https://arxiv.org/abs/2005.09921
End-to-End Speaker Diarization for an Unknown Number of Speakers with Encoder-Decoder Based Attractors
End-to-end speaker diarization for an unknown number of speakers is addressed in this paper. Recently proposed end-to-end speaker diarization outperformed conventional clustering-based speaker diarization, but it has one drawback: it is less flexible in te
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
speaker 수를 알지 못하는 상황에서의 End-to-end speaker diarization을 해결할 수 있는 방식을 제안합니다. 최근에 제안된 end-to-end speaker diarization은 conventional clustering based speaker diarization보다 더 뛰어난 성능을 보였지만, 단점이 존재합니다. 이는 speaker 수에 대한 flexible이 부족합니다. 이 논문에서는 encoder-decoder based attractor calculation (EDA)를 제안합니다. speech embedding sequence를 이용해 flexible number of attractor를 생성합니다. 그다음 생성된 multiple attractors를 speech embedding sequence와 곱합니다. speech embedding sequence는 conventional self-attentive end-to-end neural speaker diarization (SA-EEND) network를 이용해 구해집니다. 저자들이 제안한 방식이 성능 향상을 이끌어냈습니다.
Introduction
Speaker diarization은 다양한 기술들의 등장으로 발전되어 왔습니다. EEND 중 하나인 self-attentive EEND (SA-EEND)는 convetional clustering 기반 방식들보다 더 좋은 성능을 보였습니다. SA-EEND는 speaker의 최대 수를 미리 정의해야 하며, speaker 수가 많다면 문제를 해결할 수 없습니다. 이렇기 때문에 EEND는 inference 중에 cluster 수를 설정하는 방식으로 speaker 수를 쉽게 변환할 수 있는 clustering based method보다 flexible이 떨어집니다.
이 논문은 EDA라 불리는 encoder-decoder 기반 attractor calculation method를 제안합니다. 이는 speech embedding sequence에서 이론적으로 attractor 수가 무한일 수 있는 flexible attractor 수를 결정합니다. 저자들은 SA-EEND를 이용해 구한 sepaker embedding과 attractor를 dot product하여 diarization result를 구합니다. 저자들은 실험을 통해 저자들이 제안한 방식이 speaker 수에 상관없이 simulated mixture와 real recording에서 좋은 성능을 보인다는 것을 보여줍니다.
Related work
speech separation을 할 수 있는 몇몇 방식들은 flexible speaker 수인 speech mixture도 처리할 수 있습니다. 대표적인 방식 중 하나는 'one vs rest' approach를 반복적으로 진행하여 수행합니다. 하지만, speaker 수가 증가함에 따라 연산 시간도 선형적으로 증가된다는 단점이 있습니다. 다른 방법은 Deep Attractor Network (DANet)을 포함하는 attractor 기반 방식입니다. 이는 inference 할 때 speaker 수의 제한이 없습니다. 하지만, speaker 수를 사전 지식으로 알아야만 합니다. Anchored DANet은 이러한 문제를 효과적으로 해결했습니다. 그러나 inference를 할 때 추출된 embedding과 모든 가능한 anchor 선택지들과 dot product를 해야만 합니다. 그래서 이는 speaker 수를 확장하는 데 용이하지 않습니다.
end-to-end 방식으로 embedding sequence를 계산하는 다양한 노력들도 존재했습니다. Transformer를 이용하는 방식이 등장했지만, 이는 output 수를 미리 정의해야만 사용가능하다는 문제점이 있습니다. 모든 가능한 cluster 수에 대한 분포를 추정하는 방식으로 end-to-end clustering도 등장했는데, 이 역시 최대 cluster 수가 미리 정의되어야만 사용가능하다는 단점이 존재합니다. 그 이후 encoder-decoder 기반 clustering도 등장했습니다. 그러나, network의 output은 각 input의 cluster 수 sequence이며, 각 time slot은 하나의 cluster로 할당되어야 합니다. 그렇기 때문에 이는 speaker overlap을 다룰 수 없습니다. 하지만, 저자들이 제안한 EDA는 cluster 수를 몰라도 embedding sequence를 이용해 attractor 수를 flexible하게 결정할 수 있습니다.
End-to-end neural diarization: Review
EEND model의 간략한 요약을 보겠습니다. EEND는 T 길이의 log-scaled Mel-filterbank기반 feature sequence를 input으로 사용합니다. 그리고 input을 BLSTM 방식으로 처리하거나 transformer encoder를 사용해 각 time slot에서 embedding을 얻어냅니다. 그 이후, D차원 embedding을 S 차원으로 선형 변환하고 각 element에 sigmoid function을 적용해 posterior를 얻어냅니다. 이를 통해 time slot t에서 speaker S의 posterior를 구할 수 있게 됩니다. EEND는 ground truth label과 calculated label을 이용한 loss를 통해 학습됩니다. 식은 다음과 같습니다.
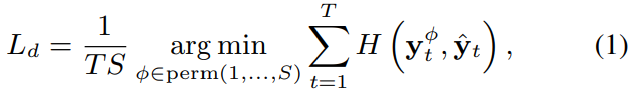
Proposed method
EEND의 output size는 network 구조에 따라 제한됩니다. inference할 때, linear transformation f는 speaker 수 S를 제약합니다. 그렇기 때문에, input mixture가 capacity보다 더 많은 speaker 수를 포함하고 있다면, EEND는 다룰 수 없게 됩니다. 그러므로, 저자들은 attractor-based method를 이용합니다. 저자들의 방식이 end-to-end 방식으로 학습 가능하게 만들기 위해서, 저자들은 embedding sequence에서 attractor를 결정할 수 있는 Encoder-Decoder based Attractor calculation (EDA)를 만들었습니다. 구조는 다음과 같습니다.
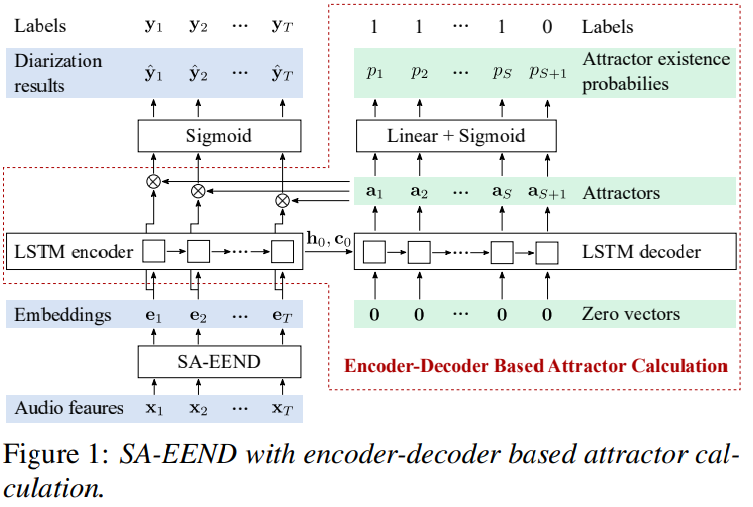
Encoder-decoder based attractor calculation
가변 길이의 embedding sequence로부터 flexible한 attractor point를 계산하기 위해, LSTM-based encoder-decoder를 사용합니다. D차원 embedding sequence를 unidirectional LSTM encoder에 feed합니다. 이를 통해 마지막 hidden state embedding h_0와 cell state c_0를 얻습니다.

그다음, initial states h_0와 c_0를 사용하는 unidirectional LSTM decoder를 이용해 D차원 attractors a_s를 구합니다.
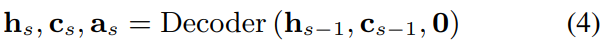
D차원 zero vector를 각 decoding step의 decoder input으로 사용합니다. 이론적으로, LSTM decoder를 사용하여 attractor 수의 제한 없이 계산할 수 있습니다. attractor 연산을 언제 멈출지 결정하기 위해 fully connected layer와 sigmoid function을 사용해 attractor a_s이 존재하는지 아닌지에 대한 확률을 계산합니다.
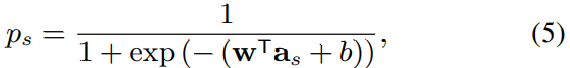
위 식에서 w와 b는 fully-connected layer의 학습 가능한 weight와 bias 입니다.
LSTM을 이용해 EDA를 구현했기 때문에, output attractors (a_s)_s의 순서는 input embedding 순서에 의해 정해집니다. input order의 영향을 확인하기 위해, 저자들은 embedding 순서를 두 가지 type으로 하여 실험을 진행했습니다. time slot index를 기준으로 embedding을 정렬하는 방식과, 순서를 shuffle하는 방식입니다.
학습을 할 때, 저자들은 ground-truth label l = [l_1, ... , l_(S+1)]^T를 정의했습니다. 여기서 S는 speaker 수를 의미합니다. 다음과 같이 표현할 수 있습니다.
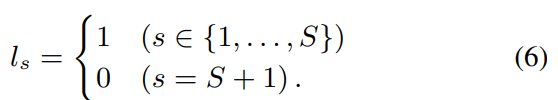
label과 추정된 probabilities p = [p_1, ... , p_(S+1)]^T는 다음과 같이 binary crsos entropy를 이용해 구해집니다.

inference를 할 때, speaker 수 S가 주어졌다면, 저자들은 EDA로부터 얻은 첫 S개의 attractor를 사용합니다. 만약 speaker 수를 알지 못한다면 다음 식을 이용해 S' 개의 attractor를 추정합니다.
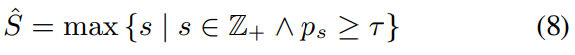
여기서 τ는 정의된 threshold입니다. 즉, threshold를 만족하는 s들 중에서 가장 큰 s를 찾아 해당 s를 S'로 설정하는 것입니다.
Speaker diarization using EDA
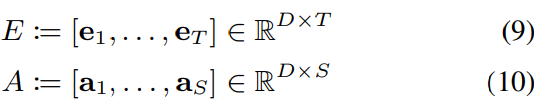
여기서 E는 SA-EEND를 통해 추출한 embedding matrix이고, A는 EDA를 통해 추출한 embedding matrix입니다. posterior 확률은 다음과 같이 내적을 통해 구해집니다. 즉 각 speaker의 attractor가 존재하고, 각 frame별로 해당 attractor를 내적하여 각 speaker가 frame마다 곱해지는 형태가 됩니다.
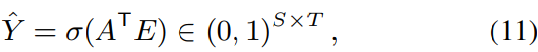
여기서 σ는 element-wise sigmoid function입니다. output size는 attractor 수에 의해 결정되며, 저자들의 method는 speaker 수가 flexible한 diarization result를 output할 수 있습니다. 마지막으로, diarization loss는 다음과 같은 식으로 똑같이 정의될 수 있습니다.
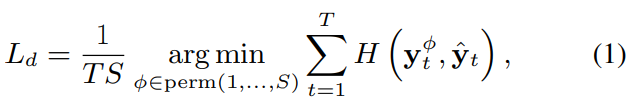
total loss는 diarization loss와 attractor loss의 합으로 구해집니다.

여기서 α는 weight parameter입니다. 저자들은 simulated data를 이용한 학습에서는 α을 1.0로 설정했으며, real data로 adaptation할 때는 0.01로 설정했습니다.
결국 LSTM decoder를 통해 attractor를 1개씩 구하고 probability를 구해 더 이상 attractor를 구할지 말지를 선택합니다. 이렇게 총 S* 개의 attractor를 구하여 embedding과 곱해 각 speaker의 activity frame을 구할 수 있습니다.
Experiments
Data
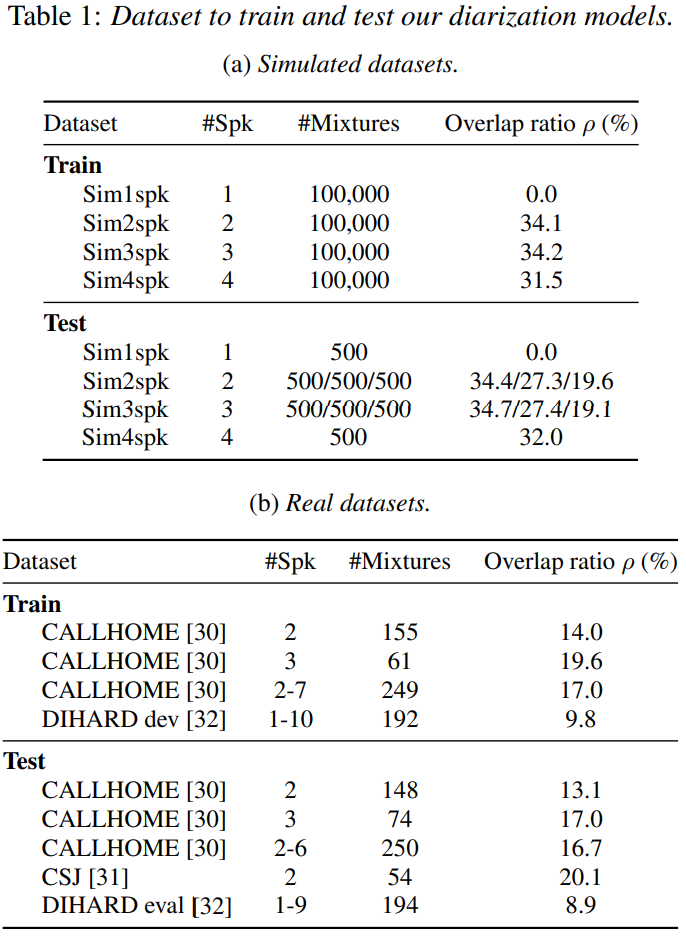
저자들은 학습과 평가를 위해, 생성한 simulated mixture와 real data를 이용합니다. training과 test dataset은 overlap된 data는 아닙니다. 그래서 저자들은 1, 3, 4 speaker dataset을 생성했습니다. detail한 data는 아래와 같습니다.
Experimental settings
저자들은 4개의 transformer를 stack한 encoder를 가지고 있는 SA-EEND를 baseline으로 사용했으며 저자들의 method의 backbone으로 사용했습니다. SA-EEND의 input은 345차원 log-scaled Mel-filterbank 기반 feature입니다. 저자들의 method에서는, SA-EEND의 마지막 layer에 normalization 한 후에 256차원 embedding sequence를 추출 추출했습니다. 이를 EDA에 feed하여 attractor를 구했습니다. 식 (8)에 등장하는 attractor가 존재하는지 안 하는지 결정하는 threshold τ를 0.5로 설정했습니다. 그리고 이 전에 말했듯이, 저자들은 2가지 input order (chronological & shuffle)를 사용하여 실험을 진행했습니다.
이 논문에서 저자들의 method를 2가지 condition ( 고정된 speaker 수와 flexible speaker 수)에 대해 실험을 진행했습니다. 고정된 speaker 수의 경우, 저자들은 Sim2spk with ρ = 34.1% 또는 Sim3spk with ρ = 34.2% 를 이용해 학습했습니다. 그다음 real recording에서의 성능도 평가하기 위해 CALLHOME data을 이용해 finetune 했습니다. 비교를 위해, 저자들은 i-vector 또는 x-vector를 이용하여 agglomerative hierarchical clustering하고 PLDA scoring을 한 model을 사용했습니다. TDNN 기반 speech activity detection과 oracle number of speakers을 이용해 평가를 진행했습니다. 저자들은 flexible speaker condition에서의 실험을 하기 위해, Sim2spk로 학습된 2-speaker model을 Sim1spk, Sim2spk, Sim3spk, Sim4spk를 concatenate한 data로 finetune했습니다. real dataset에서의 성능을 확인하기 위해서 CALLHOME 또는 DIHARD dataset을 이용해 model을 finetune하기도 했습니다.
Results on a fixed number of speakers
먼저, 2-speaker condition에서의 제안한 method를 평가하겠습니다. 결과는 다음 표와 같습니다.

가장 좋은 결과는 shuffled order의 EDA를 사용한 SA-EEND입니다. 그다음 3-speaker condition에서의 성능을 보겠습니다.

이 역시 shuffled order EDA를 사용하는 SA-EEND가 가장 좋은 성능을 보여줍니다.
- Effect of the input order
EDA를 더 잘 이해하기 위해, 저자들은 chronologically ordered sequence와 shuffled sequence에 대한 diarization performance를 비교했습니다. 그리고 저자들은 sequence의 length를 줄이기 위해 embedding을 subsample로 나누기도 했습니다. 위 표에서 본 것과 같이, chronological order가 shuffled order보다 약간 안 좋은 결과를 보여줍니다. subsampling을 했을 때는, chronological order가 상당히 성능이 감소됩니다. shuffled embedding을 이용해 학습된 EDA는, embedding의 순서나 subsample에 대한 의존성이 줄어들어 덜 영향을 받게 된다고 합니다. 즉 shuffled order를 이용한 EDA가 전체 sequence를 더 잘 capture 할 수 있습니다.
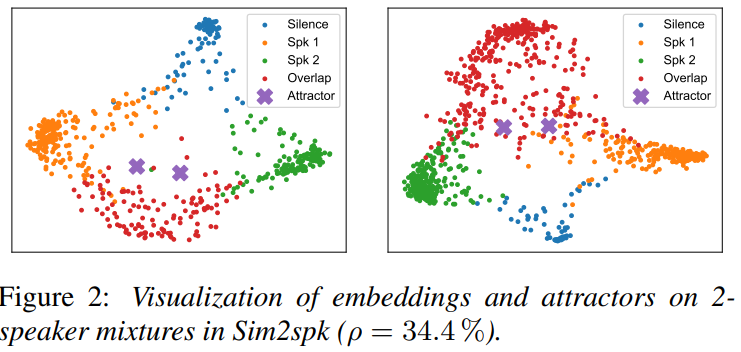
위 그림은 2-speaker mixture에 대한 embedding과 attractor에 PCA를 적용해 차원을 감소시킨 모습입니다. 확실히 speaker들의 embedding이 silent region과 잘 분리된 것을 볼 수 있고 overlapping region도 두 cluster와 분리되어 있는 것을 볼 수 있습니다. attractor는 두 speaker에 대해 성공적으로 연산된 모습을 볼 수 있습니다.
Results on a flexible number of speakers
저자들은 flexible speaker 수에 대해서도 실험을 진행했습니다. 이 경우, embedding 순서는 shuffle로 하여 진행했습니다. model은 먼저 Sim2spk dataset을 이용해 학습된 weight를 finetune했습니다. 그다음 fexible speaker 수인 simulated mixture에 대해 평가했습니다.

결과는 위와 같습니다. 저자들의 method는 x-vector clustering 기반 method보다 더 좋은 DER을 보여줍니다. 2명의 speaker나 3명의 speaker의 경우, 각 speaker condition에 특화된 model보다 성능이 아주 조금 감소됩니다. 게다가, 저자들의 method는 speaker 수가 주어졌을 때(Oracle), x-vector는 대부분의 case에서 성능이 하락되지만, SA-EEND + EDA는 성능이 향상됩니다.
저자들은 CALLHOME dataset을 이용해 real conversation에 대한 평가도 진행했습니다. 이 경우, CALLHOME training set을 이용해 model을 finetuning하고 tset했습니다. 결과는 다음과 같습니다.
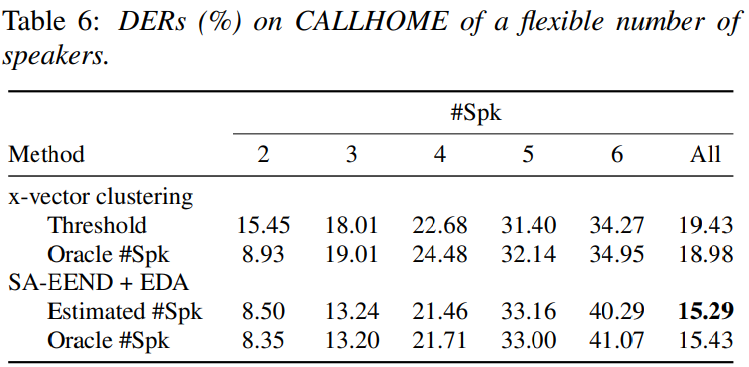
저자들의 method는 clusteirng based method보다 좋은 성능을 보여줍니다. 그러나, speaker 수가 4명보다 많아지는 경우 성능이 나쁜 모습을 보입니다. CALLHOME은 4명보다 더 많은 speaker가 존재하는 data는 오직 10개밖에 없기 때문입니다.
Conclusion
이 논문에서, 저자들은 embedding sequence에서 attractor를 계산하는 EDA를 제안했습니다. EDA를 SA-EEND에 적용해 flexible speaker 수인 speech mixture에서 동작하는 end-to-end speaker diarization을 수행합니다. 저자들의 method는 fixed and flexible number of speaker 모두에서 가장 좋은 DER 수치를 보입니다.



