https://arxiv.org/abs/2212.04356
Robust Speech Recognition via Large-Scale Weak Supervision
We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 internet에 있는 대량의 audio transcription을 예측할 수 있도록 간단하게 학습된 speech processing에 대한 연구를 진행했습니다. 680000 시간의 다국어 및 multitask supervision을 사용하면, model은 좋은 성능을 보입니다. 사람과 비교했을 때도, model은 높은 정확도와 robustness를 보입니다.
Introduction
speech recognition의 발전은 Wav2Vec 2.0과 같은 unsupervised pre-training technique의 발달에 따라 빠르게 진행되고 있습니다. 이러한 방식들은 human label이 없는 raw audio를 직접적으로 이용해 학습하며, human label이 없어도 되기 때문에 대규모 unlabeled speech dataset을 효과적으로 사용할 수 있습니다. 최근에는 1,000,000시간의 training data를 사용하기도 합니다. 적은 수의 dataset인 상황에서, standard benchmark를 fune-tuning하는 것은 좋은 성능을 보였습니다.
이러한 pre-trained audio encoder는 speech의 high-quality representation을 학습하지만, 완전히 unsupervised이기 때문에 representation을 usable output으로 mapping하는 decoder의 성능이 떨어집니다. 그래서 speech recognition과 같은 task를 진행할 때는 fine-tuning stage가 필수적으로 사용됩니다. fine-tuning 역시 간단한 작업은 아닙니다. 그리고 fine-tuning을 할 때 추가적인 risk도 존재합니다. 특정 dataset으로 fine-tuning한다면, 해당 dataset에 대한 정확도는 향상되지만 다른 dataset에 대한 정확도가 향상 되지는 않습니다.
unsupervised pre-training이 audio encoder의 quality를 매우 향상시킬 수 있지만, pre-trained decoder의 능력이 부족하고 dataset에 특화되는 fine-tuning이 결합되어 최종 model의 유용성과 강건함이 떨어지게 됩니다. speech recognition system의 목표는 모든 환경에서 supervised fine-tuning decoder 없이도 바로 사용 가능하게 안정적으로 작동하는 것입니다.
다양한 dataset/domain에서 supervised 방식으로 pre-trained된 speech recognition system은 single source로 학습된 model보다 더 robustness하고 일반화 성능이 더 좋습니다. 하지만 supervised high-quality speech recognition dataset의 양이 부족하다는 문제가 여전히 존재합니다.
high-quality supervised dataset의 양이 제한되기 때문에, 최근에는 dataset을 생성하는 연구들이 진행되었습니다. 또한, weakly supervised speech recognition system을 개발하여 추가적인 noise가 있는 training dataset을 사용해 학습하는 방식도 등장했습니다. computer vision 분야에서는, weakly supervised dataset을 사용하는 것이 model의 robustness와 generalization을 크게 향상시킨다는 연구도 등장했습니다.
이렇게 새로 생성된 weakly supervised dataset들은 high-quality dataset의 몇 배 정도 양이긴 하지만, 여전히 unsupervised dataset보단 현저히 적습니다. 이 연구에서, 저자들은 680,000 시간의 labeled audio data를 이용해 wakly supervised speech recognition을 학습했습니다. 저자들은 이를 Whisper라고 부릅니다(Web-scale Supervised Pretraining for Speech Recognition). 저자들이 제안한 model은 zero-shot에도 잘 전이되며, 추가적인 data-specific fine-tuning을 필요로 하지 않습니다.
dataset의 scale 뿐만 아니라, 저자들은 weakly supervised pre-training을 영어 뿐만 아니라 다양한 언어와 multitask로도 확장합니다. 680,000시간 audio 중에 117,000시간은 96가지의 다른 언어입니다. model의 크기가 충분히 크다면, 다양한 언어와 multitask training을 공동으로 진행하는 데 문제가 없으며, 오히려 이점이 있다는 것을 발견했다고 합니다.
저자들의 연구는 weakly supervised pre-training의 scaling을 늘리는 것이 speaker recognition에서 과소평가되었음을 제안합니다. 저자들은 speech recognition에서 현재 주로 사용되는 self-supervision이나 self-training technique을 사용하지 않고도 좋은 성능을 가져왔습니다.
Approach
Data Processing
machine learning system을 학습시키기 위해 internet에서 web-scale text를 가져와 사용하는 것이 최근 연구 trend이며, 이를 따라 저자들은 data pre-processing을 최소로 합니다. 대부분의 speech recognition과 다르게 저자들은 Whisper model이 standardization없이 transcript의 raw text를 예측할 수 있도록 학습합니다. utterance와 utterance의 transcribed form 사이를 mapping하도록 배우는 sequence-to-sequence model입니다.
이 방식은 naturalistic transcription을 만들 때 사용되는 inverse text normalization step의 필요성을 제거하기 때문에, speech recognition pipeline을 단순화시킬 수 있습니다.
저자들은 Internet에 있는 transcript와 pair를 이루는 audio를 가지고 dataset을 만들어냅니다. 그렇기 때문에 다양한 환경, recording setup, speaker, language을 다루는 다양한 audio dataset이 됩니다. audio quality에서의 다양성은 model이 robust하도록 만들어주지만, transcript quality의 다양성은 그렇게 이점이 되지는 않습니다. raw dataset에서 많은 양의 불량 transcript가 있다는 것을 알아냈습니다. 그래서 저자들은 transcript quality를 향상시켜주는 automated filtering method를 개발했습니다.
internet에 있는 많은 transcript는 사람이 직접 만든 것이 아니라, ASR system의 output입니다. 최근 연구에서 인간이 만들어낸 data와 machine이 만들어낸 data를 섞어서 training dataset으로 사용하는 것은 translation system의 성능을 크게 저하시킨다는 것이 밝혀졌습니다. 그래서 "transcriptese (machine이 만든 transcript를 기반으로 학습되는 것?)"를 학습하는 것을 피하기 위해, 저자들은 training dataset에서 machine이 생성한 transcript를 detect하고 제거하는 여러 heuristic을 개발했습니다. 존재하는 많은 ASR system들은 복잡한 구두점(느낌표, 쉼표, 물음표), 문단과 같은 서식 공백 또는 대소문자와 같이 audio signal만 사용했을 때 예측하기 어려운 부분을 제거하거나 정규화한 output을 생성합니다. 즉 제한된 output을 생성합니다. 많은 ASR system들은 inverse text normalization을 포함하지만, 보통 단순하거나 rule-based이기 때문에 여전히 detectable합니다.
그리고 저자들은 audio language detector도 사용합니다. 이는 VoxLingua107에서 prototype version dataset으로 fine-tuning된 prototype model입니다. audio language detector는 transcript의 language가 spoken language와 동일한 지 확인합니다. 만약 transcript language와 spoken language가 일치하지 않는다면, 해당 (audio, transcript) pair를 speech recognition train dataset으로 사용하지 않았다고 합니다. transcript이 영어이면, speech translation training dataset으로 해당 pair를 사용했다고 합니다(audio는 영어가 아니고 transcript은 영어니까). 추가적으로 저자들은 transcript text의 중복을 줄이고 training dataset에서 자동으로 생성되는 content의 양을 줄이기 위해 fuzzy de-duping을 사용합니다.
추가적인 filtering pass를 위해, initial model을 학습한 후 training data source에 대한 error rate를 집계했습니다. data source를 error rate와 data source의 크기의 조합으로 정렬하여 low quality data를 효율적으로 식별하고 제거했습니다. 이 과정을 통해 이전에 감지하지 못한 low quality machine-generated caption을 대량으로 발견할 수 있었습니다.
data 오염을 피하기 위해, 저자들은 training dataset과 evaluation dataset에서 중복 가능성이 높은 것으로 판단되는 transcript들을 제거했습니다.
Model
저자들의 연구는 speech recognition system에 large-scale supervised pre-training했을 때의 성능에 중점을 두고 있으므로, model 개선 결과를 혼동하지 않기 위해 이미 발표된 model을 사용합니다. 저자들은 encoder-decoder Transformer을 선택했습니다. 모든 audio는 16000 Hz로 resample되었으며, 80-channel log-magnitude mel-spectrogrma representation을 25ms window, 10ms stride로 구했습니다. feature normalization을 위해, 저자들은 input을 pre-training dataset 전반에 걸쳐 대략적으로 평균이 0이 되도록 -1에서 1 사이로 scaling합니다. encoder는 filter width가 3이고 geLU activation function을 사용하는 2개의 convolution layer로 구성되며, encoder는 input을 representation으로 만들어줍니다. 여기서 두 번째 convolution layer는 stride를 2로 설정했습니다. 그 이후 cosine position embedding이 더해지고 encoder transformer block이 추가됩니다. transformer는 pre-activation residual block을 사용하며, 마지막으로 encoder의 output에 layer normalization이 적용됩니다. decoder는 학습된 position embedding을 사용하고 input-output token representation을 사용합니다. encoder와 decoder는 동일한 width를 사용하고 transformer block 수도 동일합니다. 그림으로 보면 다음과 같이 model 구조를 그릴 수 있습니다.
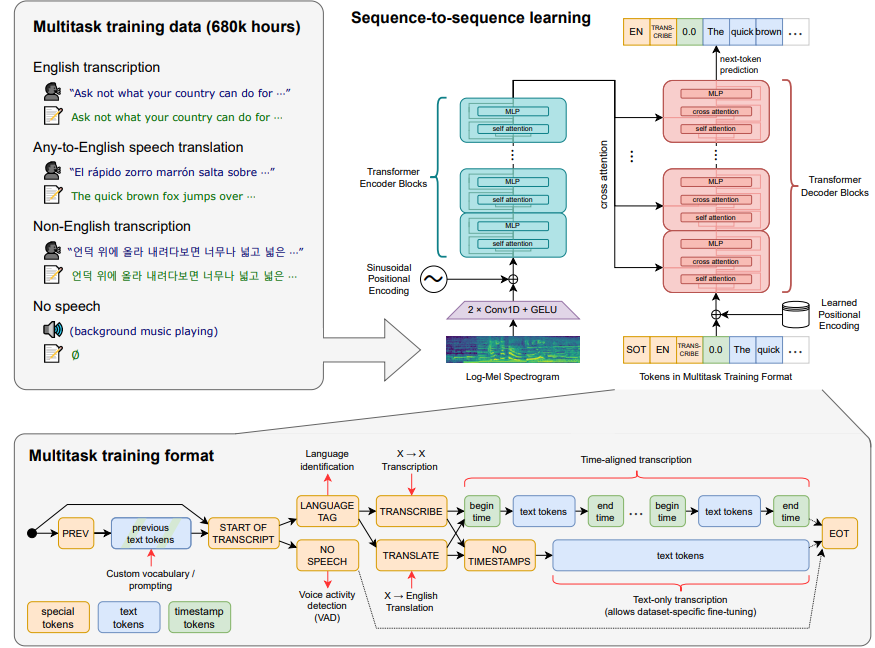
영어 전용 model에는 GPT-2에서 사용되는 byte-level BPE text tokenizer를 사용했으며, multilingual model에서는 GPT-2-BPE vocabulary가 영어 전용이기 때문에 vocabulary를 refit했습니다(size는 동일하게).
Multitask Format
주어진 audio에서 어떤 단어가 말해졌는지 예측하는 것은 full speech recognition problem에서 주요한 part이고 주로 연구되는 부분이지만, 이 부분만 중요한 것은 아닙니다. fully featured speech recognition system은 voice activity detection, speaker diarization, inverse text normalization과 같은 추가적인 component를 포함할 수 있습니다. 이러한 component들은 주로 분리되어 처리되어, 복잡한 system이 형성됩니다. 복잡성을 줄이기 위해, 저자들은 전체 speech processing pipeline을 단일 model로 perform하도록 만듭니다. 이를 위해선 model의 interface를 잘 구현해야 합니다. 다양한 서로 다른 task들은 동일한 input audio signal을 받아서 perform할 수 있습니다. 예를 들어 transcription, translation, voicec activity detection, alignment, language identification은 동일한 input audio signal을 받아서 perform할 수 있습니다.
단일 model로 하나의 input을 각 task에 맞춰 다양한 output으로 mapping하기 위해, task 별로 작업이 필요합니다. 저자들은 간단한 방식으로 모든 task와 input token의 sequence를 conditioning information으로 decoder에 전달합니다. 저자들의 decoder는 audio-conditional language model이기 때문에, 저자들은 모호한 audio를 해결하기 위해 decoder가 긴 범위의 text context를 사용하도록 학습될 수 있게 긴 범위의 text context history를 condition으로 할 수 있도록 학습합니다. 구체적으로, 일정 확률로 현재 audio segment에 이전 transcript text를 decoder의 context에 추가합니다. 저자들은 예측의 시작을 <|startoftranscript|> token으로 나타냅니다.
먼저, spoken language를 예측하는데, train set에 있는 각 언어에 대한 고유한 token(language token은 99개 존재)으로 이를 표현합니다. 이러한 language target은 VoxLingua107 model에서 가져옵니다. audio segment에서 speech가 존재하지 않는 경우, model은 <|nonspeech|> token을 예측하도록 학습됩니다. 다음 token은 task를 token으로 표현해 줍니다(<|transcrible|>, <|translate|>처럼). 이후, timestamp를 예측하는지 아닌지를 <|notimestamps|> token을 예측하거나 안 하는 것으로 표현합니다. 이렇게 timestamp token까지 끝나면, 이제 task와 원하는 형식이 완전히 지정되며, output이 시작됩니다. timestamp 예측을 위해, 저자들은 현재 audio segment에 상대적인 시간을 예측하고, 모든 시간을 Whisper model의 기본 시간 해상도에 맞춰 가장 가까운 20ms로 양자화하며, 이에 대한 추가적인 token을 vocabulary에 추가합니다. 저자들은 caption token과 timestamp token을 번갈아가면서 예측합니다. 시작 시간 token이 각 caption의 text를 예측하기 전에 예측되며, caption text를 예측한 후 end time token이 예측됩니다. transcript가 30초 audio chunk에 부분적으로만 포함된 경우(utterance가 35초인데 audio chunk가 30초 길이여서 utterance가 잘린 경우), start time token만 예측하며 후속 decoding은 해당 time과 정렬된 audio window에서 동작되어야만 하며, 그렇지 않으면 해당 segment를 포함하지 않도록 audio를 잘라냅니다.
마지막으로, <|endoftranscript|> token을 추가합니다. 저자들은 이전에 처리한 context text(long range text context를 처리하기 위해 이전에 구한 context text를 사용하니)에 대해서는 training loss를 구하지 않고, 새로운 text에 대해서만 training loss를 구하며, model은 다른 모든 token들을 예측하도록 학습됩니다.
Training Details
저자들은 Whusper의 scale에 따른 연구를 진행하기 위해 model을 다양한 size로 설정하여 학습했습니다.
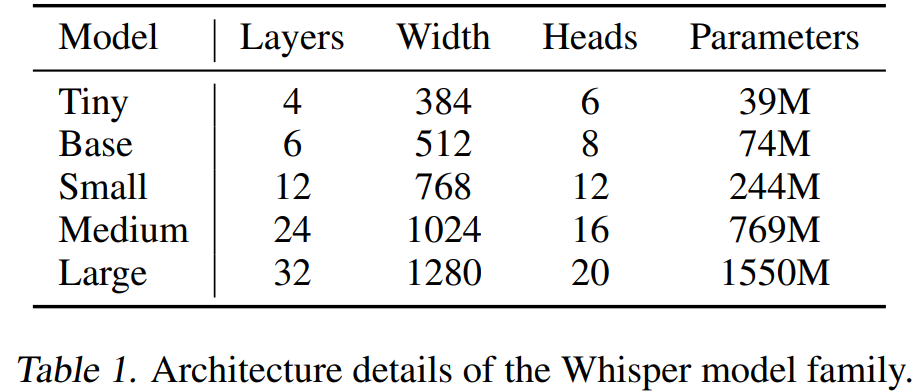
위와 같습니다. 저자들은 model을 많은 횟수의 epoch으로 train하지 않았으며, overfitting 문제는 크게 고려하지 않았다고 합니다. 그리고 저자들은 data augmentation이나 regularization을 사용하지 않았으며, 대신 large dataset내에 포함된 다양성에 의해 generalization과 robustness가 증가되도록 만들었습니다.
실험 초반에 Whipser model은 그럴싸한 transcribe를 수행하지만 speaker의 이름은 잘못 예측하는 경향을 발견했습니다. pre-training dataset에 있는 많은 transcript들이 말하고 있는 사람의 이름을 포함하고 있기 때문에 model이 이를 예측하길 바랐지만, 30초의 audio context만으로 유추할 수 있는 경우가 드물기 때문에 speaker 이름을 잘못 예측하는 문제가 발생했습니다. 이를 해결하기 위해, 저자들은 speaker 이름이 없는 transcript을 이용해 Whisper모델을 잠깐 동안 fine-tune했습니다.
Experiments
Zero-shot Evaluation
Whisper의 goal은 dataset에 대한 fine-tuning 없이도 high-quality의 결과를 보이는 단일 robust speech processing을 개발하는 것입니다. 저자들은 Whisper가 domain, task, language 별로 generalize 성능을 보이는지 아닌지를 확인하기 위해 널리 사용되는 speech processing dataset을 사용했습니다. 이러한 dataset에 대한 standard evaluation protocol (train and test split)을 사용하는 대신, Whisper를 각 dataset에 대한 training data를 사용하지 않는 zero-shot setting에서 평가했으며 이를 통해 generalization을 측정할 수 있었습니다.
Evaluation Metrics
Speech recognition 연구는 주로 word error rate (WER) metric을 기반으로 system을 평가합니다. WER은 string edit distance를 기반으로 model의 output과 target transcript 사이의 차이를 penalty합니다. 결과적으로 사람은 output transcript와 target transcript 사이의 차이가 없다고 판단하지만, WER은 높게 측정될 수도 있습니다. 이는 특정 dataset의 transcript의 예시를 전혀 알지 못하는 Whisper와 같은 zero-shot model에 특히 큰 문제가 됩니다.
사람의 판단과 더 연관 있는 evaluation metric을 개발하는 것은 활발히 연구되고 있는 분야이지만, 아직 speech recognition에서 널리 사용되고 있는 method가 존재하지는 않습니다. 그래서 저자들은 WER을 계산하기 전에 text를 광범위하게 standardization하여 의미가 없는 차이에 대한 penalty를 최소화하는 방식으로 문제를 해결했습니다. 저자들의 text normalizer는 naive WER이 Whipser model에 의미가 없는 차이에 대한 penalty를 주는 pattern을 분석하여 개발되었습니다. 여러 dataset에서, 저자들은 WER이 50% 가까이 감소되는 것을 볼 수 있었습니다.
English Speech Recognition
2015년, Deep Speech 2라는 사람 수준의 speech recognition system이 등장했습니다. 해당 model의 저자들은 "domain adaptation 없이는 일반적인 음성 system이 더 깔끔한 음성을 만드는 것에 대한 개선할 여지가 없다"라고 했습니다. 하지만 7년 후 LibriSpeech test-clean에 대한 SOTA WER는 5.3%에서 1.4%로 감소했습니다. 인간 수준의 eeror rate가 5.8%인데, 이 수치는 그보다 훨씬 더 뛰어난 결과입니다. 이렇게 뛰어난 결과를 보이는 speech recognition system이지만, 다른 setting에서 사용되면 사람 수준의 결과보다 훨씬 좋지 않은 모습을 보여줍니다. 그럼 사람보다 뛰어난 모습을 보이다가도 다른 setting에서는 사람보다 좋지 않은 모습을 보이는 것에 대해서 어떻게 설명할 수 있을까요?
저자들은 이러한 차이는 test에서 발생하는 것이 아니라 어떻게 훈련했는지에 있다고 합니다. 사람들은 특정 data 분포에 대해 거의 또는 전혀 supervision이 없는 상태로 task를 수행합니다. 그렇기 때문에 사람의 performance는 분포 외의 generalization을 측정하는 것입니다. 하지만 machine learning model들은 주로 많은 양의 supervision으로 학습이 된 후에 evaluation distribution으로 평가됩니다. 이는 machine의 performance는 분포 내의 generalization을 평가하는 것입니다.
광범위하고 다양한 분포의 audio로 학습되고 zero-shot setting에서 평가되는 Whisper model은 기존의 system들보다 사람의 행동과 훨씬 더 일치시킬 수 있습니다. 저자들은 Whisper model을 인간 performance와 비교하고 standard fine-tuned machine learning model과 비교하였습니다.
비교한 차이를 정량화하기 위해, 저자들은 overall robustness (많은 distribution/dataset에 대한 평균 performance)와 effective robustness (분포 내에 있는 dataset과 하나 이상의 분포 외 dataset 간의 성능 차이)를 보입니다. 높은 effective robustness가 있는 model은 reference dataset에서의 성능에 따라 분포 외 dataset에서 예상보다 더 나은 성능을 보이며, 모든 dataset에서 동일한 성능을 보이는 이상적인 상태로 접근합니다. 저자들은 분석을 위해 LibriSpeech를 reference dataset으로 사용합니다. 저자들은 분포 외에서의 행동을 확인하기 위해 12개의 speech recognition dataset을 사용했습니다.
저자들의 주요한 발견은 다음과 같습니다.
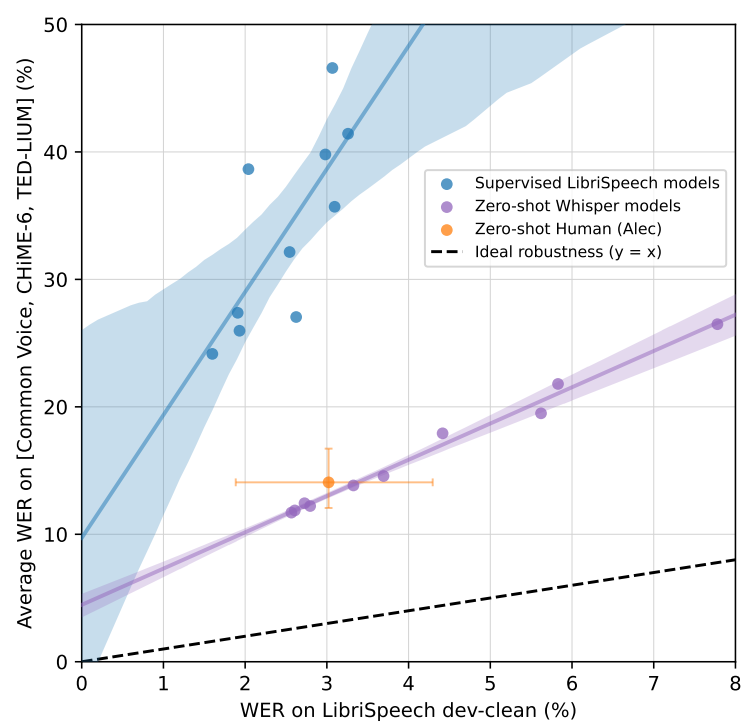 |
 |
가장 좋은 zero-shot Whisper model은 LibriSpeech clean-test WER이 2.5지만, 이는 2019년 중반의 최고 기술 수준과 비슷한 수치입니다. 그리고 zero-shot Whisper model은 supversied LibriSpeech model과 매우 다른 robustness 특성을 가지며, 다른 dataset으로 평가한 model 성능은 zero-shot Whipser model이 훨씬 뛰어난 모습을 보입니다. 가장 size가 작은 zero-shot Whisper model도 LibriSpeech tset-clean WER이 6.7이며, supervised LibriSpeech model을 다른 dataset으로 평가했을 때 얻은 결과와 비슷합니다. 위 왼쪽 그래프와 같이 best zero-shot Whisper model을 사람과 비교했을 때, best zero-shot Whisper model은 accuracy와 robustness가 비슷한 수준을 보여줍니다. 위 오른쪽 표는 best zero-shot Whisper model을 supervised LibriSpeech model과 비교한 모습입니다. supervised LibriSpeech model은 LibriSpeech test-clean에서는 best zero-shot Whisper와 매우 유사한 성능을 보여줍니다. 이와 같이 reference distribution에서는 매우 비슷한 성능을 보여주지만, zero-shot Whisper model은 다른 speech recognition dataset으로 평가했을 때 평균적으로 55.2% 더 좋은 성능을 보여줬습니다.
이 결과는 zero-shot과 model을 분포 외 dataset으로 평가하는 것을 강조하며, 특히 사람의 성능과 비교할 때 machine learning system의 능력을 과장하지 않기 위해 중요합니다.
Multi-lingual Speech Recognition
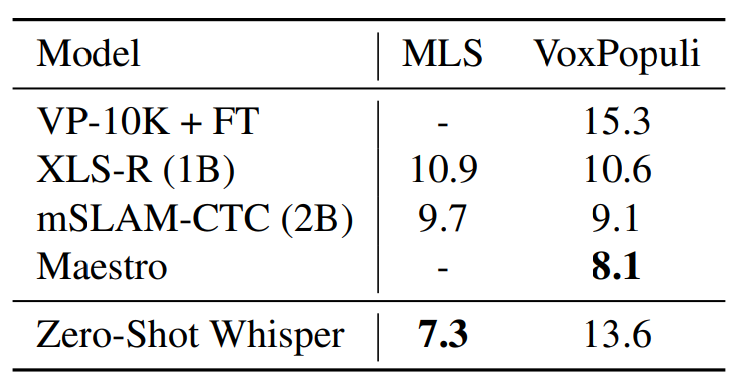
MLS는 Multilingual LibriSpeech입니다. VoxPopuli도 multilingual speech recognition에서 주로 사용되는 dataset입니다. zero-shot setting에서 다른 model들보다 훨씬 더 좋은 성능을 보이는 것을 볼 수 있습니다. VoxPopuli dataset에 대해서는, Whisper의 성능이 떨어진다는 걸 볼 수 있습니다. 저자들은 다른 model들이 unsupervised pre-training한 dataset에 VoxPopuli의 major distribution을 포함하고 있기 때문이라고 합니다.
이뿐만 아니라 다양한 실험을 저자들은 진행했으며, 자세한 내용은 논문을 보면 확인할 수 있습니다.
Conclusion
Whisper는 scaling weakly supervised pretraining은 speech recognition 분야에서 과소평가되었다는 것을 보여줍니다. self-supervision과 self-training technique 없이 얻은 저자들의 결과는, 어떻게 많고 다양한 supervised dataset으로 간단하게 학습할 수 있는지와 zero-shot transfer가 speech recognition system의 robustness를 매우 향상시킬 수 있다는 것을 보여줍니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Imaginary Voice: Face-Styled Diffusion Model for Text-to-Speech (0) | 2024.04.22 |
|---|---|
| [논문] Improving Medical Speech-to-Text Accuracy with Vision-Language Pre-training Model (0) | 2024.04.16 |
| [논문] End-to-End Adversarial Text-to-Speech (0) | 2024.04.08 |
| [논문] FastSpeech: Fast, Robust and Controllable Text to Speech (0) | 2024.04.05 |
| [논문] Char2Wav: End-to-End Speech Synthesis (0) | 2024.04.04 |



