https://dl.acm.org/doi/10.1145/3474085.3475198
해당 논문을 보고 작성했습니다.
Abstract
얼굴과 voice 사이에는 강한 relatioship이 존재하기 때문에, face representation으로 다양한 voice characteristic을 합성하는 것은 매우 유망한 접근 방법입니다. 그래서, 사람얼굴로 voice style을 생성할 수 있는 새로운 idea를 제안합니다. 하지만 audio-visual relationship이 암묵적입니다. 또한, 기존의 Voice Conversion model들은 speaker의 사진 없이 모아진 data를 사용하여 학습되었으며, 사진과 audio가 모두 포함된 dataset은 실생활에서 얻어지는 dataset입니다. target audio를 바로 target photo로 대체하고 실생활 dataset으로 학습하는 것은 noisy한 결과를 야기합니다.
이러한 문제를 다루기 위해, 저자들은 새로운 many-to-many voice conversion framework를 제안합니다. 이름은 Face-based Voice Conversion (FaceVC)이며, 이는 3개의 training strategy로 학습됩니다.
Introduction
이 논문에서는 face가 voice와 매우 연관이 있다는 연구 결과를 토대로, 새로운 voice conversion approach를 제안합니다. target speaker의 speech corpus 대신 face image에 대응하는 target voice로 합성하는 방식입니다. original speaker의 voice와 동일한 음색을 만들어내는 것이 아니라, target speaker의 얼굴을 보고 그에 대응할만한 voice style을 생성하여 face-based voice conversion을 진행합니다.
face-based VC를 수행할 때, target speaker의 acoustic feature를 facial feature로 변환하는 것으로는 해결할 수 없는 2가지 문제가 존재합니다. 먼저 Face-Speech Transformation입니다. facial image와 speech는 cross domain입니다. 남성이 낮은 목소리를 갖는 것과 같이 각각의 dimension 중 일부는 서로 연관이 있지만, 화자의 vocal style 중 facial feature과는 전혀 연관이 없는 것들도 존재합니다. 그래서 VC는 불필요한 information에 의해 쉽게 혼란을 겪을 수 있으며 동일한 speaker에 대한 multimodality를 mapping하는 것을 학습하지 못할 수 있습니다. 이러한 현상은 model이 모든 speaker에 대한 평균 음색만 generate하도록 만들기도 합니다. 두 번째 문제는 Noisy-Clean Transformation입니다. 현재 존재하는 deep-learning 기반 VC 연구들은 상대적으로 간단한 내용으로 구성된 speech dataset으로 수행되며, speaker의 사진은 포함되어 있지 않습니다. 반면, 얼굴과 음성 모두를 포함하고 있는 dataset은 대부분 실제 환경에서 수집되며, 이러한 noise가 많은 dataset에서 변환된 audio는 일반적으로 quality가 좋지 않습니다. speaker face와 깨끗한 speech를 동시에 포함하고 있는 dataset은 존재하지 않기 때문에, 주된 challenge는 '간단한 내용으로 구성된 speech dataset과 실제 환경에서 수집된 data를 어떻게 활용하여 더 나은 결과를 얻을 것인가' 입니다.
한 가지 가능한 solution은 깨끗한 음성을 위해 speaker의 face image를 합성하는 것입니다. 하지만 이러한 face generation module들은 dataset bias에 영향을 받습니다. 그리고 합성된 face는 artifact를 포함할 가능성이 존재합니다.
다른 해결책 중 하나는 TTS system을 사용하여 실제 환경에서 수집된 dataset의 음성을 regenerate하는 것입니다. 불행하게도 합성된 speech는 ground truth speech와 frame-wise matching 할 수 있다는 이점을 잃게 되며, 이는 reconstruction에 대한 추가적인 alignment가 필요하다는 것을 의미하게 됩니다. 또한 TTS를 이용해 합성한 speech는 원본 sentence의 감정을 잃게 됩니다.
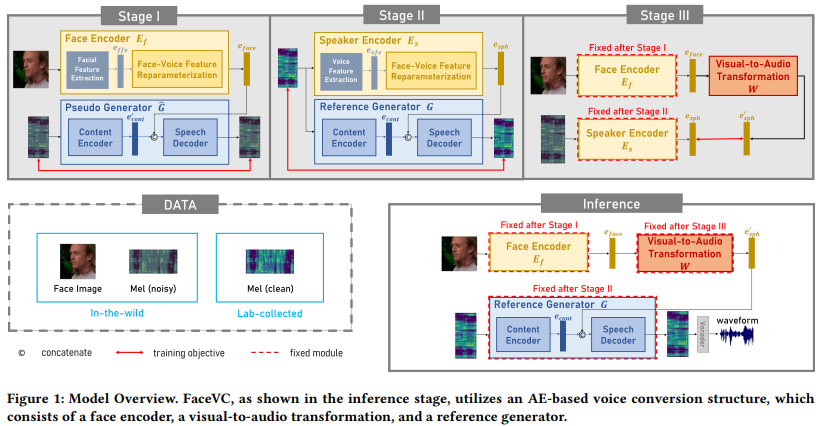
저자들은 이러한 문제를 해결하기 위해 Face-based Voice Conversion (FaceVC)라 불리는 새로운 VC framework를 제안합니다. 그리고 multimodal input으로부터 지식 전이를 달성하기 위한 잘 설계된 train strategy를 제안합니다. 구체적으로 FaceVC는 face encoder, reference generator, visual-to-audio transformation으로 구성됩니다. face encoder는 speaker과 관련된 facial feature를 추출하고, face-voice feature reparameterization을 통해 visual speaker distribution을 형성하여 연속적인 speaker style 분포를 구성합니다. 또한, reference generator는 speech로부터 encode된 content와 speaker distribution으로부터 구해진 voice style을 이용하여 converted audio를 생성합니다. 마지막으로 visual-to-audio transformation은 visual speaker distribution을 vocal speaker distribution으로 warp합니다.
추가적으로 두 번째 문제 (dataset problem)를 해결하기 위해, 저자들은 두 dataset을 잘 활용하는 3-stage training strategy를 제안합니다. 실험을 통해 저자들의 model이 target speaker의 음색으로 정확한 voice conversion을 수행하는 것을 보였습니다. 저자들의 contribution은 다음과 같이 요약할 수 있습니다.
- face-based VC framework를 제안합니다. 일반적인 VC framework에서 사용되는 speaker encoder를 redesign하여 새로운 framework를 제안했습니다. 이는 얼굴로부터 speaker 와 관련된 distribution을 얻습니다. 저자들이 알기로는 parallel data 없이 face image를 이용하여 voice를 변환하는 첫 연구라고 합니다.
- 저자들은 laboratory-collected dataset과 in-wild dataset을 사용하는 3-stage training strategy를 제안합니다. 이를 통해 저자들의 converted audio quality는 laboratory-collected dataset만 이용하여 수행되는 만큼 뛰어난 quality를 보여줍니다.
- 실험을 통해 face가 speaker style representation의 source가 될 수 있음을 보여주며, 실제 환경에서 수집된 dataset으로 학습된 model의 결과는 지식 전이 후 더 나은 audio quality를 보여줍니다.
Related Work
Audio-Visual Relationship
speaker의 visual and audio information은 매우 연관성이 높기 때문에, audio-visual relationship은 서로의 잃어버리거나 생략한 information을 채워줄 수 있습니다. 구체적으로 voice separation의 경우, noisy signal에서 speech를 분리하는 것은 어렵기 때문에 이전 연구들은 visual information을 사용하여 speaker의 visual feature를 tracking함으로써 performance를 향상시켰습니다. audiovisual matching task는 audio와 visual modality 사이의 pair relation을 연구하며 이를 통해 deepfake multimedia content를 탐지하는데 사용될 수 있습니다. audiovisual generation 분야에서는 audio-to-visual과 visual-to-audio generation 모두 연구되었습니다.
Methodology
FaceVC의 goal은 content는 보존하면서 facial image에 대응하는 음색을 변환하는 것입니다. conventional VC는 original speaker (source)의 audio waveform을 수정하여 target speaker가 말하는 것처럼 보이게 만듭니다. 하지만, target speaker의 speech corpus를 필요로 하며, 많은 비용이 들게 됩니다. 따라서 얼굴 image에 대응하는 voice를 합성하기 위해, 저자들은 auto-encoder 기반 VC architecture를 제안합니다. 이는 face encoder, reference generator, visual-to-audio transformation, vocoder로 구성됩니다. face encoder는 얼굴 image에서 feature를 추출합니다. reference generator는 clear speech content embedding을 추출하고 다른 speaker로부터 변환된 audio를 생성합니다. visual-to-audio transformation은 face encoder로부터 구한 visual feature를 target speaker feature로 변환합니다. vocoder는 spectrogram으로 speech waveform을 생성합니다. 구조는 다음과 같습니다.
Face Encoder
face encoder는 각 speaker마다 구분 가능한 face embedding을 얻는 것을 목표로 합니다. VC는 새로운 얼굴을 이용해 voice를 합성하는 것을 목표로 합니다. training data에서 얻어지는 face embedding은 latent space에서 새로운 얼굴의 representation을 정확히 추정할 수 있어야 합니다. 그렇기 때문에 face encoder는 얼굴로부터 정확한 음색 정보를 추정할 뿐만 아니라 음색 정보를 interpolation 할 수 있는 바람직한 distribution로 encode 가능해야 합니다. 그래서 저자들이 제안하는 face encoder는 2가지 module로 구성됩니다. facial feature extraction과 face-voice feature reparameterization입니다.
- Facial Feature Extraction
얼굴 사진으로 음색 정보를 추출하기 위해, speaker embedding의 바람직한 성질은 서로 다른 speaker를 분류할 수 있어야 한다는 것입니다. 그러므로 VGGFace2 dataset으로 pre-train된 FaceNet을 사용하여 initial speaker embedding을 추출합니다. 이는 e_init으로 표기하며 얼굴이 얼마나 비슷하지 않은지를 distance로 반영하는 latent space로 face image를 project한 결과입니다. 하지만 서로 다른 얼굴 image는 서로 다른 각도에서 capture된 것일 수도 있습니다. 그렇기 때문에 speaker embedding을 더 잘 학습시키기 위해 face angle의 일관성을 유지해야 하며, 이를 위해 저자들은 MTCNN을 사용하여 face image를 alignment합니다. MTCNN은 사람 얼굴을 detect하며, 한쪽 눈만 보이는 얼굴은 제외시켜 speaker embedding의 robustness를 향상시켰습니다.
FaceNet으로부터 speaker embedding을 구한 후, speaker embedding은 개개인의 characteristic을 강조할 뿐만 아니라 voice와 관련된 facial feature를 유지해야 하며, 연관 없는 facial feature들은 제거해야하기 때문에 self-attention mechanism을 이용해 더 발전시켰습니다. 아래 그림의 (a)와 같은 모습입니다.

Self-attention은 다양한 task에서 facial characteristic을 학습하는 데 도움을 준다는 것이 입증되었습니다. 저자들의 경우, self-attention은 서로 다른 facial dimension에서 얻어지는 비슷한 정보를 집계하고 voice style에 미치는 영향에 따라 reweight합니다. Query (Q), Key (K) Value (V) vector들은 facial feature e_init에서 각각 변환됩니다. 이후 Query는 Key와 곱해지고 softmax를 적용시켜 attention vector를 계산합니다. 결국 Value는 attended result e_ffe를 얻기 위해 attention vector와 곱해집니다.
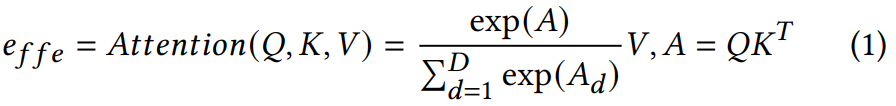
식은 위와 같습니다. 여기서 D는 Q, K, V의 dimension을 의미하고 A_d는 A vector의 d번째 dimension을 의미합니다. facial feature e_init으로부터 향상된 hidden features e_ffe는 target speaker의 음색을 생성하는 데 필요한 부분만 포함하도록 기대됩니다.
- Face-Voice Feature Reparameterization
facial feature 추출은 구분 가능한 feature를 추출하는 것을 목표로 합니다. 추출된 face feature를 timbre feature로 변환하는 직관적인 방법 중 하나로, transformation function으로 neural network를 사용하는 것입니다. 하지만, 이 방법은 두 modality 사이의 gap이 매우 크기 때문에 deep network를 필요로 합니다. 가장 중요한 것은 대응되는 latent space가 interpolation을 수행하지 않을 수 있으며, zero-shot VC 성능이 크게 감소할 수 있다는 점입니다. 결과적으로 face image의 아주 작은 변화로 인해 decoder가 아주 다른 output을 만들어낼 수 있습니다.
이 문제를 해결하기 위해, 저자들은 network에 확률성을 도입하기 위해 reparameterization approach를 채택합니다. Gaussian mixture model (GMM)은 speaker recognition에 있어 매우 높은 정확도를 보였기 때문에, 저자들은 reparameterization process를 수행할 때 GMM mechanism을 모방합니다. 아래와 같은 모습입니다.

먼저 e_ffe는 fully connected layer와 ReLU activation layer로 구성된 multi-layer perceptron에 feed됩니다. 그다음 transformed speaker embedding e_face는 reparameterization process에 의해 생성됩니다.
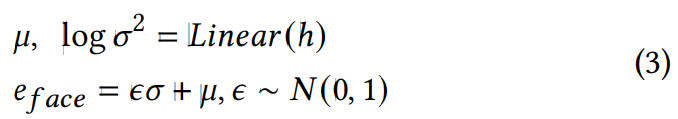
위 식에서 μ는 평균을 의미하고 σ는 표준편차를 의미하며 ε은 random하게 선택된 sample noise입니다. 이 process는 e_face가 normal distribution에서 sampling되도록 만들어줍니다.
저자들은 speaker embedding의 gaussian distribution을 256차원 latent variable으로 characterize했으며 embedding이 relationship을 바로 학습하도록 만들었습니다. 이러한 과정을 통해 간단하고 대표적이며 부드러운 분포로 latent variable을 나타내기 때문에, 앞으로 나오는 conversion 과정이 더 간단해질 수 있었습니다.
Reference Generator
face information을 포함하고 있는 dataset은 실제 환경에서 얻어진 speech입니다. VC performance는 감소될 수밖에 없습니다. clean dataset (recorded in laboratory environment)를 활용하여 face information을 timbre information으로 변환하기 위해, 저자들은 noisy speech로부터 target speech의 clean speech를 얻는 것을 목표로 하는 reference generator를 제안합니다.
reference generator는 AutoVC structure를 따르는데, content encoder, speech decoder로 구성됩니다. content encoder의 input은 80차원 speech mel-spectrogram이며 output은 content feature e_cont입니다. content encoder의 목표는 input spectrogram에서 speech content를 추출하는 것입니다. 그래서, 저자들은 content e_cont를 target timbre e_sph와 concatenate하여 speech decoder에 feed합니다.
speech decoder는 decoder와 post network로 구성됩니다. decoder는 converted speech spectrogram을 output합니다. audio의 detail한 부분도 생성하기 위해, post network가 decoder로부터 예측된 spectrogram을 condition으로 하여 추가적인 signal을 생성합니다. 이 signal은 original output을 조정하는 역할을 하여 audio quality를 개선할 수 있습니다. 최종 변환된 결과는 original decoder estimation에 extra signal을 더하는 방식으로 구해집니다.
Visual-to-Audio Transformation
정확한 audio-visual distribution을 형성하는 것은 쉽지 않으며, speaker timbre를 생성하기 위해 hidden variable을 keeping하는 것도 어렵습니다. 대부분의 audiovisual representation learning은 두 modality로부터 speaker를 recognize하는 것을 목표로 합니다. 하지만 face visual에서 voice style로 어떻게 변환하는지 알지 못합니다. facial embedding을 바로 speaker embedding으로 다루고 content part와 concat한 다음 decoder로 feed하는 것입니다. 하지만 cross-modal representation이 암묵적이기 때문에 여전히 challenge입니다. 다른 방법으로 facial embedding을 speaker의 timbre를 나타내는 speaker embedding으로 mapping하는 것입니다. 그러나 얼굴 형태 domain과 spekaer domain이 동일하지 않기 때문에, 서로 다른 model로부터 구해집니다. 이 경우 mapping function은 face-speech transformation 뿐만 아니라 domain 간 형태 변환도 학습해야 합니다. 이 상황은 효과적인 mapping 능력을 감소시킵니다. 그러므로 저자들은 reparameterization trick 기반 visual-to-audio transformation을 수행합니다. 두 modality는 face-voice feature reparameterization을 거친 후에 normally distribute되기 때문에, visual domain은 acoustic domain으로 더 잘 project 될 수 있습니다. 두 정규 분포 사이의 mapping이기 때문에 더 간단해집니다.
Vocoder
neural vocoder는 spectrogram을 inverse할 때 사용됩니다. 이는 자연스러운 사람의 speech를 생성하는 것을 목표로 합니다. 저자들은 pre-trained WaveNet vocoder를 사용하여 generated spectrogram을 time-domain waveform으로 변환했습니다.
Training Strategy
모든 module이 서로 다른 modality를 학습하기 때문에, end-to-end 방식으로 model을 학습하려면 엄청난 양의 paired data가 필요합니다. 대신에 3-stage procedure를 통해 knowledge transfer 방법을 사용합니다. stage 1에서는 speech에 사용될 timbre를 생성하는데 유리한 facial feature를 추출하는 것을 목표로 합니다. stage 2에서는 stage 3에 사용되는 정확한 speaker embedding을 제공하면서 inference할 때 명확한 content를 추출할 수 있는 능력을 갖도록 content encoder를 학습시킵니다. 마지막 stage 3에서는 stage 1에서 얻어진 facial feature와 stage 2에서 얻어진 speaker embedding 사이의 implicit relationship을 학습합니다.
- Stage 1
face encoder는 human face로부터 speaker information을 얻을 수 있게 도움을 주는 facial speaker distribution을 construct합니다. 그렇기 때문에 VC framework는 face encoder E_f, content encoder E_c를 포함하고 있으며, speaker의 얼굴과 noisy speech를 포함하고 있는 video dataset으로 학습된 speech decoder를 포함하고 있습니다. stage 1에서 E_f는 face input으로 speaker embedding을 생성하고, E_c는 noisy speech로부터 content를 추출합니다. 그리고 speech decoder는 다른 speaker embedding에 대한 speech를 합성합니다. E_c와 speech decoder는 pseudo generator G로 결합되며, 이는 reference generator와 동일한 구조이지만 parameter는 다릅니다. AutoVC에 영감을 받아, 저자들은 reconstruction spectrogram과 original의 L1 loss를 적용하며 content embedding에 L1 loss를 적용합니다. 식은 다음과 같습니다.
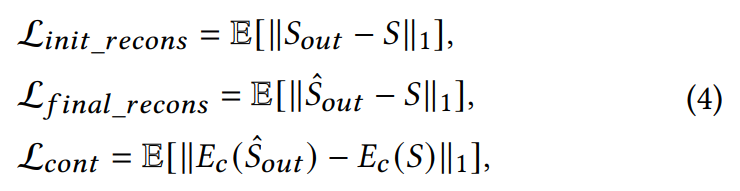
L_cont가 content embedding loss입니다. 여기서 S는 decoder의 output이고 S^은 post network까지 거친 후에 나온 output을 의미합니다.
또한 저자들은 GE2E loss를 facial speaker embedding e_face에 사용합니다. GE2E loss는 동일한 speaker에 대한 유사도는 maximize하고 다른 speaker에 대한 유사도는 minimize합니다. 최종 식은 다음과 같습니다.

여기서 lambda는 hyperparameter이며, 이를 통해 각 term의 중요도를 control합니다. 일부 경우가 대략적인 경향을 왜곡하는 것을 막기 위해, 저자들은 gradient clipping을 사용합니다. 이때 threshold는 1로 설정했다고 합니다.
stage 1에서의 conversion result의 audio quality는 in-the-wild speech dataset의 한계 때문에 만족할 정도는 아니지만, 이 stage에서 face encoder를 얻습니다. 적절한 bottleneck setting이 있다면, face encoder는 학습 중에 facial feature를 의미 있는 speaker embedding으로 encode하는 것을 배울 수 있습니다.
- Stage 2
AutoVC framework를 따라, speaker encoder E_s와 content encoder E_c, speech decoder를 사용합니다. E_s로 pre-trained speaker verification model을 사용하여 voice feature를 추출합니다. 추출된 voice embedding e_vfe는 face voice feature reparameterization으로 feed되어 vocal speaker distribution을 구성합니다. Stage 1과 Stage 2의 두 reparameterization module은 동일한 구조이지만 다른 parameter를 사용합니다. E_c와 speaker decoder는 reference generator G로 사용됩니다. 최종 loss는 GE2E loss를 제외하고 Stage 1과 동일합니다.
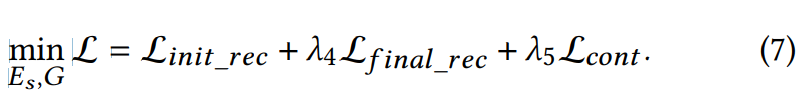
stage 2에서는 clean speech dataset을 사용하며, 이를 통해 converted result의 audio quality를 향상시킬 수 있었다고 합니다. 잘 학습된 speaker encoder는 speech input을 잘 일반화하며, stage 3에서 transformation target으로 사용될 수 있습니다. 또한 reference generator는 inference stage에서 VC를 수행하는 데 사용됩니다.
- Stage 3
마지막으로, visual-to-audio transformation W는 이 stage에서 학습되며 이를 통해 face domain과 acoustic domain 사이의 connecting 역할을 해줍니다. visual-to-audio transformation은 face encoder로부터 입력받은 facial embedding을 사용하여 fully connected layer를 구성합니다. 학습 objective는 output e'와 speaker encoder로부터 얻어진 speaker embedding e_sph 사이의 distance를 minimize하는 것입니다. 식은 다음과 같습니다.

여기서 (S, F)는 동일한 speaker의 (speech, face image) pair입니다. speech는 noisy가 있을 수 있습니다.
speaker encoder의 output을 target label로 사용할 수 있는데, speaker encoder에서 voice feature를 추출하는 부분은 noisy utterance에 대한 speaker verification task를 아주 잘 학습했기 때문입니다. 이를 통해 speaker encoder는 robust한 speaker embedding을 생성할 수 있기 때문에, 저자들은 speaker encoder의 output을 target label로 사용했습니다.
Conclusion
이 논문에서 FaceVC를 제안했으며, 이는 facial representation으로부터 voice style을 생성할 수 있는 첫 voice conversion method입니다. voice style이 최대한 진짜 사람의 voice가 되도록 합성하기 위해, 저자들은 face encoder와 visual-to-audio transformation을 construct하여 face embedding을 audio embedding으로 convert했습니다. 또한 3-stage training strategy를 소개했습니다. 이를 통해 in-the-wild dataset을 이용하여 high audio quality로 합성할 수 있었다고 합니다. 실험을 통해 facial appearance가 voice style을 나타낼 수 있으며 converted result가 좋은 quality의 audio임을 보였습니다. 얼굴로 voice conversion을 수행하는 것은 face-voice relation의 새로운 연구 방향을 열어주었다고 생각한다고 합니다.



