https://arxiv.org/abs/2007.15256
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
We present a novel high-fidelity real-time neural vocoder called VocGAN. A recently developed GAN-based vocoder, MelGAN, produces speech waveforms in real-time. However, it often produces a waveform that is insufficient in quality or inconsistent with acou
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 VocGAN을 제안합니다. 이는 고음질의 실시간 neural vocoder입니다. 최근에 개발된 GAN 기반 vocoder인 MelGAN의 경우, real-time으로 speech waveform을 생성할 수 있습니다. 그러나, 실시간으로 생성된 waveform의 quality가 충분하지 않거나 input mel-spectrogram의 acoustic 특성과 일치하지 않는 경우가 종종 존재합니다. VocGAN은 MelGAN과 비슷한 속도로 speech waveform을 생성하면서, output waveform의 quality와 일관성을 크게 향상시켰습니다. VocGAN은 multi-scale waveform generator를 사용하고, 계층적으로 중첩된 discriminator를 사용해 multiple level acoustic 속성을 균형 있게 학습합니다. 그리고 conditional and unconditional objective를 결합하여 사용합니다.
Introduction
Deep learning base speech synthesis 기술은 빠르게 성장하고 있습니다. 특히, WaveNet과 같은 neural vocoder의 등장 은 end-to-end speech synthesizer의 성능(원음과 매우 유사한 음성을 생성)을 크게 향상시켰습니다. 그러나 TTS system의 경우, 실시간으로 음성을 생성하는 것 또한 매우 중요합니다. WaveNet은 sequential auto-regressive 구조이기 때문에 매우 느립니다. Parallel WaveNet과 ClariNet은 non-autoregressive parallel 구조를 사용하여 실시간으로 speech waveform을 생성할 수 있습니다. 하지만 복잡한 구조와 복잡한 train 과정 때문에, performance를 보이기 위해선 많은 시간과 노력이 필요합니다. 다른 방법으로, WaveGlow와 FloWaveNet과 같은 flow-based model이 있습니다. 이는 training data의 negative log-likelihood를 minimize하는 방식으로 학습을 하는 방식이며, GPU를 사용했을 때 고품질의 speech waveform을 빠르게 생성할 수 있습니다. 그러나, 매우 많은 parameter를 사용하고 연산량이 매우 많습니다. 그래서 GPU를 사용하지 않으면 real-time에 speech waveform을 생성할 수 없습니다.
최근에는 GAN을 이용해 neural vocoder를 학습하는 idea를 사용하는 model들이 등장했습니다. Parallel WaveGAN은 mel-spectrogram과 같은 auxiliary feature를 condition으로 하는 WaveNet 기반 generator를 사용하고, GPU를 사용하여 실시간으로 자연스러운 speech waveform을 합성합니다. Parallel WaveGAN의 경우 좋은 성능을 보이지만, 연산량이 많기 때문에 CPU를 사용하면 real-time에 도달할 수 없습니다.
MelGAN은 또 다른 GAN 기반 vocoder이며, 이는 pretraining이나 density distillation 없이도 학습시킬 수 있습니다. MelGAN의 generator는 lightweight nework이며 CPU에서도 real-time 합성이 가능합니다. MelGAN은 다양한 기술을 사용하여 높은 temporal resolution의 raw waveform을 생성합니다.
하지만, 여전히 MelGAN의 output quality에는 개선사항이 존재합니다. instance normalization을 사용하는 경우, 중요한 pitch 정보가 사라지기도 하며, 생성된 audio가 metallic하게 들리게 됩니다. 비록 연구자들이 weight normalization을 사용하여 상당히 많은 부분을 완화하긴 했지만, 아직 문제가 완전히 해결된 것은 아닙니다. MelGAN의 quality 문제는 low-frequency components(e.g., fundamental frequency(F_0))와 high-frequency components(e.g., noise)의 degradation도 포함하고 있습니다. MelGAN은 또한 input mel-spectrogram의 acoustic characteristic와 일치하지 않는 waveform을 생성하기도 합니다. 이러한 문제들은 MelGAN의 network 구조와 learning objective가 audio signal의 acoustic representation을 정확하게 학습하기에 불충분하다는 것을 의미합니다.
이 논문에서는, GAN 기반 vocoder인 VocGAN(Vocoder GAN)을 제안합니다. 이는 MelGAN만큼 빠르며 output quality를 크게 향상시키고, input mel-spectrogram과 일치하도록 만들었습니다. VocGAN은 MelGAN의 확장된 버전이며 MelGAN의 한계점을 극복하기 위해 다양한 technique을 사용했습니다.
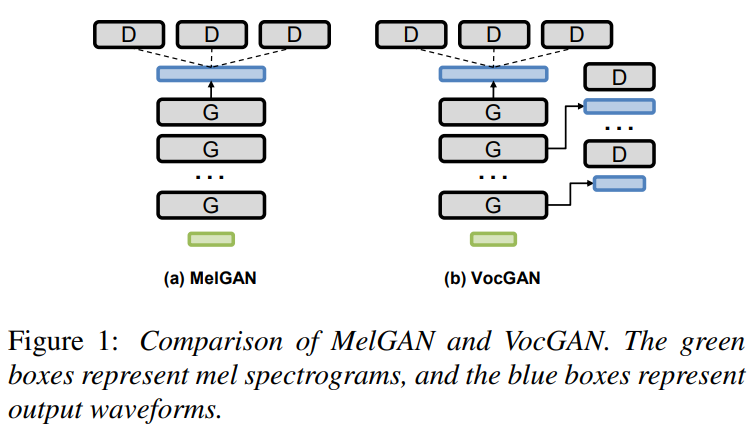
위 그림을 보면 MelGAN과 VocGAN의 구조적 차이를 알 수 있습니다. generator가 다양한 scale에서의 multiple waveform을 output으로 하도록 확장했습니다. 저자들은 generator가 resolution-specific discriminator에 의해 계산되는 adversarial loss를 통해 학습되도록 만들었습니다. 이러한 계층적 구조는 acoustic 특성을 다양한 level에서 균형적으로 학습할 수 있도록 만들어줍니다. 각각의 resolution-specific discriminator는 conditional and unconditional loss의 결합(JCU)을 사용합니다. 저자들은 waveform synthesis에서 좋은 성능을 보였던 STFT loss를 결합함으로써 output quality를 더욱 향상시켰습니다.
Proposed Method
Baseline model
저자들은 GPU 없이도 실시간으로 waveform을 생성할 수 있는 고음질의 neural vocoder를 개발하기 위해 MelGAN을 baseline model로 정했습니다. 저자들은 MelGAN의 model 구조와 learning objective를 향상시켜 quality degradation 문제를 해결합니다. baseline model의 generator는 upsampling 비율이 8, 8, 2, 2인 4개의 upsampling block을 이용하는 fully convolutional feed-forward network입니다. 각 upsampling block은 transposed convolution을 가지고 있으며, 3개의 dilated convolution으로 구성된 residual stack과 residual connection을 가지고 있습니다. generator의 학습은 multi-scale discriminator를 이용해 진행됩니다. muti-scale discriminator는 다양한 scale에서 window-based objective를 계산합니다.
Multi-scale waveform generator
계층적으로 중첩된 adversarial objective는 고화질의 image 합성에서 효과적인 모습을 보였습니다. 계층적으로 중첩된 adversarial objective는 다양한 resolution에서 waveform을 합성하는 데 유용하도록 중간 representation을 유도하여 정규화합니다. 이는 generator가 효과적으로 high-frequency component 뿐만 아니라 low frequency도 학습할 수 있도록 도와줍니다. 비록 계층적으로 중첩된 adversarial objective는 원래 이미지 합성을 위해 개발되었지만, raw waveform의 quality를 효과적으로 향상시키는 데에도 도움을 줄 수도 있습니다. 그렇기 때문에 저자들은 neural vocoder의 성능을 향상시키기 위해 계층적 중첩 adversarial objective를 사용합니다.
계층적 중첩 objective를 neural vocoder에 사용하기 위해서는 generator와 discriminator를 수정해야 합니다. generator는 input으로 mel spectrogram을 받으며 그에 해당하는 raw waveform을 생성합니다. 저자들의 generator의 구조는 MelGAN의 가벼운 generator를 기반으로 합니다. 그러나, 저자들은 계층적 중첩 objective를 사용하기 위해 구조를 상당히 많이 수정했습니다.

위 그림과 같이 generator를 수정했습니다. generator는 6개의 upsampling block으로 구성됩니다. 처음 두 upsampling block의 upsampling 비율은 4이며, 나머지 block들은 2입니다. generator는 마지막 full-resolution waveform만 output할 뿐만 아니라, k개(1 <= k <= K)의 multiple downsampled waveform을 side output으로 output합니다. 각 resolution은 full-resolution의 1/2^k 만큼의 resolution을 갖습니다. 여기서 K는 downsampled waveform의 수를 의미합니다. 저자들은 K를 4로 고정하여 연구를 진행했습니다. k개의 downsampled waveform은 top-five up-sampling block에 convolution layer를 적용해 생성됩니다. waveform은 generator에 의해 생성되며, 식으로 나타내면 다음과 같습니다.
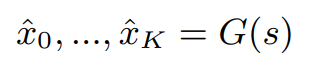
위 식에서 s는 input mel-spectrogram을 의미하며, x_0는 final full resolution waveform을 의미합니다. x-1, ... , x_K는 downsampled side waveform입니다.
추가적으로, 저자들은 input mel-spectrogram에서 각 2x upsampling block으로의 skip connection을 추가합니다. 이를 통해 input mel-spectrogram을 직접적으로 condition으로 만들어 중간 representation을 학습할 수 있도록 만들었습니다. 이를 통해 저자들은 input mel-spectrogram에 일치하는 acoustic characteristic 능력을 향상시켰습니다.
Hierarchically-nested JCU discriminator
- Hierarchically-nested structure
VocGAN의 계층적 중첩 discriminator는 5개의 resolution-specific discriminator로 구성됩니다.
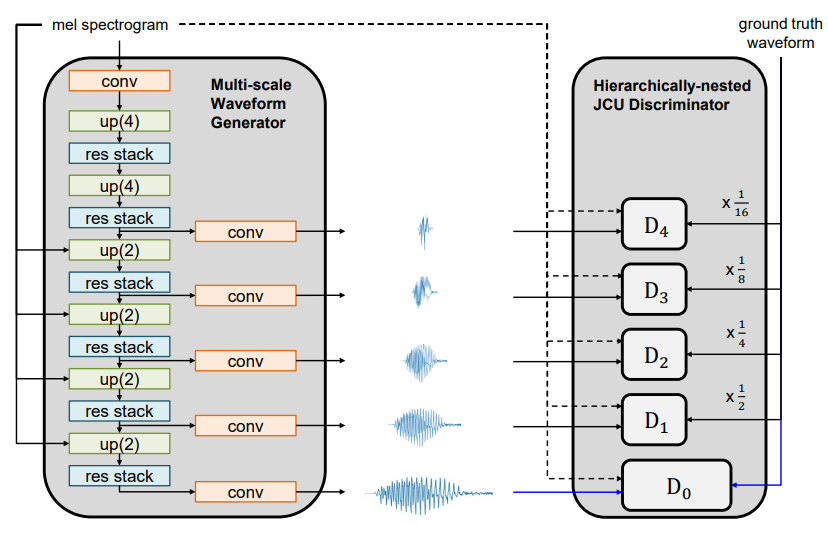
그림으로 나타내면 위와 같습니다. 각 discriminator는 해당하는 resolution의 output waveform이 real인지 fake인지 구분합니다. 계층적 중첩 discriminator는 multi-scale waveform generator가 5개의 다른 resolution에서 spectrogram을 waveform으로 mapping하는 것을 학습하도록 만듭니다. 다시 말해, generator가 acoustic feature의 low frequency와 high frequency 구성요소의 mapping을 학습할 수 있도록 도와줍니다. 각 resolution-specific discriminator는 JCU loss를 사용합니다. 마지막 discriminator의 경우, multi scale JCU discriminator를 사용합니다. multi scale JCU discriminator의 구조는 pix2pixHD와 MelGAN의 multi-scale discriminator와 유사합니다.
저자들의 계층적 중첩 discriminator는 기존에 존재하는 multi-scale discriminator와 다릅니다. 저자들의 discriminator는 generator의 중간 representation으로부터 직접적으로 생성되는 multiple reduced-resolution sample을 input으로 받습니다. 하지만 기존에 존재하는 multi-scale discriminator의 경우, single full-resolution waveform을 받습니다. single full-resolution waveform을 다양한 비율로 downsampling하여 reduced resolution을 생성하여 사용하는 방식입니다.
전자의 경우, 여러 중간 layer가 reduced resolution waveform을 생성하는 방법을 학습하도록 만듭니다. 결과적으로, 저자들의 계층적 중첩 discriminator는 generator가 high and low frequecny feature를 더 균형적으로 학습하도록 만듭니다.

저자들은 resolution-specific discriminator에 least square adversarial objective를 사용합니다. 식은 위와 같습니다. 여기서 x_k는 k번째 downsampling ground-truth waveform을 의미합니다. 그리고 V_k(G, D_K)는 k번째 downsampled waveform에 대한 objective function을 의미합니다. final discriminator가 multi-scale discriminator이기 때문에, V_0(G, D_0)는 sub-discriminator들의 합으로 정의됩니다. discriminator와 generator의 loss는 다음과 같이 정의됩니다.
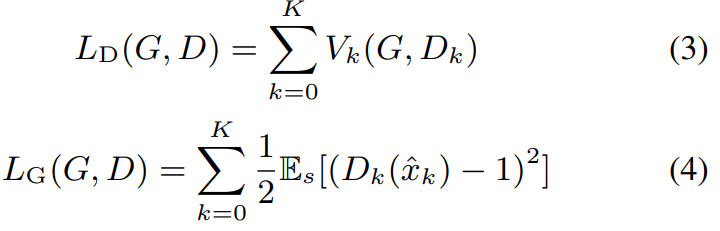
- Joint conditional and unconditional loss
저자들은 JCU loss를 계층적 중첩 adversarial objective에 결합하여 speech quality를 더욱 향상시킵니다.
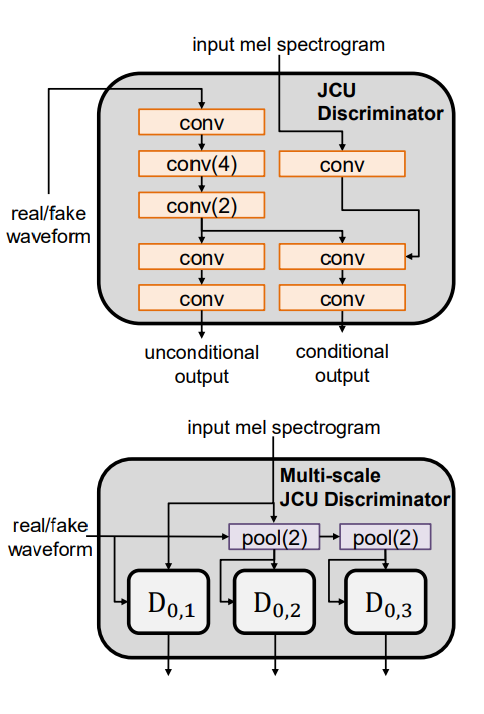
JCU discriminator 구조는 위와 같습니다. conventional adversarial loss와 대조적으로, JCU loss는 conditional adversarial loss와 unconditional adversarial loss를 결합합니다.

위 식과 같이 loss를 정의합니다. conditional loss는 generator가 input mel-spectrogram의 acoustic feature를 waveform으로 더 정확하게 mapping하도록 만듭니다. 그러므로, input mel-spectrogram의 acoustic characteristic과 output waveform 사이의 차이를 줄이는 데 도움이 됩니다.
- Feature matching loss
MelGAN처럼 저자들은 feature matching loss를 사용합니다. feature matching loss는 real waveform과 fake waveform을 이용해 계산된 discriminator의 feature map 사이의 L1 distance로 정의됩니다. 저자들은 모든 resolution-specific discriminator에 feature matching loss를 적용합니다. feature matching loss를 이용해 학습의 안정성을 상당히 향상시켰습니다. 식은 다음과 같습니다.
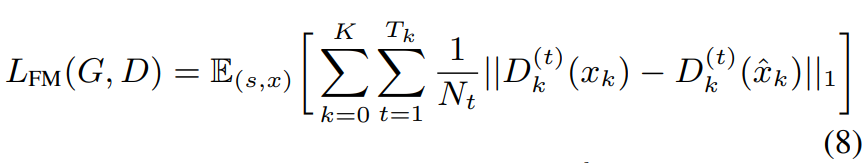
여기서 T_k는 k번째 resolution-specific discriminator에 존재하는 layer 수를 나타내며, N_t는 각 layer의 구성 요소의 수를 의미합니다.
Multi-resolution STFT loss
adversarial training의 안정성과 효율성을 향상시키기 위해, 저자들은 multi-resolution STFT loss라는 부수적인 loss도 사용했습니다. 특히, multi-resolution STFT loss는 training 수렴 속도를 향상시켜줍니다. 이 추가적인 loss는 generator에만 독립적으로 사용됩니다. single STFT loss는 frame-level에서의 ground truth와 합성된 full-resoluton waveform를 가지고 측정됩니다. multi-resolution STFT loss인 L_STFT는 다양한 FFT size, window size, frame shift에서 multiple STFT loss를 구해 합치는 방식으로 구해집니다. 최종 generator objective functoin은 다음과 같습니다. 여기서 α = 10.0 β = 1.0으로 두었습니다.

Experiments
Datasets and experimental settings
저자들은 실험에서, Korean Single Speaker Speech(KSS) dataset과 LJSpeech dataset을 사용합니다. KSS dataset은 12,853개의 script로 구성되며, 이 script는 1명의 한국 여성 speaker에 의해 녹음되었습니다. LJSpeech dataset은 13,100개의 sample로 구성되며, 1명의 미국 여성 speaker에 의해 녹음되었습니다. 총 길이는 12시간, 24시간입니다. 두 dataset의 sampling rate는 22,050Hz입니다. 저자들은 129개와 131개의 utterance를 validation에 사용했으며 또 다른 129개와 131개의 utterance를 test에서 사용했습니다. 모든 남아있는 utterance는 training할 때 사용했습니다. 저자들은 NVIDIA Tesla V100 GPU를 사용해 학습했으며, Intel Xeon(R) E5-2620 v4 2.10GHz CPU와 NVIDIA GTX 1080Ti GPU를 사용해 test했습니다.
Training and evaluation
저자들은 모든 model을 3000 epoch으로 학습했습니다. Adam optimizer를 사용해 학습했습니다. 저자들은 sample을 1초 audio clip으로 잘라 train에 사용했습니다. multi-resolution STFT loss를 사용하기 위해, 저자들은 512, 1024, 2048의 frame size와 240, 600, 1200의 window size, 50, 120, 240의 frame shift 크기를 가진 3가지 STFT loss를 사용했습니다.
저자들은 MCD, F_0 RMSE을 ground truth와 합성된 waveform 사이의 차이를 확인하기 위해 적용했습니다. 이를 통해 vocoder가 mel-spectrogram을 waveform으로 변환했을 때의 정확도를 측정했다고 합니다.
Exerimental results
- Ablation study
저자들은 저자들이 제안한 method가 KSS와 LJSpeech datset에서 얼마나 효과가 있는지 분석하기 위해 ablation study를 진행했습니다. baseline model로 MelGAN을 정했으며, MelGAN은 multi-scale discriminator와 feature matching loss를 사용합니다.

실험 결과는 위와 같습니다. 계층적 중첩 objective와 구조를 사용해 상당한 speech quality 향상을 이끌었습니다. 특히 MCD에서 더 큰 향상을 보입니다. conventional least-square loss를 JCU loss로 대체했을 때도 큰 성능 향상을 얻었습니다. 계층적 중첩 JCU objective 역시도 두 method를 결합했기 때문에 큰 성능 향상을 보였습니다. 또한 계층적 중첩 adversarial objective와 multi-resolution STFT loss를 결합했을 때도 성능을 향상시킬 수 있었습니다. 그러나, PESQ에서는 계층적 중첩 JCU objective를 사용했을 때 약간 성능이 향상되는 것을 볼 수 있습니다.

위 그래프를 보면 알 수 있듯이, STFT loss를 사용했을 때 더 빠른 수렴 속도를 보이는 것을 알 수 있습니다.
- Comparison with existing models
저자들은 최근에 개발된 neural vocoder인 MelGAN과 Parallel WaveGAN과 비교합니다. speech quality를 비교하기 위해, 저자들은 MOS score를 사용했습니다. 저자들은 KSS test dataset에서 20개의 mel-spectrogram을 램덤하게 선택해 각 vocoder에 넣어 raw waveform을 합성했습니다. 그다음 score range를 1 ~ 5로 설정하여 score를 구했습니다. 결과는 다음과 같습니다.
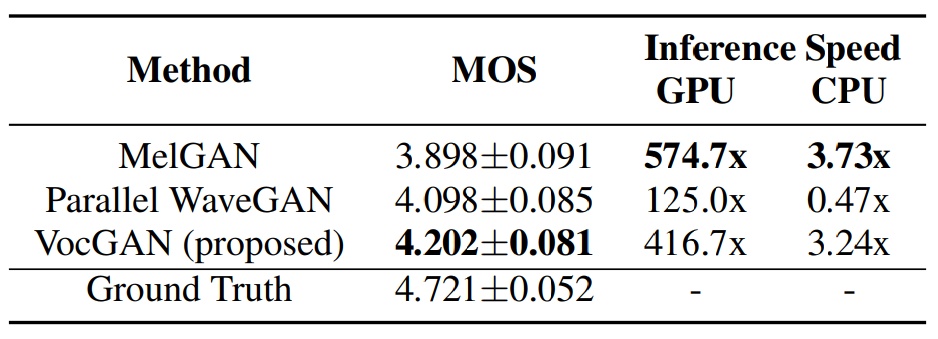
VocGAN의 성능이 다른 두 model에 비해 더 높게 측정된 것을 볼 수 있습니다. 또한 inference speed 역시 MelGAN과 유사한 속도를 보이고 있습니다. 위 표는 real-time에 비해 얼마나 빠르게 inference를 하는지를 보여주는 수치이며, CPU에서도 real-time으로 inference할 수 있는 것을 볼 수 있습니다.
Conclusion
저자들은 VocGAN을 제안했으며, 이는 GAN-based high-fidelity real-time vocoder입니다. multi-scale waveform generator와 계층적 중첩 JCU discriminator로 구성되며, VocGAN은 high-quality waveform을 생성합니다. 저자들은 학습의 안정성과 효율성을 크게 향상시켰으며, multi-resolution STFT loss를 부수적인 loss로 적용해 waveform의 quality도 향상시켰습니다. MelGAN과 비슷한 inference 속도를 보이며, real-time보다 더 빠른 inference 속도를 GPU, CPU에서 보여줍니다.
'연구실 공부' 카테고리의 다른 글
| Speaker Diarization (0) | 2024.03.11 |
|---|---|
| [논문] HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis (0) | 2024.03.08 |
| [논문] MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis (0) | 2024.03.06 |
| [논문] WaveGlow: A Flow-Based Generative Network for Speech Synthesis (0) | 2024.03.03 |
| [논문] WaveNet: A Generative Model for Raw Audio (0) | 2024.02.29 |


