https://arxiv.org/abs/1804.02812
Multi-target Voice Conversion without Parallel Data by Adversarially Learning Disentangled Audio Representations
Recently, cycle-consistent adversarial network (Cycle-GAN) has been successfully applied to voice conversion to a different speaker without parallel data, although in those approaches an individual model is needed for each target speaker. In this paper, we
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
최근에, cycle-consistent adversarial network (Cycle-GAN)이 parallel data 없이 다른 speaker로의 voice conversion에서 성공적으로 적용되었습니다. 하지만, 이러한 방식에서는 각 target speaker 마다 독립적인 model이 필요합니다. 이 논문에서, 저자들은 voice converison을 adversarial learning frame으로 구현하는 방식을 제안하며, single model로 parallel data 없이도 여러 speaker의 voice로 convert를 수행할 수 있습니다. 이를 저자들은 speech signal에서 linguistic content와 speaker characteristic을 분리하는 방식으로 수행합니다.
먼저 speaker independent latent representation과 별도의 보조 speaker classifier를 사용하여 speaker embedding을 추출하도록 autoencoder를 학습시킵니다. 그다음 decoder는 speaker independent latent representation과 target speaker embedding을 input으로 받아서 target speaker의 voice로 speech를 생성합니다. decoder output의 quality는 generator와 discriminator에 의해 생성된 residual signal로 보완되어 더욱 향상됩니다. preliminary experiment에서 20명의 target speaker에 대해 test를 진행했으며, 매우 좋은 quality를 얻을 수 있었다고 합니다.
Introduction
speech signal은 본질적으로 linguistic information과 acoustic information 모두를 담고 있습니다. Voice Conversion (VC)는 특정 acoustic domain에서 speech signal을 linguistic content는 유지한 채로 다른 acoustic domain으로 변환하는 것을 목표로 합니다. acoustic domain의 예로는 speaker identity, speaking style, accent, emotion 또는 linguistic content와 직교하는 다른 성질들이 있습니다. VC는 speech enhancement, language learning과 같은 다양한 task에서 사용될 수 있습니다. 이 논문에서는 speaker identity의 conversion에 focusing합니다.
일반적으로 aligned data가 있어야 하고 signal이 oversmoothing하게 되는 것과 같이 해결하기 어려운 문제들이 VC에 존재합니다. aligned corpora를 얻는 것이 어렵기 때문에, VAEs나 GAN과 같은 generative model을 사용하는 연구들이 등장했습니다. 왜냐하면 이러한 generative model들은 non-parallel data로 학습될 수 있기 때문입니다. VAEs에서는, encoder가 speaker independent linguistic content를 학습하고, encoder의 output이 decoder에 feed되어 특정한 speaker id의 voice를 생성할 수 있습니다. Cycle-consistent adversarial network (Cycle-GAN)는 unsupervised 방식으로 source speaker를 target speaker로 mapping하는 것을 학습합니다.
VAE를 사용하여 성공적으로 VC를 수행했던 이전 연구들이 있지만, frame별로 voice를 생성했었습니다. 또 다른 연구는 representation을 학습할 때 speaker characteristic으로부터 linguistic content를 분리할 수 있었지만, heuristic assumption을 기반으로 동작했었습니다. Cycle-GAN은 parallel data 없이 VC를 수행할 수 있지만, 각 target speaker에 대해 individual model이 필요하다는 단점이 존재합니다. 이 논문에서 저자들은 여러 frame을 한번에 다룰 수 있고, 여러 frame을 한번에 다루다 보니까 인접한 frame들을 고려한 information을 사용하기 때문에 더 좋은 결과를 보이는 autoencoder architecture를 제안합니다. 저자들이 제안한 model은 heuristic assumption의 필요성을 제거하기 위해 공동으로 train된 speaker classifier를 사용합니다. 이 방식은 single model이 여러 다른 speaker의 voice로 convert 할 수 있도록 학습되며, parallel data가 필요하지 않습니다. 이를 위해 linguistic content와 speaker characteristic을 분리하여 진행합니다. representation을 분리하도록 학습하는 다양한 computer vision 연구들 또는 conditional input으로 하여 shared generator를 사용하는 다양한 computer vision 연구들과 비슷한 방식입니다.
저자들이 제안한 model은 two stage를 포함합니다. stage 1에서, 저자들은 autoencoder를 학습합니다. encoder는 input spectra를 latent representation으로 encode합니다. encoder는 adversarial training 방식으로 speaker characteristic을 제외하고 linguistic content를 표현하는 representation을 만들도록 학습됩니다. latent representation을 기반으로 speaker를 분류하도록 학습되는 classifier를 학습하여 이를 수행합니다. 동시에 encoder는 classifier를 속이도록 학습됩니다. 반면에, decoder는 latent representation과 speaker identity를 merge하여 original spectra를 reconstruct합니다.
stage 2에서, 저자들은 decoder output의 residual signal (fine structure)을 생성할 수 있도록 다른 generator를 학습합니다. decoder output은 residual signal로 보정되어 최종 output을 만들어냅니다. generator는 input signal이 realistic 한 지 아닌지 대해 scalar 값을 output하는 discriminator와 함께 학습됩니다. discriminator는 input signal의 speaker를 예측하는 보조 classifier를 이용해 더 학습됩니다. 이를 통해 generator가 더 많은 target speaker의 characteristic을 생성하도록 만들어줍니다.
Proposed Approach
x ∈ X를 acoustic feature sequence라고 하고, X는 모든 acoustic feature sequence들의 collection이라고 하겠습니다. 그리고 y ∈ Y를 speaker라고 하고, Y는 collection X를 생성하는 모든 speaker들의 group이라고 하겠습니다. training set D = {(x_1, y_1), ... , (x_m, y_m)}은 m개의 (x_i, y_i) pair를 포함하고 있으며, sequence x_i는 speaker y_i에 의해 생성됩니다. training 과정에서 x는 X로부터 random하게 sample되는 고정된 길이의 segment입니다. test할 때 x는 가변 길이가 되는데, test에 사용되는 model은 recurrent-based component로 구성되기 때문입니다. 전체 framework는 다음과 같이 표현할 수 있습니다.

Stage 1: Autoencoder plus classifier-1
이 stage에서는 autoencoder와 classifier-1을 학습합니다.
- Autoencoder
encoder (Block(A))는 input sequence x를 latent representation enc(x)로 mapping하도록 학습됩니다. decoder (Block(B))는 주어진 speaker identity y와 enc(x)를 가지고 x를 reconstruct한 x'를 생성하도록 학습됩니다.

Mean Absolute Error (MAE)를 minimize하는 방식으로 autoencoder를 학습시킵니다. MAE를 사용하면 MSE를 사용했을 때 보다 더 sharp한 output을 생성합니다. 그렇기 때문에 저자들은 MAE를 사용했다고 합니다. reconstruction loss는 다음과 같이 작성할 수 있습니다.
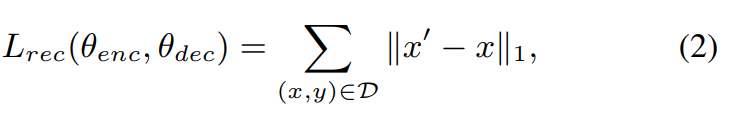
여기서 θ_enc는 encoder의 parameter를 의미하고 θ_dec는 decoder의 parameter를 의미합니다. 이 autoencoder는 단독으로 VC를 수행할 수 있습니다. source speaker y가 생성한 utterance x가 주어졌을 때, decoder는 x의 linguistic content를 사용하여 target speaker y'의 voice를 생성할 수 있습니다.
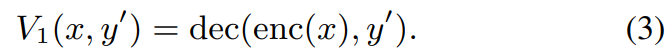
training할 때, decoder의 input은 enc (x), y입니다. 하지만 voice conversion을 할 땐, y를 target speaker y'으로 대체합니다. V_1(x,y')은 stage 1의 output이 됩니다. 이는 linguistic content x와 speaker identity y'를 가지고 만들어진 output입니다.
- Classifier-1
식 (2)를 통해 학습된 autoencoder는 latent representation enc(x)를 speaker-independent하게 만들 수 없습니다. enc(x)에 존재하는 original speaker x의 speaker characteristic은 VC의 성능을 불가피하게 저하시킵니다. 그래서 저자들은 classifier-1 (Block(C))를 추가적으로 학습합니다. 이를 통해 autoencoder가 speaker-independent한 enc(x)를 생성하도록 만듭니다. 각 training pair (x_i, y_i)에 대해서, classifier는 enc(x_i)를 input으로 받고 P(y|enc(x_i))일 확률을 output합니다. 즉 이 확률 값은 x_i가 speaker y에 의해 생성되었을 확률을 의미합니다. classifier-1은 다른 speaker를 구분하기 위해 negative log-probability를 minimize하도록 학습됩니다. 식은 다음과 같습니다.
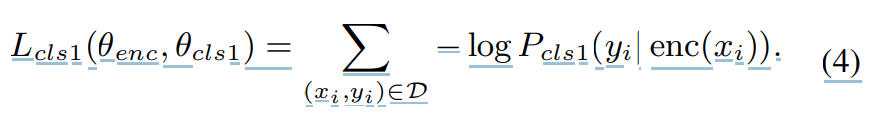
하지만 encoder는 enc(x)에서 speaker identity를 제거하기 위해 위 식을 maximize하도록 학습됩니다. 그래서 classifier-1에 의해 regularize된 최종 autoencoder의 식은 다음과 같습니다.

위 식은 식 (2)와 (4)를 통합한 모습이고, λ는 hyper-parameter를 의미합니다. autoencoder와 classifier는 번갈아가며 학습됩니다.
Stage 2: GAN
만약 stage 1에서 단순히 VC를 수행하면, classifier-1를 사용하더라도 reconstruction loss로 인해 spectrogram이 blurry해지고 artifact가 발생하는 경향이 있습니다. 그래서 stage 2를 사용하여 문제를 해결합니다. stage 2에서 저자들은 generator와 discriminator pair를 사용하여 output spectra를 더 realistic하도록 만들어줍니다.
decoupled learning의 concept을 기반으로 stage 2를 구성합니다. decoder와 generator를 분리하여 GAN train을 안정화하는 방법으로, 다른 generator (Block(D))를 별도로 학습합니다. 이 Block(D)는 enc(x)와 speaker identity y''를 input으로 받습니다. 여기서 y''은 Y들 중 균형 있게 sample되는 speaker입니다. Block(D)는 input을 받아 decoder output (Block(B))의 residual (fine signal)을 생성합니다. encoder (Block(A))의 parameter와 decoder (Block(B))는 stage 2를 학습할 때는 fix시켜 학습을 안정화시킵니다.
위 그림과 같이 generator는 "discriminator plus classifier-2" (Block(E))의 도움을 받아 학습되며, 선택된 target speaker y'로의 VC test를 진행할 때의 최종 output은 decoder (Block(B))의 output과 generator (Block(D))을 더한 형태입니다(y'=y''인 경우에 대해). 식은 다음과 같습니다.

위 식에서 x는 input speech이고, enc(x)는 encoder의 output이며, y'은 선택된 target speaker이고, V_1(x, y')는 stage 1에서 얻어진 converted voice이고, gen(enc(x), y')은 generator의 output이고 V_2(x,y')는 stage 2의 VC result입니다.
generator는 adversarial network에서 discriminator (Block(E))로 학습이 진행됩니다. 이 discriminator는 input acoustic feature sequence x가 real인지 생성된 것인지에 대해 구별할 수 있도록 학습이 진행됩니다. discriminator D(x)의 output은 x가 얼마나 진짜 같은지를 나타내는 scalar이며, D(x) 값이 클수록 x가 실제일 가능성이 높다고 판단합니다. adversarial network는 다음 loss 식을 이용해 학습됩니다.
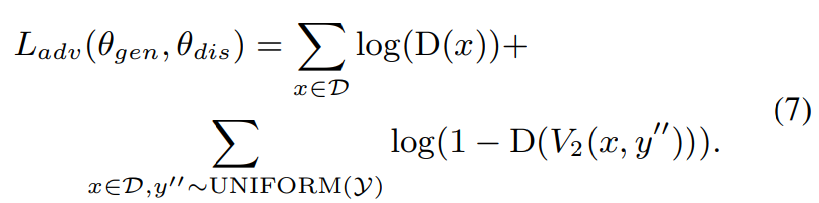
θ_gen은 generator의 parameter이고 θ_dis는 discriminator의 parameter입니다.
discriminator는 dataset D에서 얻은 real speech x에 대해서는 큰 value를 return하고, speech V_2(x,y'')에 대해서는 낮은 score를 return할 수 있도록 학습됩니다. 그래서 discriminator는 위 loss를 maximize하도록 학습되면서 real voice와 generated data를 구별할 수 있도록 학습됩니다.
또한, "discriminator plus classifier-2"는 speech x의 speaker를 예측할 수 있도록 학습되는 classifier-2가 포함됩니다. classifier-2는 다음 식을 minimize하는 방식으로 학습됩니다.
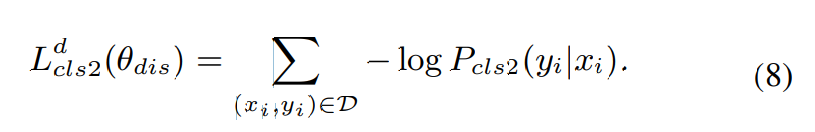
classifier-2와 discriminator는 마지막 layer를 제외한 모든 layer를 공유합니다. generator는 Y에서 균일하게 sampling된 speaker y''에 대해 voice V_2(x,y'')을 생성해야 하며, V_2(x,y'')가 y''의 speaker characteristic을 더 많이 보존해야 한다는 것을 의미합니다. 그래서 generator는 다음 loss를 minimize하는 방식으로 학습됩니다.
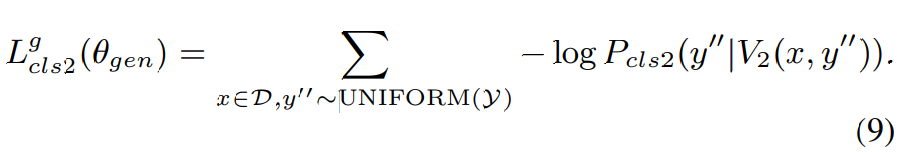
식 (8)과 식 (9)은 동일한 구조이지만, (8)은 실제 data와 dataset의 correct speaker에 대한 것이고, (9)는 생성된 voice와 target speaker에 대한 식입니다.
그래서 stage 2에서의 최종 loss function은 다음과 같습니다.
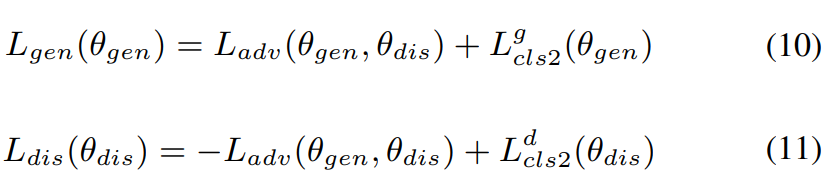
식 (10)은 generator θ_gen에 대한 loss function이고, 식 (11)은 discriminator θ_dis에 대한 loss function입니다.
Implementation
저자들의 model architecture는 다음과 같습니다.

다양한 길이의 input을 다루기 위해 저자들은 time-step에 대한 fully connected layer를 사용하지는 않았습니다. convolution bank는 acoustic feature에 대한 local information을 capture할 수 있기 때문에 사용했습니다. 저자들은 high resolution spectra를 만들기 위해 pixel shuffle layer를 사용했다고 합니다. emb_l(y)가 l번째 layer의 speaker embedding을 의미합니다. embedding을 feature map에 더하는 방식으로 사용했다고 합니다. 그리고 discriminator를 제외한 모든 network에 1d convolution을 사용했으며, discriminator는 2d convolution을 사용했을 때 더 좋은 성능을 보였다고 합니다.
Experiments
저자들은 CSTR VCTK Corpus를 사용하여 VC model을 평가했습니다. audio data는 109명의 English speaker에 의해 녹음되었으며, 각 speaker마다 서로 다른 악센트를 가지고 있다고 합니다. 각 speaker들은 서로 다른 sentence를 녹음했습니다. 저자들은 10명의 남성과 10명의 여성으로 구성된 20명의 speaker를 subset으로 선택하여 사용했다고 합니다. dataset은 random하게 90% data들은 train data로, 10% data는 test data로 나눴다고 합니다. 저자들은 acoustic feature로 log-magnitude spectrogram을 사용했습니다.
저자들은 encoder와 decoder를 8000 mini-batch로 pre-train했습니다. 그다음 classifier-1을 20000 mini-batch로 pre-train했다고 합니다. Stage 1은 80000 mini-batch로 학습되었으며, stage 2는 50000 mini-batch로 학습되었다고 합니다.
Objective evaluation
모든 frequency에 대한 다양한 분포는 speech signal의 매우 바람직한 성질이며, 대부분의 conventional approach들은 over-smoothed spectra들을 생성했으며, 이는 voice conversion에서 주된 문제 중 하나였습니다. spectrum에서 Global Variance (GV)를 계산함으로써 이러한 성질이 관측할 수 있습니다. 높은 global variance는 converted speech의 sharpness를 나타내줍니다. 저자들은 4가지 conversion에 대한 frequency의 global variance를 평가했습니다(남성에서 남성으로, 남성에서 여성으로, 여성에서 남성으로, 여성에서 여성으로). 결과는 다음과 같습니다.

위 그래프에서 (a)는 classifier-1을 사용하지 않고 stage 1의 autoencoder만 사용한 경우를 의미합니다. (b)는 classifier-1을 이용한 stage 1을 의미합니다. (c)는 stage 1과 stage 2를 포함한 저자들이 제안한 방식을 의미합니다. 모든 case에서, 저자들이 제안한 (c)가 가장 뛰어난 sharpness를 나타내는 것을 볼 수 있습니다. 저자들이 제안한 방식이 가장 큰 global variance를 갖습니다.

그리고 위 그림은 spectrogram을 보여주고 있습니다. original (a)를 (b), (c), (d)로 변환한 결과를 spectrogram으로 표현한 모습입니다. 이를 통해 저자들이 제안한 방식이 sharpness를 향상시키는 것을 볼 수 있습니다.
Subjective evaluation
그리고 저자들은 subjective human evaluation을 진행했습니다. 20명의 평가자들이 있고, 각 평가자들은 변환된 pair를 random하게 받아서 어떤 sample이 가장 자연스러운지, target speaker가 만든 referenced target utterance와 가장 유사한 것은 무엇인지에 대한 평가를 진행했습니다.

왼쪽 결과는 stage 2에 대한 ablation study 결과를 보여주고 있습니다. stage 2가 자연스러움과 유사도에 있어서 voice quality를 향상시켜주는 것을 볼 수 있습니다. 오른쪽은 parallel data를 사용하는 Cycle-GAN-VC와 비교한 결과를 보여주고 있습니다. 저자들이 제안한 model은 parallel data가 아니어도 비교가능할 정도의 좋은 성능을 보여줍니다.
Conclusion
speaker-independent representation을 추출함으로써 voice conversion을 수행하는 method를 제안합니다. parallel data를 필요로 하지 않으며, 단일 model multiple target speaker로의 변환을 수행할 수 있습니다. residual signal을 더하는 것이 변환된 speech의 quality를 상당히 향상시킬 수 있다는 것을 알아냈습니다. global variance에 대한 objective evaluation metric을 통해 저자들이 제안한 방식으로 sharp voice spectra를 생성할 수 있음을 보여줍니다. 그리고 subjective human evaluation으로도 성능을 증명했습니다.



