https://arxiv.org/abs/1904.05742
One-shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization
Recently, voice conversion (VC) without parallel data has been successfully adapted to multi-target scenario in which a single model is trained to convert the input voice to many different speakers. However, such model suffers from the limitation that it c
arxiv.org
해당 논문을 보고 작성했습니다.
Abstact
최근, parallel data 없는 voice conversion (VC)들은 single model이 input voice를 여러 다른 speaker로 변환하는 multi-target scenario에서 성공적으로 사용되고 있습니다. 하지만 이러한 model들은 training data에 존재하는 speaker의 voice로만 convert할 수 있으며, 이는 VC가 사용가능한 scenario가 줄어들게 됩니다. 이 논문에서, 저자들은 새로운 one-shot VC approach를 제안합니다. 이는 training할 때 존재하지 않는 source와 target speaker에 대해서도 voicec conversion을 수행할 수 있습니다. speaker와 content representation을 disentangle하는 방식으로 수행가능하며, disentangle은 instance normalization으로 수행합니다. 저자들의 model이 어떠한 supervision을 사용하지 않고도 의미 있는 speaker representation을 학습할 수 있음을 증명했습니다.
Introduction
VC는 speech singal의 linguistic content는 유지하면서 non-linguistic information을 변환하는 것을 목표로 합니다. non-linguistic information은 speaker identity, accent, pronunciation를 포함합니다. VC는 multi-speaker text-to-speech나 expressive speech synthesis와 같은 down-stream task에서 유용하게 사용될 수 있으며, speech enhancement, pronunciation correction과 같은 application에서도 유용하게 사용될 수 있습니다. 이 논문에서 저자들은 speaker identity conversion에 focus를 두고 연구를 진행했습니다.
VC에 대한 이전 연구들은 supervised 또는 unsupervised로 분류할 수 있습니다. supervised VC는 좋은 성능에 도달했습니다. 하지만 source와 target utterance 사이의 frame-level alignment가 필요합니다. 만약 source와 target domain 사이의 gap이 크다면, 부정확한 alignment가 conversion 성능을 저하시킬 수 있습니다. 이 뿐만 아니라 parallel data를 구하는 것은 어렵고 시간이 오래 걸리며, 새로운 domain에 적용할 수 있는 flexibility를 원한다면 supervised VC는 적합하지 않습니다.
unsupervised VC는 data collection에 대해 매우 효율적이기 때문에 최근에 많이 연구되고 있습니다. parallel data를 수집할 필요가 없고, non-parallel data로 VC system을 학습하는 방식입니다. speech를 phoneme posterior sequence로 변환하고 난 후에 target domain synthesizer의 speech로 합성하는 방식으로 unsupervised VC가 수행될 수 있습니다. 하지만 이러한 방식의 성능은 speech recognition의 성능에 매우 의존적이며 speech recogntion sytem이 잘 동작하지 않는다면 VC 성능이 크게 저하됩니다. 다른 연구에서는 VAE, GAN과 같은 deep generative model을 사용하여 unsupervised VC를 수행합니다. 이러한 연구들은 VC를 domain mapping problem으로 보며, utterance를 다른 domain으로 변환하는 network를 학습하는 것을 목표로 합니다. 이러한 연구들은 좋은 품질의 speech를 만들 수 있으며 speaker characteristic을 성공적으로 변환할 수 있었습니다. 하지만, 이러한 deep generative model을 사용하는 model들은 training때 보지 못한 speaker으로의 conversion은 수행할 수 없다는 한계가 존재합니다.
speech signal은 static information과 linguistic information을 모두 포함하고 있습니다. speaker, acoustic condition과 같은 static part는 time-independent하고 전체 utterance 중에 거의 변하지 않지만, linguistic part는 frame별로 dramatic하게 변하기도 합니다. utterance를 speaker representation과 content representation로 분해할 수 있습니다. speaker representation과 content representation을 분리하기 위해, 저자들의 model은 3가지 구성요소를 포함합니다. speaker encoder, cotent encoder, decoder입니다. speaker encoder는 speaker information을 speaker representation으로 encode합니다. content encoder는 linguistic informatoin만 content representation으로 encode합니다. decoder는 두 representation을 결합하여 다시 voice로 합성합니다. 저자들은 content encoder에서 affine transformation 없이 instance normalization을 사용하여 channel statistic을 normalize하고 이를 통해 global information을 control합니다. 이러한 방식은 speaker information과 같은 global information을 content encoder로 encode된 representation에서 제거할 수 있습니다. 그리고 adaptive instance normalization을 decoder에서 사용하며, 해당 affine parameter가 speaker encoder에 의해 제공됩니다. 이러한 방식을 통해 decoder가 필요로 하는 global information은 speaker encoder에 의해 control됩니다. 저자들의 model은 분리된 representation을 학습하게 됩니다. 이러한 분리된 방식은 저자들의 model이 one-shot voice conversion을 수행할 수 있도록 만들어줍니다. source speaker에서 utterance를 얻고 target speaker에서 또 다른 utterance를 얻은 후, target utterance에서 speaker representation을 얻습니다. 그다음 source utterance에서 cotent representation을 추출합니다. 마지막으로 decoder를 이용해 represnetation을 결합하여 converted result를 생성합니다. 이러한 저자들의 model은 training process에서 어떠한 utterance의 speaker label을 필요로 하지 않으며, data collection이 간단합니다. 흥미롭게도, speaker encoder는 speaker label 없이도 의미 있는 speaker embedding을 학습합니다.
이전 연구에서는 utterance에서 특정 attribution을 제거하기 위해 adversarial training을 사용하기도 했었습니다. 하지만 추가적인 discriminator network를 학습시키는 cost 때문에 더 많은 연산량이 필요로 하고 사용됩니다. 또한 adversarial training은 불안정적이라는 문제가 있으며 학습이 어려워집니다. 저자들이 제안한 방식은 utterance에서 speaker information을 제거하기 위해 adversarial training을 하는 대신 간단한 instance normalization을 사용하며, 연산량을 상당히 줄일 수 있고 학습 과정이 간단해집니다. 저자들의 주요 contribution은 다음과 같습니다.
- 저자들의 model은 supervision 없이도 one-shot VC을 할 수 있습니다.
- instance normalization의 representation을 분리 효율성을 입증합니다.
- 저자들의 model이 의미있는 speaker embedding을 학습할 수 있습니다.
model 구조는 다음과 같습니다.

Proposed Approach
Variational autoencoder
x가 acoustic feature segment라 하고, X가 training data에 존재하는 모든 acoustic segment라 하겠습니다. E_s가 speaker encoder이고 E_c가 content encoder이며 D는 decoder라고 하겠습니다. E_s는 speaker representation z_s를 생성하도록 학습도비니다. E_c는 content representation z_c를 생성하도록 학습됩니다. p(z_c|x)가 unit variance인 conditionally independent Gaussian distribution 이라고 하겠습니다. 즉 p(z_c|x) = N(E_c(x), I)입니다. 이 상태에서 reconstruction loss는 다음과 같습니다.

train할 때 acoustic segment x를 X로부터 uniform하게 sample합니다. posterior distribution p(z_c|x)를 prior N(0, I)에 matching하기 위해, KL divergence loss를 minimize합니다. unit variance로 저자들이 가정했기 때문에, KL divergence는 L2 regularization을 줄여줍니다. KL divergence term은 다음과 같습니다.

VAE training을 위한 objective function은 weighted hyper-parameter를 이용하여 두 term을 combination한 형태이며, 이 식을 minimize하는 방식으로 VAE는 학습을 진행합니다.

Instance Normalization for Feature Disentanglement
먼저, E_s와 E_c encoder가 어떻게 speaker information과 content information을 encode하는 지에 대해 알아보겠습니다. 저자들은 affine transformation 없이 Instance normalization (IN)을 content encoder E_c에 사용하여 cotent information은 유지하면서 speaker information은 제거했습니다. computer vision 분야에서 style transfer를 할 때 이와 같이 instance normalization을 사용해 성공을 거두었으며, 이에 영감을 받아 진행했다고 합니다. affine transformation 없는 instance normalizaiton (IN)은 다음과 같습니다.
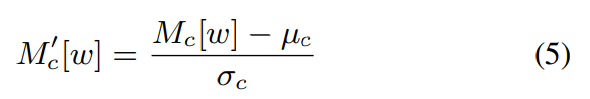
위 식에서 M은 convolution layer의 output의 feature map을 의미합니다. M_c는 W차원 array인 c번째 channel을 나타냅니다. 각 channel은 matrix 대신 array를 사용하는데, 2D convolution 대신 1D convolution을 사용하기 때문입니다. IN을 사용하기 위해, 저자들은 c번째 channel의 mean μ_c와 표준편차 σ_c를 구합니다.
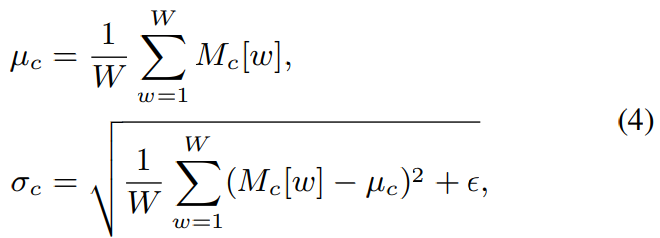
M_c[W]은 M_c의 w번째 element를 의미합니다. 표준편차를 구할 때 ε를 사용하는데, 매우 작은 값이며 이를 통해 수치적 불안정성을 피하기 위해 사용됩니다. IN에서 M_c의 각 element는 normalized되어 M_c'가 됩니다.
normalized M_c'는 deep network layer를 통해 처리됩니다. content encoder가 domain information을 학습하는 것을 방지하기 위해 content encoder에 IN layer를 이용합니다. model이 speaker encoder로부터 speaker information을 추출하고 content encoder로부터 content information을 추출하도록 enforce할 수 있게 됩니다.
speaker encoder가 speaker representation을 생성하도록 더욱 강제하기 위해서, 저자들은 adaptive instance normalization (adaIN) layer를 이용하여 speaker information을 decoder에 제공합니다. adaIN layer에서, decoder는 IN을 이용해 global information을 normalize합니다. 그다음 speaker encoder는 global information을 제공합니다. 식으로 나타내면 다음과 같습니다.

μ_c와 σ_c는 이전에 구한 평균과 표준편차입니다. γ_c와 β_c는 speaker encoder E_s의 output의 각 channel에 대한 linear transformation을 의미합니다.
Implementation Details
Architecture
저자들은 encoder와 decoder에 Conv1d layer를 사용했으며, 모든 frequency information을 처리할 수 있습니다. 구조는 다음과 같습니다.
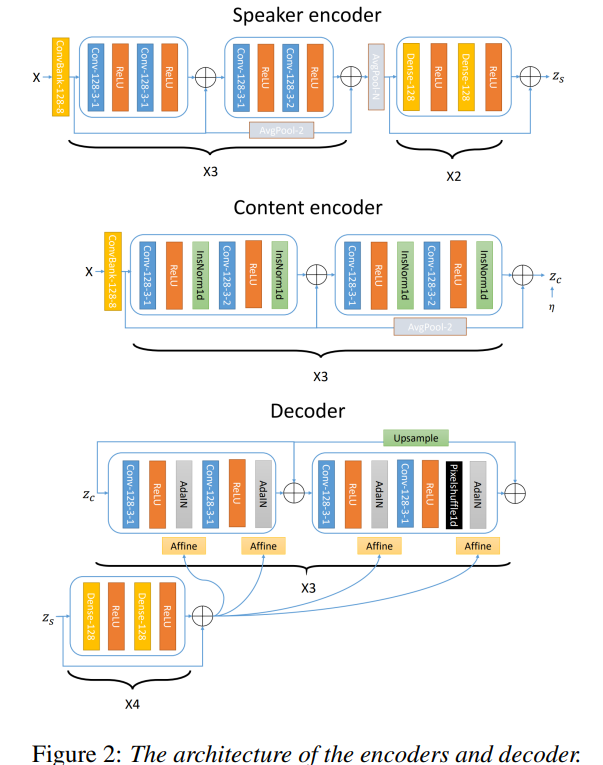
ConvBank layer는 speaker encoder와 content encoder 모두에서 사용되며, 이를 통해 long-term information을 더 잘 capture할 수 있습니다. 저자들은 speaker encoder에서 모든 time에 대해 average pooling을 사용하여 speaker encoder가 global information만 학습할 수 있도록 만들어줍니다. Instance normalization layer는 content encoder에서 사용되며, 이를 통해 global information을 normalize할 수 있습니다. PixelShuffle 1d layer는 decoder에서 upsampling을 위해 사용됩니다. adaIN layer는 global information을 decoder에 제공하기 위해 사용됩니다. speaker reprensetation z_s는 residual DNN에 의해 처리된 후, affine layer을 거친 다음에 adaIN layer에 transform됩니다.
Acoustic feature
저자들은 mel-scale spectrogram을 acoustic feature로 사용했습니다. 먼저 침묵을 처리하고 volume을 normalize했습니다. 그리고 난 후 audio를 24kHz로 변환했습니다. 그다음 50ms window length, 12.5 ms hop length, 2048 STFT window size를 사용하여 audio를 STFT했습니다. 그 다음 spectrogram의 magnitude를 변환하여 512-bin mel-scale spectrogram으로 transform합니다. mel-scale spectrogram은 평균을 빼고 표준편차로 나누어서 normalize되었습니다. mel-scale spectrogram을 다시 waveform으로 변환하기 위해, 저자들은 linear scale spectrogram을 recover 하기 위해 inverse linear transformation을 사용했습니다. 그 다음 Griffin-Lim algorithm을 이용하여 waveform을 복원했습니다.
Training details
ADAM optimizer를 사용하여 학습했습니다. batch size는 256으로 두었습니다. model이 overfitting되는 것을 막기 위해, 저자들은 각 layer마다 0.5 dropout rate를 이용한 dropout을 진행했습니다. λ_rec은 10으로, λ_set은 0.01로 두고 학습을 진행했다고 합니다.
Experiments
저자들은 CSTR VCTK Corpus를 이용해 평가를 진행했습니다. audio data는 109명 speaker가 영어를 서로 다른 accent로 녹음했습니다. 저자들은 20명의 utterance를 random하게 선택하여 test set으로 두었으며 나머지 utterance의 90%는 train set으로 사용하고 나머지 10%는 validation set으로 사용했다고 합니다. fully-convolutional architecture이기 때문에 학습할 때 segment length가 128로 두었지만, inference할 때 model은 어떠한 length의 input도 처리할 수 있습니다. 128 frame보다 짧은 utterance들은 제거했으며, training set은 16000개의 utterance를 포함하게 되었습니다.
Evaluation of disentanglement
IN layer의 효과를 확인하기 위해, 저자들은 ablation study를 진행했습니다. 이를 통해 content encoder가 speaker characteristic의 information을 제거하는 데 IN layer가 효과적임을 증명했습니다. 저자들은 content encoder로 encode된 latent representation이 제공하는 speaker identity를 분류하도록 다른 network를 학습했습니다. 저자들은 3가지 setting에서 분류 정확도를 비교했습니다. IN을 가진 content encoder, IN이 없는 content encoder, speaker encoder에는 IN이 있지만, content encoder에는 IN이 없는 경우에 대해 분류 정확도를 비교했습니다. 결과는 다음과 같습니다.

IN을 content encoder에 사용했을 때 정확도가 현저히 떨어지는 것을 볼 수 있습니다. 즉 IN을 cotent encoder에 적용하면 content encoder에서는 speaker information을 잘 다루지 않는다는 것을 의미합니다. 하지만 content encoder에 IN을 사용하지 않았을 때, 기대보다는 정확도가 낮았습니다. speaker encoder가 adaIN을 통해 decoder의 channel statistic을 control 할 수 있기 때문이라고 저자들은 생각했습니다(speaker encoder의 output이 decoder의 adaIN에 적용되니까). 이렇게 되면 전체 model이 cotent encoder보다는 speaker encoder에서 speaker information을 학습하는 경향이 생기게 됩니다. 즉 speaker encoder가 decoder에서의 영향력이 존재하기 때문에 speaker encoder로 speaker information을 더 다루게 됨을 의미합니다.
이 가정을 확인하기 위해, 저자들은 content encoder에는 IN을 사용하지 않지만 speaker encoder에는 IN을 사용했습니다. speaker encoder에 있는 average pooling과 IN layer의 특성으로 인해(otuput zero-vector), speaker encoder는 더 이상 speaker information을 가지지 않게 되었고, 따라서 전체 model은 cotent encoder를 통해 speaker information을 전달하는 경향을 띄게 되며 그에 따라 classification 정확도가 증가되게 되었습니다.
Speaker embedding visualization
저자들은 speaker encoder가 speaker에 관련된 의미 있는 embedding을 학습한다는 것을 알아냈습니다. seen speaker와 unseen speaker의 utterance를 speaker encoder에 feed하여 구한 embedding을 2D space로 표현했습니다. 결과는 다음과 같습니다.
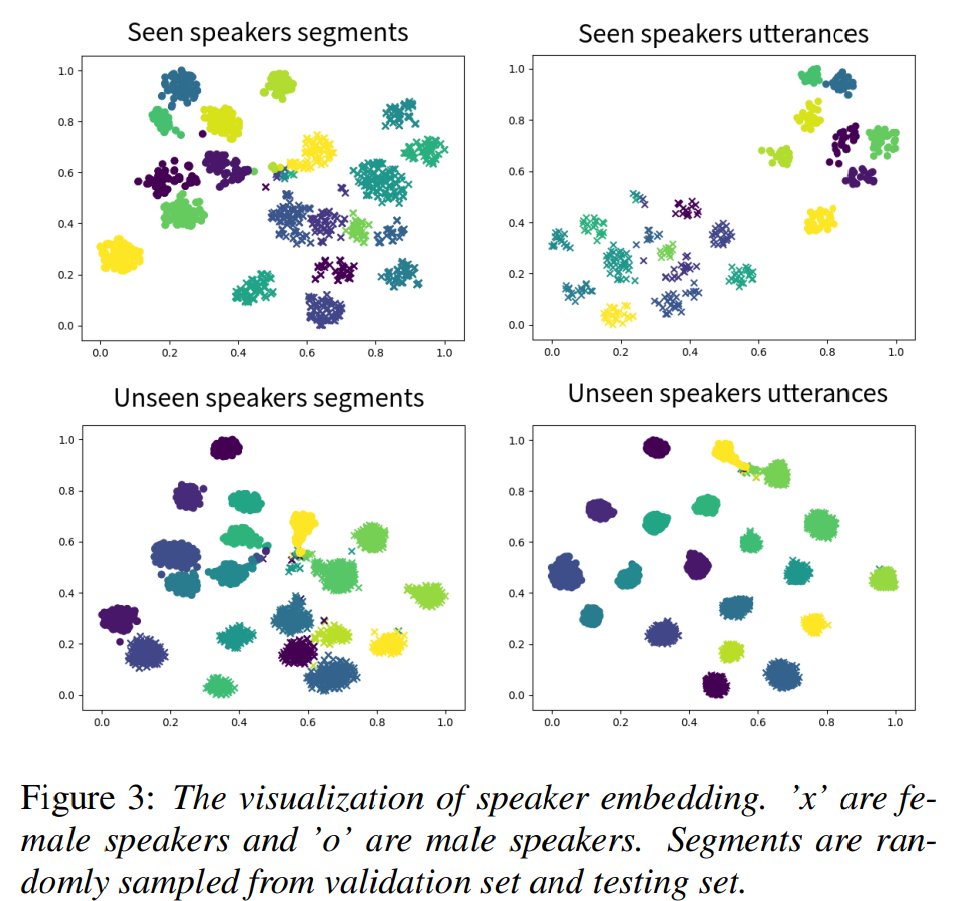
다른 speaker에게서 얻어진 utterance들이 잘 분류된 것을 볼 수 있습니다. 그리고 이 embedding들을 가지고 speaker id를 classify하는 실험도 진행했습니다. seen speaker에 대한 정확도는 0.9973, unseen speaker에 대한 정확도는 0.9998을 달성했으며 speaker encoder가 embedding space에서 의미 있는 representation을 학습한다는 것을 나타내줍니다.
Objective evaluation
- Global variance
저자들의 model이 speaker characteristic을 convert할 수 있음을 보이기 위해, 저자들은 global variacne (GV)을 spectral distribution의 시각화로 사용했습니다. GV는 voice conversion 결과가 target speaker와 맞는지 아닌지를 볼 수 있는 방법 중 하나입니다. male to male, male to female, female to male, female to female라는 4가지 coversion에 대한 실험을 진행했습니다.
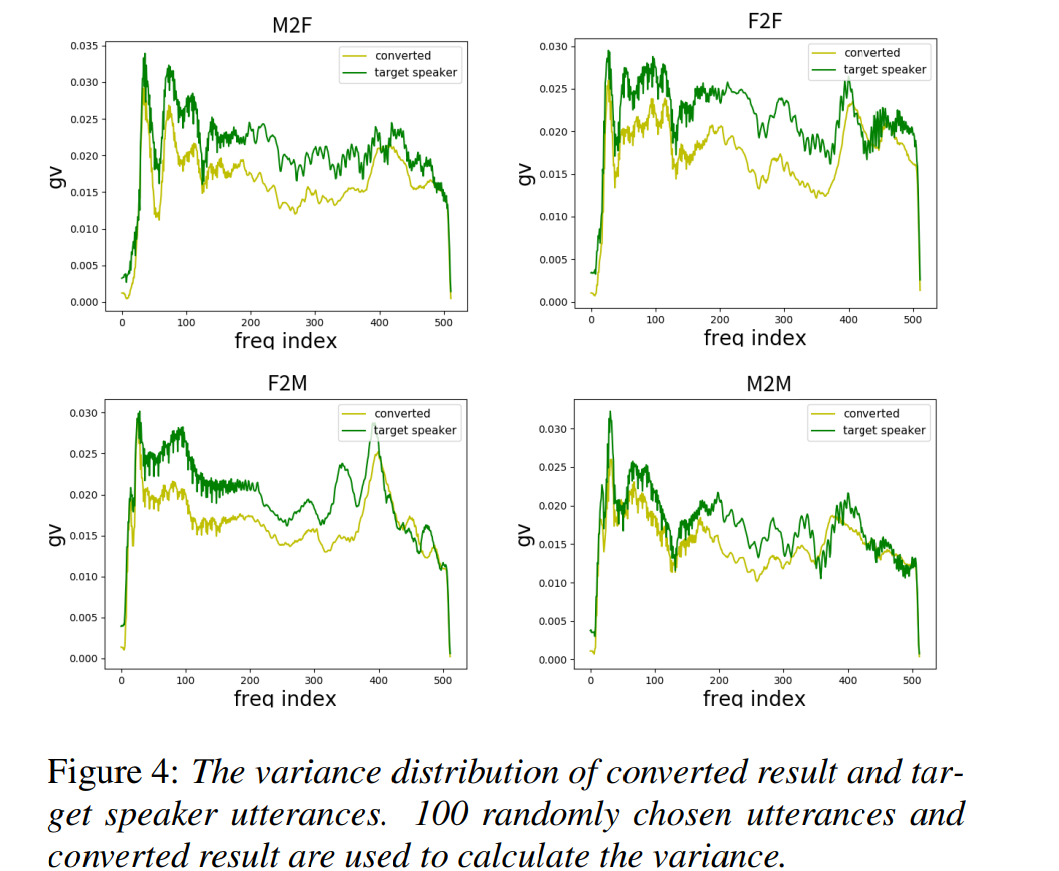
결과는 위와 같습니다. 저자들의 model이 생성한 sample들은 target speaker와 각 frequency에서의 variance가 match하는 것을 볼 수 있습니다.
- Spectrogram example
spectrogram heatmap은 다음과 같습니다.

저자들의 model이 fundamental frequency f_0를 transform할 수 있음을 볼 수 있으며, male to female과 female to male에서 original phonetic content는 모두 잘 유지하는 것을 볼 수 있습니다.
Subjective evaluation
subjective evaluation은 converted voice를 가지고 진행했습니다. 4개의 pair(male to male, male to female, female to male, female to female) 모두 unseen speaker에 대해 진행되었으며, 각 pair의 converted 결과는 하나의 source utterance와 하나의 target utterance를 사용하여 구해졌습니다. 그다음 평가자들에게 두 utterance가 얼마나 비슷한지에 대해 4-scale score test를 부탁했습니다. 결과는 다음과 같습니다.

Conclusion
저자들은 새로운 one-shot unsupervised VC를 제안했습니다. instance normalization을 사용하여 model이 representation을 분리할 수 있도록 만들었습니다. 그리고 저자들의 model은 1개의 utterance를 가지고 unseen speaker로의 VC를 수행할 수 있습니다. objective, subjective evaluation을 진행하여 target speaker와 비슷한 utterance를 만들어낸다는 것을 증명했습니다. 또한 disentanglement experiment와 visualization을 통해 저자들의 model이 어떠한 supervision 없이도 speaker encoder가 의미 있는 embedding space를 학습한다는 것을 보였습니다.



