https://arxiv.org/abs/2010.13366
Integrating end-to-end neural and clustering-based diarization: Getting the best of both worlds
Recent diarization technologies can be categorized into two approaches, i.e., clustering and end-to-end neural approaches, which have different pros and cons. The clustering-based approaches assign speaker labels to speech regions by clustering speaker emb
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
최근 diarization 기술들은 2가지 접근법으로 나눌 수 있습니다. clustering과 end-to-end neural approach입니다. clustering 기반 방식은 x-vector와 같은 speaker embedding을 clustering하여 speaker label을 speech region에 할당하는 방식입니다. 이 방식은 다양한 도전적인 data에 대해 robustness하고 정확한 최신 기술로 볼 수 있습니다. 하지만 overlapped speech를 다룰 수 없기 때문에 자연스러운 대화 data에는 적합하지 않다는 큰 단점이 있습니다. 반면에 end-to-end neural diarization (EEND)는 neural network를 이용해 diarization label을 직접적으로 예측하는 방식입니다. 이는 overlapped speech를 다룰 수 있습니다. EEND가 몇몇의 사실적인 dataset에 대해 x-vector clustering 방식보다 더 좋은 성능을 보였지만, memory 소비량이 많기 때문에 긴 recording (10분보다 더 긴 recording)에도 동작하게 만드는 것은 어렵습니다. block별로 독립적인 처리를 하는 것 또한 어렵습니다.
이 논문에서 저자들은 간단하지만 효과적인 hybrid diarization framework를 제안합니다. 이 framework는 overlapped speech에 동작할 수 있으며 임의의 수의 speaker를 포함하는 긴 녹음에 대해서도 동작할 수 있습니다. conventional EEND framework를 수정하여 global embedding을 출력하도록 만들었습니다. 순열 문제를 해결하기 위해 각 block마다 제한된 clustering algorithm을 적용해 speaker clustering을 진행합니다.
Introduction
자동 meeting/conversation 분석은 communication agent와 같은 미래지향적 speech application을 실현하는 데 필요한 필수 기술 중 하나입니다. 회의 분석을 위한 중요한 핵김 task로서, speaker diarization은 광범위하게 연구되고 있습니다.
현재 많은 challenge에서 신뢰할만한 성능을 보이고 있는 최신 diarization system은 i-vector, x-vector와 같은 speaker embedding을 clustering하는 방식을 사용합니다. 이러한 clustering 기반 방식들은 먼저 recording을 짧은 block으로 segment합니다. 그리고 각 block에 1명의 speaker만 말하고 있다고 가정한 다음 speaker embedding을 추출합니다. 그다음 speaker embedding vector들을 clustering하여 동일한 speaker에 속한 segment들을 regroup합니다. 이러한 방식으로 speaker diarization 결과를 얻을 수 있습니다.
다양한 speaker embedding과 clustering 기술들이 연구되고 있습니다. 하지만 이러한 방식들은 매우 도전적인 scenario를 처리할 수 있고 임의의 수의 speaker에 대해 동작할 수 있지만, 이는 overlapped speech (한 segment에 2명 이상의 speaker가 말하고 있는 speech)를 다룰 수 없다는 명확한 단점이 있습니다. 왜냐하면 각 segment마다 1명에 대한 speaker embedding을 추출하기 때문입니다. 전문적인 회의에서조차 overlapped speech의 비율은 약 5~10%이며, 비공식적인 모임에서는 20%를 쉽게 초과할 수 있습니다.
최근에 개발된 End-to-End Neural Diarization (EEND)은 overlapped speech 문제를 다룰 수 있습니다. neural source separation algorithm과 유사하게, EEND에 사용되는 neural network가 frame-level spectral feature를 input으로 받고 overlapped speech가 있든 없든 각 speaker에 대한 frame-level speaker activity를 output합니다. 이러한 system은 단순하고 conventional clustering based algorithm보다 더 좋은 성능을 보이지만, EEND system을 long recording에 바로 사용하는 것은 문제가 있습니다. system은 batch processing mode에서 동작하도록 design되어 있기 때문에, long recording에 대한 inference를 하면 매우 큰 computer memory가 필요하게 됩니다. memory 문제뿐만 아니라, EEND에 있는 neural network는 매우 긴 unseen sequential data를 일반화하는 것이 어렵습니다. 만약 long recording을 small chunk로 segment 하고 original EEND model을 각 chunk에 독립적으로 사용한다면, model은 불가피하게 chunk 간 speaker label 순열 문제가 생깁니다. 즉 각 chunk마다 speaker label 할당의 모호성 문제가 생깁니다. 이러한 문제를 해결하기 위해, block-online 처리를 위한 EEND의 NN 기반 확장 방법이 제안되었습니다. 이 방법은 먼저 single speaker region을 찾습니다. 그다음 해당 region들을 guide로써 사용하여, 다른 block들의 diarization result의 speaker label로 사용하는 방식입니다. 그러나 이러한 방식은 original EEND보다 더 좋지 않은 결과를 보입니다. 또한, 이 방법은 speaker 수가 모호한 경우에는 동작하지 않습니다.
이 논문에서, 저자들은 간단하지만 효과적인, EEND-vector clustering이라 불리는 hybrid diarization 방식을 제안합니다. 이는 clustering based diarization의 가장 좋은 결과와 EEND를 결합한 형태입니다. 저자들이 제안한 방식의 핵심 component는 EEND network가 각 chunk마다 diarization result 뿐만 아니라 diarization result와 관련있는 global speaker embedding을 output하도록 수정하는 것입니다. 이렇게 하여 각 chunk간 순열 모호성 문제는 block-level speaker embedding vector를 clustering함으로써 간단하게 해결할 수 있습니다. 이러한 확장은 clustering과 EEND 의 장점을 자연스럽게 결합할 수 있게 됩니다. 그래서 overlapped speech에서 동작할 수 있으며 speaker 수가 모호한 long recording에서도 잘 동작할 수 있습니다. 그리고 저자들은 실험을 통해 저자들이 제안한 EEND-vector clustering이 original EEND system보다 훨씬 좋은 결과를 보여준다는 것을 알아냈으며, 특히 5분보다 더 긴 long recording에서 훨씬 좋은 모습을 보인다고 합니다. recording의 길이가 짧다면, original EEND와 동일한 성능을 유지한다고 합니다.
Proposed Diarization Framework: EEND-Vector Clustering
Overall framework

위 그림은 저자들이 제안하는 EEND-vector clustering framework를 보여줍니다. 먼저, input recording을 chunk로 segment합니다. 그다음 각 chunk에서 input frame feature sequence를 계산합니다. X_i = (x_(t, i) | t = 1, ... , T)처럼 input feature sequence를 계산합니다. 여기서 i는 chunk index가 되며 t는 chunk에서의 frame index를 의미하고, T는 chunk size를 의미합니다. x_(t, i) ∈ R^K는 time frame t에서의 K차원 input frame feature를 의미합니다. 위 그림의 경우, input recording은 2개의 chunk로 구성됩니다. 그리고 2개의 chunk에서 총 3명의 speaker가 존재하는 형태입니다. 저자들은 chunk에 존재하는 최대 active speaker 수를 고정할 수 있으며, S_Local을 2로 고정한 모습입니다.
hyper-parameter S_Local = 2를 기반으로, network는 각 chunk에서 2명의 speaker에 대한 disrization을 추정합니다. 위 그림에서, 첫번째 speaker에 대한 과정은 검은 선으로 표시되어 있습니다. 그리고 두 번째 speaker에 대한 선은 회색 선으로 표시되어 있습니다. diarization 결과는 각 chunk에 Encoder로 표시된 neural network와 Linear_s^D (s = 1, 2)를 통해 추정되며, 여기서 s는 chunk에 존재하는 speaker index를 의미합니다. 이러한 방식은 특정한 speaker에 대한 speaker diarization 결과가 동일한 output node를 추정한다고 보장할 수 없기 때문에, diarization output에 label permutation 문제가 발생할 수 있습니다. 예를 들어, 위 그림에서 첫 chunk에 대해서 Linear_1^D가 'speaker A'에 대한 diarization을 추정하지만, 두 번째 chunk에서는 'speaker B'를 추정합니다. 즉, Linear_1^D가 index 1에 대한 result를 구하는 network인데, 각 chunk마다 speaker의 index가 다르다는 것을 의미합니다. 이는 모든 chunk에 대한 output node의 diarization 결과를 단순히 연결함으로써 최적의 diarization result를 얻을 수 없음을 의미합니다.
이러한 permutation 문제를 해결하기 위해, 저자들은 각 chunk의 diarization result에 해당하는 speaker embdding을 동시에 추정합니다. speaker embedding을 추정하는 network는 Linear_s^S (s = 1, 2)입니다. speaker embedding extraction network는 neural network가 동일한 speaker에 대한 vector는 가깝게, 다른 speaker에 대한 vector는 멀게 만들 수 있도록 학습하여 최적화될 수 있습니다. 모든 chunk에 대해서 diarization result를 얻은 다음, input recording에 존재하는 총 speaker 수(위 예시의 경우, 3명)에 대해 speaker embedding을 clustering합니다. 그다음, embedding clustering result를 기반으로 하는 결과를 결합함으로써 최종 전체 diarization result를 얻을 수 있습니다.
어떠한 clustering algorithm을 사용해도 문제가 없다고 합니다. 하지만, 이러한 framework의 특징을 알고 있고, chunk에서 구한 speaker embedding이 동일한 speaker cluster에 속할 필요가 없다는 제약을 가지고 있는 clustering algorithm이면 더 바람직하긴 합니다. 저자들의 경우, 'COP-k-means'라 불리는 constrained clustering algorithm을 사용합니다. 이 algorithm은 주어진 embedding pair는 동일한 speaker cluster에 속할 수 없다고 제약을 설정할 수 있습니다.
Neural diarization with speaker embedding estimation
EEND-vector clustering에서 사용되는, diarization result와 speaker embedding을 추정하는 neural network model에 대해 살펴보겠습니다. X_i에 해당하는 ground-truth diarization label sequence를 Y_i = (y_(t,i) | t = 1, ... , T)라고 하겠습니다. 여기서 diarization label y_(t,i) = [y_(t,i,s) ∈ {0, 1} | s = 1, ... , S_Local]은 S_Local speaker의 activity를 표현합니다. 예를 들어, y_(t,i,s) = y_(t,i,s') = 1 (s ≠ s')은 두 speaker s와 s'이 chunk i에서 time frame t에서 말을 하고 있다는 것을 의미합니다.
EEND framework에서, diarization task는 multi-label classification problem으로 표현할 수 있습니다. 구체적으로, 각 time frame에 대해 s번째 speaker의 diarization 결과를 추정하는 것입니다.
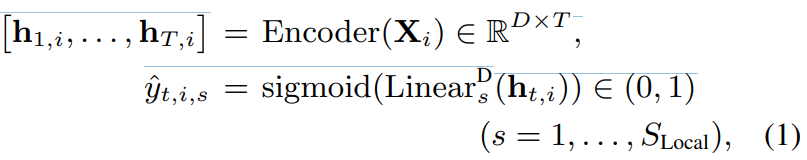
수식으로 나타내면 위와 같습니다. 여기서 Encoder()는 multi-head self-attention NN과 같은 encoder를 의미합니다. h_(t,i)는 D차원 representation을 의미합니다. Linear_s^D()는 D차원 representation 값을 1차원 diarization result로 만들어주는 fully connected layer입니다.
diarization result를 추정한 다음, permutation problem을 풀기 위해 s번째 speaker에 대한 diarization result에 해당하는 speaker embedding e_(i, s)^를 추정합니다.
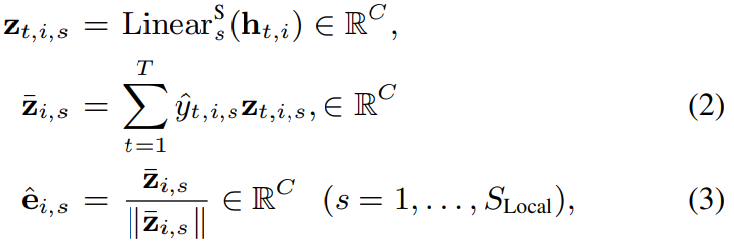
식으로 표현하면 위와 같습니다. C는 speaker embedding 차원을 의미합니다. Linear_s^S는 D차원 representation을 C차원 speaker embedding으로 만들어주는 fully-connected layer를 의미합니다. 그리고 || ||는 vector norm을 의미합니다. 저자들은 speaker embedding을 frame-level embedding z_(t, i, s)와 diarization result y_(t, i, s)^의 weighted sum으로 표현합니다. 이러한 연산을 통해, 저자들은 모든 S_Local speaker에 대한 speaker embedding과 diarization result를 추정할 수 있습니다. speaker embedding estimator를 제외한 model은 conventional EEND model과 동일합니다.
Training objective
저자들은 diarization result와 speaker embedding을 동시에 추정하는 network를 사용하기 때문에, 저자들은 multi-task loss를 사용했습니다.

여기서 L은 total loss function을 의미하며, 이를 minimize하도록 학습합니다. L_diarization은 diarization error loss를 의미하고, L_speaker는 speaker embedding loss를 의미합니다. 그리고 λ는 두 loss function의 weight에 해당하는 hyper-parameter입니다.
- Diarization Loss
각 chunk에 대한 diarization loss는 다음과 같습니다.
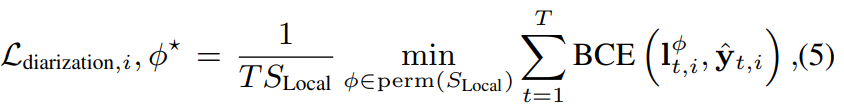
perm(S_Local)은 (1, ... , S_Local)에 가능한 모든 permutation 집합을 의미합니다. y_(t, i)^ = [y_(t, i, 1)^, ... , y_(t, i, S_Local)^] ∈ R^(S_Local)이고, I_(t, i)^Φ는 Φ번째 추론한 speaker label permutation을 의미합니다. BCE()는 label과 추정한 diarization output 사이의 binary cross-entropy function을 의미합니다. Φ*는 우항을 minimize하는 Φ를 의미합니다. 이러한 permutation-invariant training은 neural diarization에 효과적이지만, 각 chunk마다 speaker label의 순서가 변할 수 있는 문제를 발생시킵니다. 이러한 L_diarization은 B 크기의 mini-batch를 이용해 구해집니다.
hyper-parameter인 S_Local은 S_Local ≤ S_total을 만족하면서 적절한 값으로 골라야 합니다. S_total은 input recording에 존재하는 총 speaker 수를 의미합니다. 만약 우리가 설정한 S_Local보다 chunk에 등장하는 speaker 수가 적다면, 가상의 조용한 speaker를 채워넣어 문제를 해결합니다.
- Speaker embedding loss
저자들은 동일한 speaker에 대해선 small distance를 갖도록 하고 다른 speaker에 대해선 large distance를 갖도록 하는 loss function을 사용해 speaker embedding training을 진행합니다. 구체적으로, 저자들은 최근에 제안된 loss를 사용합니다. 이는 speech separation task에서 매우 효과적인 loss입니다. loss를 사용하기 위해, 저자들은 training data가 speaker identity label로 annotated된 형태라고 가정합니다. test에서는 speaker identity를 필요로 하지는 않습니다. 그리고 train speaker와 test speaker는 달라도 됩니다. σ_i* = [ σ_(i, 1)*, ... , σ_(i, S_Local)*]를 (5)식을 minimize하는 permutation에 해당하는 speaker identiy라고 하겠습니다. chunk i에 대한 speaker embedding loss L_(speaker, i)는 다음과 같이 정의됩니다.
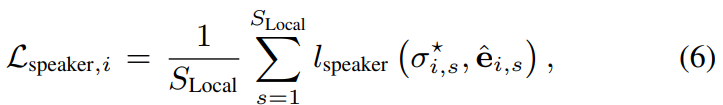
위 식은 다음 식을 이용해 표현됩니다.

여기서 E는 학습 가능한 global speaker embedding dictionary를 의미합니다. E_m은 학습 가능한 m번째 training speaker에 해당하는 variance-normalized global speaker embedding입니다. (8)식은 학습 가능한 global speaker embdding과 추정된 speaker embedding 사이의 Euclidean 거리의 제곱을 의미합니다. 해당 식은 학습 가능한 parameter α > 0, β을 사용합니다. (7)식은 추정된 embedding과 global embedding 사이의 추정된 distance에 log softmax를 적용한 값입니다. loss function L_speaker는 B개의 chunk에 적용해 구해집니다.
이 두 가지 loss를 minimize함으로써, overlapped speech여도 diarization result를 정확하게 추정할 수 있으며, 동시에 clustering process에 적절히 사용할 수 있는 speaker embedding도 학습할 수 있습니다.
Experiments
저자들이 제안한 방식의 효과를 보입니다. conventional EEND와 비교하며, 상당히 많은 부분이 overlapped speech인 long recording을 포함한 test data를 이용합니다.
Data
저자들은 대화와 같이 2명의 speaker의 mixture에 대해 simulate하기 위해, random하게 선택된 2명의 speaker로부터 utterance를 고른 다음 적절히 잘 섞어서 사용했습니다. 저자들은 다양한 condition의 dataset을 만들어내어 사용했습니다. training과 validation tdata로 저자들은 random하게 460시간의 clean training data를 사용했습니다. 이 data에는 총 1172명(M = 1172)의 speaker가 존재합니다. 그리고 test dataset으로 4개를 만들었습니다. 각 dataset은 500개의 utterance가 존재합니다. 평균적으로 각 dataset에는 3, 5, 10, 20분의 mixture가 존재합니다.
NN training and hyper-parameters
input frame feature로, 저자들은 23차원 log-Melfilterbank feature를 25ms frame length와 10ms freame shift와 함께 사용했습니다. 저자들이 제안한 method와 conventional EEND는 각 training stage에서 chunk size T = 500 (50sec)으로 설정했습니다. 그래서 training data가 50초를 넘긴다면, input audio를 non-overlapping 50초 chunk로 나누었습니다. inference 단계에서, conventional EEND는 chunk 없이 전체 input sequence를 사용했습니다. 반면에, 저자들이 제안한 방식은 input data를 non-overlapping 50초 chunk로 나누어 사용했습니다. test data의 약 25%는 1명 speaker로 이루어지며, 나머지는 2명 speaker로 이루어져 있습니다.
저자들은 Encoder로 4개의 head (D = 256)를 가지고 있는 256 attention unit으로 이루어진 two multi-head attention block을 사용했습니다. Adam optimizer를 사용해 학습했습니다. batch size B는 64로 두고 진행했습니다.
저자들이 제안한 방식에 존재하는 λ = 0.01로 두었습니다. S_Local = 2로 설정했습니다. speaker embedding 차원 C는 256으로 설정했습니다. 제안한 방식의 performance는 COP-k-means algorithm의 초기화에 따라 약간 달라지기 때문에, random initialization을 사용해 10번 test inference를 진행한 후 평균을 구했습니다.
Results
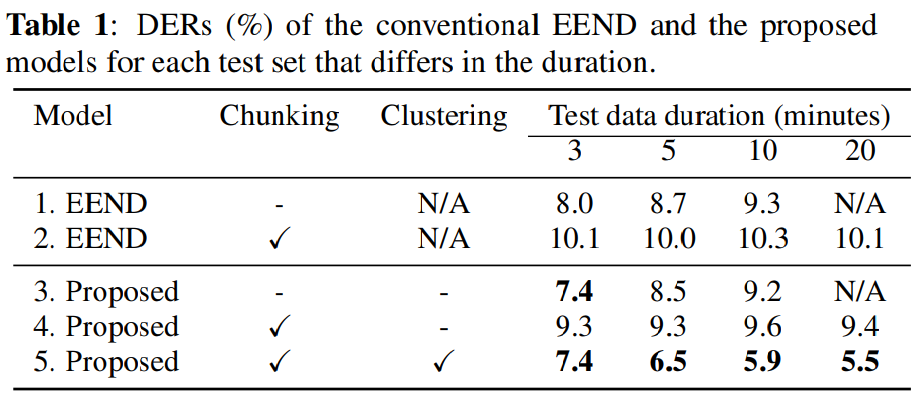
위 표는 DER을 보여줍니다. 1번째 행은 chunk를 사용하지 않고 전체 sequence를 사용하는 conventional EEND를 의미합니다. 5번째 행은 chunk를 사용하고 clustering도 하는 proposed method입니다. 저자들이 제안한 방식이 conventional EEND보다 더 뛰어난 결과를 보이는 것을 알 수 있습니다. 특히, test data의 length가 길어질수록, 저자들이 제안한 방식의 성능이 conventional EEND보다 현저히 뛰어난 것을 알 수 있습니다. conventioanl EEND는 long data에 대한 일반화 성능이 좋지 않기 때문에 10분에서 20분 정도의 dataset을 다룰 수 없습니다. 하지만 EEND-vector clustering은 각 data에 대해 안정적인 diarization performance를 보여줄 수 있습니다. 저자들이 사용한 data에서는 data length가 늘어날수록 clustering 성능이 향상되는 것을 볼 수 있습니다. 아마 data의 길이가 길어질수록 clustering에 사용할 수 있는 embedding수가 늘어나고, 이를 통해 clustering algorithm이 cluster 중심을 잘 찾도록 만들어진다고 예측한다고 합니다.
첫 번째 행과 세 번째 행을 비교하겠습니다. 저자들이 제안한 방식이 conventional EEND와 거의 모든 경우에 유사한 성능을 보여줍니다. 즉 이를 통해 추가적인 speaker loss가 diarization 성능에 부정적인 영향을 주지 않는다는 것을 알 수 있습니다.
그다음, 첫/세 번째 행과 두/네 번째 행을 비교하겠습니다. chunk를 사용하는 것이 block 간의 label permutation problem을 야기하므로 성능이 저하되는 것을 볼 수 있습니다. speaker 수가 많아진다면, 이러한 문제는 더 크게 적용될 것입니다. 하지만 저자들이 제안한 constrained-clustering-based diarization result stiching을 사용하면 성능이 크게 향상되며, 이를 통해 효과를 확인할 수 있었습니다.
Conclusion
저자들은 간단하지면 효과적인 diarization framework인 EEND-vector clustering을 제안했습니다. 이는 diarization 결과와 speaker embedding을 동시에 추정할 수 있습니다. speaker embedding을 이용함으로써, 저자들은 block 간의 label permutation 문제를 해결했습니다. 실험을 통해 EEND-vector clustering이 original EEND보다 더 좋은 성능을 보인다는 것을 알아냈으며, 특히 input data가 길수록 더 좋은 결과를 보인다는 것을 알아냈습니다.



