectrogram이 어느 정도 맞도록 만들어줍니다. model이 생성된 audio에서 시간적 variation을 capture할 수 있도록 만들기 위해, 저자들은 spectrogram 기반 prediction loss에서 soft dynamic time warping을 사용합니다. 저자들이 제안한 model은 multi-stage training을 사용하고 추가적인 supervision을 사용하는 model들과 비슷한 성능을 보입니다.
Introduction
TTS system은 natural language text를 input으로 받아서 사람이 말하는 것과 같은 speech를 생성하여 output합니다. 전통적인 TTS pipeline은 여러 개의 stage를 독립적으로 학습하거나 독립적으로 design합니다- e.g. text normalization, aligned linguistic featurisation, mel-spectrogrma synthesis, and raw audio waveform synthesis. 비록 이러한 pipeline들이 실제 같고 high-fidelity speech를 합성할 수 있으며 오늘날 널리 실용화되고 있지만, 이러한 module 방식은 여러 단점이 존재합니다. 각 stage마다 supervision을 필요로 하며, 때때로 각 단계의 output을 guide하기 위해 expensive한 실제 데이터의 annotation이 필요로 합니다. 추가적으로, end-to-end 방식 학습이 주는 reward를 사용하지 못합니다.
이 논문에서, 저자들은 TTS pipeline을 단순화하는 것에 초점을 두었으며, text 또는 phoneme을 speech로 합성하는 end-to-end 방식 model을 제안합니다. 저자들은 EATS (End-to-end Adversarial Text-to-Speech) generative model을 제안합니다. 이 model은 pure text 또는 raw phoneme (temporally unaligned)를 input sequence로 받아서 raw speech waveform을 output하는 adversarial하게 학습된 TTS model입니다. 이 model은 대부분의 최신 TTS engine에 존재하는 중간 bottleneck 현상을 제거하여 network 전반에 걸쳐 학습된 intermediate feature representation을 유지합니다.
저자들의 speech 합성 model은 2개의 high-level submodule로 구성됩니다. aligner는 raw input sequence를 처리하고 200Hz의 low-frequency aligned feature를 생성합니다. aligner를 통해 생성된 feature output은 전통적인 TTS pipeline의 earlier stage들을 대신할 수 있습니다. 예를 들어 시간적으로 algin된 mel-spectrogram이나 linguistic feature를 aligner가 생성한 feature로 대체할 수 있습니다. 이러한 feature는 decoder에 input되며, decoder는 1D convolution을 거쳐 24kHz audio waveform을 생성하도록 upsample됩니다.
aligner를 잘 design 하고 adversarial feedback과 domain-specific loss function을 잘 결합하여 training하여 TTS system이 end-to-end 방식으로 학습될 수 있음을 보입니다. 그리고 이러한 TTS system이 high-fidelity natural-sounding speech를 만들 수 있습니다. 저자들의 주요 contribution은 다음과 같습니다.
- 전체적으로 미분 가능하며 각 input token의 duration을 예측하는 효과적인 feed-forward aligner 구조를 제안했습니다. 그리고 이러한 구조는 audio-aligned representation을 생성합니다.
- model이 사람 speech의 time variability를 catpure할 수 있도록 input flexible dynamic time warping-based prediction loss를 사용합니다.
Method
저자들의 goal은 character/phoneme input sequence를 24kHz의 raw audio로 mapping하는 neural network (generator)를 학습하는 것입니다. input sequence의 length와 output signal의 length의 차이가 크다는 것 말고도, input과 output이 align하지 않다는 문제점이 존재합니다. 즉, 어떤 output token이 각 input token에 해달될 지 사전에 알 수 없습니다. 이러한 문제를 해결하기 위해, 저자들은 generator를 2가지 block으로 나눴습니다. 1) unaligned input sequence를 aligned representation output으로 mapping하는 aligner입니다. aligner가 생성한 representation output은 sample rate가 200Hz입니다. 2) decoder입니다. 이는 aligner의 output을 full audio frequency까지 upsample합니다.
전체 generator 구조는 미분 가능하며, end-to-end 방식으로 학습됩니다. 또한 이는 feed-forward convolutional network이며, batch 별로 inference 속도가 빨라야 하는 application에 적합합니다. 저자들의 model인 EATS는 single V100 GPU를 사용했을 때, speech를 realtime보다 200배 더 빠르게 생성합니다. 구조는 다음과 같습니다.

generator는 GAN-TTS에서 영감을 받아 구현했으며, GAN-TTS는 aligned linguistic feature를 이용해 연산하는 text-to-speech generative adversarial network입니다. 저자들은 GAN-TTS generator를 decoder로 사용했지만, 미리 계산된 linguistic feature를 upsampling하는 대신 input으로 aligner block을 사용했습니다. 저자들은 speaker embedding s과 latent vector z를 추가적으로 feeding하여 speaker를 condition으로 할 수 있도록 만들었습니다. 이를 통해 multi-speaker recording이 있는 대규모 dataset으로도 학습이 가능해집니다. 저자들은 multiple random window discriminator (RWDs)도 사용했습니다. RWD는 adversarial raw waveform modelling에서 효과적이라고 입증되었습니다. 그리고 저자들은 real audio input을 μ-law transform하여 전처리합니다. generator는 μ-law domain에서 audio를 생성하도록 학습되며, 생성된 audio는 다시 inverse되어 raw audio로 전환됩니다.
generator를 학습하기 위해 사용한 loss function은 다음과 같습니다.
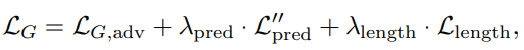
L_G,adv는 adversarial loss입니다. 이는 discriminator의 output에 linear한 adversarial loss로, discriminator loss로 hinge loss를 사용합니다. adversarial loss를 사용하는 것은 feed-forward training과 inference를 효과적으로 진행할 수 있도록 도와주며, text-to-speech와 같은 사실성이 중요한 design에서 더 사실적인 행동을 하는 경향성을 만들어줍니다. L_pred''는 보조 예측기를 의미하며, L_length는 length loss를 의미합니다.
Aligner
N 길이 token sequence x = (x_1, ... , x_N)가 주어졌을 때, token representation h = f(x, z, s)를 먼저 계산합니다. 여기서 f는 dilated convolution stack, batch normalization, ReLU로 구성됩니다. latent z와 speaker embedding s는 batch normalization layer의 scale, shift parameter를 조절합니다. 그다음 각 input token의 length를 예측합니다. l_n = g(h_n, z, s)를 사용해 예측하며, 여기서 g는 MLP입니다. ReLU를 사용해 output이 length이기 때문에 음수가 나오지 않도록 만듭니다. 저자들은 예측된 token의 끝 부분은 token 길이의 누적 합으로 찾을 수 있습니다. token length의 누적 합은 e_n = ∑ㅣ_m이며, 중심 위치에 존재하는 token은 c_n = e_n - l_n/2로 구할 수 있습니다. 이러한 예측된 위치를 기반으로, 저자들은 200Hz에서 audio와 정렬된 a = (a_1, ... , a_S)로 token representation을 보간할 수 있습니다. 여기서 S는 output time step의 total 수를 의미합니다. 즉 각 token representation들이 각 length를 구하고, 이 누적합을 구합니다. 해당 누적합을 이용해 각 token의 중앙 position을 구해, 200Hz까지 upsample하는 방식입니다. 이 결과는 audio와 align됩니다.
a_t를 계산하기 위해, 저자들은 t와 c_n 사이의 squared distance에 softmax를 적용하여 token representation h_n에 대한 보간 weight를 얻습니다. 해당 weight는 temperature parameter σ^2에 의해 scale되며 이를 10으로 설정해 사용했다고 합니다.
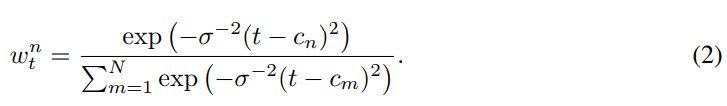
위 식과 같이 weight를 얻을 수 있습니다. 이 weight를 사용하여 저자들은 a_t를 구합니다.
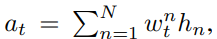
식으로 나타내면 위와 같습니다. position을 바로 예측하는 대신 token length를 예측하고 누적 합을 이용해 position을 얻음으로써, alignment의 단조성을 강제할 수 있습니다. dilated convolution의 stack f가 전체 token sequence에 걸쳐 information을 propagation할 수 있을 만큼 충분히 receptive field가 크기 때문에, 구두점과 같이 운율에 비단조적인 영향을 미치는 token도 전체 utterance에 영향을 줄 수 있습니다.
Windowed Generator Training
1초에서 20초까지의 다양한 length의 example을 가지고 학습합니다. 저자들은 training할 때 sequence를 maximal length까지 padding하지 않으며, 이를 통해 쓸데없는 연산을 줄일 수 있었습니다. 대신 저자들은 각 example에서 2초 window를 추출하여 사용합니다. 이를 저자들은 training window라 부릅니다. aligner는 각 window에서 200Hz audio-aligned representation을 생성하며, representation은 decoder로 input됩니다. time step t에 대해서만 a_t를 계산하면 되지만, 전체 input sequence에 대한 예측된 token length l_n은 계산해야 합니다. evaluation에서, 저자들은 전체 utterance에 대한 audio-aligned representation을 생성하고 decoder에 feed하여 model이 동작하게 만들었습니다. 이를 통해 fully convolutional하게 만들 수 있었습니다.
Adversarial Discriminator
- Random window discriminators
저자들은 random window discriminator (RWD)의 ensemble을 이용했습니다. 각 RWD는 서로 다른 length의 audio fragment에서 동작하며, fragment는 training window를 통해 ramdom하게 sample됩니다. 저자들은 5개의 RWD를 사용하며, 각 discriminator는 window size를 240, 480, 960, 1920, 3600으로 사용합니다. 각 RWD들은 서로 다른 해상도에서 연산을 진행합니다. 3600 samples의 경우, 150ms의 24kHz audio로부터 구해집니다. 그래서 모든 RWD는 짧은 timescale에서 연산됩니다. 저자들의 model에서 사용되는 모든 RWD는 text에 대해 uncondition합니다. 그 대신, projection embedding을 통해 speaker에 대해 condition합니다.
- Spectrogram discriminator
저자들은 spectrogram domain에서 동작하는 full training window 연산을 하는 추가적인 discriminator를 사용합니다. audio signal로부터 log-scaled mel-spectrogram을 추출하고 BigGAN-deep architecutr를 사용합니다. spectrogram discriminator는 projection embedding을 통해 speaker identity 또한 사용합니다.
Spectrogram Prediction Loss
예비 실험에서, 저자들은 adversarial feedback이 alignment를 학습하기에 충분하지 않다는 것을 알아냈습니다. training을 시작할 때, aligner는 정확한 alignment를 생성하지 못하기 때문에, input token의 information이 시간적으로 부정확하게 분포되게 됩니다. 이를 통해 decoder가 aligner의 output을 무시하게 됩니다. unconditional discriminator는 이를 조절할만한 learining signal을 제공해주지 못합니다. 만약 conditional discriminator를 대신 사용했다면, aligned ground truth가 없다는 문제에 직면하게 됩니다. conditional discriminator는 aligner module도 사용해야 하기 때문에, 학습 초기에 정확하게 동작하지 못하게 되며, 결국 unconditional discriminator로 전환됩니다. 이론적으로 discriminator의 aligner module을 adversarial하게 학습하는 것이 가능하지만, 저자들은 이 방식이 제대로 동작하지 못한다는 것을 알아냈으며, train이 정체되는 것을 발견했다고 합니다.
그래서 저자들은 spectrogram domain에서 prediction loss를 적용해 학습을 guide합니다. generator가 생성한 log-scaled mel-spectrogram과 그에 대응하는 ground-truth training-window 사이의 L1 loss를 minimize하도록 하는 방식입니다. 이는 train이 시작되는 데 도움이 되며, conditional discriminator가 불필요해지기 때문에 model이 간단해집니다. S_gen을 생성된 audio의 spectrogram이라고 하고, S_gt를 ground truth의 spectrogram이라 하겠습니다. 그리고 S[t, f]는 time step t에서 mel-frequency bin f의 log-scaled magnitude입니다. 이 경우 prediction loss는 다음과 같습니다.
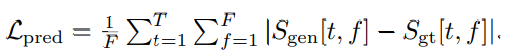
T는 총 time step의 수를 의미하고 F는 mel-frequency bin 수를 의미합니다. spectrogram domain에서 prediction loss를 계산하기 때문에, 생성된 signal과 ground truth signal 사이의 phase 차이에 대한 불변성이 증가한다는 장점이 있습니다.
adversarial feedback만 이용해 alignment를 학습하는 것이 어렵다는 사실에 대해 좀 더 이야기해 보겠습니다. likelihood 기반 autoregressive model은 alignment를 학습해야 한다는 issue가 없습니다. 왜냐하면, autoregressive model은 training할 때 teacher forcing을 하기 때문입니다. autoregressive model은 각 sequence step에서 다음 step을 예측하는 방식이며, 한번에 1개씩 infer합니다. 그러나, 이러한 방식은 feed-forward adversarial model에 적용할 수 없으며, prediction loss는 alignment를 학습하는 데 필수적이게 됩니다.
L_pred를 학습하기 위해 mel-spectrogram을 생성하지만, generator는 generation 과정에서 spectrogram을 생성하지 않습니다. generator의 output은 raw waveform이며, training할 때만, waveform을 spectrogram으로 변환하여 사용합니다.
Dynamic Time Warping
spectrogram prediction loss는 token length가 deterministic하다고 추정합니다(좋지 않음). 생성된 spectrogram과 ground truth spectrogram이 완벽하게 align해야만 spectrogram prediction loss를 사용할 수 있지만, 완전히 일치하지 않아도 괜찮게 만들기 위해 dynamic time warping (DTW)를 사용할 수 있습니다. 생성된 spectrogram S_gen과 target spectrogram S_gt 사이의 alignment path cost p가 minimal한 path를 반복적으로 찾아 prediction loss를 계산합니다. p_gen,1 = p_gt, 1 = 1 상태로 시작하며, 각 k번째 반복에서, 다음 3가지 action 중 하나를 합니다.
- S_gen, S_gt 모두 다음 time step으로 이동합니다: p_(gen,k+1) = p_(gen,k) + 1, p_(gt,k+1) = p_(gt,k) + 1
- S_gt만 다음 time step으로 이동합니다: p_(gen,k+1) = p_(gen,k), p_(gt,k+1) = p_(gt,k) + 1
- S_gen만 다음 time step으로 이동합니다: p_(gen,k+1) = p_(gen,k) + 1, p_(gt,k+1) = p_(gt,k)
최종 path p = <(p_(gen,1), p_(gt,1)), ... , (p_(gen,K_p), p_(gt,K_p))>가 됩니다. 여기서 K_p는 length입니다. 각 action은 S_gen[p_gen,k]와 S_gt[p_gt,k]의 L1 distance cost를 기반으로 선택되며, warp penalty w는 path가 같이 대각선으로 나아가지 않고 양옆이나 상하로 움직였을 때 penalty를 주는 역할을 합니다. 저자들은 w = 1.0으로 설정했습니다.

식은 위와 같습니다. 총 path cost가 위와 같이 정의될 수 있습니다. δ_k는 indicator를 의미하는데, warping이 발생하면 1이 되고 아니면 0이 되는 값입니다. 최종 DTW prediction loss는 다음과 같이 정의할 수 있습니다.

P는 모든 가능한 path들의 집합을 의미합니다. p∈P는 p_(gen,1) = p_(gt,1) = 1 그리고 p_(gen,K_p) = p_(gt, K_p) = T인 path들을 의미합니다. 즉 spectrogram의 처음과 마지막 timestep이 align한 path들을 의미합니다. minimum을 찾기 위해, 저자들은 dynamic programming을 사용합니다.

위 그림은 두 sequene 사이의 optimal alignment path를 보여줍니다. DTW는 미분 가능하지만, 모든 path에 대한 minimum을 찾는 것은 어렵습니다. 그래서 저자들은 soft version of DTW를 사용합니다. 이는 minimum을 soft minimum으로 대체한 DTW입니다.

soft version은 위와 같이 정의됩니다. 여기서 τ는 temperature parameter이며, 0.01로 두고 사용합니다. loss scale factor λ_pred = 1.0으로 두고 사용합니다. minimum operation은 τ = 0일 때 구해집니다. loss는 모든 path에 대해 cost를 구하고 weight를 적용하여 구해집니다. 그래서 모든 feasible한 path들은 gradient propagation이 가능해집니다. 이러한 구조는 trade-off 관계를 만들어냅니다. 큰 τ를 사용하면 optimization이 쉬워집니다. 하지만 결과적인 loss는 minimal path cost를 덜 정확하게 반영합니다.
prediction loss에서 alignment를 완화함으로써, generator는 정확하게 align하지 않는 waveform을 생성할 수 있으며, 이는 크게 penalty를 받지 않습니다. 이는 adversarial loss와 synergy를 만들어냅니다. adversarial이 확률적으로 aignment된 실제 같은 audio를 생성하도록 만들어줍니다. prediction loss는 full length utterance가 아니라 training window별로 계산되며, window의 시작점과 끝나는 지점은 정확하게 일치되야 하기는 합니다. 이 시작점과 끝점이 일치하지 않아도, 큰 문제가 되지 않는 것으로 보인다고 합니다.
Alignment length Loss
model이 실제같은 token length prediction을 할 수 있도록 하기 위해, 저자들은 예측된 utterance length가 ground truth length와 유사해지도록 만들 수 있는 loss를 추가했습니다. 총 length는 모든 token length prediction을 더해 정의됩니다. L을 training utterance의 time step 수로 정의하고, l_n을 n번째 oken이 예측한 length라고 하고, N을 token 수라고 할 때, 다음과 같이 loss를 정의할 수 있습니다.
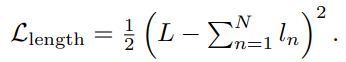
저자들은 scale factor λ_length = 0.1로 두고 사용했습니다. 각각의 predicted length l_n을 ground truth length와 맞추는 방식은 아닙니다.
Text Pre-processing
저자들의 model이 character input을 받아서도 잘 동작하지만, 저자들은 phoneme input을 받아서 sample quality를 더 향상시킬 수 있는 방법을 제안합니다. 숫자, 날짜, 측정 단위와 같은 다양한 도메인에서 많은 character sequence들은 특정한 발음을 가지고 있으며, 정확하게 발음하도록 하기 위해서는 매우 많은 training dataset이 필요합니다. text normalization은 이러한 sequence들을 일반적으로 발음되는 대로 철자를 풀어쓰게 할 수 있습니다(1976, nineteen seventy six). 그다음에 발음으로 변환이 이어질 수 있습니다. 저자들은 phonemizer라는 open source tool을 사용하여 정규화 및 발음화를 수행했습니다. 마지막으로, 저자들은 phoneme sequence로 학습하든 text sequence로 학습하든, special silence token을 sequence의 앞과 뒤에 붙였습니다. training과 inference 둘 다 이 방식을 적용했으며, 이를 통해 각 utterence의 시작과 끝에 존재하는 silence를 aligner가 고려하도록 만들었습니다.
Related work
음성 생성은 생성 modelling 방식으로 문제를 다루기 시작하면서 상당한 quality의 발전을 보였습니다. likelihood-based 방식들이 지배적이지만, GAN이 최근에는 중요한 진전을 이루고 있습니다. 대부분의 논문에서의 공통적인 점은 speech 생성 process를 여러 stage로 나눈다는 점입니다. mel-spectrogram과 같이 time aligned intermediate representation을 사용하여 task를 더 다루기 쉬운 subproblem들로 나눕니다. 대부분의 연구들은 spectrogram이나 vocoder에만 전념합니다. 저자들은 이러한 관점에서 다른 연구를 진행했습니다.
먼저, TTS에서 사용되는 대부분의 likelihood-based model들은 autoregressive합니다. 즉 생성된 output signal들의 연속적인 timestep 사이의 종속성이 있습니다. 이러한 autoregressive model들은 real-time에서는 실용적이지 않지만, 잘 modelling하면 real-time에서도 동작하도록 만들 수 있습니다. 더 최근에는, flow-based model들이 등장했습니다. 이는 feed-forward 방식이며 inference 속도가 빠릅니다. 이러한 model들은 maximum likelihood로 직접 학습되거나 autoregressive model을 이용해 distillation하여 학습됩니다. 앞에서 말한 model들 전부 intermediate representation을 condition으로 하여 waveform을 생성합니다. intermediate representation으로 spectrogram이나 linguistic feature를 사용하는 데, 둘 다 시간적으로 align되어 있으며 speech signal에 대한 high-level information입니다. spectrogram-conditioned waveform model은 vocoder로 불립니다.
GAN 변형을 음성 합성에 적용한 연구들이 증가하고 있습니다. Tacotron 1&2, Deep Voice 2&3, TransformerTTS, Flowtron, VoiceLoop들은 frame별로 spectrogram을 생성하거나 vocoder feature를 생성하는 autoregressive model입니다. Paranet과 FastSpeech는 non-autoregressive model이지만, autoregressive model을 이용한 distillation이 필요합니다. 최근에는 flow-based 방식인 Flow-TTS와 Glow-TTS들이 distillation가 필요 없는 feed-forward network를 사용하고 있습니다. 대부분의 spectrogram generation model들은 생성된 spectrogram에 맞춰 학습된 vocoder model을 필요로 하는데, 생성된 spectrogram이 완벽하지 않으며 vocoder가 이에 대한 해결책이 되기 때문입니다. 일부 연구에서는 spectrogram 생성 model과 함께 새로운 vocoder architecture를 제안하기도 합니다.
앞서 말했던 model들과 다르게, 저자들이 제안한 model은 single feed-forward neural network이며, end-to-end 방식으로 single stage로 학습됩니다. model은 character나 phoneme sequence가 input으로 주어졌을 때 waveform을 생성하며, 추가적인 supervision (추가적인 model을 통해 얻은 aligned linguistic feature나 teacher forcing 등을 의미합니다) 없이도 align을 학습할 수 있습니다. 학습 과정은 상당히 단순합니다. Char2wav는 end-to-end 방식을 finetuning 되지만, intermediate supervision을 위해 vocoder feature로 pre-training하는 stage가 필요합니다.
spectrogram prediction loss는 feed-forward audio prediction model에 광범위하게 사용되었습니다. 저자들은 spectrogram loss가 magnitude, log magnitude 및 phase 성분에 각각 적용되며, L1 loss를 spectrogram loss로 사용합니다. spectrogram에 dynamic time warping을 하는 것은 많은 speech recognition system에서 사용되었습니다. 그리고 TTS system을 평가할 때도 사용되어 왔습니다. 저자들은 soft version of DTW를 사용하여 시계열 model이 미분 가능하도록 만들었습니다. DTW와 관련 있는 Monotionic Alignment Search (MAS)는 text와 latent representation 사이에서 optimal alignment를 찾는 것을 목표로 하지만, 저자들은 spectrogram prediction loss term에서 부과되는 constraint를 완화하기 위해 DTW를 사용합니다. sequence alignment를 요구하는 task에서 단조성을 활용하는 여러 mechanism들이 제안되었으며, attention mechanism, loss function, search-based approach들이 등장했습니다. TTS에서 이러한 제약들을 통합하는 것은 긴 sequence의 generlization에 도움이 된다는 것으로 나타났습니다. 저자들은 interpolation mechanism을 활용하여 단조성을 통합하는데, 이는 recurrent방식이 아니기 때문에 연산량이 적습니다.
Evaluation
Multi-Speaker Dataset
Professional voice actor가 녹음하고 그에 대응하는 text가 있는 고퀄리티의 recording으로 모든 model들을 학습했습니다. data는 69명 남자와 여자 North American English speaker로 이루어지며, audio clip은 1초에서 20초 사이의 full sentence를 포함하고 있습니다. 각각의 voice들은 불균등하게 분포되어 있으며, 15분에서 51시간까지 다양하며 총 260.49시간의 recording입니다. 학습할 때, 저자들은 각 clip에 2초 window를 적용했으며, 2초보다 짧은 slience를 window 뒤에 padding했습니다. 평가할 때, 저자들은 dataset에서 가장 prolific한 single speaker를 사용했으며, speaker ID를 condition으로 하는 model의 MOS 뿐만 아니라, 저자들의 multi-speaker model을 이용해 4명의 speaker에 대한 MOS도 보여줍니다.
Results
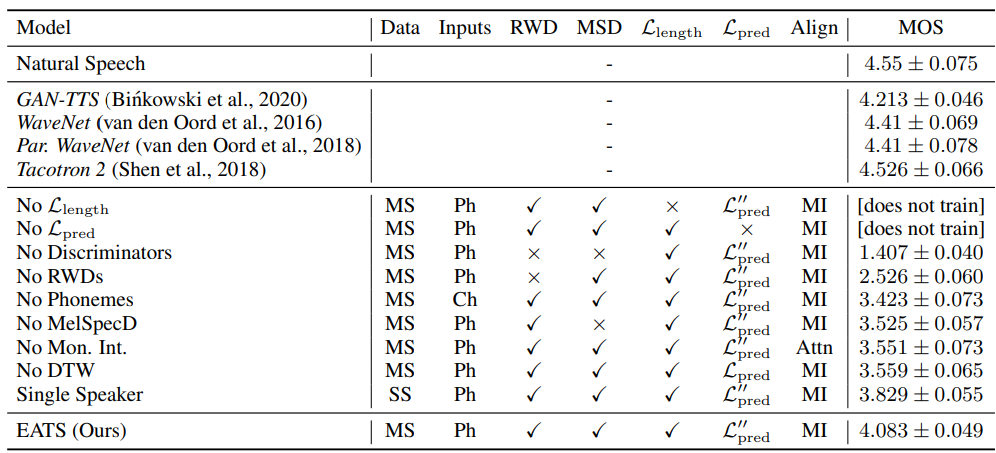
위 표는 저자들의 EATS model과 다른 model들의 ablation과 learning signal component를 보여줍니다. 각 ablation에 대한 architecture와 training setup은 ablation을 제외하고는 EATS와 동일합니다. 즉 각 ablation은 full EATS system에서 해당 feature를 빼는 형태라고 보시면 됩니다. 저자들이 제안한 multi-speaker model은 MOS가 4.083입니다. dataset이 다르기 때문에 다른 논문들에서 제시한 결과와 직접적인 비교를 하는 것은 어렵지만, 다른 model들은 MOS를 4.2~4.4 정도 보여줍니다. 이러한 aligned linguistic feature에 의존하는 이전 model들과 비교했을 때, EATS는 상당히 더 적은 supervision을 사용합니다.
No RWDs, No MelSpecD, No Discriminator ablation을 보겠습니다. 이 3가지 ablation 모두 MOS 결과가 상당히 떨어지며, adversarial feedback의 중요성을 입증하는 결과임을 의미합니다. 특히 No RWDs ablation의 경우, MOS는 2.526이며 raw audio feedback의 중요성을 보여주는 수치입니다. RWD를 제거하는 것은 high frequency component를 상당히 degrade시킵니다. No MelSpecD는 artifact, 왜곡을 야기하며, 모든 discriminator result를 제거하는 것은 audio가 기계음처럼 들리게 만듭니다. No L_length와 No L_pred ablation은 model의 학습이 잘 안 되는 것을 보여줍니다. NO DTW model의 결과를 보면, 시간적 flexibility가 dynamic time warping에 의해 상당히 향상된 fidelity를 제공하는 것을 볼 수 있습니다. DTW를 제거하면 자연스럽지 않은 phoneme length를 야기합니다. No Phoneme은 raw character input으로 학습되며, MOS 3.423을 얻습니다. No Phoneme은 잘못된 발음을 만들거나 자연스럽지 않은 pattern을 만들어냅니다. No Mon. Int.는 transformer 기반 attention mechanism을 aligner로 사용하는 방식입니다. 이는 긴 utterance에 대한 좋지 않은 generalization 성능을 보입니다. 마지막으로, Single Speaker입니다. speaker 1명에 대한 data만 가지고 학습한 EATS는 여러 speaker로 학습한 EATS에 비해 좋지 않은 결과를 보입니다.
aligner가 latent vector z를 이용하여 예측된 token length를 변화시키는 법을 학습합니다.

위 표는 저자들의 multi-speaker EATS로 얻은 추가적인 MOS 결과입니다. training data에서 가장 많은 data를 가진 4명의 speaker에 대한 MOS 결과입니다. 일반적으로 더 많은 training data와 함께 MOS가 향상되지만, correlation이 완벽한 것은 아닙니다.
Discussion
저자들은 normalized text나 phoneme이 speech audio와 pair한 weak supervisory signal을 사용해 학습할 수 있는 adversarial text-to-speech synthesis를 제안합니다. 저자들의 model에 의해 생성된 speech는 주어진 text와 일치하며, multi-stage training pipeline이나 추가적인 supervision이 있는 다른 model들과 비슷한 정도의 자연스러움을 보여줍니다. 저자들의 model은 autoregressive 방식이 아니며 teacher forcing도 사용하지 않습니다. 그렇기 때문에 inference할 때 병렬적으로 처리할 수 있으며 distillation을 하지 않기 때문에 복잡성을 줄일 수 있었습니다.
저자들이 제안한 model이 생성한 speech와 다른 최신 model이 생성한 speech의 fidelity의 차이가 여전히 있지만, 저자들은 end-to-end 방식이 앞으로 더 발전될 것이라고 생각합니다. end-to-end learning은 system이 많은 양의 training data의 이점을 완전히 사용할 수 있습니다. 그리고 다른 model들은 mel-spectrogram이나 aligned linguistic feature와 같은 intermediate representation을 최적화해야 하고 이는 학습에 있어 bottleneck이 되지만, end-to-end는 이러한 representation을 따로 최적화할 필요가 없습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Improving Medical Speech-to-Text Accuracy with Vision-Language Pre-training Model (0) | 2024.04.16 |
|---|---|
| [논문] Robust Speech Recognition via Large-Scale Weak Supervision (0) | 2024.04.14 |
| [논문] FastSpeech: Fast, Robust and Controllable Text to Speech (0) | 2024.04.05 |
| [논문] Char2Wav: End-to-End Speech Synthesis (0) | 2024.04.04 |
| [논문] TACOTRON: Towards End-to-End Speech Synthesis (0) | 2024.04.03 |



