https://arxiv.org/abs/1805.00833
Learnable PINs: Cross-Modal Embeddings for Person Identity
We propose and investigate an identity sensitive joint embedding of face and voice. Such an embedding enables cross-modal retrieval from voice to face and from face to voice. We make the following four contributions: first, we show that the embedding can b
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 face와 voice의 identity에 민감한 결합 embedding을 제안하고 조사합니다. 이 embedding은 voice에서 face로, face에서 voice로의 cross-modal 검색을 가능하게 합니다. 저자들은 4가지 contribution이 존재합니다.
1. 어떠한 identity label 없이도 말하고 있는 video로 embedding을 학습할 수 있음을 보입니다. cross-modal self-supervision 형태를 이용해 이 방식이 가능하도록 만듭니다.
2. 이 작업에서 training을 성공적이게 진행하기 위해 필수적인 curriculum learning schedule을 개발했습니다. 이는 hard negative mining을 위한 learning schedule입니다.
3. train 중에 보거나 듣지 못한 identity에 대한 cross-modal 검색을 여러 scenario에서 진행하고 평가하여 저자들이 제안한 task를 위한 benchmark를 설정합니다.
4. TV drama에서 character를 자동으로 검색하고 labelling하는 application을 제안합니다. 이 application은 결합 embedding을 사용합니다.
Introduction
얼굴과 목소리 인식은 모두 non-invasive하고 접근이 쉬운 생체 인식 도구로, 다양한 task에서 사용됩니다. face recognition의 가장 최신 기술은 labelling된 대규모 face dataset으로 학습된 deep convolutional neural network을 이용해 face embedding을 생성하고 사용하는 방식입니다. speaker recognition에서도 voice embedding을 생성하여 사용합니다. 하지만 얼굴이나 목소리로 사람을 구분할 수 있음에도 불구하고, 상당히 독립적으로 다뤄져 왔습니다.
이 논문의 최종 목표는 face와 voice의 결합 embedding을 학습하는 것이고, 이를 '말하는 얼굴'의 video와 같은 무한한 source의 unlabelled train dataset을 사용합니다. 이 train dataset을 이용해 cross-modal self-supervision 방식으로 학습을 진행합니다. face를 위한 subnetwork와 voice segment를 위한 subnetwork가 face가 voice에 연관이 있는지 아닌지를 예측하는 방식으로 동시에 학습되는 것이 key idea입니다. talking face video에서 동일한 face와 voice segment를 가져와 positive data로 사용하면 되고, 다른 video에서 face와 voice segment를 가져와 negative data로 사용하면 됩니다.
먼저, 결합 embedding이 가능한 지 고려할 가치가 있습니다. 확실히, network가 결합 embedding을 학습하는 작업을 수행하도록 하면 training dataset에 대해서는 성공할 가능성이 높습니다. 하지만, 얼굴과 목소리 사이의 관계를 완전히 임의적이고, network가 training data를 momorize했다면, train중에 보지 못하거나 듣지 못한 identitiy를 cross-modal 검색에서는 우연한 행동을 기대하게 됩니다. 사실 얼굴과 목소리 사이의 관계가 완전히 임의적이지 않습니다. 성별과 얼굴/목소리, 나이와 얼굴/목소리 사이에는 어느 정도의 의존성이 존재하기 때문입니다. 놀랍게도, 실험을 통해 보지도 못하고 듣지도 못한 identity에 대한 cross-modal 검색을 사용하여 성별과 나이를 넘어서는 matching을 보여줍니다.
Related Work
Cross-modal embeddings
visual content와 audio 사이의 관계는 다양한 context에 대해 연구되었으며, 대부분은 generation, matching, retrieval에 대한 연구였습니다. 이 논문에서는 shared representation을 구성하거나 두 modality의 결합 embedding을 구성하는 것이 목표입니다. image와 text에 대한 결합 embedding이 집중적으로 연구되어 왔지만, audio와 vision에 대해서도 주목을 받기 시작했습니다. 이러한 결합 embedding은 여러 방법으로 학습될 수 있으며, 저자들은 self-supervised learning의 한 형태로 연구를 진행하며, audio와 visual의 상응관계에 대한 일련의 작업들에 영감을 받아 진행했습니다. 또한 cross-modal distillation을 통해 embedding을 학습할 수도 있습니다.
최근에 관련된 연구 중 하나는 악기, 노래, 도구의 visual frame과 sound segment 간의 결합 embedding을 학습하는 것이 있습니다. 하지만 저자들의 경우, 세밀한 인식이 필요합니다: face와 voice pair 사이의 미묘한 차이를 학습해야 합니다. 그리고 사람은 말을 할 때 어휘 내용, 감정 및 억양과 같은 내부적 요인으로 인해 상당한 변동성을 보입니다. 각 사람마다의 identity를 생성할 수 있는 embedding은 이러한 요소에 대한 불변성이 존재해야 합니다.
Cross-modal learninig with faces and voices
생체 인식 분야에서 활발하게 연구되고 있는 분야 중 하나는 face image와 voice를 활용하는 multimodal recognition system을 개발하는 것입니다. single modality보다 더 나은 system 성능을 달성하는 multi-modal을 개발하는 것이 goal입니다. 이러한 system들은 일반적으로 feature를 fusion하여 구현됩니다. 하지만, 저자들은 두 modality의 공통적인 signal의 중복성을 활용하여 cross-modal 검색 task를 용이하게 하는 것입니다.
저자들의 이전 연구에서, face와 voice 사이에 강한 correlation이 있다는 것을 알아냈습니다. 이러한 상관관계는 성별, 나이, 국적 등과 같은 cross-modal biometric의 결과로 발생하며, 이러한 요인들은 얼굴의 외모와 목소리에 모두 영향을 미칩니다. 이 연구에서 저자들은 cross-modal retrieval과 verification과 같은 다른 task에서도 사용할 수 있는 joint embedding을 개발합니다.
Learning Joint Embeddings
저자들은 f(x_f) : R^F ⇒ R^E와 g(x_v) : R^V ⇒ R^E를 학습하는 것이 목표입니다. f(x_f)는 face를 shared coordinate space R^E로 mapping하고 g(x_v)는 face와 동일한 identity에서 추출한 voice를 shared coordinate space로 mapping합니다.
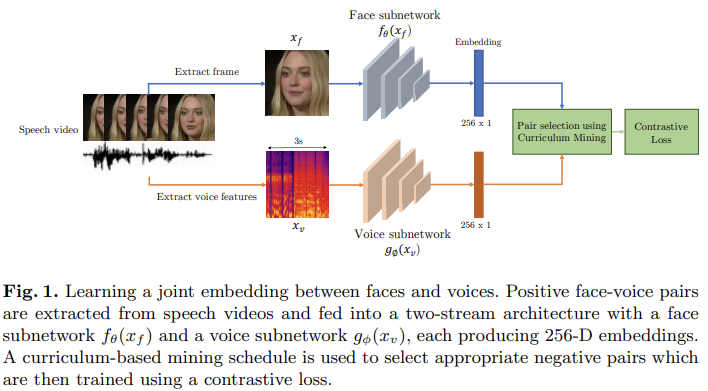
위 그림과 같이 f(x_f)와 g(x_v)는 convolutional neural network로 구현하고, face subnetwork와 voice network라는 두 stream architecture로 구현합니다. f와 g의 parameter를 학습하기 위해, {x_f, x_v}라는 training pair set를 sample합니다. 여기서 x_f는 face image를 의미하고 x_v는 speech segment입니다. 그리고 각 pair를 연관된 label y ∈ {0, 1}를 붙입니다. y = 0인 경우 x_f와 x_v가 다른 identity (negative pair)라는 것을 의미하고 y = 1인 경우는 x_f와 x_v가 동일한 identity (positive pair)라는 것을 의미합니다. 저자들은 contrastive loss를 paired data {(x_fi, x_vj, y_ij)}에 적용합니다. contrastive loss를 통해 f()와 g()가 positive pair에 대해서는 distance를 줄이고 negative pair에 대해서는 distance를 키우는 방식으로 최적화합니다. 여기서 negative pair의 distance는 margin parameter α를 사용하고, distance가 α보다 커지도록 만듭니다. 최종 식은 다음과 같습니다.
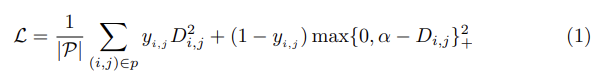
여기서 (i, j) ∈ p는 (x_fi, x_vj, y_ij) ∈ P를 나타내는 데 사용되고, D_ij는 두 normalized embedding 사이의 euclidean distance를 의미합니다. 식으로 보면 다음과 같습니다.
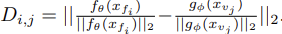
Generative face-voice pairs
- obtaining speaking face tracks
이전의 audio-visual self-supervised 관련 연구들은 명시적으로 synchronized data를 찾는 방식이었습니다. 저자들은 same time에 audio와 video frame을 추출하는 것은 contrastive loss를 학습할 때 필요한 face와 voice pair dataset을 만들기에 불충분하다고 합니다. 사람이 말하는 내용을 포함하고 있다는 tag가 있는 video라고 할지라도, 해당 video에서 짧은 audio를 추출했을 때 어떠한 speech가 없을 수도 있으며, speech가 포함되어 있어도 해당 frame에 사람 얼굴이 안 보일 수도 있습니다. 그리고 1명 이상의 face가 frame에 나타날 수도 있습니다.
그래서 저자들은 이러한 문제를 다루기 위해 SyncNet을 사용합니다. 이는 unsupervised method이며, video에서 speaking face-track을 자동으로 얻을 수 있습니다. SyncNet은 2가지 stream convolutional neural network로 구성됩니다. 이 network들은 audio track과 mouth omtion 사이의 상관관계를 추정합니다. 이를 통해 video에서 speaking face-track을 정확하게 segment할 수 있습니다.
- Selecting face-voice pairs
face-track collection이 주어졌을 때, 간단한 labelling algorithm을 사용하여 training pair에 labell을 구성할 수 있습니다. 동일한 face-track에서 추출된 face와 voice segment는 positive pair로 정의하고, 다른 face-track에서 추출된 face와 voice segment는 negative pair로 정의하면 됩니다.
저자들은 감정이나 어휘 내용과 같은 본질적인 요소를 capture하는 것이 아니라 identity를 같이 place하는 embedding을 학습하는 것이 목표이며, face와 voice의 positive pair가 audio에서 동일한 시간에 align될 필요가 없습니다.
The Importance of Curriculum-based Mining
contrastive loss를 통해 embedding을 학습하는 데의 주요한 어려움 중 하나는 dataset이 늘어남에 따라 가능한 pair 수가 제곱으로 증가한다는 점입니다. 이러한 상황에서, network는 간단한 example에 대해서는 빠르게 학습하여 정확하게 mapping할 수 있지만, 성능을 더욱 향상시키기 위해서는 hard positive와 negative mining이 필요합니다. 충분한 capacity의 neural network는 다른 성별의 face와 voice를 빠르게 embad를 학습합니다 - 다른 성별에서 나온 sample들은 쉬운 negative pair가 됩니다. 성별은 identity를 구성하는 많은 요소 중 하나에 불과하기 때문에, embedding이 다른 요소들도 encode할 수 있도록 만들어야 합니다. 하지만 speaker face-track를 사전에 알 수 없기 때문에, 성별이 일치하는 부정적 쌍의 sampling을 강제할 수 없습니다. 즉 negative pair를 만들 때, 성별을 기준으로 matching할 수 없음을 의미합니다. 저자들은 training 중에 identity에 대한 지식이 필요 없는 어려운 negative pair mining 방식으로 이 문제를 해결했습니다.
unsupervised setting에서 이 방식을 사용할 때, hard negative selection은 상당히 민감한 과정이며, 특히 network를 처음부터 학습시킬 때 더욱 그렇습니다. negative sample이 너무 어렵다면, network는 outlier에 지나치게 focus하게 되고 의미 있는 embedding을 학습하는 데 어려움을 겪게 됩니다. 저자들의 실험 환경에서는 가장 어려운 negative hard는 특히 조심해야 합니다. 왜냐하면 실제로는 같은 identity의 voice와 face가 우연히 다른 speaking face-track에서 sampling될 수 있기 때문입니다(즉, 잘못된 negative label이 될 수 있음을 의미).
Controlling the difficulty of mined negatives
Standard online hard example mining (OHEM) 기술은 minibatch에서 가장 어려운 positive pair와 negative pair를 sample하는 방식입니다. 하지만 저자들의 상황에서는 speaking face-track 내에서의 변동성이 나타나지 않을 것으로 예상되므로, hard positive mining은 어느 정도의 제한이 있을 것입니다. 만약 각 mini-batch에서 hardest negative example을 선택한다면, 큰 batch에서 training하는 것은 outlier의 위험성이나 false negative의 위험성(실제로는 positive pair이지만 negative로 labelling된 pair가 존재하게 될 수 있음) 이 증가하며, 이를 통해 학습이 잘 이뤄지지 않을 수 있습니다. 그래서 저자들은 curriculum-based mining system을 고안했습니다. 각 mini-batch는 K개의 random하게 sample된 face-track이 있습니다. 각 face-track에 대해, 저자들은 single frame x_f에서 균일하게 sampling하여 positive pair를 구성하고 3초 audio segment x_v를 균등 sampling합니다(즉 face image를 sampling하고 그에 맞는 3초 길이의 audio를 sampling하여 positive pair를 만드는 것을 의미). 이 sampling 과정은 간단한 data augmentation으로 볼 수 있으며 이용 가능한 data를 잘 활용하여 K개의 positive face-voice pair를 생성합니다. 그다음 pair들 중 각 face input x_f를 anchor face로 생각하고 적절한 hard negative sample을 mini-batch 내에서 고릅니다. 이는 해당 face embedding과 직접 연결되지 않은 모든 voice embedding 사이의 거리를 계산함으로써 구현할 수 있으며, 총 K-1개의 잠재적 negative pair를 만들 수 있습니다. 잠재적 negative voice들은 anchor face와의 거리를 기준으로 내림차순 정렬합니다. 그렇게 되면 가장 마지막에 위치한 negative voice가 해당 batch에서 hardest negative pair가 되게 됩니다. 이렇게 정렬된 잠재적 negative voice들 중에서 'negative difficulty parameter τ'를 기준으로 적절한 negative sample들을 선택하면 됩니다. τ = 1이라면 가장 어려운 negative pair를 의미하게 되고, τ = 0.5면 중간 정도, τ = 0은 가장 쉬운 pair를 의미하게 됩니다. 이 parameter τ는 learning rate에 맞춰서 tuning 될 수 있습니다. 학습 초기에는 쉬운 negative pair를 선택하고 그 이후에는 점점 어려운 negative pair를 고르는 것이 효율적인 학습에 도움이 된다는 것을 확인했다고 합니다. 적절한 negative pair를 선택하면서 저자들은 anchor face와 threshold negative의 distance가 anchor face와 positive 사이의 distance보다 더 멀어지도록 만듭니다.
Experiments
저자들은 2가지 초기화 방식에 대해 실험을 진행합니다. 처음부터 학습하는 방식(각 subnetwork의 parameter는 random하게 초기화)과 pretrained subnetwork를 사용하는 방식입니다. pretrained subnetwork를 사용한다면, 각 subnetwork들은 각 single modality에 대해 학습된 weight를 가져와 사용합니다.
그리고 저자들은 teacher-student style architecture에 대한 실험도 진행합니다. face subnetwork의 pretrained weight는 training (teacher)할 때는 frozen되고 voice subnetwork는 학습됩니다(student). 하지만 이러한 teacher-student style이 성능을 오히려 저하시킨다는 것을 알아냈다고 합니다. face subnetwork는 VGG-face dataset를 이용해 identity에 대해 학습된 weight를 가져와 사용하고, voice subnetwork는 VoxCeleb dataset으로 speaker identification에 대해 학습된 weight를 가져와 사용한다고 합니다.
Network architectures and implementation details
- Face subnetwork
face subnetwork는 VGG-M architecture를 사용합니다. face subnetwork의 input은 RGB image이고, face region만 포함하도록 source frame만 crop한 후 224 x 224로 resize한 image입니다. image는 random horizontal flipping, brightness, saturation jittering을 이용해 augmentation되지만 face region에서 random crop을 진항하지는 않습니다. VGG-M의 final fully connected layer는 각 face input의 256차원 embedding을 생성하기 위해 resize했다고 합니다. embedding은 그다음 L2 normalization된 다음 negative mining 방식의 pair selection으로 전달됩니다.
- Voice subnetwork
audio subnetwork는 VGG-Vox architecture를 이용합니다. input은 short-term aplitude spectrogram이고, 이 spectrogram은 3초 raw audio에서 512-point FFT를 적용하여 구해집니다. 최종 주어진 spectorgram의 size는 512x300이 됩니다. train할 때, audio의 3초 segment는 전체 audio segment에서 random하게 선택됩니다. spectrogram의 모든 frequency bin에 mean normalization과 variance normalization을 진행합니다. face subnetwork와 유사하게, final fully connected layer는 256으로 reduce되고 256차원 voice embedding이 output되고, voice embedding에 L2-normalization을 적용합니다. test 할 때, 전체 audio segment를 network에 feed하고 average pooling을 이용해 최종 voice embedding을 생성합니다.
Evaluation
Cross-modal Verification
저자들은 cross-modal verification을 진행하여 저자들의 network를 평가합니다. 서로 다른 modality의 두 input이 의미적으로 align되어 있는지 아닌지를 결정하는 것이 objective입니다. 더 자세히 말하자면, face input과 speech segment가 주어졌을 때, 두 input이 동일한 identity에 속하는지 아닌지를 결정하는 것이 goal입니다. 이 task에 대한 benchmark가 없기 때문에, 저자들은 VoxCeleb dataset에 대한 evaluation protocol을 만들었습니다. seen-heard identity에 대한 평가와 unseen-unheard identity에 대한 평가를 진행합니다. 각 evaluation benchmark test pair는 랜덤하게 sample된 것이며, unseen-unheard identity에 대해선 30,496개의 pair가 존재하고 seen-heard identity에 대해서는 18,020개 pair가 존재합니다.

실험 결과는 위와 같습니다. 왼쪽 표가 cross-modal verification에 대한 결과입니다. random은 untrained model을 의미합니다.
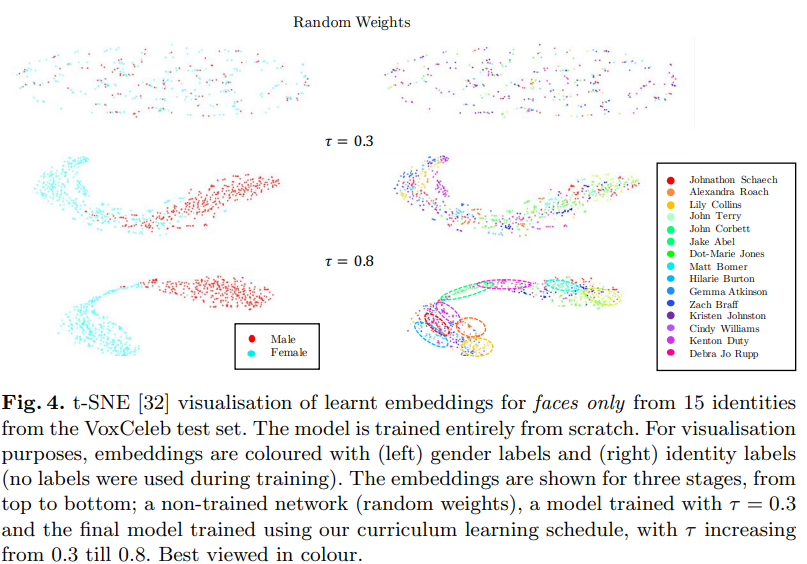
embedding을 시각화한 결과는 위와 같습니다. 보지도 듣지도 못한 identity에 대해서도 잘 clustering하는 것을 볼 수 있습니다.
- Effect of cross-modal biometrics
voice와 face에 모두 영향을 주는 latent properties (age, gender, nationality)에 대한 효과를 알아보겠습니다.

저자들은 성별, 국적, 나이를 각각의 기준으로 사용하여 negative test pair를 생성하고, test를 진행했습니다. 이를 통해 각 factor들이 얼마나 영향을 주는지 평가를 진행했습니다. 예를 들어 성별이 기준인 경우, 같은 국적과 같은 나이인 data를 사용합니다. 같은 국적이고 같은 나이이며 성별이 같은 data들은 positive pair로 만들어주고, 성별만 다른 경우를 negative pair로 만들어줬습니다.
성별과 국적 label은 Wikipedia에서 얻었습니다. speaker의 나이는 video마다 다르기 때문에, 저자들은 face frame에서 age를 예측하는 classifier를 사용하고 각 video마다 구해진 age를 평균내어 사용했다고 합니다. 성별이 가장 영향을 미치는 인구 통계적 factor임을 볼 수 있습니다.
저자들은 이 외에도 다양한 실험을 진행했으며, 자세한 내용은 해당 논문을 통해 확인하시면 됩니다.
Conclusion
저자들은 face와 voice가 동시에 embedding될 수 있고 unseen 또는 unheard identity에 대한 cross-modal retrieval이 가능하다는 것을 증명했습니다. joint embedding은 video에 있는 face가 voice와 동일한 지 check하는 데 사용될 수 있습니다.



