https://arxiv.org/abs/2303.00091
Improving Medical Speech-to-Text Accuracy with Vision-Language Pre-training Model
Automatic Speech Recognition (ASR) is a technology that converts spoken words into text, facilitating interaction between humans and machines. One of the most common applications of ASR is Speech-To-Text (STT) technology, which simplifies user workflows by
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
Automatic Speech Recognition (ASR)은 spoken word를 text로 변환하는 기술을 의미합니다. 가장 최근의 ASR application 중 하나는 Speech-To-Text (STT) 기술이며, 이는 sopken word를 text로 transcribing하는 방식입니다. 의료 분야에서 STT는 의사가 음성 녹음을 타이핑하는 사람에게 존재하는 업무 부담을 크게 줄일 수 있는 잠재력을 가지고 있습니다. 그러나 medical domain에서의 STT model 발전은 speech와 text dataset이 부족하기 때문에 어렵습니다. 이 문제를 해결하기 위해, 저자들은 medical-domain text correction method를 제안합니다. Vision Language Pre-training (VLP) method를 이용해 general STT system의 output text를 수정하는 방식입니다. VLP는 image 지식을 기반으로 text를 맞추기 위해, textual information과 visual information을 결합합니다.
Introduction
Automatic Speech Recognition (ASR)은 machine이 spoken language를 인지하고 text로 변환하는 것을 가능하게 하는 기술입니다. speech pattern을 분석함으로써, ASR은 spoken word를 text로 transcribe합니다.
ASR의 가장 유명한 application은 STT model이며, 이는 실시간으로 speech를 text로 transcribe합니다. 전통적으로, Hidden Markov Models (HMMs)와 Gaussian Mixture Models (GMMs)와 같은 확률 model은 speech를 text로 변환하는 데 사용되었습니다. deep learning framework에서의 최근 발전은 정확도를 향상시키고 복잡한 STT model을 가능하게 만들었으며, 복잡해진 만큼 performance가 향상되었습니다. 예를 들어 open source STT model 중 하나는 RNN을 사용해 sequential model을 구현하며, low latency and high fidelity로 speech를 text로 변환할 수 있습니다. Facebook은 높은 정확도를 보이는 효율적인 STT model (wav2letter, wav2letter++)을 제안했습니다. 이는 CNN을 이용해 speech signal의 feature를 추출하며 RNN을 이용해 sequential 구조를 구현했습니다. Google은 실시간으로 spoken language를 written text로 변환하는 cloud-based Speech-to-Text API를 제공합니다. Microsoft는 대규모 dataset으로 학습된 cloud basd Azure STT service를 제공합니다. 이 외에도 Kaldi와 Julius와 같이 널리 사용되는 대표적인 음성 인식 도구 kit가 있으며, 확률 모델 또는 neural network와 languag eprocessing module을 기반으로 다양한 음성 인식을 지원합니다.
의료 STT application은 일반적으로 medical dictation을 written text로 transcribe하는 데 사용됩니다. 이를 통해 작업의 효율성을 높일 수 있습니다. 하지만, powerful medical STT application을 구현하는 것은 몇 가지 기술적 한계 때문에 어렵습니다. medical 용어와 언어는 복잡하고 애매할 수 있으며, STT model은 해당 단어들을 정확하게 변환하기엔 지식이 부족할 수 있습니다. 그러므로, general language로 학습된 STT model들은 medical 분야에서는 잘 동작하지 않을 수 있습니다. 추가적으로 STT model은 특정 medical domain으로 학습되거나 adapt되어야 하며, 이는 추가적인 시간이 걸리고 resource를 사용해야만 합니다. 그리고 medical dataset은 privacy하고 보안 문제가 있어서 사용하기 힘들 수 있습니다.
하지만 self-supervised learning (SSL)의 발전 덕분에 vision language pretrained (VLP) model이 연구되었습니다. 이는 vision information과 speech information의 공유된 의미 정보를 학습하려는 목표를 가지고 있으며, 향상된 representation을 제공할 수 있습니다. 또한 VLP model은 다양한 meldical 분야에서 사용되고 있습니다.
이러한 성공에서 영감을 받아, 저자들은 pretrained VLP method로 일반적인 언어로 학습된 STT model의 output을 수정함으로써 medical domain에서의 STT model의 성능을 향상시킬 수 있는 Multi-modal Medical Speech Module (MMSM)을 제안합니다. 구체적으로 이 방법은 text의 개념뿐만 아니라 시각적 의미를 활용하여 multi-modal의 이해를 활용합니다. 저자들이 제안한 method가 Medical Speech Module (MSM)에 대해서 좋은 성능을 보인다는 것을 실험을 통해 증명했으며, textual information뿐만 아니라 시각적 의미를 사용하는 것이 효과적임을 보입니다.
저자들의 contribution은 다음과 같습니다.
- 다양한 STT system에서 자유롭게 사용될 수 있는 text correction을 제안합니다. 이 방법은 의료 분야에 특화되도록 설계되었습니다.
- 저자들의 방식은 common language로 학습된 어떠한 STT system을 사용해도 상관없습니다.
- 존재하는 method들과 대조적으로, 제안한 method는 시각적 의미를 활용하여 STT module에서 text를 의미 있는 방식으로 수정합니다.
Background
Vision-languag emodels in medical imaging
deep learning model의 최근 발전은 다양한 task에서 뛰어난 성공을 보였지만, 해당 model의 전문성은 특정 domain에 한정되어 있습니다. 예를 들어, AI기반 computer-aided diagnosis (CAD) model은 경험이 많은 인간보다 뛰어나지만, medical image의 의미 있는 시각적 의미를 medical report에 있는 keyword로 연관시키는 능력이 부족합니다. 하지만 이는 전문적인 사람에게는 매우 간단한 task입니다.
시각적 의미와 언어적 이해 사이의 차이를 해결하기 위해, VLP가 등장했습니다. 전통적인 학습 방법(손으로 작성된 data-label pair의 pattern을 이해하도록 model을 학습하는 방식)과 다르게, VLP는 model이 image와 text 사이의 relationship을 바로 학습하도록 만들어줍니다. 전문가가 annotation을 만드는 것은 비싸고 얻기 힘든 medical imaging 분야에서 특히 효과적입니다.
다양한 연구는 medical domain에서 VLP가 성공적으로 적용되었음을 보여주며, VL pre-trained model이 report generation과 vision-question answering을 포함한 다양한 task에서 가장 좋은 성능을 보였습니다. 하지만, 이는 written text와 medical image사이의 관계에 대한 것으로 제한되며, speech와 image를 사용하는 vision-language model에 대한 연구는 아직 조사되지 않았다고 합니다.
STT model for medical domain
STT system은 spoken language를 written text로 변환합니다. 과거에는 HMM이나 GMM과 같은 확률 모델을 활용하여 speech를 transcribe했지만, 해당 model들은 많은 양의 annotated dataset을 필요로 하고 복잡한 speech signal에 취약하다는 한계가 있었습니다.
최근에는 deep learning framework가 STT의 유망한 성능을 보여주고 있습니다. RNN과 DNn은 널리 사용되며, CNN은 feature extraction에서 아주 뛰어난 성능을 보여주고 있습니다. self-attention 기반 transformer 구조는 성능을 더욱 향상시켰으며, model이 language representation을 포함하도록 학습시키는 SSL은 적은 수의 dataset과 적은 양의 computational resource를 가지고도 혁신적인 성능을 제공합니다. wav2vec과 wav2vec2.0과 같은 pre-trained language model은 10분 정도 길이의 labeled data만 가지고 fine-tuning했을 때 좋은 성능을 보여줍니다.
반면에 medical STT model은 deep learning을 사용해 발전되었지만, 의료 전문 언어의 복잡성과 annotated data set이 부족함 때문에 어려움을 직면했습니다. 이러한 한계에도 불구하고, 어떤 연구에서는 logistic regression과 conditional random field model을 사용한 error detection 및 reformulation을 제안했습니다. Google ASR system을 domain에 맞춰서 text를 수정하는 시도도 있었습니다. IBM Watson, Google, Amazon과 같은 회사들은 medical-specific STT service를 제공하고 있습니다. general domain STT model과 대조적으로, medical specific STT model은 다른 medical domain pre-trained model과 synergy를 내는 데 어려움이 있습니다.
Main Contribution
VLP-basd STT Correction Model
vision-language pre-trained model은 image feature와 text feature의 이해와 둘 사이의 관계를 이해하고 있어, MMSM model 개발을 위한 이상적인 baseline으로 작용합니다. MMSM model은 textual task의 정확도를 향상시키기 위해 시각적 의미를 사용할 수 있습니다.
저자들은 image-report data 쌍과 medical X-VL을 VL pre-trained baseline으로 사용하여, multi-modal model을 생성하기 위해 VLP를 사용합니다. X-VL model의 구조와 학습 목표는 다음과 같습니다.

model은 cross-attention을 사용하여 image와 text의 포괄적인 representation을 얻고, x자 cross attention을 사용하여 image에서 text로, text에서 image로의 융합을 번갈아 가며 처리합니다. 각 uni-modal encoder에서 image feature와 text feature 사이의 유사도를 향상시키기 위해 cross-modal contrastive (CMC) learning과 intra-modal contrastive (IMC) learning을 수행하여 image feature와 text feature가 동일한 embedding space에 존재하도록 만들었습니다. 이는 image feature와 text feature를 key/value, query로 반복적으로 번갈아가며 적용하여 제한된 data pair를 가지고도 model이 더 효율적으로 학습할 수 있도록 만들었습니다.
VLP model은 5개의 learning objective를 가지고 최적화되는데, masked language modeling (MLM), masked image modeling (MIM), cross-modal contrastive (CMC) loss, intra modal contrastive (IMC) loss, image-text matching (ITM) loss입니다. 저자들은 momentum distillation과 hard negative mining 전략을 사용합니다. 이를 통해 VLP model의 전반적인 성능을 효과적으로 향상시켰습니다. 추가적으로, 저자들은 성능을 향상시키기 위해 MLM 과정에서 medical subheading (MeSH) keyword weighted masking을 사용했습니다.
VLP network 구조는 ViT-S/16를 visual encoder로 사용합니다. 해당 encoder는 12개의 layered transformer이며, 12개의 attention head를 가지고 있으며, 첫 6개 layer는 text encoder로 사용되며 뒤 6개 layer는 fusion encoder로 사용됩니다. 저자들은 model의 vision representation과 language representaiton을 향상시키기 위해 X-attention과 momentum teacher model을 사용했습니다.
MMSM model은 vision-question answer model을 사용합니다. MMSM model은 image와 error가 있는 report를 input으로 받으며, report를 수정하여 output합니다. 구조는 다음과 같습니다.
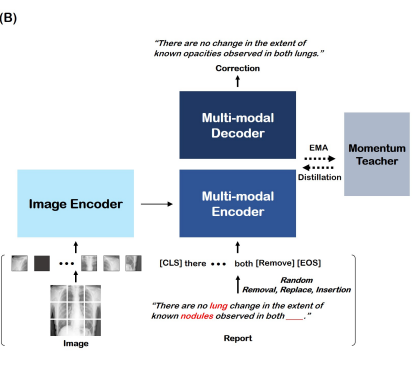
저자들은 VLP와 동일한 visual encoder를 사용하며, text encoder의 첫 6개 layer는 cross attention이 있는 multi-modal text encoder로 사용했습니다. multi-modal representation은 corrected report를 output하기 위해 multi-modal decoder가 사용합니다. 아래 그림은 uni-modal transformer encoder-decoder 구조를 이용하여 text 정보만으로 speech module을 구현한 방식입니다.

MMSM model training
MMSM model은 auto-regressive language modeling objective와 pre-trained VLP model을 활용하여 fine-tune되었습니다. model은 이전 word들의 sequence가 주어졌을 때, 그다음 단어를 예측하도록 학습되었으며, albel과 predicted next work 사이의 cross-entropy loss를 minimize하는 방식으로 학습되었습니다. [CLS]는 sequence의 시작을 의미하는 token이며, [SEP] token에 도달할 때까지 network는 계속 생성합니다.
그리고 저자들은 다양한 음성 손상 사례를 모방하는 자체 training 전략을 개발했습니다. 구체적으로, 저자들은 3가지 전략을 사용합니다. 1) speech를 놓친 상황을 가정하기 위해 random하게 단어를 제거 2) STT model의 잘못된 이해를 가정하기 위해 단어를 random하게 replace 3) token 분할을 가정하기 위해 단어를 random하게 삽입. 이렇게 3가지입니다. 다음과 같습니다.

각 iteration에서, removal, replacement, insertion의 확률은 50%에서 90% 사이로 random하게 정해집니다. 추가적으로, 저자들은 각 sentence에서 처리된 단어의 비율은 50%로 고정시켰습니다. 저자들은 가장 성능이 좋은 parameter를 선택했습니다. 이러한 기술들은 training dataset에서 합성 error를 생성하기 위해 사용되며, MMSM이 error를 수정하는 데 더 효율적이게 만들어줍니다. 점진적으로 합성 error의 복잡성을 증가시킴으로써, 저자들은 MMSM의 robustness를 향상시켰으며 real-world error를 correcting하는 성능을 향상시켰습니다.
Implementation Details
Dataset
VLP model을 학습하기 위해, MIMIC-CXR dataset을 사용했습니다. 이 dataset은 377,110개의 흉부 x-ray image가 있습니다. inference step에서, 저자들은 speech dataset을 다양한 STT model에 넣어 진행했습니다. speech dataset을 만들기 위해 "Balabolka" TTS probram을 사용했습니다.
Details of model training
VLP model은 AdamW optimizer를 이용해 pre-train됩니다. visual encoder는 ImageNet으로 self-supervised된 weight로 초기화되며, text encoder는 그냥 처음부터 학습되었습니다. model은 15 epoch으로 학습되었는데, 이 중 5 epoch은 warm-up이었으며, batch size는 12로 설정했습니다. fine-tuning을 할 때, 저자들은 동일한 optimizer를 사용했습니다. model은 pre-trained parameter로 초기화되며, 해당 parameter는 text-image alignment를 pretraining에서 학습된 상태입니다.
Experiments Results
Qualitative results
저자들의 model을 Google speech recognition software, Baidu's open-source STT engine DeepSpeech을 포함한 STT system들과 비교합니다. 저자들은 1531개의 image-text pair test set을 가지고 text 전용 model, 저자들이 제안한 model, 다양한 STT system들과 다양한 task에서 비교합니다.
 |
 |
여기서 파란색은 correct sentence를 의미하고 빨간색은 wrong sentence를 의미합니다. 노란색은 틀리진 않았지만, 정답과는 다른 문장을 의미합니다. (A)를 보면 저자들이 제안한 model이 좋은 정확도를 보여주는 것을 볼 수 있습니다. visual semantic을 학습했기 때문에 이런 좋은 결과를 얻을 수 있었다고 합니다. (B)를 보면, 저자들이 제안한 model 정답을 만들지는 못했지만, 다른 model들에 비해 좀 더 좋은 결과를 보여줍니다.
이 외에도 다양한 실험을 저자들은 진행했으며, 자세한 내용은 논문을 확인하시면 됩니다.
Discussion and Conclusion
저자들은 MMSM이라고 불리는 새로운 method를 제안합니다. 이 method는 포괄적인 sematic context information을 사용하여 STT model의 error를 효과적으로 수정하는 방식입니다. 이 방식은 STT model와 독립적이며, 어떠한 STT model을 사용해도 괜찮으며 추가적인 tuning을 하지 않아도 됩니다. medical imaging은 일반적으로 방사선 전문의의 녹음된 목소리로부터 생성된 report와 medical image pair로 이루어지며, 저자들은 이러한 방사선 분야에서 실질적인 적용 가능성이 큽니다.



