https://arxiv.org/abs/1811.00002
WaveGlow: A Flow-based Generative Network for Speech Synthesis
In this paper we propose WaveGlow: a flow-based network capable of generating high quality speech from mel-spectrograms. WaveGlow combines insights from Glow and WaveNet in order to provide fast, efficient and high-quality audio synthesis, without the need
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문에서 WaveGlow를 소개합니다. flow-based network이며 이는 mel-spectrogram을 이용해 고품질의 speech를 생성할 수 있습니다. WaveGlow는 Glow와 WaveNet을 결합한 형태로, auto-regression 하지 않는 방식으로 빠르고 효율적이게 고품질의 audio를 합성할 수 있습니다. WaveGlow는 단일 network를 이용하며 1개의 cost function을 사용해 학습합니다. cost function은 training dat의 likelihood를 maximize하는 방식이며, 이는 간단하고 안정적으로 학습할 수 있게 만듭니다. 저자들이 만든 model은 V100 GPU를 이용했을 때, 500kHz보다 빠른 속도로 audio sample을 생성합니다.
Introduction
machine을 이용해 voice를 처리하는 방식들이 점점 더 유용해짐에 따라, 효과적으로 고품질의 speech를 합성하는 것이 점점 더 중요해졌습니다. 고품질, real-time speech 합성은 여전히 challenging task입니다. 음성 합성은 강력한 long term dependencies를 가지고 있는 매우 높은 차원의 sample을 생성해야 합니다. 실시간 음성 합성을 하기 위해선 속도와 계산 제약이 존재합니다. audio sampling rate가 16kHz보다 떨어지게 되면 speech quality는 현저히 떨어지게 되고, 더 높은 sampling rate면 더 질 좋은 speech가 생성되게 됩니다. 대부분의 application은 16kHz보다 더 빠른 합성 속도를 요구합니다. 예를 들어 원격 서버에서 음성 합성을 한다면, 발화가 실시간 요구보다 훨씬 더 빠르게 음성 합성이 돼야 합니다.
최근에, 가장 좋은 성능의 음성 합성 model은 parametric neural network입니다. TTS 합성은 일반적으로 2 단계로 이루어집니다. text를 mel-spectrogram이나 F_0 frequency나 linguistic feature 같은 time-algined feature로 먼저 변환해야 합니다. 그다음 이 time-aligned feature를 audio sample로 변환하는 과정을 거칩니다. feature를 audio sample로 변환하는 model은 보통 vocoder라고 불리며, 이는 연산량이 매우 많이 필요하고 audio quality에 영향을 주게 됩니다.
저자들은 vocoder에 focusing합니다. 음성 합성에 사용되는 대부분의 neural network들은 auto-regressive model입니다. 이는 long term dependencies를 modeling하기 위해 이전 sample을 condition으로 사용해 미래의 audio sample을 생성하는 방식입니다. 이러한 접근법은 학습하고 사용하기 간단합니다. 하지만, 이는 본질적으로는 순차적이며, 완전한 병렬 처리는 불가능합니다. 이러한 model들은 16kHz보다 더 빠른 속도로 audio를 합성하는 데 어려움이 있습니다.
그래서 auto-regression이 없는 음성 합성 model들이 등장하기 시작했습니다. Parallel WaveNet, Clarinet 등이 있습니다. 이러한 model들은 GPU를 사용했을 때 500kHz보다 더 빠른 속도로 audio를 합성할 수 있습니다. 하지만, 이러한 model들은 auto-regressive model보다 학습하기 어렵고 이용하기도 어렵습니다. 그리고 이러한 model들은 audio quality를 향상시키거나 model collapse 문제를 해결하기 위해선 복잡한 loss function을 사용해야 합니다.
Parallel WaveNet과 Clarinet은 student & teacher network를 이용합니다. student network는 Inverse Auto-regressive Flow(IAF)를 사용합니다. IAF network가 추론할 때 병렬적으로 동작할 수 있지만, flow가 auto-regressive하기 때문에 IAF의 계산이 비효율적입니다. 이를 극복하기 위해, teacher network를 이용해 student network가 실제 likelihood를 근사할 수 있도록 만듭니다. 이러한 접근법은 배포하거나 reproduce하기 어려운데, model을 성공적으로 수렴하도록 학습하는 것은 어렵기 때문입니다.
이 연구에서는, 저자들이 auto-regressive flow가 음성 합성에서 불필요하다는 것을 보여줍니다. 저자들은 flow-based network가 mel-sepctrogram을 이용해 고품질의 음성을 생성할 수 있도록 만듭니다. 저자들은 WaveGlow라고 이 network를 부르며, 이는 Glow와 WaveNet를 결합한 형태입니다. WaveGlow는 학습하고 사용하기 간단하며, 단일 network 형태입니다. 그리고 likelihood loss function만 사용하여 학습됩니다. WaveGlow는 500kHz보다 더 빠르게 음성을 합성할 수 있습니다. 이는 real time보다 25배 더 빠른 속도입니다.
WaveGlow
WaveGlow는 distribution에 sampling하여 audio를 생성하는 생성 모델입니다. neural network를 생성 모델로 사용하기 위해서 저자들은 간단한 distribution을 사용해 sampling합니다. 저자들의 경우 평균이 0이고 저자들이 만들고 싶은 output과 동일한 차원 수를 가진 gaussian distribution을 사용합니다. 저자들은 distribution에서 sampling한 sample을 우리가 원하는 분포로 변환시켜 주는 여러 layer를 통과시킵니다.

위 식과 같은 형태입니다. 저자들은 mel-spectrogram을 조건으로 하는 audio sample의 distribution을 modeling합니다.
저자들은 data의 negative log-likelihood를 직접적으로 최소화시키는 방식으로 model을 학습합니다. 임의의 neural network를 사용하면 이는 연산 불가능합니다. flow-based network는 network mapping이 invertible한 형태로 만들어 이러한 문제를 해결합니다. 각 layer를 bijective function(전단사 함수)으로 제한함으로써, variable을 변환하여 likelihood를 직접적으로 계산할 수 있습니다.
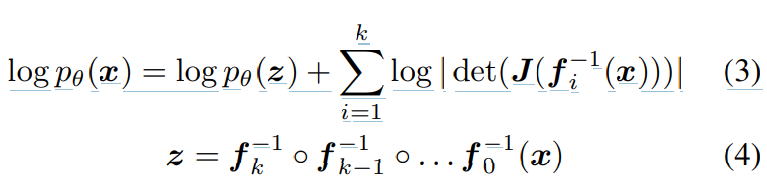
위 식과 같은 형태로 만들어 invertible하게 구현할 수 있습니다. (3)식에서 첫 항은 spherical Gaussian에 대한 log-likelihood를 의미합니다. 이는 변환된 sample의 l2 norm에 페널티를 부여합니다. 두 번째 항은 variable 변환 때문에 생기는 항이며, J는 Jacobian입니다. Jacobian의 log-determinant는 forward pass 동안 space의 volume을 증가시키는 모든 layer에 reward합니다. transformation은 normalizing flow입니다.

저자들의 model은 위와 같습니다. forward pass를 할 때, 8개의 audio sample을 vector로 그룹화하는데, 이를 squeeze 연산이라고 부릅니다. 그다음 이 벡터들을 여러 "step of flow"를 통해 처리합니다. 여기서 flow의 한 단계로, affine coupling layer와 invertible 1x1 convolution으로 구성됩니다. 이러한 flow가 총 12개를 적용하는 것이 저자들의 model입니다.
Affine coupling layer
invertible neural network는 일반적으로 coupling layer로 구성됩니다. 저자들이 제안한 model의 경우, affine coupling layer를 사용합니다. channel 중 절반은 input으로 사용되며, 이는 곱셈 및 덧셈 term을 생성하여 나머지 channel의 scaling과 변환에 사용됩니다.
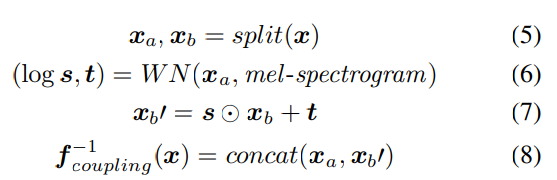
위 식에서 WN()은 어떠한 변환도 될 수 있습니다. WN()이 invertible이지 않아도 coupling layer는 전체 network의 invertibility를 유지합니다. 왜냐하면, WN()의 input으로 사용되는 channel(이 경우에는 x_a)이 layer의 output으로 변환되지 않은 채로 전달되기 때문입니다. 따라서, network를 invert할 때, output x_a를 이용해 s와 t를 계산할 수 있으며, 그다음 x_b'를 이용해 x_b를 구할 수 있습니다. WN()은 gated tanh를 사용하는 dilated convolution layer를 사용하며, residual connection과 skip connection도 사용합니다. 이러한 WN 구조는 WaveNet과 Parallel WaveNet과 매우 유사하지만, 다릅니다. affine coupling layer는 생성된 output을 input의 조건으로 사용하기 위해 mel-spectrogram을 포함합니다. upsampled moel-spectrogram은 각 layer의 gated-tanh을 거치기 전에 더해집니다.
affine coupling layer를 사용할 때, s term만 mapping의 volume을 변경하기에 variable term의 변화를 loss에 더합니다. 이 term은 model이 non-invertible affine mapping을 하는 것에 대한 penalty를 부여하는 역할을 합니다. 식은 다음과 같습니다.
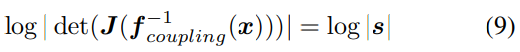
1x1 Invertible convolution
affine coupling layer에서 같은 절반에 해당하는 channel들은 서로 직접 수정하지 않습니다. channel 간에 information을 혼합하지 않으면, 이는 심각한 제한이 됩니다. 그래서 저자들은 channel 간 information을 혼합합니다. 저자들은 각 affine coupling layer를 하기 전에 invertible 1x1 convolution layer를 추가합니다. 이 convolution의 weight W는 orthonormal하게 초기화되기 때문에 invertible합니다.
trasnformation의 Jacobian에 해당하는 log-determinant는 변수 변화로 인해 loss function에 합쳐지며, network가 학습됨에 따라 이 convolution들을 invertible하게 유지하는 데에도 도움이 됩니다.
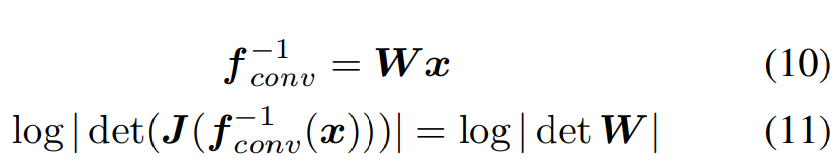
식으로 나타내면 위와 같습니다. 모든 term을 이용해 최종 likelihood를 구하면 다음과 같습니다.

우리는 p(z)가 gaussian이라고 가정했기 때문에 위와 같은 첫 term을 구할 수 있습니다. 그리고 s만 volume을 변경할 때 사용되기 때문에 loss로 사용했습니다. 여기서 첫 term을 제외한 두 term은 variable 변환에 의해 구해지는 값입니다.
Early outputs
모든 channel이 모든 layer를 거치지 않고, 저자들은 4개의 coupling layer 이후에 2개의 channel을 loss function로 출력하는 것이 더 효과적임을 알아냈습니다. network의 모든 layer를 통과한 후, final vector들은 최종 output z를 만들기 위해 이전에 출력된 모든 channel들과 연결됩니다. 일부 차원을 조기에 출력하는 것은 network가 다양한 time scale에서 information을 추가하기 쉽게 만들고, skip connection과 유사하게 초기 layer로의 gradient 전파를 돕습니다.
Inference
network가 학습된 후에, inference를 하는 것은 단순히 gaussian에서 z를 random하게 sampling하고 z를 network에 넣으면 됩니다. 학습 중에 가정된 표준편차보다 더 낮은 값을 갖는 gaussian에서 z를 sampling하는 것이 더 높은 품질의 audio를 만드는 것을 저자들은 알아냈습니다. 그래서 저자들은 train할 때 표준편차를 0.5^(0.5)로 두었고 inference할 때는 표준편차가 0.6인 gaussian에서 z를 sampling하여 사용합니다. 1x1 convolution을 invert하는 것은 weight matrix를 inverting하기만 하면 됩니다.
Experiments
저자들은 LJ speech data를 이용해 model들을 학습했습니다. 이 dataset은 13,100개의 short audio clip으로 구성되며, 이는 단일 speaker가 7개의 non-fiction book을 읽어 구성됩니다. data는 약 24시간 길이의 speech data이며, MacBook Pro를 이용해 녹음되었습니다. sampling rate는 22,050kHz입니다.
저자들은 original audio의 mel-spectrogram을 input으로 WaveNet과 WaveGlow network에 사용했습니다. WaveGlow의 경우 저자들은 80 bin의 mel-spectrogram을 사용했습니다. 그리고 FFT size는 1024이고 hop size는 256, window size는 1024로 설정하여 mel-spectrogram을 구했다고 합니다.
Griffin-Lim
Mean Opinion Score의 baseline으로 저자들은 Griffin-Lim algorithm을 사용했습니다. Griffin-Lim은 전체 spectrogram을 사용하며, 반복적으로 frequency domain과 time domain을 변환하면서 손실된 phase information을 추정합니다. 저자들은 60번의 반복을 사용했습니다.
WaveNet
저자들은 WaveNet을 비교 대상으로 사용했습니다. WaveNet은 24개의 layer를 가지고 있고 4개의 dilation doubling cycle을 가지고 있으며, 512 residual channel, 512 gating channel, 256 skip channel을 사용합니다. network는 mel-spectrogram을 전체 시간 resolution으로 upsampling합니다. network는 adam을 사용하여 학습됩니다.
WaveGlow
WaveGlow는 12개의 coupling layer를 가지고 있고 12개의 invertible 1x1 convolution을 가지고 있습니다. 각 coupling layer networks(WN)는 8개의 dilated convolution layer를 가지고 있으며, 각 512 channel이 residual connection으로 사용되며 256 channel이 skip connection으로 사용됩니다. 저자들은 매번 4 coupling layer 이후에 2개의 channel을 output으로 사용합니다. WaveGlow network는 8개 Nvidia GV 100 GPU에서 16,000 sample의 무작위로 선택된 clip을 사용하여 580,000회의 반복으로 학습되었습니다. 그리고 weight normalization과 adam optimizer를 사용하며, 24개의 batch size를 사용하고 step size는 1x10^-4입니다. 그리고 학습이 정체되었을 때, learning rate는 5x10^-5로 감소됩니다.
Audio quality comparison
MOS test를 했습니다. test받는 사람들은 청력 검사를 받은 후에 통과된 사람들만 test에 참여했습니다. test받는 사람들은 발화를 듣고 5점 scale로 평가했습니다. 저자들은 40개의 volume normalized된 발화를 평가에 사용했고 각 사람마다 random하게 발화를 들려주었습니다.
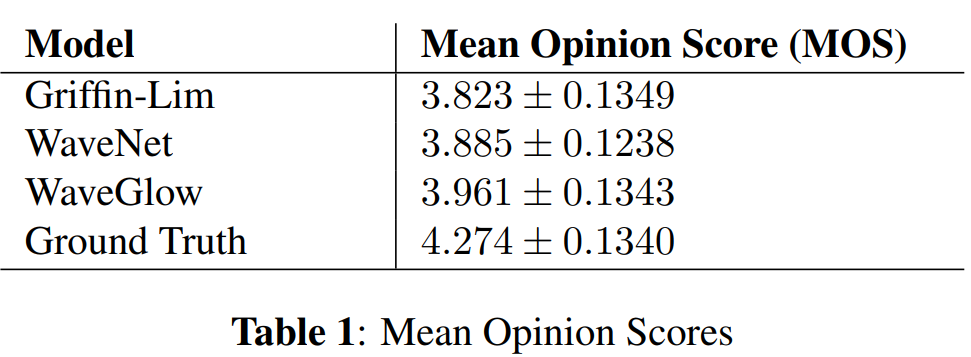
MOS는 95% 신뢰구간과 함께 나타낸 결과가 위와 같습니다. 합성된 sample의 MOS들은 실제 audio의 MOS score에 도달하지 못했습니다. WaveGlow는 가장 높은 MOS를 보여주고 있습니다. WaveGlow는 MOS 결과보단 학습이 단순하고 inference speed가 빠르다는 점이 더 큰 장점입니다.
Speed of inference comparison
저자들이 구현한 Griffin-Lim은 507kHz의 속도로 음성을 합성할 수 있습니다. Griffin-Lim은 full spectrogram을 사용해야 하며, 다른 vocoder들은 reduced mel-spectrogram을 사용합니다. WaveNet의 inference는 0.11kHz의 속도로 음성을 합성하며, 이는 매우 느립니다.
저자들이 제안한 WaveGlow는 optimize되지 않았음에도 불구하고 10초 길이의 발화를 520kHz의 속도로 합성할 수 있습니다. 이는 Parallel WaveNet보다 약간 더 빠른 속도입니다. 저자들은 WaveGlow를 optimize한다면 약 2000kHz 속도가 가능하다고 합니다.
Discussion
neural network 기반 음성 합성은 2가지 group으로 나눠집니다. 첫 번째 group은 long term dependencies를 modeling하기 위해 이전의 sample을 condition으로 하여 future audio를 sample합니다. 이러한 auto-regressive neural network model 중 첫 번째는 WaveNet이며, 이는 높은 quality audio를 생성할 수 있습니다. 하지만 WaveNet inference는 연산량이 매우 많이 듭니다. 그렇기 때문에 audio의 quality를 유지하면서 inference 속도를 향상시키기 위한 auto-regressive 연구들이 등장했습니다. 저자들이 논문을 작성할 때, 240kHz의 속도로 audio를 생성하는 auto-regressive RNN model이 가장 빠른 model이었습니다.
두 번째 그룹의 대표적인 model은 Parallel WaveNet과 ClariNet입니다. MCNN은 하나의 multi-headed convolutional network를 사용하여 audio를 생성합니다. 이 network는 5000kHz보다 더 빠르게 sample을 생성합니다. 하지만 training과정이 4가지 수작업으로 설계된 loss로 인해 복잡하며, reduced mel-spectrogram이 아닌 full spectrogram을 사용하거나 다른 feature를 사용해야만 합니다. 이는 어떻게 MCNN과 같은 non-generative approach가 mel-spectrogram이나 linguistic feature와 같은 부정확한 표현으로부터 실제같은 audio를 생성할 수 있는지는 명확하지 않습니다.
flow-based model은 network를 invertible하다고 제약함으로써, 다양한 생성 모델링 문제에 대해 다룰 수 있는 가능성을 제공합니다. 저자들은 flow-based approach를 사용하고 WaveNet의 architecture적 insight를 사용합니다. 저자들이 제안한 WaveGlow network는 쉽게 학습할 수 있는 간단한 model을 이용해 효율적으로 음성을 합성할 수 있습니다. 저자들은 high quality audio synthesis의 배포에 도움이 될 것이라고 생각한다고 합니다.
'연구실 공부' 카테고리의 다른 글
| [논문] VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network (0) | 2024.03.07 |
|---|---|
| [논문] MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis (0) | 2024.03.06 |
| [논문] WaveNet: A Generative Model for Raw Audio (0) | 2024.02.29 |
| Source Filtering (0) | 2024.02.27 |
| 음성학 관련 공부 (0) | 2024.02.27 |



