https://openreview.net/forum?id=B1VWyySKx
Char2Wav: End-to-End Speech Synthesis
Unlike traditional models for speech synthesis, Char2Wav learns to produce audio directly from text.
openreview.net
해당 논문을 보고 작성했습니다.
Abstract
저자들은 end-to-end speech synthesis model인 Char2Wav을 제안합니다. Char2Wav는 2가지 component로 이루어집니다: 'reader' & 'neural vocoder'. reader는 encoder-decoder model with attention입니다. encoder는 text는 phoneme을 input으로 받는 bidirectional recurrent neural network입니다. decoder는 vocoder acoustic feature를 생성하는 RNN with attention입니다. neural vocoder는 중간 representation을 이용해 raw waveform을 생성하는 SampleRNN의 확장된 version입니다. 이전의 speech synthesis model과는 다르게, Char2Wav는 text로부터 바로 audio를 생성합니다.
Introduction
speech synthesis에서의 주된 task는 text를 audio signal로 mapping하는 것입니다. 이해도가 높고 자연스러운 음성을 합성하는 것이 목표입니다. 여기서 이해도(intelligibility)는 합성된 audio의 명확성을 의미하며, 특히 청자가 original message를 얼마나 잘 알아듣는지에 대한 것입니다. 자연스러움(naturalness)는 청취의 전반적인 용이성, 전역적인 style 일관성 등을 포함하는 정보를 의미합니다.
전통적인 speech synthesis 방식에서는 이를 2가지 단계(frontend, backend)로 나누어 진행했습니다. frontend는 text를 lingustic feature로 변환하는 과정을 의미합니다. 이러한 linguistic feature는 주로 음소, 음절, 단어, 구절, 발화 수준의 feature를 포함합니다. backend는 frontend에서 생성된 linguistic feature를 input으로 받아, 그에 대응하는 sound를 생성하는 과정입니다.
좋은 linguistic feature를 정의하는 것은 종종 시간이 많이 걸리고 언어마다 다릅니다. 이 논문에서, 저자들은 frontend와 backend를 통합하며, 이 전체 과정을 end-to-end 방식으로 학습하는 model을 제안합니다. 이를 통해 전문적인 언어적 지식의 필요성을 제거할 수 있습니다.
Model Description
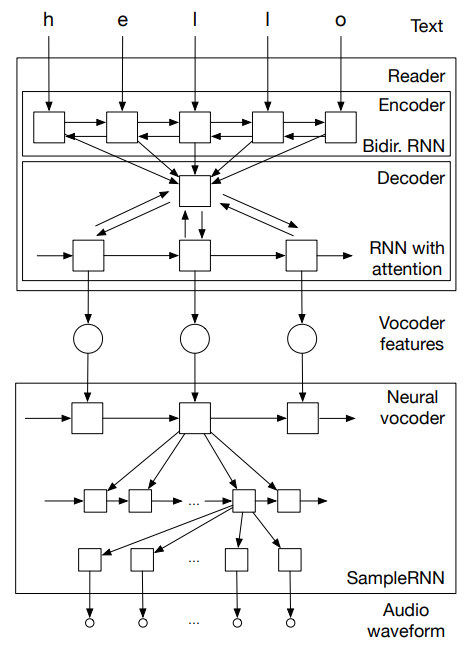
Reader
attention-based recurrent sequence generator (ARSG)는 input sequence X를 condition으로 하여 sequence Y = (y_1, ... , y_T)를 생성합니다. encoder는 X를 input으로 받아 sequence h = (h_1, ... , h_L)를 출력합니다. output Y는 sequence of acoustic feature이며, X는 생성된 text 이거나 phoneme sequence입니다. 그리고 encoder는 bidirectional recurrent network입니다.
i번째 step에서 ARSG는 h를 focus하며 y_i를 generate합니다.
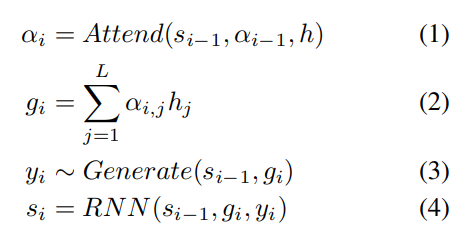
여기서 s_(i-1)는 generator의 i-1번째 recurrent neural network를 의미합니다. α_i ∈R^L은 attention weight 또는 alignment를 의미합니다.
저자들은 location-based attention mechanism을 사용합니다. location-based attention mechanism을 통해, decoder가 생성하는 output이 어떤 h를 focus 해야 하는지를 구할 수 있습니다. 그래서 α_i를 구하는 attention은 아래와 같이 구현됩니다.
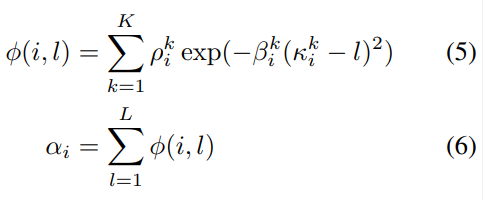
여기서 L은 h의 length를 의미합니다. κ_i는 location, β_i는 width, ρ_i는 window의 importance를 나타냅니다.
결국 location-based attention mechanism을 활용해 각 output을 구할 때 h의 어느 부분을 focus 해야 할지 구합니다.
Neural vocoder
음성을 생성할 때 vocoder는 매우 중요합니다. vocoder에 따라 합성된 음성의 quality가 달라집니다. high quality speech를 위해, 저자들은 SampleRNN을 사용했습니다.
SampleRNN은 audio signal과 같은 sequential data의 long-term dependencies를 model할 수 있습니다. SampleRNN의 계층적 구조는 다른 time scale을 갖는 다양한 sequence를 capture하도록 design되었습니다. 원래 SampleRNN을 확장하여 vocoder feature sequence를 condition으로 하여 audio sample을 mapping하도록 만들었습니다. 각 vocoder feature frame은 model의 top tier에 추가적인 input으로 추가됩니다. 이를 통해 이전 audio sample과 vocoder feature frame을 이용해 현재 audio sample을 생성할 수 있게 되었습니다.
Training Details
저자들은 reader와 neural vocoder를 분리해서 pretrain했습니다. normalized WORLD vocoder feature를 reader의 target output으로 사용했습니다. 그리고 normalized WORLD vocoder feature를 neural vocoder의 input으로 사용했습니다. 마지막으로, 저자들은 전체 model을 end-to-end method로 finetune했습니다.
Results
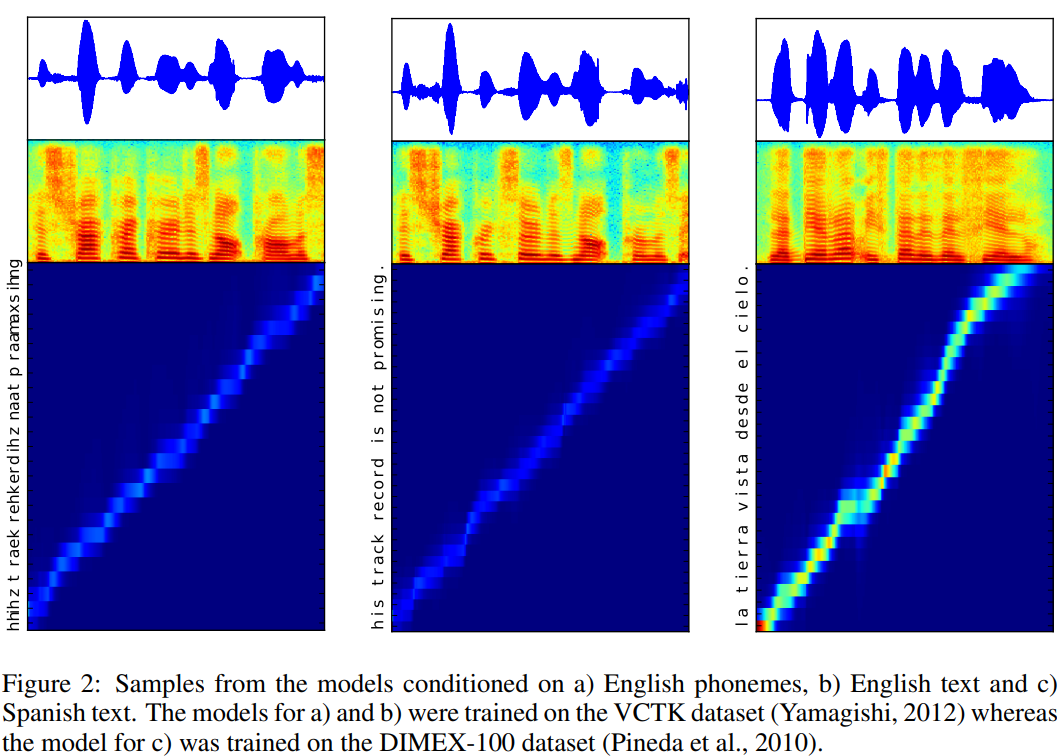
위 그림을 통해, 저자들의 model이 (text, frame) alignment가 좋은 것을 볼 수 있습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] End-to-End Adversarial Text-to-Speech (0) | 2024.04.08 |
|---|---|
| [논문] FastSpeech: Fast, Robust and Controllable Text to Speech (0) | 2024.04.05 |
| [논문] TACOTRON: Towards End-to-End Speech Synthesis (0) | 2024.04.03 |
| Text-to-Speech (TTS) 정리 (0) | 2024.04.01 |
| [논문] BW-EDA-EEND: Streaming End-to-End Neural Speaker Diarization for a Variable Number of Speakers (0) | 2024.03.26 |



