STT는 발화된 대화를 text로 변환하는 기능을 제공하는 반면, TTS는 쓰어진 text를 natural-sounding speech로 생성할 수 있습니다.
STT와 TTS 인식 기술은 사람들이 computer 및 digital device와 interact하는 방식을 변화시켰습니다. TTS와 STT는 번역 서비스, 가상 비서 등 다양한 domain에서 사용되고 있습니다. STT와 TTS 인식 기술의 발전은 대규모 dataset, deep learning 기술 발전, computational power 향상 덕분에 이루어졌으며, system의 정확성, 자연스러움, 사용성이 크게 증가되었습니다.
Text-to-Speech Conversion
Text-to-Speech (TTS) 인식, 또는 speech synthesis로 알려진 이 분야는 쓰어진 text를 natural sounding speech로 변환하는 데 중점을 둡니다. TTS 기술도 deep learning, neural network, natural language processing의 발전을 통해 최근 몇 년 동안 많은 발전이 있었습니다. Text-to-Speech 인식 기술은 다음과 같이 나눌 수 있습니다.
- Concatenative TTS: concatenative TTS는 human speech를 사전 녹음한 다음, phoneme이나 diphone과 같은 작은 음성 단위를 연결하여 합성된 음성을 생성하는 전통적인 방식입니다. 이는 고품질이며 자연스러운 speech를 생성할 수 있다고 알려져 있지만, 많은 양의 녹음된 speech data가 필요하며 음조, 음높이, 운율의 변화를 가진 speech를 생성하는 능력에는 한계가 있습니다.
- Formant Synthesis: formant 합성은 또 다른 전통적인 방식입니다. 이는 성대를 modelling하고 formant frequency를 조작하여 음성을 생성하는 방식입니다. 이러한 방식은 음높이, 운율, 음색에 대해 더 잘 다룰 수 있지만, 자연스러움과 현실감이 부족한 결과를 생성하기도 합니다.
- Articulatory Synthesis: 조음 합성은 혀, 입술, 턱과 같은 음성 기관의 움직임을 modelling하여 speech를 생성하는 발전된 방식입니다. 이는 더 자연스럽고 현실감 있는 speech를 생성할 수 있지만 복잡하며 연산량이 많이 필요하다는 단점이 있습니다.
- Statistical Parametric Synthesis: concatenative TTS의 단점을 해결하기 위해, statistical parametric speech synthesis (SPSS)가 제안되었습니다. 기본 idea는 speech를 직접적으로 바로 생성하는 것이 아니라, 먼저 음성을 생성하는 데 필수적인 acoustic parameter를 생성합니다. 그 다음 몇몇 algorithm들을 사용해 생성된 acoustic parameter들로 speech를 복원하는 방식입니다. SPSS는 주로 3가지 요소로 구성됩니다. text analysis module, parameter prediction module (acoustic model), vocoder analysis/synthesis module (vocoder)입니다. text analysis module은 text normalization, grapheme-to-phoneme conversion, word segmentation 등 다양한 방식으로 text를 처리합니다. 그다음 phoneme, duration, POS tag와 같은 linguistic feature를 추출합니다. acoustic model (e.g., hidden Markov model (HMM) based)들은 linguistc feature와 parameter (acoustic feature) 쌍을 이용해 학습되며, 여기서 acoustic features는 fundamentaal frequency, spectrum, cepstrum 등을 포함합니다. 여기에 사용되는 parameter (acoustic feature)는 vocoder analysis를 통해 추출됩니다. vocoder는 예측된 acoustic feature를 이용해 speech를 합성합니다. SPSS는 이전의 TTS system들보다 몇 가지 장점이 존재합니다. 1) audio가 더 자연스럽습니다. 2) speech 생성을 control하기 위해 parameter만 수정하면 되며 편리합니다. 그래서 flexible 하다는 장점이 있습니다. 3) concatenative synthesis보다 더 적은 수의 data만 사용합니다. 하지만 이러한 SPSS에도 단점이 존재합니다. 1) 생성된 speech의 이해도가 낮습니다. 음성이 뭉개지거나 윙윙거리거나 소음이 섞인 audio와 같은 artifact가 존재하기 때문입니다. 2) 생성된 voice는 여전히 기계적으로 들리며 인간이 녹음한 speech와 쉽게 구분될 수 있습니다. 2010년대에 neural network와 deep learning이 발전하면서, deep neural network를 SPSS에 적용하기 시작했습니다.
- Deep Learning-based TTS: Deep learning-based TTS는 최근에 빠르게 발전하고 있는 방식입니다. RNN, CNN, transformer와 같은 neural network를 사용해 speech를 생성합니다. 이러한 model들은 많은 양의 data로부터 human speech의 pattern과 feature를 학습하며, 높은 정확도, 자연스러움, 표현력을 가지고 있는 speech를 생성할 수 있습니다. 최근 등장한 TTS system들은 deep learning 기반 TTS를 사용하는 것이 지배적입니다.
Key Components in TTS

최근 TTS system은 3가지 component로 구성됩니다: text analysis module, acoustic model, vocoder입니다.
text analysis module은 text sequence를 linguistic feature로 변환합니다. acoustic model은 linguistic feature를 이용해 acoustic feature를 생성합니다. vocoder는 acoustic feature를 이용해 waveform을 합성합니다.
3가지 component를 기준으로 분류한 TTS model들은 다음과 같습니다.
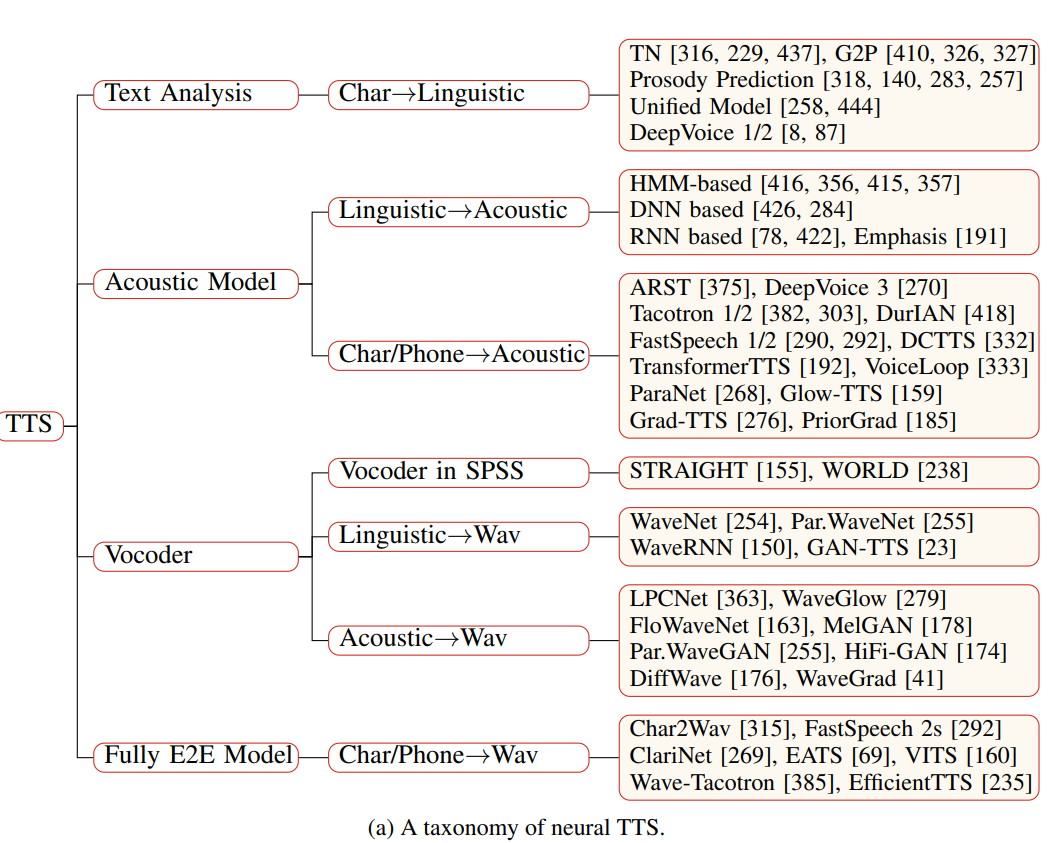
Main Taxonomy
저자들은 neural TTS를 text analysis, acoustic model, vocoder에 따라 분류하였으며, fully end-to-end model도 따로 분류하였습니다. 그리고 각 분류마다 text를 waveform으로 변환하는 data conversion flow에 따라 분류를 했습니다. 1) Text analysis는 character를 phoneme 또는 linguistic feature로 변환합니다. 2) acoustic model은 linguistic feature 또는 chracters/phoneme을 이용해 acoustic feature를 만들어 냅니다. 3) Vocoder는 lingustic feature 또는 acoustic feature를 이용해 waveform을 생성합니다. 4) Fully end-to-end model은 character/phoneme을 바로 waveform으로 변환합니다.
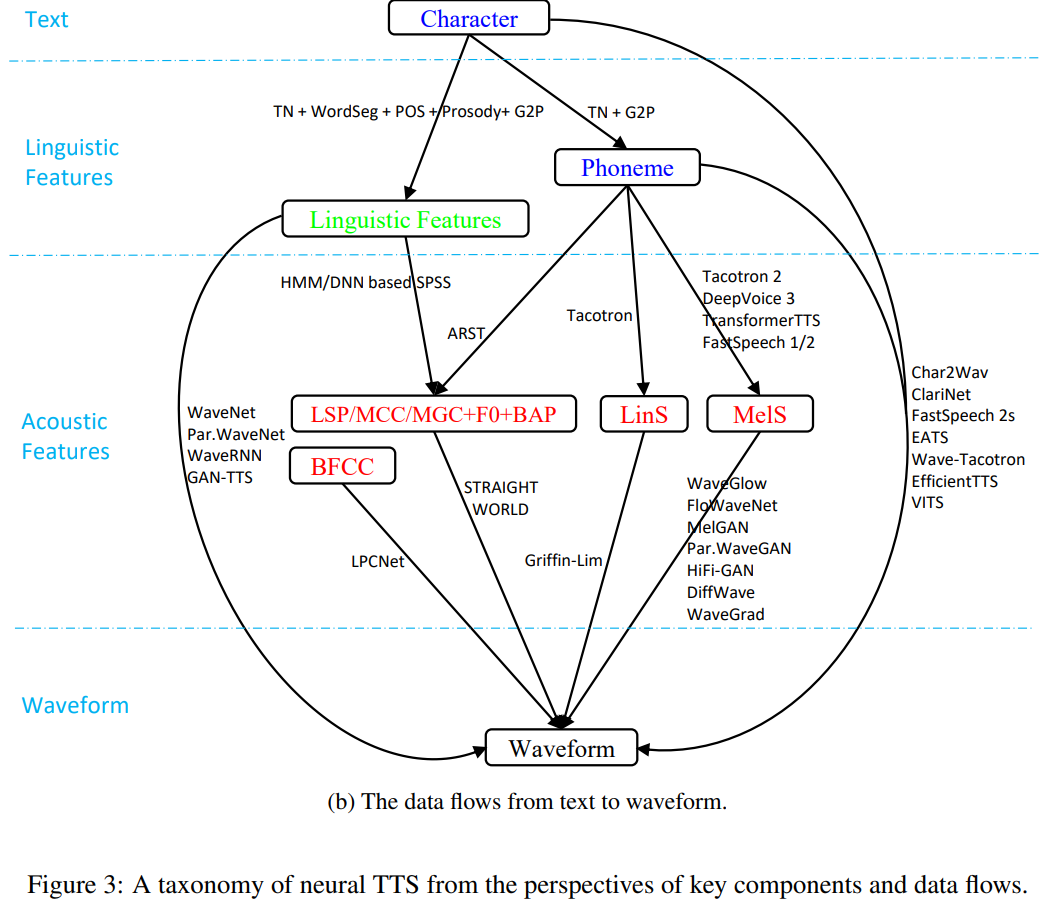
위 Fig 3(b)에서는 text를 speech로 변환하는 과정에서 사용되는 몇 가지의 data representation을 보여줍니다. 1) text의 raw format인 character가 있습니다. 2) text analysis를 통해 얻어지며, 발음과 운율에 대한 풍부한 context information을 포함하고 있는 linguistic features이 있습니다. 이는 주로 neural based TTS model에서 단독으로 text를 포현할 때 사용됩니다. 3) speech waveform의 추상적인 표현인 acoustic feature도 있습니다. statistical parametric speech synthesis, LSP (line spectral pairs), MCC (mel-cepstral coefficients), MGC (mel-generalized coefficients), F0, BAP (band aperiodicities) 들이 주로 acoustic feature로 사용되며 이는 STRAIGHT, WORLD와 같은 vocoder를 통해 쉽게 waveform으로 변환될 수 있습니다. neural based end-to-end TTS model은 mel-spectrogram이나 linear spectrogram을 주로 acoustic feature로 사용합니다. mel-spectrogram이나 linear spectrogram은 neural based vocoder를 이용해 waveform으로 변환됩니다. 4) speech의 final format인 waveform이 마지막으로 사용되는 representation입니다.
위 Fig 3(b)에서 볼 수 있듯이, text를 waveform으로 변환할 때 다양한 representation을 사용할 수 있습니다. 1) character → linguistic features → acoustic features → waveform 2) character → phoneme → acoustic features → waveform 3) character → linguistic features → waveform 4) character → phoneme → acoustic features → waveform 5) character → phoneme → waveform 6) character → waveform
이제부터는 TTS model의 3가지 주요 component들을 알아보겠습니다.
Text Analysis
TTS의 frontend라고도 불리는 text analysis는 input text를 음성 합성을 용이하게 하기 위해 발음, 운율에 대한 풍부한 정보를 포함하고 있는 linguistic feature로 변환합니다. statistic parametric syntehsis에서는 text analysis가 linguistc feature vector sequence를 추출합니다. 그리고 text analysis는 text normalization, word segmentation, part-of-speech (POS) tagging, prosody prediction, grapheme-to-phoneme conversion과 같은 다양한 기능들을 포함하고 있습니다. end-to-end neural TTS에서는 neural based model이 large capacity를 modeling할 수 있기 때문에, character 또는 phoneme sequence를 input으로 하여 바로 합성을 할 수 있습니다. 그렇기 때문에 end-to-end neural TTS는 text analysis module이 매우 간단해집니다. 이 같은 경우에, character input으로부터 standard word format을 얻기 위해 text normalization은 일반적으로 여전히 사용됩니다. 그리고 grapheme-to-phoneme 변환도 standard word format으로부터 phonemes을 얻기 위해 사용됩니다. 비록 몇몇 TTS model들은 text로부터 waveform을 바로 생성하는 fully end-to-end 합성을 할 수 있지만,
실제 사용을 위해 non-standard format인 raw text를 다루기 위해 text normalization은 여전히 사용됩니다. 그리고 몇몇 end-to-end TTS model은 conventional text analysis function을 통합하기도 합니다. 예를 들어 Char2Wav, DeepVoice 1/2들은 character를 lingustic feature로 변환하는 pipeline을 neural network로 구현하고, 일부 연구들은 text encoder로 prosody feature를 예측하기도 합니다. task analysis의 다양한 task들에 간단히 알아보겠습니다.
- Text normalization: raw written text (non-standard words)는 text normalization을 통해 spoken-form word로 변환되어야 합니다. 이렇게 spoken-form word로 변환해야 TTS model이 단어를 발음하기 쉬워집니다. 예를 들어 "1989년"의 경우 "nineteen eighty nin"으로 정규화되어야 하고, "Jan. 24"의 경우는 "January twenty-fourth"로 정규화됩니다. 초기 text normalization는 rule based였습니다. 그 이후에는 neural network가 사용되었습니다. neural network는 text normalization을 modelling하는데, 이는 non-standard word로 이루어진 source sequence를 spoken-form word로 이루어진 target sequence로 변환하는 task를 수행합니다. 최근 몇몇 연구들은 rule-based와 neural-based model의 장점들을 결합하여 text normalization 성능의 큰 발전을 이끌어냈습니다.
- Word segmentation: 중국어와 같은 character-based language의 경우, word segmentation은 raw text로부터 word boundary를 탐지하기 위해 필수적입니다. 이렇게 word segmentation을 해야지 POS tagging, prosody prediction, grapheme-to-phoneme conversion process의 정확도를 보장하는 데 도움이 됩니다.
- Part-of-speech tagging: 명사, 동사, 전치사 등 각 단어의 part-of-speech (POS, 품사)를 tagging하는 것도 TTS의 grapheme-to-phoneme conversion, prosody prediction에서 매우 중요합니다.
- Prosody prediction: 리듬, 스트레스, 억양과 같은 운율이라는 정보는 음절의 지속 시간, 소리 크기 및 음높이의 변화와 관련이 있으며 인간 음성 communication에서 중요한 지각적 역할을 합니다. 운율 예측은 각 운율을 tagging하는 system에 의존적입니다. 다른 언어들은 다른 운율 tagging system, tool을 가지고 있습니다. 영어의 경우, ToBI (tones and break indices)가 대표적인 tagging system입니다. 이는 tone에 대한 tag (e.g. pitch accent, phrase accent, boundary tones)와 break에 대한 tag (단어와 단어 사이의 분리 강도)를 사용해 설명하는 tagging system입니다. 예를 들어 "Mary went to the store?" 이라는 문장이 있을 때, "Mary"와 "store"는 강조되며, sentence는 tone이 올라가는 방식으로 발음됩니다. 많은 연구가 ToBI를 기반으로 prosody tag를 예측하기 위한 다양한 model과 feature를 조사했습니다. 중국어 speech 합성의 경우, 일반적인 prosody boundary label은 prosodic word (PW, 운율 단어), prosodic phrase (PPH, 운율 구), intonational phrase (IPH, 억양 구)를 포함하며, 이 세 계층 운율 tree를 구성할 수 있습니다. 몇몇 연구들은 중국어의 prosody preidction을 위해 CRF, RNN, self-attention과 같은 다른 model 구조들을 사용하기도 합니다.
- Grapheme-to-phoneme (G2P) conversion: character (grapheme)를 발음(phoneme)으로 변환하는 것은 speech synthesis를 매우 용이하게 만들어줍니다. 예를 들어, "speech"라는 단어를 "sp iy ch"와 같이 변환할 수 있습니다. 수작업으로 수집된 문자에서 음소로의 사전을 주로 변환에 사용합니다. 그러나 영어와 같은 alphabetic language의 경우, 사전이 모든 단어의 발음을 두룰 수 없습니다. 그렇기 때문에 영어에 대한 G2P conversion은 주로 사전에 없는 단어의 발음을 생성하는 것을 담당합니다. 중국어와 같은 언어의 경우, 사전이 거의 모든 character를 다루긴 하지만 문맥에 따라 결정될 수 있는 다의어가 있습니다. 그래서 이러한 종류의 언어들에 대한 G2P conversion은 주로 다의어를 명확하게 만드는 데 사용되며, 문맥에 따라 적절한 발음을 결정해줍니다.
위 text analysis를 한 이후에, linguistic feature를 만들고 TTS pipeline의 input으로 사용합니다 e.g., acoustic model의 SPSS or vocoder. 일반적으로 음소, 음절, 단어, 구, 문장 등 다양한 level에서 구한 text analysis의 결과를 집계하여 linguistic feature를 만듭니다.
이러한 text analysis가 음성 합성에 비해 덜 중요해 보이지만, 다양한 방식으로 neural TTS에 통합되어 사용되고 있습니다. text analysis를 통해 더 자연스러운 음성을 합성할 수 있도록 만들어줍니다.
Acoustic Models
acoustic model은 linguistic feature 또는 phoneme이나 character로부터 acoustic feature를 생성하는 model입니다. TTS의 발전으로, 초기 HMM, DNN 기반 model과 같은 다양한 종류의 acoustic model들이 statistical parameteric speech synthesis (SPSS)에 도입되었습니다. 그리고 그 이후에는 acoustic model로 encoder-attention-decoder framework 기반의 sequence-to-sequence model들이 등장했으며, 병렬적으로 acoustic feature를 생성할 수 있는 feed-forward network 들도 등장했습니다.
acoustic model은 vocoder를 사용하여 waveform으로 변환될 수 있는 acoustic feature를 생성하는 것이 목표입니다. acoustic feature의 선택은 TTS pipeline의 종류에 따라 결정됩니다. mel-cepstral coefficients (MCC), mel-generalized coefficients (MGC), band aperiodicity (BAP), fundamental frequency (F0), voiced/unvoiced (V/UV), bark-frequency cepstral coefficients (BFCC) 및 가장 널리 사용되는 mel-spectrogram들이 acoustic feature로 사용되어 왔습니다. 그래서 acoustic model을 두 시기로 나눌 수 있습니다. 1) SPSS에서의 acoustic model입니다. 이는 MGC, BAP, F0와 같은 acoustic feature를 linguistic feature로부터 예측하는 model입니다. 2) neural based end-to-end TTS에서의 acoustic model입니다. 이는 phoneme과 character로부터 mel-spectrogram과 같은 acoustic feature를 예측합니다.
- Acoustic models in SPSS
SPSS에서, HMM, DNN, RNN과 같은 statistical model들은 linguistic feature로부터 acoustic features (speech parameters)를 만들어내는 데 사용됩니다. 생성된 speech parameter들은 STRAIGHT, WORLD와 같은 vocoder를 통해 speech waveform으로 변환됩니다. 이러한 acoustic model은 몇 가지 고려 사항에 맞춰 발전되었습니다. 1) input으로부터 더 많은 context information을 갖도록 해야 합니다. 2) output frame과의 연관성을 modeling해야 합니다. 3) linguistic feature를 acoustic feature로 mapping이 one-to-many 관계이기 때문에 over-smoothing prediction problem을 해결해야 합니다. 이러한 고려 사항들을 해결하는 방식으로 acoustic model들이 발전되어 왔습니다.
HMM은 speech parameter를 생성할 때 사용되었는데, HMM의 observation vector는 mel cepstral coefficients (MCC)와 F0 같은 spectral parameter vector입니다. 이전 concatenative speech synthesis와 비교하였을 때, HMM기반 parameteric synthesis는 speaker identity, emotion, speaking style의 변화에 대해 더 flexible합니다. 이러한 HMM기반 SPSS는 합성된 speech의 quality가 만족할 정도가 아닌데, 원인으로 2가지 이유가 있습니다. 1) acoustic model의 정확도가 좋지 않고, 예측된 acoustic feature가 over-smoothing되고 detail이 부족하기 때문입니다. 2) vocoding 기술이 충분히 좋지 않기 때문입니다. 첫 번째 이유는 HMM의 modeling capacity가 부족하기 때문에 발생합니다. 그러므로, DNN기반 acoustic model들이 SPSS에 사용되었습니다. 이를 통해 HMM-기반 model들의 합성 quality를 향상시킬 수 있었습니다. 더 나아가, speech utterance의 long time span contextual effect를 잘 model하기 위해, LSTM기반 recurrent neural network가 사용되었습니다. 이를 통해 context dependency를 더 잘 modeling할 수 있게 되었습니다. deep learning의 발전에 따라, CBHG와 같은 몇 가지 발전된 network 구조들이 acoustic feature를 더 잘 예측하기 위해 사용되었습니다. VoiceLoop은 phonological loop라 불리는 working memory를 사용했는데, 이를 통해 phoneme sequence로부터 acoustic features (e.g., F0, MGC, BAP)를 생성했습니다. 그리고 난 후에 WORD vocoder를 사용해 acoustic feature로부터 waveform을 합성했습니다. 또 다른 연구에서는, acoustic feature의 quality를 향상시키기 위해 GAN을 사용했습니다. 그 이후에는 phoneme sequence로부터 acoustic feature를 직접적으로 생성하기 위해 attention기반 recurrent sequence transducer model을 이용하는 end-to-end에 대한 연구도 등장했습니다. 이러한 end-to-end model은 기존 neural network 기반 acoustic model은 frame별 정렬을 요구했었는데, 이를 피할 수 있게 되었습니다. SPSS에서 사용되는 acoustic model들은 다음과 같이 정리할 수 있습니다.
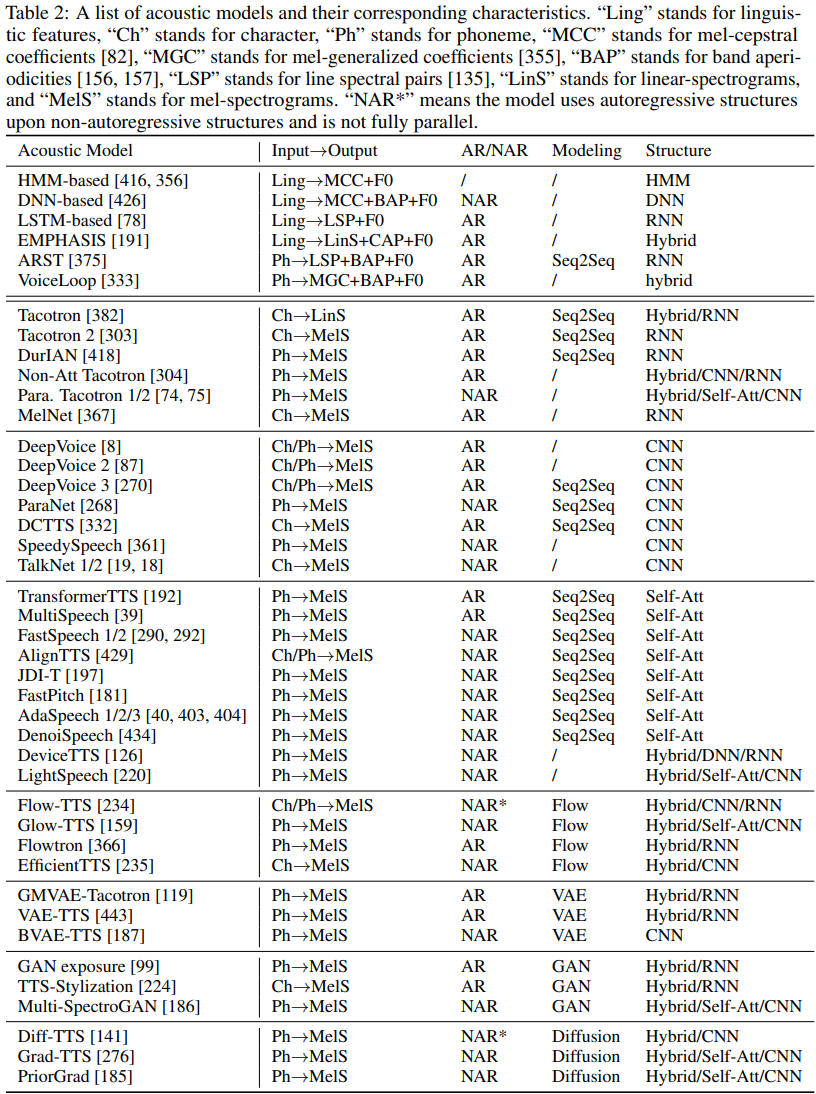
- Acoustic models in End-to-End TTS
neural based end-to-end TTS의 acoustic model은 SPSS에서 사용되는 acoustic model과 비교했을 때 몇 가지 장점이 있습니다. 1) 기본적인 acoustic model은 linguistic feature와 acoustic feature 간의 alignment을 필요로 합니다. 하지만 sequence to sequence 기반 neural modle은 attention을 통해 암시적으로 alignment를 학습하거나 duration을 함께 예측하여 더 end-to-end method 방식으로 볼 수 있으며 전처리 과정이 덜 필요합니다. 2) neural network의 modeling power가 증가됨에 따라, linguistic features는 character나 phoneme sequence로 단순화되었으며, acoustic features는 저차원의 밀집된 cepstrum (e.g., MGC)에서 고차원의 mel-spectrogram이나 더 고차원의 linear spectrogram으로 변화했습니다.
이제는 neural TTS에서 사용되는 몇 가지 대표적인 acoustic model들에 대해 보겠습니다.
- RNN-based Models (e.g., Tacotron Series)
Tacotron은 encoder-attention-decoder framework를 사용하며 character를 input으로 받아 linear-spectrogram을 output합니다. 그리고 Griffin-Lim algorithm을 사용해 waveform을 생성합니다. Tacotron 2는 mel-spectrogram을 생성하며 추가적인 WaveNet model을 사용하여 mel-spectrogram을 waveform으로 변환합니다. Tacotron 2는 이전의 방식인 concatenative TTS, parametric TTS, Tacotron과 같은 neural TTS들보다 더 좋은 quality의 voice를 생성합니다.
그 이후에 Tacotron의 다양한 부분들을 발전시키는 많은 연구가 등장했습니다. 1) speech 합성의 표현력을 향상시키기 위해 reference encoder와 style token을 사용하는 GST-Tacotron, Ref-Tacotron이 있습니다. 2) Tacotron에 있는 attention mechanism을 제거하는 대신 autoregressive prediciton을 이용하는 duration predictor를 사용하는 DurlAN과 Non-attentative Tacotron이 있습니다. 3) Tacotron에 사용되는 autoregressive generation 대신 non-autoregressive generation을 사용하는 Parallel Tacotron 1/2가 있습니다. 4) text를 waveform으로 변환시키는 Tacotron 기반 end-to-end model이 있습니다. 대표적으로 Wave-Tacotron이 있습니다.
- CNN-based Models (e.g., DeepVoice Series)
DeepVoice는 SPSS system에 convolutional neural network를 적용해 향상시킨 system입니다. neural network를 통해 linguistic feature를 얻은 다음, DeepVoice는 WaveNet 기반 vocoder를 사용해 waveform을 생성합니다. DeepVoice 2는 DeepVoice의 data conversion flow를 사용하지만, network 구조를 향상시키고 multi-speaker modeling도 가능한 system입니다. 그리고 DeepVoice2는 Tacotron + WaveNet model pipeline을 사용했습니다. Tacotron을 이용해 linear spectrogram을 만들고 WaveNet을 이용해 waveform을 생성합니다. DeepVoice 3는 음성 합성을 fully convolutional network structure로 수행합니다. character를 이용해 mel-spectrogram을 만들고, 이를 real-word multi-speaker dataset으로 scale up합니다. DeepVoice 3는 더 compact한 sequence-to-sequence model을 사용하고 복잡한 linguistic feature를 사용하는 대신 mel-spectrogram을 직접 prediction하는 방식으로 DeepVoice 1/2 system을 발전시켰습니다.
그 이후에 ClariNet은 fully end-to-end 방식으로 text로부터 waveform을 생성합니다. ParaNet은 fully convolutional based non-autoregressive model입니다. 이는 mel-spectrogram 생성 과정의 속도를 향상시키고 좋은 quality의 speech도 합성할 수 있습니다. DCTTS는 character sequence로부터 mel-spectrogram을 생성하기 위해 fully convolutional based encoder-attention-decoder network를 사용합니다. 그다음 mel-spectrogram을 linear spectrogram으로 복원하기 위해 super-resolution network를 사용하고 Griffin-Lim을 사용해 waveform을 합성합니다.
- Transformer-based Models (e.g., FastSpeech Series)
TransformerTTS는 Transformer기반 encoder-attention-decoder 구조입니다. 이는 phoneme으로부터 mel-spectrogram을 만들어냅니다. Tacotron 2와 같은 RNN 기반 encoder-attention-decoder model이 겪는 2가지 문제를 해결합니다. 문제는 다음과 같습니다. 1) recurrent의 특징 때문에, RNN 기반 encoder와 decoder는 병렬적으로 학습될 수 없습니다. 그리고 RNN 기반 encoder는 inference 또한 병렬적으로 진행할 수 없습니다. 즉 training과 inference의 효율성이 떨어집니다. 2) text와 speech sequence가 보통 매우 길기 때문에, RNN은 long dependency를 modeling하는데 적합하지 않습니다. TransformerTTS는 기초적인 Transformer model의 구조를 사용하면서 decoder pre-net/post-net, stop token prediction과 같은 Tactron 2로부터 몇 가지 구조를 가져와 사용했습니다. TransformerTTS는 Tacotron 2와 유사한 quality의 voice를 생성할 수 있지만 더 빠른 training time을 보여줍니다. 그러나 Tacotron과 같은 stable attention mechanism을 사용하는 RNN기반 model과 비교했을 때, Transformer의 encoder-decoder attention은 병렬적 연산 때문에 robust하지 않다는 단점이 있습니다. 그래서 Transformer-based acoustic model의 robustness를 향상시키기 위한 여러 연구들이 등장했습니다. 예를 들어, MultiSpeech는 encoder normalization, decoder bottleneck, diagonal attention constraint를 사용하여 attention mechanism의 robustness를 향상시켰습니다. 그리고 RobuTrans는 duration도 예측하여 agutoregressive generation의 robustness도 향상시켰습니다.
Tacotron 1/2, DeepVoice 3, TransformerTTS와 같은 이전 neural-based acoustic models은 autoregressive generation을 사용합니다. autoregressive generation은 몇 가지 문제점이 있습니다. 1) inference speed가 느립니다. autoregressive mel-spectrogram generation은 특히 speech sequence가 길수록 훨씬 느립니다. 2) Robust issue가 있습니다. 생성된 speech는 주로 많은 단어들이 skip 되고 반복되기도 하기 때문에 문제가 발생합니다. 이렇기 때문에 encoder-attention-decoder 기반 autoregressive generation에서 text와 mel-spectrogram의 attention alignment의 정확도가 떨어집니다. 이러한 문제를 해결하는 FastSpeech model이 등장했습니다. 이는 mel-spectrogram을 병렬적으로 생성하는 feed-forward transformer network입니다. 그렇기 때문에 inference speed가 빠릅니다. 그리고 이는 text와 speech에서의 attention mechanism을 제거했습니다. 그렇기 때문에 단어를 skip하거나 반복하는 문제를 피할 수 있으며, robustness를 향상시켰습니다. 대신에 length regulator를 사용해 phoneme과 mel-spectrogram sequence 사이의 length mismatch를 해결했습니다. length ragulator는 각 phoneme의 duration을 예측하기 위해 duration predictor를 사용했으며 phoneme을 phoneme duration에 해당하는 hidden sequence로 확장했습니다. 이를 통해 확장된 phoneme hidden sequence가 mel-spectrogram의 length와 match될 수 있으며 병렬적 처리가 가능해집니다. 그 이후에 다양한 version의 FastSpeech가 등장했으며, 많은 성능 발전을 이뤄냈습니다.
- Other Acoustic Models (e.g., Flow, GAN, VAE, Diffusion)
Flow-based model은 neural TTS에서 오랫동안 사용되어 왔습니다. vocoder로 Flow based model (e.g., Parallel WaveNet, WaveGlow, FloWaveNet)을 사용하여 성공적인 결과를 얻어낸 후에, flow-based model들은 acoustic model에도 사용되기 시작했습니다. 예를 들어 Flowtron의 경우, autoregressive flow-based mel-spectrogram generation model입니다. Flow-TTS와 Glow-TTS는 non-autoregressive mel-spectrogram generation을 위해 generative flow를 사용했습니다. flow-based model 말고도, 다른 생성 모델들이 acoustic model에 사용되었습니다. 예를 들어 GMVAE-Tacotron, VAE-TTS, BVAE-TTS는 VAE 기반 model이며, GAN exposure, TTS-Stylization, Multi-SpectroGAN은 GAN 기반 model입니다. 그리고 Diff-TTS, Grad-TTS, PriorGrad는 diffusion 기반 model입니다.
Vocoders
vocoder의 발전은 2가지 stage로 나눌 수 있습니다. statistical parametric speech synthesis (SPSS)에 사용되는 vocoder와 neural network-based vocoder로 나눌 수 있습니다. SPSS에서 사용되는 유명한 vocoder들은 STRAIGHT와 WORLD가 있습니다. 예를 들어 WORLD vocoder는 vocoder 분석과 vocoder 합성 step으로 구성되어 있습니다. vocoder 분석에서는, speech를 분석한 후 mel-cepstral coefficient, band aperiodicity, F0와 같은 acoustic feature를 구합니다. vocoder 합성에서는, acoustic feature를 이용해 speech waveform을 생성합니다.
WaveNet, Char2Wav, WaveRNN과 같은 초기 neural vocoder는 linguistic feature를 input으로 사용하여 waveform을 생성합니다. 그 이후 연구들은 mel-spectrogram을 input으로 사용하여 waveform을 생성합니다. speech waveform이 매우 길기 때문에, autoregressive waveform generation은 매우 긴 inference time이 걸립니다. 그래서 Flow, GAN, VAe, DDPM과 같은 generative model들이 waveform generation에서 사용되었습니다. 그래서 autoregressive vocoder, flow-based vocoder, gan-based vocoder, VAE-based vocoder, Diffusion-based vocoder로 나누어 볼 수 있습니다.
- Autoregressive Vocoders
WaveNet은 autoregressively하게 waveform point를 생성하기 위해 dilated convolution을 사용하는 첫 neural-based vocoder입니다. SPSS의 vocoder analysis와 synthesis와는 다르게, WaveNet은 audio signal에 대한 prior knowledge를 거의 사용하지 않고 end-to-end learning에 의존하는 방식입니다. WaveNet을 vocoder로 사용하는 model들이나 original WaveNet은 linguistic feature를 condition으로 하는 speech waveform을 생성합니다. 하지만 WaveNet은 linear-spectrogram과 mel-spectrogram에 condition을 두도록 쉽게 적응될 수 있습니다. WaveNet이 좋은 quality의 voice를 생성할 수 있지만, inference speed가 느립니다. 그래서 빠르고 경량화된 vocoder에 대한 연구들이 많이 등장했습니다.
- Flow-based Vocoders
Normalizing flow는 generative model의 종류 중 하나입니다. 이는 확률 밀도를 invertible mapping sequence로 변환하는 생성 model입니다. 변수 변환 규칙을 기반으로 하여 invertible mapping sequence로 standard/normalized 확률 밀도를 구할 수 있기 때문에, 이러한 종류의 flow-based generative model은 normaliziing flow라고 불립니다. sampling 과정에서, transform의 inverse를 통해 standard 확률 분포로 data를 생성합니다. neural TTS에서 사용되는 flow-based model은 2가지 카테고리로 나눌 수 있습니다. 1) autoregressive transform (e.g., Parallel WaveNet에서 사용되는 inverse autoregressive flow) 2) bipartite transforms (e.g., WaveGlow에서 사용되는 Glow, FloWaveNet에 사용되는 RealNVP)

autoregressive와 bipartite transform 둘 다 장점과 단점이 존재합니다. autoregressive transform은 bipartite transform에 비해 더 많은 표현을 할 수 있습니다. data distribution x와 표준 확률 밀도 z 사이의 의존성을 modeling하기 때문에 더 많은 표현을 할 수 있지만, train할 때 teacher model을 student model이 distill해야하는 복잡성이 존재합니다. Bipartite transform은 더 간단한 training pipeline을 사용하지만, 더 많은 parameter 수가 필요합니다.
두 transform의 이점을 결합하는 WaveFlow도 등장했습니다.
- GAN-based Vocoders
Generative adversarial networks (GANs)는 image generation, text generation, audio generation과 같은 data generation task에서 많이 사용되었습니다. GAN은 data를 생성하는 generator와 generated data의 확실성을 판단하는 discriminator로 구성됩니다. WaveGAN, GAN-TTS, MelGAN, Parallel WaveGAN, HiFi-GAN과 같이 많은 vocoder들은 audio 생성 quality를 보장하기 위해 GAN을 사용합니다. 요약하면 아래와 같습니다.
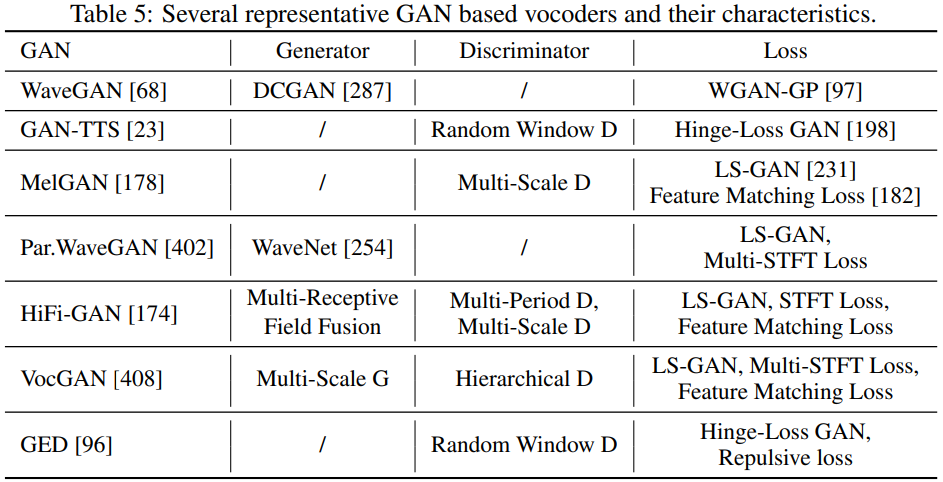
- Generator
대부분의 GAN-based vocoder들은 waveform sequence의 long-dependency를 modeling하기 위해 receptive field를 늘릴 수 있는 dilated convolution을 사용합니다. 그리고 condition information (e.g., linguistic features or mel-spectrograms)을 waveform sequence와 동일한 length가 되도록 upsampling하는 transposed convolution을 사용합니다. VocGAN의 경우, 다른 scale의 waveform sequence를 점진적으로 output할 수 있는 multi-scale generator를 제안합니다. HiFi-GAN의 경우, multi-receptive field fusion module을 통해 다양한 길이의 다른 pattern을 병렬적으로 처리합니다. 그리고 HiFi-GAN은 합성 효율성과 sample quality 사이의 trade-off에서 flexibility를 갖습니다.
- Discriminator
discriminator의 연구들은 waveform의 characteristic을 capture하는 modeling 방식에 대해 focus합니다. 이를 통해 generator에게 더 좋은 guide signal을 제공할 수 있습니다. 몇 가지 방식들에 대해 보겠습니다. 1) GAN-TTS에서 제안한 Random window disciriminator입니다. 이는 multiple discriminator를 사용하는데, 각 discriminator들은 서로 다른 random window를 waveform에 적용합니다. random window discriminator는 full audio를 이용한 true/false 판단과 비교했을 때, 더 간단하고 다양한 보원적인 방식으로 audio를 평가할 수 있습니다. 그리고 data augmentation의 효과를 더 증가시킬 수 있다는 장점이 있습니다. 2) MelGAN에서 제안된 Multi-scale discriminator는 다른 scale에서 audio를 평가하는 데 사용됩니다. multi-scale discriminator는 각 scale의 discriminator들이 서로 다른 frequency range에서의 characteristic을 focus할 수 있다는 장점이 있습니다. 3) HiFi-GAN에서 제안한 multi-period discriminator는 각각 주기를 가진 input audio의 균일하게 배치된 sample을 받아들이는 multi-discriminator를 사용합니다. 4) VocGAN에서 사용되는 Hierarchical discriminator는 다른 resolution의 generated waveform을 판별합니다. 이를 통해 generator가 acoustic feature를 low frequency waveform과 high frequency waveform 모두 mapping할 수 있도록 학습됩니다.
이 외에도 다양한 vocoder들이 존재합니다. 매우 간단하게 요약하면 다음 표와 같습니다.
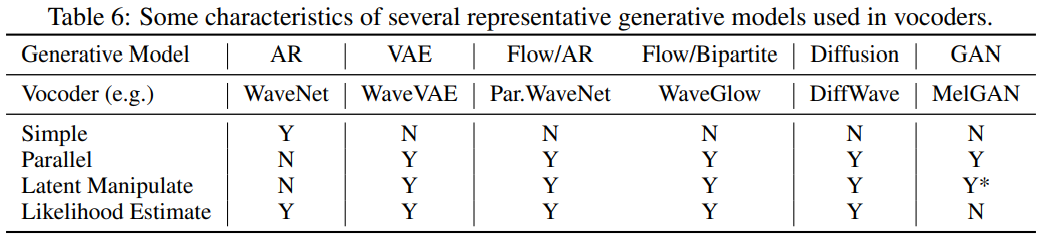
autoregressive (AR) based model은 VAE, Flow, Diffusion, GAN과 같은 다른 generative model에 비해 간단합니다. AR을 제외한 모든 generative model들은 speech 생성을 병렬적으로 할 수 있습니다. AR model을 제외했을 때, 모든 generative model들은 latent manipulation을 할 수 있습니다. 그리고 GAN-based model들은 data sample의 likelihood를 estimate할 수 없지만, 다른 model들은 할 수 있습니다.
Towards Fully End-to-End TTS
Fully end-to-end TTS model은 character 또는 phoneme sequence를 이용해 speech waveform을 바로 생성할 수 있습니다. 이는 다음과 같은 장점이 있습니다. 1) text와 speech 정렬 정보와 같은 human annotation과 feature development가 덜 필요합니다. 2) joint and end-to-end optimization은 연쇄 모델에서의 propagation error를 피할 수 있습니다 (e.g., text analysis + acoustic model + vocoder를 다 같이 사용한다면, 순차에 따른 propagation error가 발생할 수 있습니다). 3) 그리고 training, development, deployment cost를 줄일 수 있습니다.
그러나 TTS model을 end-to-end 방식으로 학습하는 것은 어려움이 있습니다. 주로 text와 speech waveform 사이의 다른 modality, 즉 character/phoneme sequence와 waveform sequence 사이의 length가 크게 mismatch하기 때문입니다. 예를 들어 5초 길이의 speech가 약 20개 단어가 있다면, phoneme sequence의 길이는 약 100 정도 됩니다. 하지만 waveform sequence의 length는 80k (sample rate가 16kHz인 경우)가 됩니다. waveform sequence의 length가 매우 길고 memory의 제한이 있기 때문에, model 학습을 할 때 전체 utterance의 waveform point를 사용하는 것이 어렵습니다. 만약 end-to-end training을 하기 위해 short audio clip을 사용한다면, context representation을 capture하는 것이 어렵습니다.
이러한 fully end-to-end training의 어려움 때문에, neural TTS은 점진적으로 fully end-to-end model을 향해 발전해 왔습니다.
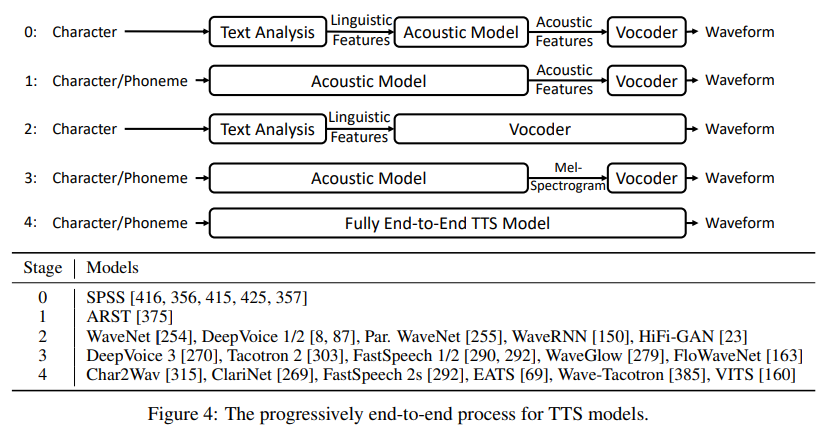
위 표를 통해 점진적인 발전 과정을 볼 수 있습니다. fully end-to-end model로의 과정은 일반적으로 몇 가지 upgrade를 포함합니다. 1) text analysis module과 linguistic feature를 간소화합니다. SPSS에서, text analysis module은 text normalization, phrase/word/syllable segmentation, POS tagging, prosody prediction, grapheme-to-phoneme conversion과 같은 다양한 function들을 포함합니다. end-to-end model은 character를 phoneme으로 변환하기 위해 text normalization과 grapheme-to-phoneme conversion만 사용하거나, character를 input으로 바로 사용하여 전체 text analysis module을 제거합니다. 2) acoustic feature를 간소화합니다. MGC, BAp, F0와 같이 SSPSS에서 사용되는 복잡한 acoustic feature들을 mel-spectrogram으로 단순화됩니다. 3) 2개 또는 3개 module을 single end-to-end model로 대체합니다. 예를 들어 acoustic model과 vocoder는 WaveNet과 같은 single vocoder model로 대체될 수 있습니다.
위 표의 stage들에 대해 간단히 알아보겠습니다.
- Stage 0. Statistic parametric synthesis는 3가지 basic module을 사용합니다. text analysis는 character를 linguistic feaeture로 변환합니다. acoustic model은 linguistic feature로 acoustic feature를 생성합니다. 그리고 vocoder는 acoustic feature를 이용해 speech waveform을 합성합니다.
- Stage 1. statistic parametric synthesis에서 text analysis와 acoustic model을 end-to-end acoustic model로 combine합니다. 이는 phoneme sequence를 acoustic feature로 직접 생성한 후, SPSS의 vocoder를 통해 waveform을 생성합니다.
- Stage 2. WaveNet은 linguistic feature를 통해 직접 speech waveform을 생성합니다. 이는 acoustic model과 vocoder를 결합한 형태로 볼 수 있습니다. 이러한 model들은 여전히 linguistic feature를 만드는 text analysis를 사용합니다.
- Stage 3. Tacotron은 linguistic feature와 acoustic feature를 간소화하여, encoder-attention-decoder model을 이용해 character/phoneme으로부터 linear-spectrogram을 직접 예측합니다. 그리고 Griffin-Lim을 사용해 linear-spectrogram을 waveform으로 변환합니다. DeepVoice 3, Tacotron 2, TransformerTTS, FastSpeech1/2과 같은 연구들은 character/phoneme으로 mel-spectrogram을 예측합니다. 그리고 WaveNet, WaveRNN, WaveGlow, FloWaveNet, Parallel WaveGAN과 같은 neural vocoder를 이용해 waveform을 생성합니다.
- Stage 4. 몇몇 fully end-to-end TTS model들은 text를 waveform으로 직접 합성하도록 개발되었습니다. Char2Wav은 RNN-based encoder-attention-decoder model을 사용해 character로부터 acoustic feature를 생성합니다. 그다음 SampleRNN을 이용해 waveform을 생성합니다. 이 2가지 model들은 speech 합성에서 동시에 직접 학습됩니다. ClariNet과 같이, autoregressive acoustic model과 non-autoregressive vocoder를 동시에 학습해 waveform을 생성합니다. FastSpeech 2s는 fully parallel structure를 이용해 text로부터 직접 speech를 생성합니다. 이를 통해 inference speed를 향상시켰습니다. text-to-waveform 학습의 어려움을 피하기 위해, phoneme sequence의 context representation을 학습하는 mel-spectrogram decoder를 사용합니다. EATS라 불리는 동시에 진행된 연구는 character/phoneme으로부터 직접 waveform을 생성합니다. EATS는 duration interpolation 및 soft dynamic time wrapping loss를 사용하여 end-to-end alignment learning을 합니다. Wave-Tacotron은 Tacotron에 기반한 flow-based decoder를 사용해 waveform을 직접 생성합니다. flow part에서 waveform을 병렬적으로 생성하지만, 여전히 Tacotron part에서는 autoregressive generation을 합니다(즉 병렬 처리가 불가능).
위에서 말한 model들 말고도 다양한 TTS model들이 존재하고 연구되고 있습니다.



