https://dl.acm.org/doi/abs/10.1609/aaai.v37i11.26628
What does your face sound like? 3D face shape towards voice | Proceedings of the Thirty-Seventh AAAI Conference on Artificial In
ABSTRACT Face-based speech synthesis provides a practical solution to generate voices from human faces. However, directly using 2D face images leads to the problems of uninterpretability and entanglement. In this paper, to address the issues, we introduce
dl.acm.org
해당 논문을 보고 작성했습니다.
Abstract
face-based speech synthesis는 사람 얼굴로 음성을 생성할 수 있는 실용적인 solution을 제안합니다. 하지만 2D face image를 바로 사용하는 것은 해석 불가능성과 얽힘 (entanglement) 문제를 야기합니다. 이 논문에서는 이러한 문제를 해결하기 위해 3D face shape를 사용합니다. 3D face shape은 voice characteristic과 해부학적 관계를 가지고 있으며, 인간의 음색 생성에서 골전도 (bone conduuction)가 참여합니다. 그리고 blending 과정을 배제함으로써 자연스럽게 관련 없는 요인들로부터 독립적입니다.
3D face shape에서 speech를 생성하는 framework를 3가지 stage로 나눕니다. 해부학적 및 후천적 측면에 음색 생성을 완전히 고려하여, 저자들의 framework는 face texture, facial feature, demographic과 같은 추가적인 relevant attributes를 통합합니다. 저자들은 실험과 subjective test를 통해 저자들의 model 성능을 증명했습니다.
저자들의 contribution은 다음과 같이 정의할 수 있습니다.
- 저자들은 3D face를 기반으로 speech를 생성하는 task를 소개합니다. 해부학적으로 설명 가능하고 deep learning model을 통해 control 가능한 face-voice relation을 생성하는 task입니다.
- 3D face shape와 다른 추가적인 input을 speaker embedding으로 만들고 최종 speech를 만드는 실용적인 pipeline을 제안합니다. 저자들의 model로 생성한 audio는 좋은 quality의 audio이며, 음성의 다양성, face-voice matching도 잘 이뤄냅니다.
- 저자들은 얼굴이 voice에 얼마나 영향을 주는지 입증할 수 있는 voice editing과 visualization approach를 제안합니다.
Related Work
Face Voice Correlation
얼굴과 음성은 개인의 정체성과 매우 관련되어 있습니다. 음성은 일종의 '청각적인 얼굴'로 여길 수 있습니다. 인지 과학 실험에서, 참여자들은 speaker의 얼굴을 가지고 voice characteristic을 예측할 수 있었으며, matching accuracy는 유의미하게 높았습니다. 즉 face와 voice는 사람에 대한 중복되거나 보완적인 information을 제공한다는 것을 알 수 있습니다. 신경과학에서는, 청각적 음성과 시각적 얼굴 영역 간의 정보를 공유함으로써 화자 인지가 가능하다고 설명합니다. speech-face와 연관된 연구들은 널리 연구되고 있습니다. 얼굴의 높이와 머리 길이로 성도 구조를 예측할 수 있으며, deep learning method로 face와 voice 사이의 관계를 나타낼 수 있습니다.
Methodology
저자들은 4가지 voice-related speaker characteristic을 선택했습니다. 이 중 3D face도 포함됩니다. 저자들은 3D face-based voice inference method를 사용합니다. 이를 통해 서로 다른 차원의 input을 통합하여 speaker의 voice embedding vector를 예측할 수 있습니다. 마지막으로, 저자들은 3-stage training strategy를 사용하여 speaker embedding extraction, voice inference, speech synthesis를 수행합니다.

Voice-Related Factors
저자들은 voice characteristic을 예측하기 위해, 4가지 voice와 관련된 factor를 선택했습니다.
- 3D face shape: 3D 얼굴 형상은 3D 공간의 꼭짓점으로 구성된 얼굴의 3D model입니다. 저자들은 해부학적 voice-related skeleton의 representation으로 3D face shape를 사용했습니다.
- Face texture: 얼굴 texture는 3D face shape의 texture map으로, 2D image로 mapping됩니다. 저자들은 face texture를 음성 생성에 영향을 주는 연조직과 근육을 나타내기 위해 사용합니다.
- Facial features: facial feature를 speaker의 개인 특성의 일부로 사용합니다. 저자들은 eyeglasses, hair color, beard, mustache, hat, smile을 facial feature로 사용했다고 합니다.
- Demographics: 인구 통계는 성별과 나이를 포함하여 서로 다른 음성 패턴을 가진 다양한 speaker group을 나타냅니다.
저자들은 3D reconstructor와 attribute extractor를 사용해 feature를 추출합니다. 먼저 3DMM을 사용하여 face를 3D face로 modelling 합니다. face shape S는 face skeleton과 face expression의 weighted sum입니다.

위 식에서 B_sklt, B_exp는 speaker identity와 expression의 PCA base입니다. f_sklt, f_exp는 PCA의 coefficient입니다. S-는 average face shape이고 이 face shape는 N개의 꼭짓점으로 face를 modelling합니다. 저자들은 2009 Base Face Model을 사용하여 S-를 구합니다. base와 coefficient의 subset만 사용합니다.
face texture T는 다음과 같은 affine model로 표현합니다.

여기서 B_t는 face texture의 PCA base이고 δ는 coefficient vector입니다. T를 linear space에서 FLAME layout으로 변환하여 UV albedo map A을 output합니다.
저자들은 attribute extractor로 CNN 구조를 사용하여 facial feature L_f와 demographic L_d를 추출합니다.
3D Face Based Voice Inference
이전에 말했듯이 4가지 input을 얻습니다: 3D face shape S, face texture T, facial feature L_f, demographics L_d입니다. 저자들은 이 서로 다른 차원의 input들을 unified embedding space로 변환하기 위해 서로 다른 method를 사용합니다.
먼저 3D face shape에 대해서, 저자들은 표정과 평균 얼굴의 간섭을 배제하는 skeleton coefficient f_sklt를 representation을 사용합니다. face texture에 대해 저자들은 VGG19 architecture를 texture encoder로 사용합니다. 그리고 texture albedo map A를 input으로 사용합니다. 저자들은 texture encoder의 hidden layer output을 face texture의 representation으로 사용합니다. 저자들은 facial feature를 embed하고 demographic을 embedding vector로 embed하기 위해 lookup table을 사용합니다. 저자들은 texture encoder의 hidden state와 facial feature의 embedding vector를 concatenate하여 feature f_a를 생성합니다. 이는 appearance information을 의미합니다. demographic의 embedding vector는 demographic feature f_d를 형성합니다.
이러한 input들로 voice를 infer하기 위해, 저자들은 speaker voice characteristic의 representation으로 저자들은 speaker embedding f_spk와 저자들의 model의 output을 사용합니다. f_spk를 바로 predict하는 대신, 저자들은 feature 차원을 감소하여 예측의 단순화시키는데, 이를 위해 PCA를 적용하여 주성분 e_spk를 유지합니다.

여기서 B_spk는 speaker embeddig vector f_spk에 적용된 PCA base입니다. 모든 추출된 feature들은 concatenate된 후에 voice encoder에 feed되어 principal component e'_spk를 predict하는데 사용됩니다.
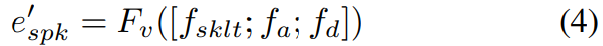
여기서 F_v는 voice encoder를 의미합니다. e'_spk에서 speaker embedding f'_spk를 restore하기 위해 저자들은 speaker embedding에 PCA의 inverse를 적용합니다.

inference stage에서는 restored speaker embedding f'_spk가 multi-speaker TTS system으로 feed되고 voice characteristic을 띈 utterance를 생성하게 됩니다.
Three Stage Training Strategy
저자들은 3-stage training strategy를 제안합니다. 이를 통해 voice extraction, inference, synthesis pipeline을 수행할 수 있습니다. 먼저 저자들은 pre-trained DNN strcture X-Vector를 speaker encoder로 사용하여 speaker embedding을 추출합니다. 여기서 512차원 embedding vector f_spk를 speaker embedding vector로 추출합니다.
그다음 speech synthesis module인데, 저자들은 Conformer-FastSpeech2를 TTS system으로 사용합니다. text sequence t가 phoneme sequence로 변환된 다음 hidden sequence h로 encode됩니다. speaker embedding vector는 hidden sequence에 더해집니다(h' = h + f_spk). 그 다음 decoder가 h'를 Mel-spectrogram으로 변환합니다. 그 다음 vocoder가 waveform으로 복원합니다. 예측된 mel-spectrogram과 ground truth mel-spectrogram 사이의 L2 loss를 사용하여 TTS system을 학습합니다.
그 다음 voice inference module을 학습시킵니다. 저자들은 e'_spk와 e_spk에 대한 L2 loss를 사용하여 voice encoder와 lookup table의 parameter를 학습시킵니다.

Conclusion
이 논문에서, 저자들은 face shape로 speech를 생성하는 연구를 진행했습니다. 저자들은 3D face shape를 이용하여 voice inference와 speech synthesis framework를 소개합니다. 2D face image와 비교했을 때, 3D face shape는 편집가능하며 expression, pose, 다른 연관없는 factor들과 독립적입니다. 실험과 subjective test를 통해 저자들의 method가 face와 matching되는 utterance를 만들어낸다는 것을 보였습니다.



