https://arxiv.org/abs/2302.13700
Imaginary Voice: Face-styled Diffusion Model for Text-to-Speech
The goal of this work is zero-shot text-to-speech synthesis, with speaking styles and voices learnt from facial characteristics. Inspired by the natural fact that people can imagine the voice of someone when they look at his or her face, we introduce a fac
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문에서는 facial characteristic으로부터 학습된 voice와 speaking style을 가지고 zero-shot text-to-speech synthesis를 하는 것입니다. 사람이 누군가의 얼굴을 봤을 때, 그 사람의 목소리를 상상할 수 있다는 것에서 영감을 받았으며, 저자들은 visible attribute로부터 학습된 통일된 framework인 face-styled diffusion text-to-speech (TTS) model을 제안합니다. 저자들은 이 model을 Face-TTS라 부릅니다. 저자들이 제안한 model이 face image를 condition으로 사용하여 TTS model을 학습한 첫 논문입니다.
저자들은 face image와 generated speech segment에서 speaker identity를 보존하기 위해 cross-modal biometric과 TTS model을 동시에 학습합니다. 저자들은 speaker embedding space에서 ground truth speech segment와 generated speech segment의 similarity를 강제하기 위해 speaker feature binding loss를 제안합니다. biometric information은 face image에서 바로 추출되며, 저자들의 method는 보지도 못했고 듣지도 못했던 speaker로부터 speech를 생성하기 위한 추가적인 fine-tuning step을 필요로 하지 않습니다.
Introduction
TTS는 speech processing에서 core task 중 하나이며, 주어진 text transcription을 가지고 speech waveform을 생성합니다. Deep generative model은 text sequence로부터 고품질의 spectral feature를 생성하기 위해 사용되었습니다. 그리고 이 model들은 전통적인 parametric 합성 방식과 비교했을 때, 합성된 speech signal의 품질을 매우 향상시켰습니다.
image generation, video generation, natural language processing과 같은 다양한 연구 분야에서 diffusion model을 사용하는 다양한 연구들은 상당히 뛰어난 품질의 output을 만들어내고 있습니다. 예를 들어, DALLE-2, Stable Diffusion과 같은 image generation model들은 diffusion method를 사용합니다. 마찬가지로, TTS에서도 diffusion method는 이전의 acoustic modeling, vocoder들과 비교했을 때 더 좋은 성능을 보이고 있습니다.
하지만, TTS에서 아직도 해결하지 못한 몇 가지 문제들이 존재합니다. 그중 하나를 이 논문에서 다루는데, single speaker TTS model을 multi-speaker TTS로 확장시키는 것입니다. 모든 사람들이 서로 다른 speaking style, tone, accent를 가지고 있기 때문에, TTS model이 다양한 speaker style을 배우는 것이 어렵습니다. 그리고 또 하나의 문제 중 하나는 unseen speaker의 voice를 생성하기 위해선 상당히 많은 양의 target speaker의 speech sample이 필요하다는 점입니다. speaking style의 변동성 때문에, 각 speaker를 등록하기 위해선 상당히 많은 양의 data가 필요합니다. 이를 위해 각 speaker에 대한 clean enrollment utterance를 구하는 것이 어렵기 때문에, "만약 face image를 clean speech 대신에 enrollment에 사용하면 안될까?" 라는 질문이 발생하게 됩니다.
합성된 speech의 speaker characteristic을 control하기 위해 face image를 사용하는 연구들이 있었습니다. 해당 연구들은 TTS model과 독립적인 voice encoder와 face identity encoder가 공유하는 joint embedding space를 학습합니다. 이 방식들은 추가적인 speaker adaptation 없이 unseen speaker에 대한 speech를 생성할 수 있습니다. 그러나, 이 연구들은 TTS model을 학습할 때 face image를 input으로 사용하지 않습니다. 대신에, model은 speaker embedding을 input으로 사용합니다. inference할 때만 speaker embedding이 아니라 face image를 input으로 사용합니다.
이 논문에서, 저자들은 강건한 speaker에 대한 characteristic을 제공하기 위해 face image를 사용하는 speech synthesis model인 FACE-TTS를 제안합니다. 이전 연구에서, voice와 face 사이의 강한 correlation이 있음을 증명했었습니다. 이 사실에서 영감을 받아, 저자들은 얼굴 특성을 condition으로 speaking style을 이용하는 multi-speaker TTS model을 제안합니다. 모든 speaker에 대해 enrollment speech segment를 모으는 것이 어렵지만, face image를 얻는 것은 훨씬 쉽습니다. 저자들은 face의 identity와 합성된 speech의 identity를 matching하도록 만들어서 speaking style의 robust한 cross-modal representation을 학습합니다. 저자들의 방식은 speaker enrollment 없이도 speech signal을 생성할 수 있으며, zero-shot or few-shot TTS modeling에서 유리한 방식입니다. 저자들의 TTS model의 backbone은 Grad-TTS를 기반으로 하며, 이는 acoustic feature를 diffusion method로 학습합니다. 다른 face-to-speech synthesis method들과 다르게, Face-TTS는 face encoder와 acoustic model을 end-to-end로 학습됩니다. 저자들이 알기로, face image를 TTS model을 학습하기 위한 condition으로 사용하는 첫 연구입니다. 저자들은 speaker representation에 대한 질적 및 양적 평가를 수행하고, 합성된 음성의 품질도 평가합니다. 또한, 아래 그림과 같이 생성한 목소리가 자신의 목소리가 없는 가상 인간의 외모와 잘 어울리는 지에 대한 평가도 진행합니다.

Related Work
Text-to-Speech
deep neural network의 성공과 함께, 합성된 speech에 대한 지각적 quality는 이전 statistical parametric speech synthesis와 비교했을 때 극적으로 향상되었습니다. 일반적으로, TTS model은 2가지 module로 구성됩니다. acoustic model과 vocoder입니다. acoustic model은 text sequence를 이용해 speech feature (일반적으로 mel-spectrogram)를 생성합니다. vocoder는 feature를 가지고 speech waveform을 생성합니다. 많은 generative modeling method들이 등장했으며, Tacotron based model들은 text sequence를 acoustic representation으로 변환하는 sequence-to-sequence model입니다. GAN based model들은 adversarial training 전략을 이용해 최근 10년 간 TTS에 혁신적인 기여를 해왔습니다. 최근에, diffusion based method라는 새로운 성공적인 generative approach가 등장했으며, diffusion method는 다양한 생성 task에서 뛰어난 모습을 보이고 있습니다. GAN based model과 비교했을 때, diffusion method는 인상적인 결과뿐만 아니라 분포 범위, 고정된 training objective, 확장성 등의 장점이 있습니다.
Audio-visual biometirc
사람들은 경험을 통해 학습되어 본능적으로 다른 사람들의 얼굴 생김새와 그들의 voice를 연관 지어 생각합니다. 왜냐하면 얼굴과 voice는 관련된 identity information을 제공하기 때문입니다. 얼굴과 목소리 사이의 연관성을 학습하기 위해, 이전의 여러 연구들은 사람들이 경험을 통해 학습하는 방식으로 self-supervised method를 이용했습니다. 그 논문들은 single speaker video로부터 구한 face image와 speech segment는 일반적인 identity라는 사실을 이용했습니다. 다른 연구에서는 저자들이 face image를 이용해 input signal을 분류함으로써, visual identity가 speaker identity와 매우 강한 correlation이 있다는 것을 보였습니다. biometric matching을 위해 robust한 cross-modal embedding을 학습하기 위해 cross-entropy loss, contrastive loss, disentanglement-based loss와 같은 다양한 self-supervised loss들이 사용되었습니다. 이전 연구들에서 영감을 받아, 저자들은 multi-speaker TTS model에서 사용할 수 있는 speaker-dependent characteristic을 반영하는 condition을 촉진하기 위해 cross-modal biometric matching을 사용합니다.
FACE-TTS
Score-based Diffusion Model
FACE-TTS는 score-based diffusion model, 특히 Grad-TTS에 기반을 둔 model로 3가지 main part로 구성됩니다. 1) text encoder 2) duration predictor, 3) diffusion model입니다. text transcription C와 그에 대응하는 mel-spectrogram X_0가 train을 위해 주어졌을 때, forward process는 점진적으로 standard Gaussian nooise를 더해갑니다. 다음과 같은 연속 확률 미분 방적식 (SDE)가 됩니다.
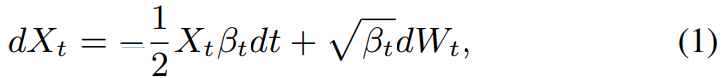
여기서 W_t는 standard Brownian motion이고, B_t는 noise schedule입니다. reverse diffusion process에서, text에 대응하는 X_t로부터 X_0를 얻을 수 있습니다.
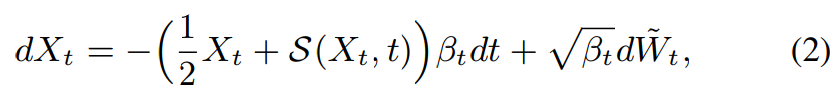
여기서 W_t~는 reverse Brownian motion을 의미하고, S(X_t, t)는 diffusion model입니다. diffusiom model은 noisy data의 log-density의 기울기를 추정합니다. SDE를 이용해 noisy data X_t에서 N번의 step을 걸쳐 speech X_0를 추론할 수 있습니다.
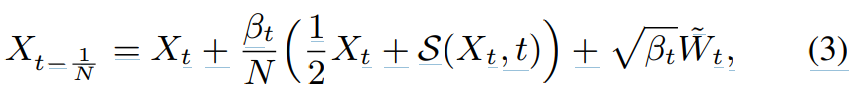
여기서 t ∈ {1/N, ... , 1}입니다. N은 discretised reverse process의 step 수를 의미하고, t는 reverse process의 time step index를 의미합니다. original diffusion과 거의 대부분이 일치하지만, 다른 점들이 존재하긴 합니다. 전체 구조는 다음과 같습니다.
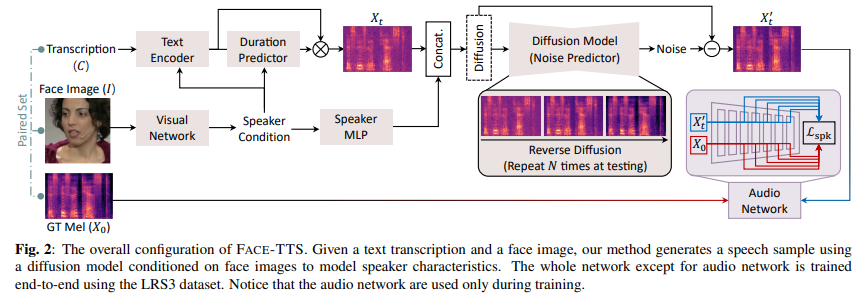
Speaker Conditioning with Cross-modal Biometircs
speaking style을 학습하는 대신 각 speaker에 대한 speaker codebook을 사전에 정의하는 방식으로 진행하는 연구들이 있었습니다. 이 방식들은 새로운 speaker에 대해서는 표현할 수 없다는 문제가 있습니다. 또 다른 연구에서는 speaker embedding이 합성된 음성에서 speaking style을 표현할 수 있음을 보이기도 했습니다. 하지만 여전히 문제로 남아있습니다. speaker embedding은 주로 speaker에 대해 과도한 detail을 표현하기 때문에, TTS의 acoustic modeling을 할 때 불안정한 학습을 유발합니다. 그러므로 speaker embedding은 음성을 합성할 때, speaker voice를 표현하기 위해서 embedding은 일반화되어야 합니다.
이 논문에서 저자들은 face image로부터 identity embedding을 생성하고 이를 multi-speaker TTS model의 conditioning feature로 사용합니다. cross-modal biometric model로부터 구한 face embedding은 voice에 대한 identity를 나타내기 때문에, 얼굴 특성에 맞는 speech를 생성하기에 적합합니다. 이러한 face embedding은 speaker에 대한 복잡한 분포를 포함하고 있지 않고 voice와 face 사이의 연관된 representation만 나타내기 때문에, face embedding은 speaker embedding의 일반화된 상태이며 multi-speaker modelling에 효율적으로 적용할 수 있습니다. mel-spectrogram X = X_0과 face image I가 주어졌을 때, network는 다양한 modality에서 동일한 speaker identity를 연관 지을 수 있도록 pre-train됩니다. 이 network는 audio network F(X)와 visual network G(I)로 구성됩니다.
visual network는 target speaker의 face image를 받아서 speaker representation을 생성합니다. 그리고 text encoder와 duration predictor가 주어진 text transcription과 face image로부터 acooustic feature를 추정합니다. 자세하게는, text encdoer는 text sequence에 맞는 acoustic feature를 생성하고, duration predcition은 target speaker의 예측된 speaking duration을 가지고 feature를 colourise하여 자연스러운 발음을 생성합니다. training 과정에서, diffusion process는 colourised feature에 gaussian noise를 더하여 noisy data를 만들어내며, diffusion model은 target audio를 얻기 위해 noisy data에서 data 분포의 기울기를 추정합니다. 특히, speaker representation은 speaker voice로 합성된 speech를 생성하는 데 최적인 기울기를 추정하도록 만들어줍니다.
하지만 multi-speaker TTS가 다양한 speaker의 characteristic을 학습하기 위해선, TTS model이 각 사람에 대해 충분한 길이의 recorded speech가 필요로 합니다. 여러 명의 speaker가 충분히 긴 utterance로 읽어준 audio book dataset을 가지고 model을 학습시켰던 연구가 있는데, 이 model도 결국은 unseen speaker에 대해서는 일반화 성능이 떨어졌었습니다. 이 문제를 해결하기 위해, 저자들은 speaker feature binding loss를 적용했습니다. speaker feature binding loss는 합성된 음성에서 target voice의 speaker characteristic을 유지할 수 있도록 도와줍니다. 이를 통해 FACE-TTS가 짧은 audio segment로부터 face-voice 연관성을 학습할 수 있도록 만들어줍니다. cross-modal biometric으로 학습된 audio network의 convolution layer로부터 구한 latent embedding은 합성된 speech와 target voice에서 각각 추출됩니다. speaker feature binding loss L_spk은 두 latent embedding의 distance를 의미하며, FACE-TTS model은 두 distance를 minimize하도록 학습됩니다.
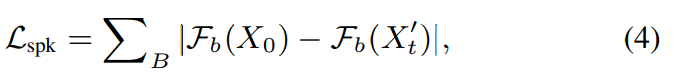
수식으로 나타내면 위와 같습니다. 여기서 X_0는 target speaker의 utterance로 구한 mel-spectrogram을 의미하며, X_t'은 network로부터 denoise된 output을 의미합니다. B는 처음 2개의 convolution block을 제외한 audio network의 covonlution block의 수를 의미합니다. 저자들은 audio network가 이 loss로 인해 update되는 것을 막기 위해 freeze했습니다. 이 학습 방식은 speaker와 관련된 synthesised speech의 latent distribution이 target speech의 speaker와 관련된 latent distribution과 비슷해지도록 만들어줍니다. 즉 audio network의 parameter들은 freeze된 상태로, 두 mel-spectrogram을 audio network에 feed합니다. 각 convolution block에서 latent representation을 추출한 다음 두 embedding의 distance를 loss로 적용하는 방식입니다. 이 loss를 통해 audio network를 제외한 다른 network들이 학습되게 됩니다.
Training & Inference
학습할 때, FACE-TTS는 multiple training loss를 가지고 multi-speaker speech synythesis를 학습합니다. text encoder와 duration predictor를 학습하기 위해, 저자들은 normal distribution의 평균을 추정하기 위해 prior loss를 사용하고 speech와 text sequence의 alignment를 사용해 duration의 pronunciation을 control하기 위해 duration loss를 사용합니다. diffusion loss는 diffusion model이 data distribution의 기울기를 추정할 수 있도록 만들어줍니다. 최종 loss는 다음과 같습니다.
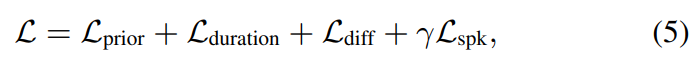
여기서 γ는 1e-2로 설정했다고 합니다. 전체 framework가 end-to-end방식으로 LRS3 dataset으로 학습되었습니다. LRS3가 다양한 각도의 facial representation을 가지고 있기 때문에, FACE-TTS가 좀 더 강건하다고 합니다.
inference에서, 학습된 FACE-TTS는 noisy data X_t로 부터 얻은 utternace X_0의 mel-spectrogram을 sample합니다. 이 X_0의 mel-spectrogram은 target speaker의 face로부터 speaker condition을 얻고 trascription을 추정하여 생성됩니다. reverse diffusion process는 반복적으로 step-by-step으로 noise를 점진적으로 처리합니다. 마지막으로, 서잔 학습된 vocoder를 사용하여 추정된 mel-spectrogram을 raw waveform으로 변환합니다.
Experiments
Experimental Settings
- Dataset
LRS3는 TED video에서 수집된 audio-visual dataset입니다. 그리고 audio-visual pair에 맞는 text transcription도 있습니다. 저자들은 training dataset을 train-val split을 하였으며, evaluation을 위해서도 tset split을 진행했습니다. dataset에서 1.3초보다 짧은 sample들은 제외했다고 합니다. 또한, 저자들은 10초 이상의 audio가 있는 speaker들에 대한 speech sample들만 선택해서 사용했다고 합니다. 그래서 총 14,114개 utterance가 있고 2,007명의 speaker data를 train에 사용했으며, 50개의 utterance를 validation에 사용했습니다. 그리고 test set에는 412명의 speaker가 포함되어 있다고 합니다. LibriTTS와 같이 널리 사용되는 multi-speaker TTS dataset은 각 speaker에 대해 평균적으로 550초의 well-recored audio book이 있는 반면, LRS3는 real-world environment에서 34초 길이의 audio를 추출했다고 합니다. 그러므로 LRS3 data를 이용해 TTS model을 학습하는 것은 상당히 도전적이라고 합니다. 저자들은 이전 연구들과의 공정한 비교를 위해 LJSpeech의 test split (448 samples)을 사용했으며, 분포 외의 text description을 얻었다고 합니다. cross-modal biometric model은 vocoder와 동일한 mel-spectrogram 구성을 따라 재구현되었다고 합니다. cross-modal biometric model은 VoxCeleb2 dataset으로 학습되었으며, dataset은 5,994명 speaker로 구성됩니다.
- Audio and image representation
cross-modal biometric model, TTS model, vocoder를 포함한 network들의 input들은 128차원 mel-spectrogram입니다. 16kHz sampling rate로 62.5ms frame length를 가지고 매 10ms마다 구했다고 합니다. image input에 대해서, face image는 각 video에서 랜덤하게 sample되고 224x224 pixel로 resize되었다고 합니다. cross-modal biometric model (audio and visual network)는 audio와 face image를 512차원 vector로 embed합니다.
- Evaluation protocols
저자들은 HiFi-GAN을 vocoder로 사용하여 generated mel-spectrogram을 audio waveform으로 합성했습니다. 'Mel.+HiFi-GAN"을 이용해 vocoder에 의해 발생하는 품질 저하량을 보였습니다. target speech의 mel-spectrogram을 waveform으로 변환할 때 합성 process 없이 진행했습니다(mel-spectrogram을 가지고 추가적인 합성 과정 없이 waveform을 생성했다는 뜻). ground-truth 결과보다 약간 낮은 점수가 나타나는 것은 자연스럽고, 이는 합성 결과의 upper-bound score가 될 수 있습니다. 저자들은 MOS test를 진행했으며, 이는 합성된 speech의 주관적인 quality를 측정하는 일반적인 방식입니다. 17명의 참여자들에게 점수를 물어봤으며 1~5 사이의 scoring을 진행했습니다. test에서 10개의 utterance를 random하게 test set에서 선택했으며 model을 이용해 합성하는 데 사용했습니다. 추가적으로 2가지 선호도 test를 진행했습니다. 1) AB forced matching test: 1개의 합성된 음성과 2개의 face image를 사용 2) ABX preference test: 2개의 합성된 음성과 1개의 face image를 사용.
저자들의 model을 가상 인간 speech generation에 대해 평가를 하기 위해, 저자들은 image generation model이 생성한 image와 합성된 음성이 잘 어울리는지에 대해 MOS test를 진행했습니다. 1에서 4 사이의 평가 지표를 사용했으며, 높을수록 자연스러운 음성임을 의미합니다. objective 평가를 위해, 저자들은 5-way cross-modal forced matching test (5가지 보기 중 하나를 고르는 방식의 test)를 진행했습니다. cross-modal biometric model을 이용했으며, 합성된 speech와 5개의 face image 중에서 일치하는 identity를 선택하는 방식으로 평가가 진행됩니다. matching test에서, 저자들은 합성된 speech가 face image와 비슷한 identity를 나타내는 것을 입증했습니다.
- Implementation details
비교를 위해, 저자들은 Grad-TTS model을 LibriTTS와 LRS3 dataset으로 학습했습니다. 또한, 저자들의 FACE-TTS를 audio input과 face input으로부터 구한 identity embedding으로 학습했습니다. 각 embedding은 cross modal biometric을 이용해 구했습니다. visual network는 pre-trained weight (biometric matching task on VoxCeleb2)로 초기화되기 때문에, 저자들은 초기 learning rate를 작게 설정했습니다. audio network와 visual network를 제외한 다른 network들은 처음부터 학습했습니다. computation time과 flops은 선형적으로 증가되지만, denoising step이 늘어날수록 audio quality가 좋아집니다. 따라서, 저자들은 inference할 때 10번 denoising step과 sampling step을 사용하여 speech signal을 생성합니다.
Results
- Audio quality
저자들은 multi-speaker TTS를 위해 LibriTTS dataset으로 학습한 pre-trained Grad-TTS의 parameter를 사용해 비교를 진행했습니다. 초기 실험에서, 저자들은 LRS3 dataset으로 학습된 Grad-TTS가 경쟁력 있는 quality를 보인다는 것을 알아냈습니다. 그래서, 저자들은 LibriTTS로 학습된 Grad-TTS를 비교 평가했고 Grad-TTS가 생성한 audio를 22.05kHz에서 16kHz로 resample했습니다. FACE-TTS는 visual network 대신에 cross-modal biometric의 audio network와 speaker ID를 이용해 학습되었습니다.
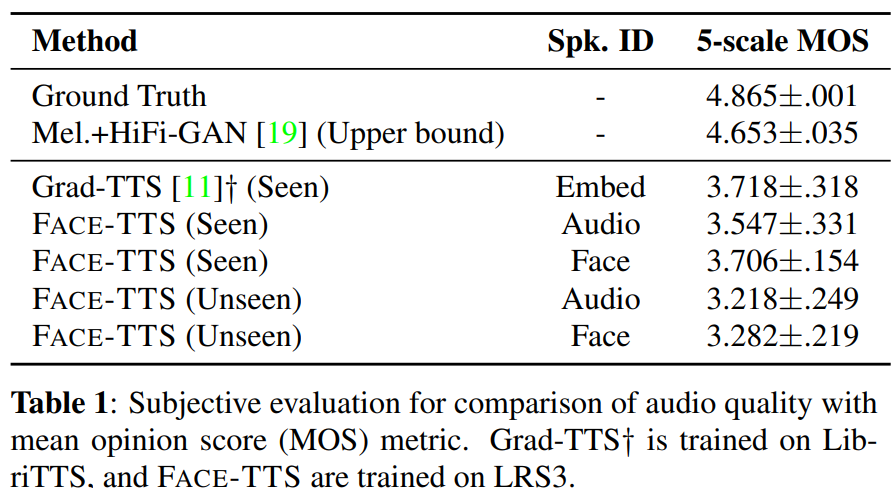
위 표는 FACE-TTS가 face image를 사용하는 것이 seen speaker condition에서 clean speech dataset으로 학습된 Grad-TTS와 비교 가능할 정도의 성능을 보이는 것을 볼 수 있습니다. FACE-TTS가 unseen speaker condition에서도 꽤나 괜찮은 성능을 보이는 것을 볼 수 있습니다. 그리고 face condition을 사용하거나 audio condition을 사용할 때 model의 performance가 거의 차이가 없다는 것도 볼 수 있습니다. audio conditioned model과 비교했을 때, face image가 recording environment에 영향을 받는 audio와 비교하여 robust한 identity를 만들어내기 때문에 face conditioning model이 더 세밀한 audio quality를 제공했다고 합니다.
- Speaker verification
저자들은 generated utterance와 face image를 사용해 speaker verificaiton task에 대해 평가를 진행했습니다. 먼저, AB와 ABX 선호도 tset는 사람 평가로 측정되었습니다. 더 도전적인 상황에서 평가를 하기 위해, 저자들은 성별을 일정하게 설정한 다음 실험을 진행했습니다. 즉 선택된 두 case의 audio 또는 audio는 같은 성별의 sample에서 선택되었습니다.

위 그래프에서 볼 수 있듯이, 평가자들은 약 60% 정도의 correct answer rate를 보여줍니다.

위 표는 LRS3 dataset에 대한 objective 평가를 진행한 5-way cross-modal speaker matching accuracy를 보여주고 있습니다. LRS3로 학습된 Grad-TTS는 저자들의 model과 비교가능할 정도의 audio quality를 보여주지만, speaker embedding을 이용해 speaker의 characteristic을 capture하는 성능은 좋지 않은 것을 볼 수 있습니다. 그리고, 저자들의 speaker loss는 matching performance를 2.6% 향상시키는 것을 볼 수 있습니다. 물론 Mel.+HiFi-GAN에 비해 성능이 좋지는 않습니다.
- Virtual speech generation
FACE-TTS의 유용성을 입증하기 위해, 저자들은 image generation model이 생성한 virtual face image를 이용해 음성을 합성했습니다.

위 표는 subjective evaluation 결과입니다(1=Bad, 2=Neutral, 3=Good, 4=Excellent). baseline으로, 저자들은 LRS3 dataset에서 random하게 선택한 ground-truth face-voice pair를 이용해 평가를 진행했습니다. 놀랍게도, 사람들은 평균적으로 'Good' score를 주었는데, 저자들의 FACE-TTS가 생성한 음성이 virtual face image와 잘 맞기 때문입니다.
Conclusion
이 논문에서, 저자들은 multi-speaker text-to-speech synthesis model인 FACE-TTS를 제안합니다. FACE-TTS는 face image를 이용해 speaker identity를 condition으로 하는 model입니다. FACE-TTS는 face image로부터 speaker characteristic를 구하기 위해 cross-modal biometric을 이용했으며, diffusion-based TTS model을 통해 음성을 합성했습니다. 두 module을 동시에 학습시키기 위해, 저자들은 speaker feature binding loss를 이용해 합성된 speech와 reference speech 사이의 speaker 일관성을 유지하도록 만들었습니다. FACE-TTS는 target speaker의 voice를 잘 표현하는 고품질의 audio를 생성합니다.



