https://arxiv.org/abs/2311.05844
Face-StyleSpeech: Improved Face-to-Voice latent mapping for Natural Zero-shot Speech Synthesis from a Face Image
Generating a voice from a face image is crucial for developing virtual humans capable of interacting using their unique voices, without relying on pre-recorded human speech. In this paper, we propose Face-StyleSpeech, a zero-shot Text-To-Speech (TTS) synth
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문에서는 Face-StyleSpeech라는 zero-shot TTS synthesis model을 제안합니다. 이 model은 reference speech가 아닌 face image를 condition으로 하여 자연스러운 speech를 생성할 수 있습니다. 저자들은 face image로 speaker identity와 prosody를 학습하도록 만들었지만 이는 상당히 어려운 문제입니다. 이 문제를 해결하기 위해 저자들의 TTS model은 face encoder와 prosody encoder 모두 사용합니다. prosody encoder는 prosodic feature만 capture 하고 face image를 capture 하지 않는 형태이며, face encoder는 face image에서 speaker identity만 capture 합니다.
Introduction
zero-shot (adaptive) TTS model은 어떠한 fine-tuning 없이 주어진 text와 reference speech로 target speaker의 voice에 맞는 음성을 합성하는 것입니다. 최근에는 reference speech를 prosody나 speaker identity와 같은 speech feature를 다루는 latent speech vector로 embed하는 speech encoder를 사용합니다.
text와 face image로 speech를 합성하는 것은 reference speech에 의존하지 않은 형태로 새로운 voice를 생성하는 유망한 방법 중 하나입니다.
이전 연구들에서는 speech vector를 face image로부터 얻어지는 latent face vector로 mapping하거나 replace하는 방식으로 model을 구현했었습니다. 하지만, face image로부터 자연스러운 음성을 합성하기엔 여전히 여러 문제들이 남아있었으며, face vector 하나로 모든 speech feature를 capture하는 것이 불가능하다는 점이 그중 하나였습니다. 직관적으로, 얼굴은 speaker identity와 상당히 연관되어 있습니다. 하지만 face를 prosody로 mapping하는 것은 상당히 어려우며, 얼굴 특성은 모든 prosodic feature를 다루지는 못합니다.
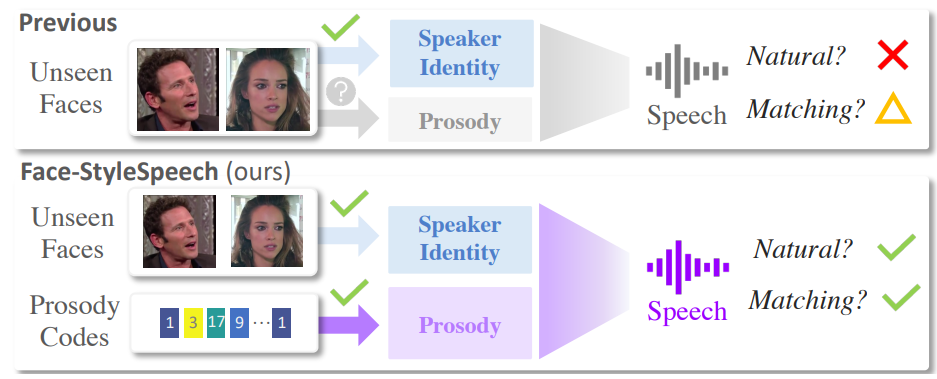
위 그림과 같이 speaker의 identity (e.g., gender, age, ... )는 그들의 얼굴로부터 얻어질 수 있지만, speech의 type (e.g., audiobook, narration, dialogue)과 dynamics (e.g., intonation, stress, rhythm)은 face image로부터 얻을 수는 없습니다. 이러한 내재된 모호성은 face-to-voice latent mapping 정확도를 감소시킵니다.
이 논문에서, 저자들은 Face-StyleSpeech라는 zero-shot TTS model을 제안합니다. 해당 model은 latent speech vector에서 prosody를 분리하였고, 그에 따라 face-to-voice latent mapping 성능을 향상시켜 face imge로부터 상당히 자연스러운 speech를 합성할 수 있었습니다. speech vector에서 prosody를 분리하기 위해 zero-shot TTS model을 prosodic feature를 encode하는 prosody encoder를 가지고 학습시켰습니다. 결과적으로 face image에서 얻은 face vector는 speaker identity와 적절히 match되었습니다. 저자들의 main contribution은 다음과 같습니다.
- face image로부터 자연스러운 speech를 생성할 수 있는 Face-StyleSpeech라는 zero-shot TTS model을 제안합니다.
- face-to-voice mapping 성능을 향상시키기 위해, zero-shot TTS model은 speech vector에서 prosody feature를 분리하는 방식을 사용합니다.
- 실험에서, 저자들은 unseen face image로 생성한 speech의 자연스러움을 상당히 향상시켰다는 것을 명시적으로 보였습니다.
Face-StyleSpeech
저자들은 target speaker의 face image로부터 자연스러운 speech를 합성하는 것이 goal입니다. model architecture는 다음과 같습니다.
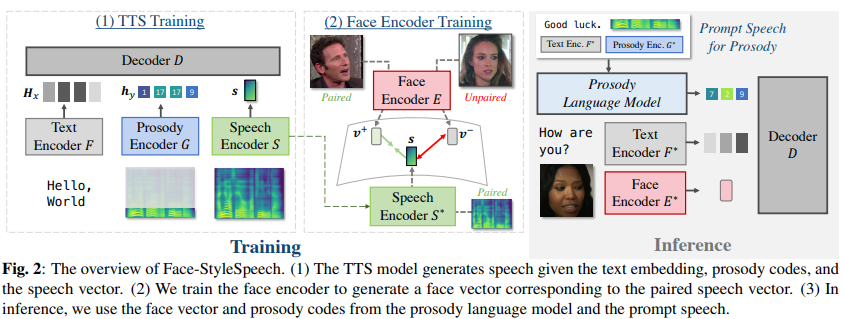
Zero-shot adaptive Text-to-Speech Model
N개의 text sequence x, speech (mel-spectrogram) Y pair로 training set이 있다고 하겠습니다. 학습을 할 때 TTS model은 주어진 text x와 speech Y를 가지고 ground truth speech Y를 reconstruct하는 것이 목표입니다. non-autoregressive zero-shot TTS model은 3가지 module로 구성됩니다. text encoder F, speech encoder S, decoder D입니다.
text encoder F는 input text sequence를 representation H_x로 encode합니다. speech encoder S는 speech Y를 speaker vector s로 encode합니다. 이전 연구들에서 Aligner를 사용하기도 합니다. aligner는 text와 speech를 monotonic alignment하도록 정렬해 줍니다. aligner는 각 phoneme의 duration을 output합니다. 그다음 duration predictor가 주어진 H_x와 s를 가지고 각 phoneme의 duration을 예측하도록 학습시킵니다. duration이 주어지면, text representation을 target speech의 길이와 맞도록 확장시킵니다. decoder D는 주어진 text representation과 speaker vector를 가지고 target speech Y를 reconstruct합니다.
inference stage에서, model은 text x, text x와 다른 내용인 reference speech Y_r을 받습니다. 학습된 TTS model은 Y를 합성합니다. 식은 다음과 같습니다.
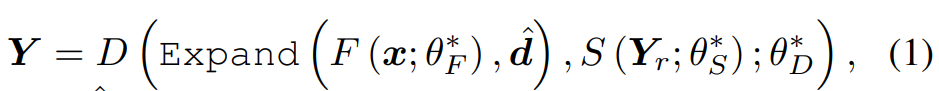
여기서 d^은 duration predictor로 예측된 duration이며, θ*은 training set으로 학습된 parameter를 의미합니다.
Face Encoder Training for Face-to-Voice Mapping
reference speech의 voice를 복제할 수 있는 zero-shot TTS model을 학습시키는 것이 목표입니다. 그래서 저자들은 face image에서 speech vector를 생성하는지에 focus를 맞췄습니다. 결과적으로, 저자들은 face encoder E의 output이 그에 대응하는 speech vector로 mapping할 수 있도록 학습시켰습니다. dataset (Y_i, I_i)가 있으며, 해당 dataset은 M개의 speech (Y), face image (I) pair로 구성됩니다. face encoder를 사용하여 face image를 face latent vector로 embed합니다. 그리고 speech는 pre-trained speech encoder를 사용하여 speaker vector로 embed합니다. 그다음 저자들은 MSE loss와 negative cosine similarity loss를 사용하여 face encoder를 학습합니다. 그리고 저자들은 서로 다른 얼굴에서 동일한 face vector가 구해지는 collapse를 막기 위해 contrastive learning을 사용했습니다. 최종 식은 다음과 같습니다.
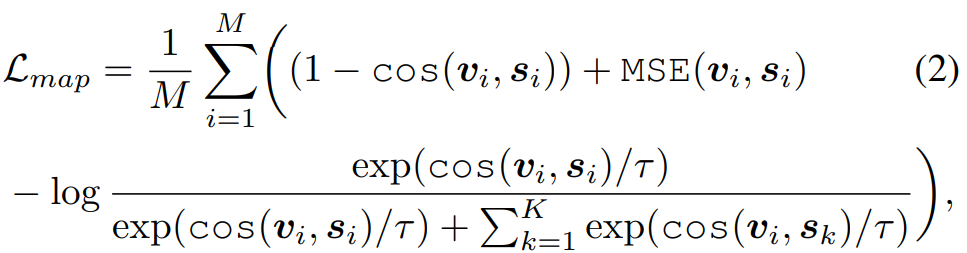
위 식에서 K는 negative sample 수를 의미하고, τ = 0.07로 두었다고 합니다.
위 식을 minimize하는 parameter를 가지고 있는 학습된 face encoder E*는 TTS model에서 사용되는 speech vector s를 대체할 수 있는 latent face vector v를 만들 수 있습니다. 하지만 TTS model이 speech vector s에만 의존하여 prosody나 speaker identity를 포함하는 모든 speech feature를 encode한다면, E*로부터 구해지는 face vector는 자연스러운 음성을 합성하지 못할 수 있습니다. 왜냐하면 face image와 prosody에는 강한 correlation가 존재하지는 않기 때문입니다.
Disentangle Prosody from Speech Vector for Improved Face-to-Voice Mapping in Latent Space
facial feature과 speech의 prosodic feature를 matching하는 것은 어렵습니다. prosodic feature를 포함하는 speech vector로 face를 mapping 한다면, unseen face로부터 생성된 speech는 부자연스러운 prosody를 띄게 됩니다.
만약 face encoder가 성별과 같은 주요한 facial feature만 capture한다면, 그에 비슷한 목소리를 갖는 speech를 합성할 순 있습니다. 결과적으로, 저자들은 speech encoder에서 추출한 speech vector와 독립적인 prosody를 encode하는 prosody encoder를 제안합니다.
Encoding Prosody with Vector Quantization
학습할 때, prosody encoding은 target speech Y를 가지고 진행될 수 있습니다. 그러므로 저자들은 speech로부터 prosodic feature를 추출하는 prosody encoder를 사용합니다. 구체적으로, prosody encoder G는 speech Y를 representation H_y = G(Y,d;θ_G)로 encode합니다. 여기서 duration d를 이용해 phoneme-level pooling을 수행합니다. 하지만 이 방법은 prosody encoder에서 prosody feature를 얻고 이를 speaker identity와 얽히게 만들 수 있습니다. prosody encoder G는 speaker identity와 얽히지 않고 오직 prosody feature만 얻고 싶은 상태인데, speaker identity와 얽힌 output을 만들어 낼 수 있음을 의미합니다.
이를 해결하기 위해, 저자들은 mel-spectrogram Y의 low-frequency feature만 사용하고 prosody encoder의 information bottleneck으로 vector quantization VQ를 사용합니다. VQ를 통해 representation H_y에 존재하는 각 prosody feature들이 codebook C로 mapping됩니다. prosody encoder의 output인 representation H_y를 discrete codes h_y로 encode할 수 있게 됩니다. h_y는 mapping된 feature들을 의미합니다. 그다음, H_y를 Y와 동일한 길이가 되도록 확장시키면 됩니다. decoder D는 prosody representation과 speech vecotr를 가지고 Y를 reconstruct하게 됩니다.
Prosody Code Generation with Language Modeling
inference stage에서, 학습된 TTS model은 target text x와 학습된 face encoder에서 구한 face vector v를 가지고 speech를 합성합니다. 이러한 맥락에서, prosody modeling을 위한 prosody code는 target text x로부터 예측되어야만 합니다. train할 때는 target speech로부터 prosody embedding을 구했었는데, inference할 때는 target text x로부터 예측되어야 합니다.
그래서 저자들은 Prosody Language Model (PLM)을 사용하여 x에 맞는 prosody code h_y를 생성합니다. 주어진 prompt speech Y^p와 그에 맞는 transcript x^p를 가지고 autoregressive modelling을 통해 진행됩니다.
즉 PLM에 target speaker와 관계없어도 상관없는 음성과 text를 input해줍니다. 이를 통해 codebook을 구할 수 있으며, 구한 codebook을 VQ의 codebook으로 사용합니다.
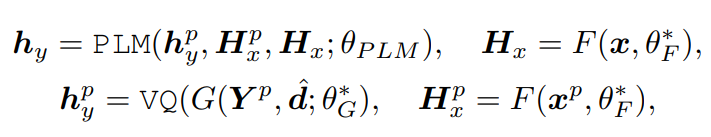
위 식에서 d^ 은 duration predictor로 예측된 x^p의 duration입니다. prompt speech Y^p가 우리가 목표로 하는 speaker로부터 생성된 voice일 필요는 없습니다. 왜냐하면 prompt speech는 단지 prosody code를 생성할 때 사용될 뿐이기 때문에, 꼭 target으로 하는 speaker로부터 구해질 필요는 없습니다. PLM training에서, 저자들은 TTS training dataset을 가지고 teacher forcing을 사용했습니다. PLM을 이용해 prosody code를 생성한 다음, h_y^p를 VQ에 사용되는 codebook을 가지고 representation H_y로 decode합니다. 이를 통해 최종적으로 image로부터 특정 voice의 natural speech를 생성할 수 있게 됩니다. 식은 다음과 같습니다.
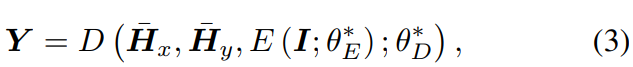
여기서 H-는 predicted duration d^를 가지고 확장된 representation입니다. 결국 이전에 소개한 prosody encoder는 train 시에만 사용되며, inference할 때는 PLM을 거쳐 나온 prosody code를 VQ에 넣어 output을 구해줍니다. 그 output을 expand하여 decode에 넣어주어 최종 speech를 synthesis합니다.
Experiments
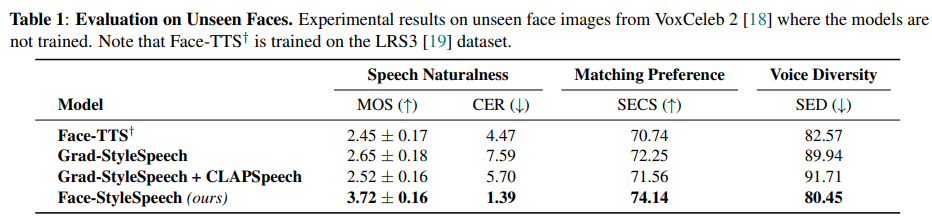
face image를 condition으로 하여 TTS를 진행한 결과입니다. 저자들의 Face-StyleSpeech가 가장 높은 MOS를 보이면서 낮은 CER을 보입니다. 즉 Face-StyleSpeech가 더 자연스러운 음성을 생성한다는 것을 의미합니다. Face-StyleSpeech는 선호도 관점에서 baseline들보다 뛰어난 성능을 보여줍니다. SECS는 speaker embedding cosine similarity를 의미하는데, 이 값도 가장 좋은 것을 볼 수 있습니다.
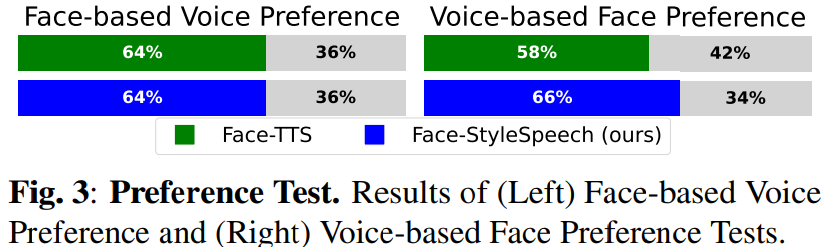
위 실험 결과는 preference 결과를 그래프로 보여준 모습입니다. face-based voice preference tset의 정확도는 모두 64%입니다. 즉 얼굴을 보여주고 해당 얼굴에 맞는 voice를 선택했을 때의 정확도입니다. voice를 기반으로 선호하는 face를 선택하는 실험에서는 저자들의 model이 더 높은 정확도를 보이는 것을 볼 수 있습니다.
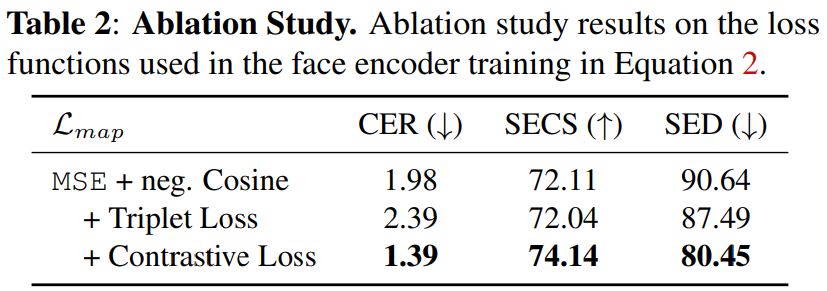
그리고 ablation study 결과입니다.
Conclusion
이 논문에서, 저자들은 Face-StyleSpeech를 제안합니다. 이는 zero-shot TTS model인데, reference speech 대신 face image를 가지고 자연스러운 음성을 합성합니다. face image와 prosody 사이의 correlation이 낮다는 문제를 해결해야만 했습니다. 그래서 저자들은 prosody encoder를 TTS model에 적용하여 speaker vector와 prosody를 분류할 수 있었습니다. 이를 통해 model이 face-to-voice mapping 성능을 향상시켜 좀 더 자연스러운 음성을 생성시킬 수 있었습니다.



