https://www.isca-archive.org/interspeech_2020/goto20_interspeech.html
ISCA Archive
An Early Study on Intelligent Analysis of Speech Under COVID-19: Severity, Sleep Quality, Fatigue, and Anxiety Jing Han, Kun Qian, Meishu Song, Zijiang Yang, Zhao Ren, Shuo Liu, Juan Liu, Huaiyuan Zheng, Wei Ji, Tomoya Koike, Xiao Li, Zixing Zhang, Yoshiha
www.isca-archive.org
해당 논문을 보고 작성했습니다.
Abstract
보통 사람 얼굴을 보고 speaker의 voice characteristic을 상상할 수 있습니다. 이 논문에서 저자들은 Face2Speech를 제안하는데, 이는 face image로부터 characteristic을 예측하고 이에 맞는 speech를 생성해 주는 model입니다. 이 framework는 분리되어 학습되는 3가지 구성요소가 있습니다: speech encoder, multi-speaker text-to-speech (TTS), face encoder입니다. speech encoder는 다른 speaker들과 구분 가능흔 embedidng vector를 생성합니다. multi-speaker TTS는 embedding vector를 이용해 speech를 합성하며, face encoder는 speaker의 얼굴 사진으로부터 speaker의 embedding vector를 output합니다.
Introduction
이 논문은 audio/visual cross-modality에 대한 더 나은 이해를 제공하려고 시도합니다. 이 논문은 특히 text-to-speech (TTS) 합성에 focusing합니다. 저자들은 facial feature를 DNN-based multi-speaker TTS framework에 적용하여 speaker의 embedding vector를 이용해 speaker의 목소리를 합성하고자 합니다. facial feature를 TTS에 적용하는 것은 몇 가지 이점이 있습니다. 예를 들어 speaker의 visual information을 기반으로 합성된 voice의 speaker를 직관적으로 구분할 수 있습니다. 만약 vocal feature를 이용한다면 speaker의 voice sample을 듣는 데 시간이 걸리고 시각화하기 어렵습니다. 게다가 facial feature는 single speaker의 speaking style도 자연스럽게 control하는 수단을 제공할 수 있습니다(e.g., emotional TTS). 그리고 vocal feature와 facial feature 사이의 관계를 학습하고 나면, voice searching system과 같은 다른 관련된 application에 적용할 수 있습니다.
이 논문에서는, DNN-based multi-speaker TTS framework인 Face2Speech를 제안합니다. 이는 face image를 이용해 합성된 speech의 voice characteristic을 control합니다. 이러한 TTS framework를 구현할 때 가장 어려운 부분 중 하나는 training dataset을 모으는 것입니다. (text, speech, face image) 이 3가지를 충분한 양으로 가지고 있는 dataset은 없으며, dataset을 구축하는 것 또한 어렵습니다. 그러므로, 저자들은 2가지 종류의 dataset을 사용합니다. (text, speech) 쌍, (face image, speech) 쌍을 이용해 framework의 3가지 module (speech encoder, multi-speaker TTS, face encoder)을 분리하여 학습합니다. speech encoder는 speech로부터 embedding vector를 추출하도록 학습됩니다. 이때 speaker verification loss를 사용하여 이를 minimize하는 방식으로 학습됩니다. multi-speaker TTS는 (text, speech) 쌍을 가지고 학습되기 때문에, module은 주어진 text와 pre-trained speech encoder로부터 얻은 embedding vector를 가지고 speech를 합성합니다. face encoder는 (face image, speech) 쌍을 가지고 학습되는데, 이는 speaker의 face image로부터 embedding vector를 추출하며, 이 vector가 실제 embedding vector와 더 가까워지도록 학습합니다. 마지막으로, face encoder와 multi-speaker TTS를 결합하여 Face2Speech model을 구현합니다.
Face2Speech Model
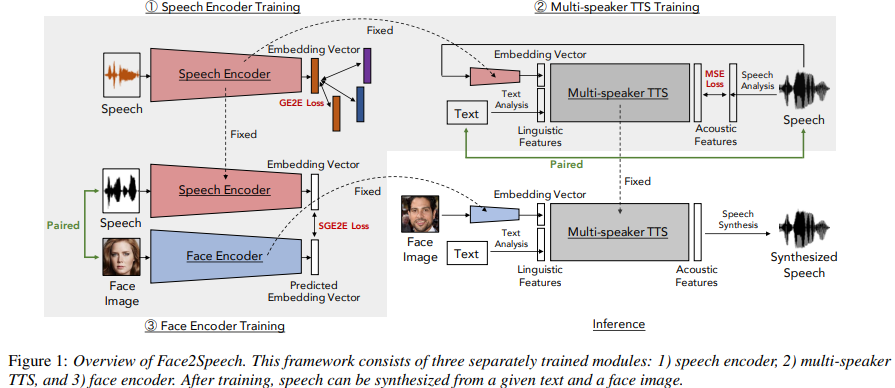
위 그림과 같이 3가지 module이 Face2Speech model에 존재하며, 분리되어 학습됩니다. speech encoder는 speech로 학습되고, mutli-speaker TTS는 (text, speech) 쌍으로 학습되고 face encoder는 (face image, speech)로 학습됩니다.
Speech Encoder
speaker의 characteristic을 capture하는 embedding vectors는 speaker verification에서 사용되어 왔습니다. 저자들의 framework에서 speech encoder는 "Generalized end-to-end loss for speaker verification"에서 제안한 방식을 사용합니다. log-Mel spectrogram은 speech encoder에 feed되고 encoder는 embedding vector를 추출합니다. speech encoder를 학습할 때, 각 mini-batch는 M x N utterance로 구성됩니다. N명의 다른 speaker가 M개의 utterance를 말하는 형태입니다. embedding에 L2 normalization을 적용한 후, j번째 speaker의 i번째 utterance는 e_ji로 표현합니다 (1<= j <= N, 1<= i <=M). j번째 speaker의 중앙 embeedding vector는 c_j = 1/M*∑(e_jm)로 정의됩니다. similarity matrix의 element S = (S_ji,k)가 됩니다. 이 similarity matrix는 cosine similarity를 이용해 구해지는데 식은 다음과 같습니다.

w와 b는 학습가능한 scalar parameter입니다. similarity matrix S를 사용함으로써, generalized end-to-end loss (GE2E) function을 speech encoder를 학습할 때 사용할 수 있습니다. 식은 다음과 같습니다.

loss function은 동일한 speaker의 embedding vector들의 cosine similarity는 크게, 다른 speaker면 작게 만들어줍니다.
Multi-speaker TTS
duration model과 acoustic model로 구성된 multi-speaker TTS model을 사용합니다. duration model은 phoneme마다 구한 linguistic feature vector와 utterance마다 구한 embedding vector를 이용해 frame 수를 output합니다. 여기서 embedding vector는 speech encoder를 통해 구합니다. acoustic model은 frame마다 linguistic feature와 embedding vector를 이용해 acoustic feature (i.e., Mel-cepstral coefficients (MCEPs), log F_0, ...)를 만듭니다. 두 model은 target feature와 model의 output vector의 MSE loss를 minimize하는 방식으로 학습됩니다.
Face Encoder
저자들은 face image, speech pair를 준비해 face encoder를 학습할 때 사용합니다. face encoder의 input은 speaker의 face image이고 output은 speaker의 utterance를 통해 추출된 embedding vector의 center입니다. face encoder의 loss function으로 가능한 선택으로 MSE loss가 있습니다. speech encoder의 embedding vector가 cosine similarity를 minimize하도록 학습되었기 때문에, MSE loss를 minimize하도록 학습된 face encoder가 target speaker의 embedding vector와의 cosine similarity를 minimize하는 embedding vector를 output하는 것을 보장하지는 않습니다. 그렇기 때문에 저자들은 face encoder에 다른 loss function을 적용합니다. M을 mini-batch에 있는 speaker의 utterance수를 의미하고, M~이 speaker의 모든 utterance 수를 의미한다고 하겠습니다. speech encoder에서는 j번째 speaker의 centroid를 각 mini-batch에 대해서 구했지만, face encoder에서의 centroid는 speech encoder의 output을 통해 구합니다. c~_j = 1/M~ * ∑(e_jm)이 됩니다. 이 값은 각 mini-batch마다 일정한 값이 됩니다. 그렇기 때문에 face encoder의 similarity matrix는 다음과 같이 정의됩니다.
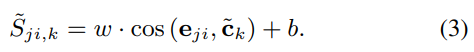
similarity matrix가 주어지면, loss function은 (2)와 같은 형태로 구해집니다. face encoder를 학습하는 것은 supervised-learning으로 가능하기 때문에, 저자들은 이 loss function을 supervised GE2E loss (SGE2E loss)로 부릅니다. 즉 위 식에서 e_ji는 face encoder가 구한 embedding을 의미하는 것 같고, c~_k와의 cosine similarity를 구해서 이를 minimize하는 방식으로 학습됩니다.
Experiments
Dataset
VoxCeleb2와 VGGFace2를 이용해 face iamge와 speech pair를 얻었습니다. VoxCeleb2는 Youtube에서 6000명 이상의 유명읜 video로 구성된 dataset입니다. VGGFace2는 VoxCeleb2로 identity가 overlap된 image dataset입니다. face image와 speech pair를 이용해 face encoder를 학습하기 때문에, face image와 그에 대응하는 video dataset에서 얻은 speech를 가지고 학습할 수 있었습니다. 하지만 많은 video가 저화질이기 때문에, cropping error가 자주 발생했습니다. 추가적으로 crop된 face image는 original face에 비해 detail이 부족하기 때문에, 이 croppped face image를 가지고 feature를 추출하기엔 적합하지 않았습니다. VGGFace2로부터 VoxCeleb2보다 더 고화질의 face image를 얻을 수 있었습니다. 그래서 저자들은 VGGFace2로부터 face image를 얻고 VoxCeleb2로부터 speech를 얻었습니다. 저자들은 5993명의 image와 speech를 training하는 데 사용했고, 118명의 data를 evaluation에 사용했습니다.
VCTK와 LibriTTS는 text와 speech pair로 사용되어집니다. VCTK에서 108명 speaker의 utterance를 사용했고 LibriTTS에서는 805명 speaker의 utterance를 가져와 사용했다고 합니다. 847명 speaker의 utterance는 training에 사용되었고, 66명의 utterance는 evaluation에 사용되었다고 합니다. VCTK와 LibriTTS는 VoxCeleb2보다 더 깨끗한 음성 dataset을 가지고 있습니다. 모든 speech sample들은 16kHz로 downsampling하여 사용했다고 합니다.
Experimental Conditions
- Speech Encoder
window length는 400(25ms), hop size는 160(10ms), FFT는 512(64ms) sample로 했다고 합니다. 40차원 Mel-spectrogram을 input으로 사용하여 256차원 embedding vector를 ouput으로 했다고 합니다. speech encoder는 768개의 hidden unit을 가지고 있는 3개 LSTM layer로 구성되고, 뒤에 256개 unit의 linear output layer가 있습니다. activation function으로는 tanh를 사용했다고 합니다. 각 mini-batch마다 32명의 speaker와 각 speaker의 utterance 수는 4로 설정했다고 합니다. training epoch는 500으로 설정했으며 Adam optimizer를 사용했다고 합니다.
- Multi-speaker TTS
420차원의 phoneme-wise linguistic feature vector(e.g., phoneme identity and accent type)와 speech encoder로부터 얻은 256차원 embedding vector를 duration model에 feed합니다. 저자들은 WORLD vocoder를 이용해 acoustic feature를 extract합니다. acoustic feature는 40차원 MCEP, log F_0, aperiodic measure, 그리고 이 값들의 미분한 값과 두 번 미분한 값으로 구성됩니다. 그리고 매 5ms마다 voiced/unvoiced flag도 acoustic feature로 사용했습니다. 최종 acoustic feature는 127차원입니다. 각 frame마다의 linguistic feature와 embedding vector의 결합 vector는 acoustic model에 feed됩니다.
static feature와 dynamic feature의 명시적 relation을 이용하여 acoustic sequence transition을 생성합니다. WORLD vocoder는 생성된 acoustic feature를 이용해 speech waveform을 합성합니다. duration model과 acoustic model의 input은 [0.01, 0.99] 사이로 normalize되며, output은 zero mean unit variance로 normalize됩니다. embedding vector는 각 utterance마다 average됩니다. duration과 acoustic model은 512개 hidden unit를 가진 3개 bi-directional LSTM layer으로 구성됩니다. hidden layer의 activation function으로 tanh를 사용했고, training epoch은 40으로 설정했다고 합니다.
- Face Encoder
face image의 input size는 160 x 160으로 scale하여 사용한다고 합니다. 각 pixel 값들은 [-1.0, 1.0]으로 normalize된다고 합니다. flip transformation을 이용해 data augmentation을 진행했습니다. VGGFace2에서 face image를 추출하기 위해 pretrained face detection model을 사용했다고 합니다. face를 detect하지 못한 image들은 사용하지 않았다고 합니다. speech encoder에서 얻은 embedding vector들은 동일한 speaker에 대한 모든 utterance의 평균을 구할 때 사용됩니다. VGG19 network architecture를 이용해 Face encoder를 구현했다고 합니다. 124차원 training epoch을 사용했으며, adam을 사용하여 학습했다고 합니다.
Investigation into effects of datasets on training speech encoder
speech encoder는 text를 사용하지 않고 speech를 speaker identity로 mapping하는 model입니다. 다양한 dataset을 사용하여 speech encoder를 학습할 때, dataset 간 environment 차이가 합성된 speech의 품질에 부정적인 영향을 주지 않으며, 원래 음성과의 유사성에도 부정적인 영향을 주지 않는다는 연구가 있었습니다. 그러나 저자들이 제안한 method에서는, TTS model을 학습할 때 사용하는 dataset과 face encoder model을 학습할 때 사용하는 dataset이 다르기 때문에 multiple dataset을 사용할 때 주의를 기울어야 했습니다. 저자들은 초기 실험에서 두 가지 speech encoder에 대한 실험을 진행했다고 합니다: VoxCeleb2, VCTK, LibriTTS로 학습된 speech encoder, VoxCeleb2만 사용해 학습된 speech encoder입니다.

위 그림에서 (a)는 VoxCeleb2, VCTK, LibriTTS로 학습된 speech encoder로 추출한 embedding vector를 보여주고, (b)는 VoxCeleb2로만 학습된 speech encoder로 추출한 embedding vector를 보여줍니다. 두 encoder로 추출한 feature들은 성별을 기준으로 서로 다른 cluster를 구성하는 경향을 볼 수 있습니다. (a)를 보면 dataset의 차이에 따라 cluster가 embedding space에서 구성되는 것을 볼 수 있으며, 그다음 성별에 따라 나눠지는 것을 볼 수 있습니다. 반면에, VoxCeleb2로만 학습된 speech encoder의 경우 오직 성별에 따라서만 clustering되는 것을 볼 수 있습니다. 즉 speech encoder가 speaker identity 뿐만 아니라 dataset identity도 capture하는 것을 볼 수 있습니다. 즉 Face2Speech는 speech encoder를 통해 서로 다른 dataset으로 학습되는 multi-speaker TTS를 사용하는데, 이는 부정적인 영향을 줄 수 있음을 의미합니다. 그렇기 때문에 저자들은 VoxCeleb2만 이용해 speech encoder를 학습하여 사용합니다.
Evaluation
저자들이 제안한 method와 비교할만한 conventional method가 존재하지 않기 때문에, 저자들은 SYNTH-SPEECH와 SYNTH-FACE라는 두 가지 frame work system을 준비하여 음성을 합성했다고 합니다. 평가를 위해, 저자들은 test speaker dataset을 사용했다고 합니다. 두 system이 embedding vector를 만드는 방식에 차이가 있습니다. SYNTH-SPEECH의 embedding vector는 speaker의 utterance에 speech encoder를 적용해 구하는 방식이고, SYNTH-FACE는 speaker의 face image를 이용해 face encoder로부터 embedding을 추출하는 방식입니다. face encoder는 speech encoder의 embedding vector와 face encoder의 output vector 사이의 SGE2E loss를 minimize하는 방식으로 학습되기 때문에, SYNTH-SPEECH가 framework의 upper-bound로 여길 수 있습니다.
- Visualization of embedding space
저자들은 평가를 위해 embedding vector의 PCA visualization을 진행했다고 합니다. 결과는 다음과 같습니다.

natural speech로부터 추출한 embedding vector와 SYNTH-FACE의 speech로부터 추출한 embedding vector와 SYNTH-SPEECH의 speech로부터 추출한 embedding vector를 visualization한 결과입니다. SYNTH-FACE가 구한 각 speaker의 point들은 SYNTH-SPEECH의 point들과 필수적으로 근처에 위치할 필요는 없지만, SYNTH-FACE는 natural speech나 SYNTH-SPEECH의 point들과 근처에 존재하는 것을 볼 수 있습니다. 그리고 SYNTH-FACE는 SYNTH-SPEECH만큼 다양한 합성된 speech를 생성할 수 있습니다.
- Matching evaluation
speaker의 face image로 추출된 embedding vector를 사용하여 합성된 speech가 face image와 잘 matching하는 지 평가했습니다. 저자들은 matching evaluation test를 진행합니다. 저자들은 20개의 pair sample을 준비하고 합성한 음성이 face image와 얼마나 잘 match하는 지 평가를 진행했습니다. 점수는 1~4입니다(1: match well, 2: match moderately, 3: match slighty, 4: not match). 결과는 다음과 같습니다.
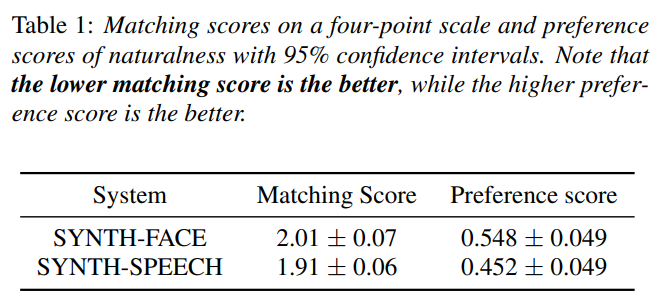
SYNTH-FACE score가 SYNTH-SPEECH보다 약간 더 높은 것을 볼지만, 두 system의 상당한 차이가 존재하는 것은 아닙니다. 이 결과는 face image를 이용해 구한 embedding vector가 face와 잘 match하는 뿐만 아니라 speech를 이용해 구한 embedding vector를 이용해 합성한 speech만큼 잘 일치한다는 것을 의미합니다.
- Naturalness evaluation
합성된 음성의 자연스러움을 평가하기 위해 AB 선호도 test를 진행했습니다. 30명의 listener들이 평가에 참가했습니다. 각 listener들은 두 system으로 합성된 speech sample 10쌍을 듣고 어떤 것이 더 자연스러운 지 선택했습니다. 위 표에서 마지막 열을 보면 자연스러움에 대한 평가 결과가 있습니다. SYNTH-FACE 결과와 SYNTH-SPEECH와 큰 차이가 없다는 것을 볼 수 있습니다. face image만 이용하여 얻은 결과를 통해, voice sample로부터 합성한 speech만큼 자연스러운 speech를 생성할 수 있음을 보여줍니다.
Conclusion
저자들은 Face2Speech라고 불리는 DNN-based multi-speaker TTS freamwork을 제안했습니다. Face2Speech는 single face image를 이용하여 합성된 speech의 speaker identity를 control합니다. matching test와 naturalness test의 결과는 Face2Speech model이 speech로부터 얻은 embedding vector를 이용하는 multi-speaker TTS model과 비교할만한 성능을 보인다는 것을 입증합니다.



