https://arxiv.org/abs/2201.03967
Emotion Intensity and its Control for Emotional Voice Conversion
Emotional voice conversion (EVC) seeks to convert the emotional state of an utterance while preserving the linguistic content and speaker identity. In EVC, emotions are usually treated as discrete categories overlooking the fact that speech also conveys em
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
emotional voice conversion (EMC)는 linguistic content와 speaker identity는 유지한 상태로 utterance의 emotion을 변환하는 것을 의미합니다. EVC에서 감정은 주로 discrete cateogry로 다뤄지는데, 사실 speech에서의 감정은 다양한 강도로 전달하고 청자가 인식할 수 있다는 사실을 간과한 모습입니다. 이 논문에서, 저자들은 명시적으로 characterize하고 감정의 강도를 control하는 것을 목표로 합니다. 저자들은 linguistic content에서 speaker style을 분리하고 speaker style을 emotional embedding의 prototype이 형성되는 연속적인 공간의 style embedding으로 encoding하는 것을 제안합니다. 그리고 emotion-labelled database로 실제 emotion encoder를 학습하고 미세한 감정 강도를 나타내는 상대적인 속성에 대한 연구를 진행합니다. 감정의 명료성을 보장하기 위해, 저자들은 emotion classification loss와 emotion embedding similarity loss를 사용하여 EVC network를 학습했습니다. 저자들이 제안한 network는 미세한 감정 강도도 control할 수 있으며, 그에 맞춰 speech를 output합니다.
Introduction
Emotional Voice Conversion (EVC)는 감정을 제외한 다른 음성 상태는 변경하지 않으면서 원하는 감정을 음성에 투영하여 합성하는 기술을 의미합니다. EVC는 대화 system의 감정적인 intelligence를 도입하는 등 인간-컴퓨터 interaction에 상당한 잠재력을 제공합니다.
Voice conversion은 linguistic information은 유지하면서 speaker identity와 같은 speaker-dependent한 음성 특성들을 변환하는 것을 목표로 합니다. speaker information은 성대의 물리적 구조에 의해 특징지어지며, spectrum mapping이 voice conversion의 주요 초점이 되었습니다. 그러나, speech는 다양한 강도의 감정을 포함하고 있으며 이는 청자가 인지할 수 있습니다. 예를 들어 행복은 기쁨 또는 환희로 인지될 수 있고, 화남은 '약간 화난' 상태와 '완전히 화난' 상태로 구분될 수 있습니다. 특히 감정의 강도는 감정의 목표를 달성하기 위한 요소의 크기로 설명됩니다. 그러므로 감정의 강도는 목소리의 크기가 아니라 감정에 기여하는 모든 acoustic 신호와 관련이 있습니다. 또한, 음성의 감정은 계층적이고 supra-segmental한 성질을 가지고 있으며 음절에서 발화에 이르기까지 다양합니다. 그러므로 frame별로 spectral로 mapping하는 방식으로 emotional voice conversion을 수행하는 것은 불충분합니다. 강도의 다양성과 운율의 변화도 고려하여 speech emotion modelling을 진행해야만 합니다.
감정의 다양한 강도로 합성하는 것은 emotional voice conversion task에 있어서 어려운 문제입니다. 대부분의 emotional speech dataset에는 강도에 대한 명시적인 label이 부족하기 때문입니다. 그리고 감정의 강도는 단순한 discrete emotion category를 고려하는 것보다 더 주관적이고 복잡하기 때문에 modelling하기 어렵습니다. 일반적으로 감정의 정도를 control하는 두 가지 유형이 존재합니다. 하나는 voiced state, unvoiced state, 침묵(VUS)과 같은 보조 특징이나 attention weight 또는 saliency map을 사용하는 방식입니다. 또 다른 방식은 interpolation 또는 scaling을 통해 내부 감정 표현을 조작하는 방식입니다. 이러한 방식들이 있음에도 불구하고, 감정의 강도를 조절하는 것은 emotional voice conversion 분야에서 여전히 덜 연구된 주제입니다.
이전의 emotional voice conversion은 주로 서로 다른 감정 type 사이의 feautre를 mapping할 수 있도록 학습하는 것을 주로 focus했었습니다. 대부분은 Gaussian mixture model, sparse representation, HMM을 사용하여 spectral과 운율의 parameter mapping을 modelling하였습니다. 최근에는 DNN, deep bi-directional long-short-term memory network (DBLSTM)과 같은 deep learning method들이 최신 기술을 발전시켰습니다. GAN-based 또는 auto-encoder-based model을 사용하는 새로운 기술들은 non-parallel training이 가능하도록 만들어줬습니다. 이러한 framework들은 frame 기반으로 감정을 변환했으며, speech duration은 수정할 수 없었습니다. 그리고 spectrum과 prosody가 서로 독립적이지 않기 때문에, 서로 별도로 연구하는 것은 conversion에 좋지 않습니다. 상관된 음성 factor를 end-to-end 방식으로 transfer할 수 있는 model을 갖는 것이 유리하며, 합성된 speech에서 더 실제 같은 감정을 생성할 수 있습니다.
최근에는 seq2seq model들이 speech synthesis, voice conversion에서 큰 관심을 받고 있습니다. attention mechanism을 적용한 seq2seq fraemwork는 feature mapping과 alignment를 동시에 학습하고, run-time에서는 speech duration을 자동적으로 예측합니다. 이러한 성공적인 시도에서 영감을 받아, 연구자들은 Seq2Seq modelling을 emotional voice conversion에도 적용했습니다. 예를 들어, pitch와 duration을 동시에 modelling 하는 Seq2Seq model이 있었습니다. 그리고 emotional voice conversion과 emotional TTS를 수행하는 multi-task learning도 연구되었습니다. 저자들은 이러한 연구들의 2가지 한계점을 제안합니다: 실제상황에서 감정은 다양한 강도로 표현되지만, 이전 연구들은 학습과정에서 감정 패턴의 평균을 학습합니다. 그리고 이전 연구들은 수많은 emotional speech data가 있어야 train이 가능합니다. 하지만 대규모 emotional speech dataset은 사용하기 어렵습니다.
이 논문에서는 위 문제들을 해결하고자 합니다. 저자들의 주요 contribution은 다음과 같습니다.
- Emovox라는 Seq2Seq emotional voice conversion framework를 제안합니다. 이는 spectrum과 duration을 end-to-end 방식으로 동시에 transfer하는 emotional voice conversion model입니다.
- Emovox는 강도에 대한 명시적인 label없이 감정 음성 dataset에서 나타나는 강도의 다양한 변화를 자동으로 학습하며, inference 시에 변환된 emotional speech에 존재하는 감정의 강도를 효과적으로 제어할 수 있습니다.
- Emovox는 Seq2Seq EVC train을 위해 대량의 emotional speech data가 필요하지 않으며, 제한된 data를 사용해도 뛰어난 성능을 보여줍니다.
- 저자들은 Emovox의 감정 표현력과 감정 강도 제어의 효과성을 보여주는 평가를 제시했습니다.
Background and Related work
Emotion Intensity in Vocal Expression
감정을 characterize하는 가장 간단한 방법은 여러 다른 group으로 분류하는 것입니다. 하지만, 감정의 label을 선택하는 것은 대부분 직관적이고 문헌으로 표현할 때 일관성이 없습니다. 감정의 강도가 우리의 감정 인식에 영향을 주기 때문입니다. 예를 들어, 행복은 행복 또는 환희로 인지될 수 있으며, 이는 목소리의 quality는 유사하지만 강도에서 차이가 나기에 이와 같이 다르게 인지됩니다. 감정의 강도는 음성의 enerygy 뿐만 아니라 sppeech rate, fundamental frequency에서도 관측될 수 있습니다. 서로 다른 감정 사이에서의 신호 차이가 더 큽니다.
Sequence-to-Sequence Emotional Voice Conversion
conventional frame-based model과 비교했을 때, sequence-to-sequence model들은 emotional voice conversion에 더 적합합니다. 먼저, sequence-to-sequence model은 run-time때 speech duration을 예측할 수 있으며, speech의 rhythm의 관점에서 중요하며 감정적 운율에 크게 영향을 줄 수 있습니다. 그리고 sequence-to-sequence model에서 spectrum과 prosody를 동시에 transfer하는데, 이는 conventional analysis-synthesis-based emotional voice conversion system이 겪는 mismatch 문제를 해결할 수 있습니다. 또한, emotional prosody는 supra-segmental하고 몇몇 단어와만 연관될 수 있습니다. attention alignment를 학습하는 것은 conversion을 할 때 emotion-relevant region에 focus 할 수 있도록 만들어줍니다. 그래서 저자들은 sequence-to-sequence modelling을 이용한 emotional voice conversion에 주로 focus를 맞추고 연구를 진행했습니다.
sequence-to-sequence emotional voice conversion 연구는 매우 드뭅니다. parallel data를 이용하여 pitch와 duration을 동시에 model하는 연구가 있었으며, 모델은 구절에서 음절 위치에 따라 condition되는 형태로 구현되었습니다. 다른 연구에서는 emotion encoder와 speaker encoder를 이용한 sequence-to-sequence emotional voice conversion을 진행하기도 했습니다. 이러한 연구들은 전부 10시간 정도의 parallel emotional speech data를 필요로 하며, 그 정도의 data를 구하는 것은 쉽지 않습니다. 최근 연구에서는 2-stage training 전략을 사용하기도 합니다. 2-stage training strategy를 사용한다면 TTS를 활용하여 대규모 emotional voice database의 필요성을 제거할 수 있습니다. 하지만 감정의 강도 변화를 다루지 않으며 감정의 강도를 조절하는 emotional utterance convertion은 불가능합니다. 어떤 연구에서는 emotion embedding에 facctor를 곱하는 방식으로 감정의 강도를 run-time에서 조절하기도 했습니다. 하지만, 이러한 방식은 학습할 때 감정의 강도 변화를 명시적으로 modelling하지 않으며, 강도 제어 방법은 해석 가능성이 부족합니다.
이 논문에서는 emotional voice conversion을 위한 emotion intensity를 modelling하는 연구를 진행합니다. 제한된 양의 emotional voice dataset을 사용하여 효과적으로 emotion intensity를 제어할 수 있는 sequence-to-sequence emotional voice conversion framework를 구현합니다.
Expressive Speech Synthesis with Prosody Style Control
speech emotion은 speech prosody에 크게 연관있으며 intonation, rhythm, enery와 같은 acoustic speech에 내재된 여러 prosody 신호에 의해 영향을 받습니다. prosody style을 modelling 하고 control 하는 가장 간단한 방법은 annotation 또는 label을 명시적으로 사용하는 것입니다. 라벨링하는 것 이외에도, 연구자들은 unsupervised 방식으로 reference style을 모방하고 이식하기 위해 reference encoder를 사용하기도 합니다. Global Style Token (GST)은 reference audio에서 해석 가능한 style embedding을 학습하는 한 예시입니다. token을 선택함으로써 model은 합성된 speech의 style을 control할 수 있습니다. 다른 연구들은 주로 globla style embedding을 세밀한 prosody embedding으로 대체합니다. VAE 기반의 다른 연구들은 학습하고 scaling하거나 분리된 representation을 결합하는 방식으로 speech style을 효과적으로 control하기도 합니다.
emotion expressive speech는 더욱 복잡하며, 여러 prosodic 속성과 관련된 미묘한 동적 변화를 가지고 있습니다. prosody style을 control하려는 시도들의 성공에서 영감을 받아, 여러 연구들은 emotion intensity를 control하는 emotional speech synthesis를 진행했습니다. 연구들은 prosody style을 명시적으로 modelling하지 않지만, input text와 emotional prosody style의 연관성을 end-to-end 방식으로 encode했습니다.
Emovox: Emotional Voice Conversion with Emotion Intensity Control
저자들이 제안한 emotional voice conversion framework인 Emovox는 4가지 module로 구성됩니다. 1) source speech에서 linguistic embedding을 구해주는 recognition encoder, 2) reference emotion style을 emotion embedding으로 encode하는 emotion encoder, 3) 미세한 강도에 대한 input을 intensity embedding으로 encode하는 intensity encoder, 4) linguistic, emotion, intensity embedding을 결합하여 converted speech를 생성하는 Seq2Seq decoder로 구성됩니다.
run-time에서 Emovox는 source linguistic content를 보존하면서 reference emotion을 source utterance로 전달합니다. 구조는 다음과 같습니다.
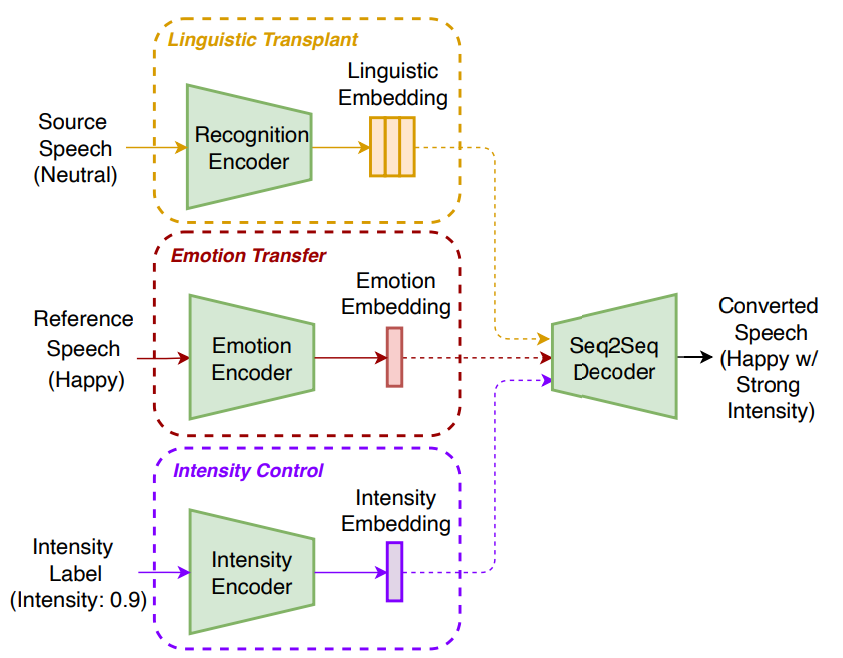
Emovox는 output speech의 emotion intensity를 조작하고 control할 수 있습니다. Emovox를 학습하기 위해, 저자들은 Seq2Seq framework를 제안하는데, 이는 input acoustic feature로부터 speech element를 분리하고 speech element를 가지고 acoustic feature를 reconstruct합니다. training data의 양을 줄이기 위해, 저자들은 2가지 pre-training strategy를 사용합니다. 1) large TTS corpus를 이용하는 style pre-training 2) Speech Emotion Recognizer를 이용한 emotion supervision training입니다.
Seq2Seq Emotional Voice Conversion
사람의 speech는 speech style과 linguistic content의 combination으로 볼 수 있습니다. 만약 감정을 표현해주는 speech style을 linguistic content로부터 분리될 수 있다면, emotion conversion을 run-time때 linguistic content와 speaker identity를 유지한 채로 speech style만 조작하는 방식으로 수행할 수 있습니다.
speech element를 분리하는 다양한 방법이 존재합니다. sequence-level autoencoder에 text information과 adversarial learning을 진행하는 방식이 존재합니다. 이 framework는 linguistic representation과 speaker representation을 명확하게 분리할 수 있었으며 voice conversion을 수행할 때 duration도 modelling할 수 있었습니다. 그래서 저자들은 이러한 framework를 이용해 Emovox가 emotion style과 intensity를 model할 수 있도록 만들었습니다. 그림으로 나타내면 다음과 같습니다.
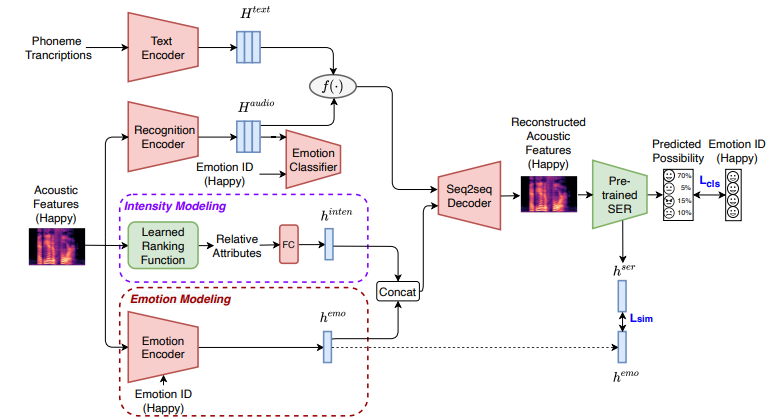
Seq2Seq 방식에 존재하는 deletion, repetition과 같은 문제를 해결하기 위해, 저자들은 linguistic embedding을 augment하기 위해 text input을 supervision signal로서 포함합니다.
phoneme sequence와 acoustic feature가 input으로 주어졌을 때, text encoder는 text (H^text)로부터 linguistic embedding을 예측하도록 학습되며 recognition encoder는 audio input (H^audio)로부터 linguistic embedding을 예측하도록 학습됩니다. emotion encoder는 speech로부터 emotion representation을 구할 수 있도록 학습되며, emotion classifier는 linguistic embedding H^audio에서 residual emotion information을 추가로 제거합니다.

Seq2Seq decoder 'Dec'는 emotion embedding h^emo, intensity embedding h^inten, linguistic embedding f(epoch)을 가지고 acoustic feature A^를 reconstruct하도록 학습합니다.

linguistic embedding은 위와 같이 정의됩니다. epoch을 기준으로 text encoder로부터 구한 H^text를 사용하거나 recognition encoder로 구한 H^audio를 사용합니다.
학습을 할 때, H^text와 H^audio는 decoder에 epoch의 값이 홀수인지 짝수인지에 따라 feed됩니다. contrastive loss는 H^text와 H^audio의 similarity를 보장하기 위해 사용됩니다. Emovox가 linguistic element와 emotional element를 효과적으로 분리하고 emotion과 emotion의 intensity를 간단하게 model하고 control할 수 있습니다.
Modelling Emotion and its Intensity
emotion intensity를 model하기 위해 등장하는 어려움 중 하나는 annotated intensity label이 부족하다는 점입니다. computer vision 분야에 등장한 연구에서 영감을 받아, 저자들은 emotion intensity를 emotional speech의 특성으로 여겼습니다. 그래서 emotion representation을 intensity information과 결합하는 것은 framework가 어떠한 emotional speech database를 사용하든 상관없이 풍부한 emotion style과 intensity level을 동시에 학습할 수 있게 됩니다.
- Formulation of Emotion Intensity using Relative attributes
computer vision에서, 서로 다른 카테고리의 data 사이의 차이를 model하는 다양한 방법들이 존재합니다. 특정 속성의 존재를 예측하는 대신, 상대적인 속성은 unseen data에 대해 더 많은 정보가 존재하는 description을 제공하며 이는 세밀한 인간의 supervision과 더 유사합니다. computer vision task에서의 성공에 동기를 얻어, 저자들은 low-level feature와 high-level semantic meaning 사이를 relative attribution이 연결시킨다고 여기며, emotion intensity를 modelling하는 데 적절하다고 생각했습니다.
emotion intensity는 감정 type이 얼마나 잘 인지될 수 있는지로 볼 수 있습니다. neutral speech는 어떠한 emotional variance를 포함하고 있지 않기 때문에, neutral speech의 emotion intensity는 0이 되어야만 합니다. 그러므로, 저자들은 emotion intensity를 neutral speech와 emotional speech 사이의 차이로 간주했습니다. emotion intensity는 각 emotion pair에서 emotion 관련 acoustic feature와 함께 학습한 relative attribution으로 표현될 수 있습니다. relative attribution을 학습하는 과정은 max-margin 최적화 문제로 표현할 수 있습니다.
training set T = {x_t}가 있고, x_t는 t번째 training sample의 acoustic feature이며, T = N∪E이고 N은 neutral set이고 E는 emotional set이라고 하겠습니다. 이 상태에서 저자들은 ranking function을 학습하는 것을 목표로 합니다. ranking function은 다음과 같습니다.

여기서 W는 weight matrix이며, 이는 emotion intensity를 나타냅니다. ranking function을 학습하기 위해, 저자들은 다음 constraint를 만족하도록 만듭니다.
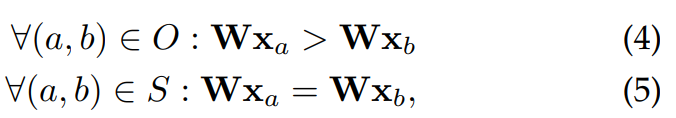
O는 ordered set이고 S는 similar set입니다. 저자들은 E의 emotional sample과 N에서의 neutral sample을 pair하여 E의 emotional intensity가 N보다 높은 ordered set O를 정의합니다. 그다음 emotional intensity가 서로 비슷한 pair로 구성된 similar set S에는 neutral-neutral pair와 emotional-emotional sample pair를 random하게 만들어 넣습니다. weight matrix W는 다음 문제를 해결하기 위해 추정되는 matrix입니다.
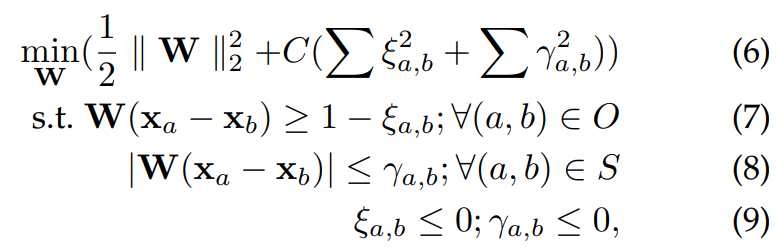
support vecctor machine을 푸는 형태로 볼 수 있습니다. 위 식에서 C는 margin과 slack variable의 크기 사이의 trade-off를 나타냅니다. 위 식을 통해 training point마다 요구되는 순서를 강제하는 wide-margin ranking function을 학습합니다. 한번 학습을 하면, relative ranking function은 unseen data의 order를 추정할 수 있습니다. 실제로 각 emotion category에 대해 ranking function을 학습했습니다. 학습된 ranking function은 [0,1]로 normalize된 training set에 존재하는 sample들의 relative attribution을 예측합니다. relative attribution가 크면 emotion의 intensity가 크다는 것을 의미합니다. 즉 각 emotion들에 대해 emotion intensity를 기준으로 ranking을 정의할 수 있는 W를 학습하는 과정에 대한 설명입니다. 이를 통해 unseen data의 emotion intensity를 판단할 수 있음을 의미합니다.
- Modelling Emotion Styles and its Intensity
학습한 ranking function으로부터 relative attribution을 얻은 후 intensity embedding을 얻기 위해 fully connected layer에 feed합니다. emotion encoder는 input speech feature로부터 emotion embedding을 생성하도록 학습됩니다. Seq2Seq decoder는 linguistic embedding sequence와 emotion embedding, intensity embedding을 combine하여 emotional speech의 acoustic feature를 reconstruct합니다.
training 과정에서, Emovox는 speech sample로 emotion style과 emotion intensity를 동시에 학습하여, 이 과정을 emotion training으로 부릅니다. 명시적인 intensity modelling과 함께, 저자들은 run-time에서 intensity를 control하기 위해 intensity의 level을 조작할 수 있게 됩니다. Emovox는 reference 또는 run-time 시 수동으로 주어진 emotion intensity를 예측할 수 있습니다. 이론적으로, Emovox는 emotional text-to-speech와 emotional voice conversion을 수행할 수 있습니다. 이 논문에서는 voice conversion에만 관심을 두고 있기 때문에 text encoder는 사용되지 않습니다.
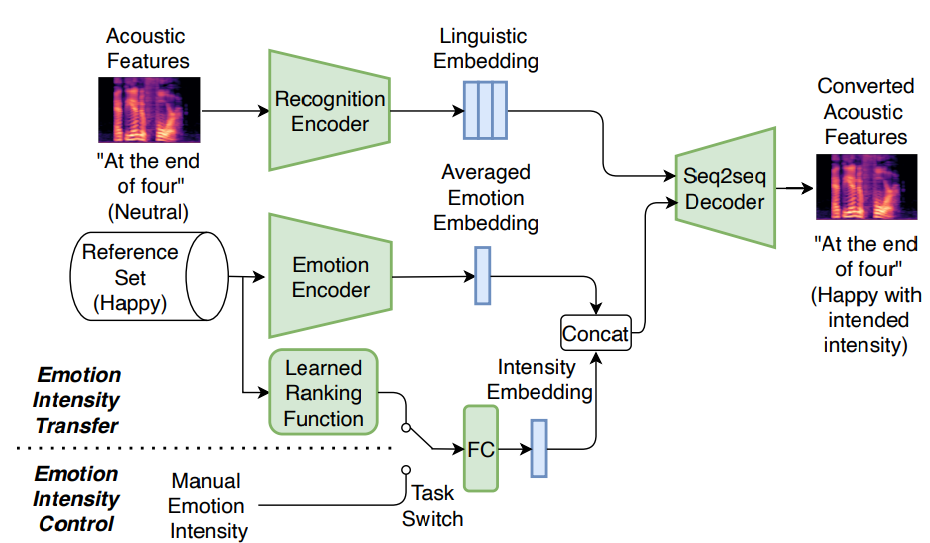
위 그림과 같이, 저자들은 emotion encoder를 사용하여 동일한 emotional category에 속하는 reference utterance set으로부터 emotion embedding을 생성합니다. 그다음 저자들은 averaged reference emotion embedding을 사용하여 emotion category를 represent합니다. 마지막으로, recognition encoder는 run-time에 source speech utterance로부터 linguistic embedding sequence를 구합니다. intended emotion category와 emotion intensity의 level을 지정함으로써, Seq2Seq decoder는 source와 동일한 content이지만 target emotion style을 적절한 intensity인 emotional speech를 생성합니다.
Model Pre-training
학습 중에는, 많은 양의 emotional speech가 있어야 Seq2Seq model이 강건한 attention alignment를 수행할 수 있으며 높은 감정 이해도를 달성할 수 있습니다. emotional speech에 대한 의존도를 줄이기 위해, 저자들은 two pre-training strategy를 제안합니다. 1) large TTS corpus를 이용한 style pre-training 2) SER을 이용한 emotion supervision training
- Style Pre-training with a Multi-Speaker TTS Corpus
speech style은 speaker characteristic과 연관된 speaker-dependent element를 포함하고 있으며, 이를 'speaker style'이라고 부릅니다. speaker style은 다중 speaker speech data를 포함하는 대부분의 TTS corpus에서 나타납니다. emotional speech database와 다르게, neutral tone의 TTS speech database가 많습니다. 그래서 저자들은 multi-speaker Seq2Seq TTS framework를 구축하고, network를 학습하여 linguistic content에서 speaker style을 분리할 수 있습니다. 저자들은 이 단계를 "style pre-training"이라고 부릅니다.
style pre-training 동안, style encoder는 multi-speaker TTS corpus를 통해 acoustic feature로부터 linguistic information을 제외하면서 풍부한 speaker style을 학습할 수 있습니다. 결과적으로, style encoder는 train 중에 특정 emotion style을 encode하는 것을 학습하지 않지만, emotion training동안에 다른 emotion style을 구분하는 방법을 학습합니다. 저자들은 TTS corpus로 학습된 style encoder를 emotion encoder의 pre-trained model로 사용합니다.
- Modelling Emotion with Perceptual Loss
변환된 emotion speech가 의도된 emotion category로 인식되기를 원합니다. 하지만 이는 어려우며, 특히 제한된 emotional training data로는 쉽게 달성되지 않습니다. 1) pre-trained emotion decoder는 emotion의 characterisation을 명시적으로 학습받지 않았습니다. 2) frame-level style reconstruction loss가 항상 human perceeption과 일관성 있는 것은 아닙니다. 왜냐하면 speech의 prosodic과 시간적 pattern을 capture하지 못하기 때문입니다.
speech synthesis에서의 perceptual loss의 성공에 따라, 저자들은 training 과정에서 emotion supervision으로써 perceptual loss를 사용합니다. pre-trained SER을 사용하여 reconstruct된 acoustic feature의 emotion category를 예측합니다. 그다음 두 가지 perceptual loss를 계산합니다. 1) emotion classification loss L_cls, 2) emotion embedding similarity loss L_sim을 사용합니다. 저자들은 이 두 lsos function을 통합하여 train하며 모든 trainable module을 update합니다.
emotion classification loss L_cls는 utterance level에서 reconstructed acoustic feature와 intended emotion category 사이의 perceptual similarity를 보장해줍니다. 식은 다음과 같습니다.

1은 target one-hot emotion label을 의미하고, p^은 utterance level에서의 예측된 emotion probabilities를 의미합니다. CE()는 cross entropy loss function을 의미합니다.
pre-trained SER은 text-independent 하다고 간주됩니다. emotion encoder가 linguistic content의 emotion independent를 characterize하는 것을 보장하기 위해, 저자들은 pre-trained SER로부터 고안된 emotion style descriptor를 emotion encoder의 learning objective로 사용합니다. 그리고 emotion encoder output인 emotion embedding과 emotion style descriptor 사이에 L_sim loss function을 이용하여 emotion encoder를 학습합니다.
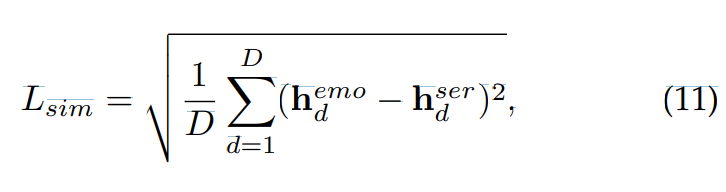
위 식과 같이 L_sim을 정의할 수 있습니다. 여기서 h_d^emo는 emotion encoder로부터 얻어지는 D차원 emotion embedding이며, h_d^ser는 pre-trained SER의 마지막 projection layer 바로 전에서 구해진 emotion style descriptor입니다.
- Effect of Perceptual Loss
perceptual loss function의 효율성을 평가하기 위해, 저자들은 emotion encoder의 emotion-discriminative ability를 평가하는 ablation study를 진행합니다. 저자들은 emotion encoder가 더 구별 가능한 emotional representation을 생성함으로써 더 좋은 성능을 보여준다고 생각합니다.
저자들은 t-SNE algorithm을 사용하여 emotion embedding을 2차원 평면에 visualize하는데 결과는 다음과 같습니다.

위 그림을 통해 서로 다른 emotion embedding들은 emotion cluster를 구성하는 것을 볼 수 있습니다. clustering 성능의 좀 더 직관적인 이해를 얻기 위해, 저자들은 emotion embedding의 구별 능력을 평가하기 위해 clustering 평가를 수행합니다.
clustering의 일반적인 objective function은 높은 intra-cluster similarity와 low inter-cluster similarity를 달성하는 것입니다. 저자들은 간단하고 효율적인 clustering 평가를 진행합니다. 저자들은 K개의 emotion class들에 대한 각 centroid를 구합니다. centroid c_i, i ∈ [1, K]는 i라는 class에 속하는 모든 embedding들의 average를 의미합니다. 식으로 표현하면 다음과 같습니다.
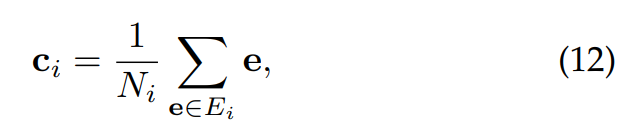
여기서 E_i는 i class에 속하는 embedding들의 집합입니다. 그다음 저자들은 각 embedding들을 본인 cluster가 아닌 다른 cluster의 centroid와의 Euclidean distance를 구해 inter-class distance dist_inter를 구합니다. 식은 다음과 같습니다.
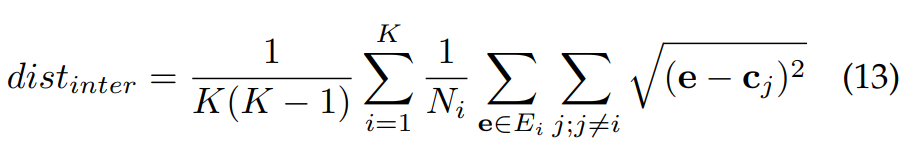
그리고 intra-class distance dist_intra는 다음과 같습니다.
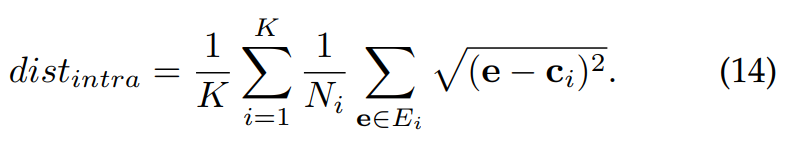
clustering ratio r은 intra class distance dist_intra와 inter-class distance dist_inter의 ratio를 통해 구해집니다. 식으로 표현하면 다음과 같습니다.

ratio r이 낮을수록 emotion embedding의 cluster 성능이 좋다는 것을 의미합니다.
저자들은 ESD evaluation dataset을 이용하여 ablation experiment를 수행합니다. 저자들은 emotion embedding의 분포를 visualize한 결과는 위와 같습니다. style encoder는 emotion intensity mechanism 없이 pre-train 되었기 때문에, 나머지 Emovox들도 intensity control 없이 비교를 진행했습니다. 확실히 L_cls와 L_sim 모두 사용한 경우가 가장 좋은 clustering 결과를 보여주며, emotion encoder가 더 구별 가능한 감정 표현을 생성하는 데 도움을 줄 수 있음을 보입니다.
Experiments
Objective Evaluation
저자들은 Mel-cepstral Distortion (MCD)와 Differences of Duration (DDUR)를 이용하여 system performance를 objective evaluation합니다.
- Mel-cepstral Distortion (MCD)
MCD는 변환된 Mel-cepstral coefficients (MCEPs)와 target Mel-cepstral coefficients (MCEPs)를 가지고 구해집니다. 식은 다음과 같습니다.
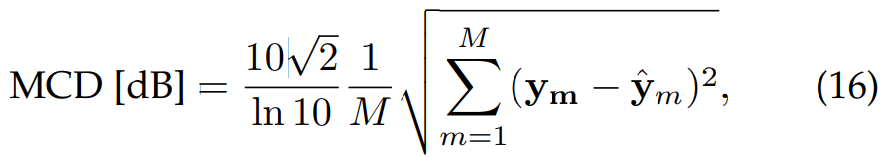
여기서 M은 MCEPs의 차원을 의미합니다. MCD의 결과값이 작다면 더 적은 spectral 왜곡을 나타내며, 더 좋은 성능임을 의미합니다. Seq2Seq-EVC와 Emovox model에서 저자들은 Mel-spectrogram을 acoustic feature로 사용했었습니다. 그러므로 MCEPs를 speech waveform에서 따로 구해서 MCD를 측정했다고 합니다.
- Differences of Duration (DDUR)
duration 관점에서 왜곡을 평가하기 위해, 저자들은 변환된 utterance와 target utterance 사이의 평균 duration 차이를 계산했습니다. 이는 voice conversion에 널리 사용되는 방식입니다. 식은 다음과 같습니다.
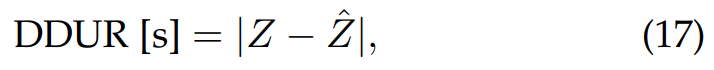
여기서 z는 reference utterance의 duration을 의미하고 z^는 converted utterance의 duration을 의미합니다. DDUR의 값이 작다면 duration conversion의 성능이 더 좋다는 것을 의미합니다.
그래서 최종 결과는 다음과 같습니다.

저자들이 제안한 Emovox가 가장 성능이 좋은 것을 볼 수 있습니다.
Subjective Evaluation
저자들은 2가지 subjective metric을 사용합니다. 1) emotion similarity 평가에 대한 MOS 2) speech quality, emotion intensity, emotion similarity에 대한 Best Worst Scaling (BWS) test입니다. 18명의 참여자들이 listening test를 진행했습니다. 12명의 남성과 6명의 여성으로 구성되며, native Chinese speaker이고 영어는 전문가 수준이라고 합니다. 그들의 나이는 20~30살 사이입니다. 모든 평가자들은 headphone을 이용하여 들으며 각 sample마다 2-3번 반복하여 들려줍니다.
- Mean Opinion Score (MOS) Test
저자들은 MOS test로 emotion similarity를 평가했습니다. 모든 참여자들은 reference target speech를 먼저 듣고 난 후에 reference target speech와 speech sample의 emotion similarity에 대한 scoring을 진행했습니다. 높은 score일수록 높은 유사도를 의미하며 더 좋은 emotion conversion performance를 보였음을 의미합니다. 저자들은 random하게 10개의 utterance를 골라 evaluation set으로 사용했습니다. 결과는 다음과 같습니다.

- Best-Worst Scaling (BWS) Test
저자들은 BWS test도 진행했습니다. speech quality, emotion intensity, emotion similarity에 대해 평가를 진행했습니다. speech quality의 경우, 모든 평가자들이 speech quality 측면에서 가장 좋은 sample과 가장 좋지 않은 sample을 선택했습니다. 얼마나 linguistic과 speaker identity가 잘 보존되는지, speech가 얼마나 자연스러운지를 중점으로 평가를 진행했다고 합니다.
emotion intensity의 경우 평가자들은 감정 표현의 관점에서 가장 덜 표현되고 가장 잘 표현된 sample을 선택했습니다.
emotion similaritiy의 경우 평가자들은 reference와 가장 emotion이 비슷한 sample과 가장 비슷하지 않은 sample을 선택했습니다.
저자들은 random하게 5개 utterance를 골라 BWS test를 진행했습니다. 결과는 다음과 같습니다.

Conclusion
저자들은 emotional voice conversion sequence-to-sequence model인 Emovox를 제안합니다. 이는 emotional voice conversion을 수행할 때 미세한 emotion intensity control을 할 수 있으며 효과적으로 control할 수 있습니다. 저자들의 주요 highlight는 다음과 같습니다.
- emotion intensity modeling technique을 공식화했으며, relative attribution을 기반으로 하는 emotion intensity controlling mechanism을 제안합니다. 이 방식들은 speech quality와 emotion intensity control에서 다른 method보다 더 우수하다는 것을 입증했습니다.
- 단순히 감정을 목소리 크기와 연관 짓는 것이 아니라, 저자들은 emotion intensity를 speech duration, pitch envelope, speech energy와 같은 다양한 prosodic attribution과의 상호 작용을 이해하기 위한 종합적인 분석을 제시했습니다. 저자들의 emotion intensity control이 다양한 prosodic 측면에서 나타날 수 있음을 보여주었습니다.
- 저자들은 변환된 emotional speech에서 감정의 명료성을 향상시키기 위해 pre-trained SER에서 style pre-trained과 perceptual loss를 제안했습니다. 저자들은 Emovox가 최신 emotional voice conversion framework보다 더 뛰어난 성능을 보임을 증명했습니다. 그리고 Emovox는 제한된 emotional speech data를 가지고도 효과적으로 성능을 보여줍니다.



