https://arxiv.org/abs/2006.06873
FastPitch: Parallel Text-to-speech with Pitch Prediction
We present FastPitch, a fully-parallel text-to-speech model based on FastSpeech, conditioned on fundamental frequency contours. The model predicts pitch contours during inference. By altering these predictions, the generated speech can be more expressive,
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
FastSpeech 기반 fully-parallel text-to-speech model인 FastPitch를 제안하며, 이는 fundamental frequency contours를 condition으로 사용합니다. model은 inference 할 때 pitch contour를 예측합니다. 이렇게 pitch contour를 예측함으로써 생성된 speech는 더 표현력 있고 utterance의 의미가 더 잘 맞으며, 듣는 이에게 더 좋은 speech를 생성하게 됩니다. FastPitch를 사용해서 일정하게 pitch를 증가시키거나 감소시키면 화자가 자발적으로 음성을 조절하는 것과 유사한 음성을 생성할 수 있습니다. frequency contour을 condition으로 하는 것은 합성된 speech의 전반적인 quality를 향상시키며, 최신 model들과 유사한 성능을 보여줍니다.
Introduction
이 논문에서 저자들이 제안한 FastPitch는 FastSpeech 기반 feed-forward model이고, synthesized speech quality를 향상시켰습니다. 모든 input에 대해 fundamental frequency를 condition으로 하여, 최신 autoregressive TTS model과 비교 가능한 성능을 보여줍니다. pitch contour를 명시적으로 modeling 하는 것은 feed-forward Transformer architecture의 단점을 해결할 수 있다는 것을 보여줍니다. textual input만 받았을 때 linguistic information이 충분치 않아 동일한 phonetic unit이어도 다른 발음을 혼합하는 문제가 존재하는데, 이 문제를 해결할 수 있음을 의미합니다. fundamental frequency를 condition으로 사용하면 수렴도 향상되고 FastSpeech에서 사용하는 mel-spectrogram target에 대한 knowledge distillation의 필요성도 없애줍니다.
WaveGlow와 결합하면, FastPitch은 실시간보다 60배 더 빠르게 mel-spectrogram을 합성할 수 있습니다. model은 각 input에 대해 하나의 값으로 pitch를 low resolution으로 예측하고 사용하도록 학습하므로, pitch를 상호작용적으로 조정하기 쉽게 만들어 pitch editing을 실용적으로 수행할 수 있게 됩니다. FastPitch를 사용하여 F_0를 일정하게 조절하면, speaker의 identity는 유지한 채로 자연스럽게 들리는 저음 및 고음 변조 음성을 생성할 수 있습니다.
Model Description
FastPitch 구조는 다음과 같습니다.

FastSpeech 기반이며 2개 feed-forward Transformer (FFTr) stack으로 구성됩니다. 첫 feed-forward trasnformer stack은 input token resolution에서 연산이 이루어지며, 두번째 stack은 output frame resolution에서 연산이 진행됩니다. x = (x_1, ... , x_n)을 input lexical unit sequence라고 하고 y = (y_1, ... , y_t)를 target mel-scale spectrogram frame sequence라 하겠습니다. 첫 FFTr stack은 hidden representaion h = FFTr(x)를 생성합니다. hidden representation h는 각 character마다 duration과 average pitch를 예측하는 데 사용됩니다.

d^ ∈ N^n이고 p^ ∈ R^n 입니다. pitch를 hidden representation h와 차원을 맞추기 위해 project 된 다음 h에 더해집니다.
여기서 h는 R^{n x d} 차원입니다. resulting sum g는 upsample된 다음 FFTr에 전달되고 mel-spectrogram sequence를 생성합니다.

duration에 맞춰 upsample되는 것을 볼 수 있습니다. ground truth p, d는 학습할 때 사용되고, predicted p^, d^가 inference 할 때 사용됩니다. model은 MSE를 적용하여 최적화됩니다.

Duration of Input Symbols
input symbol에 대한 duration은 Tacotron2 model을 통해 추정되었습니다. A ∈ R^{n x t}을 Tacotron 2의 마지막 attention matrix라 하겠습니다. i번째 input symbol의 duration은 d_i = ∑_{c=1}^{t} [argmax_r A_{r, c} = i]가 됩니다. Tacotron2에는 single attention matrix가 있기 때문에, multi-head 중에서 따로 우리가 attention head를 선택할 필요가 없습니다.
FastPitch는 alignment의 quality가 robust합니다.
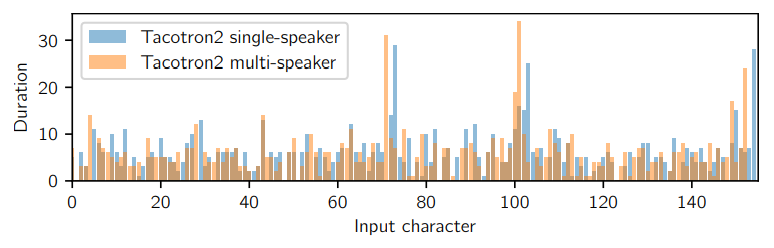
위 그림처럼 Tacotron 2 model을 통해 추출된 duration을 보면 가장 긴 duration은 대략 같은 위치에 있지만 서로 다른 단어에 할당될 수 있습니다. 놀랍게도 이러한 다른 align model은 유사한 품질의 quality를 합성하는 FastPitch model을 생성합니다. 즉 같은 단어여도 서로 다른 duration이 align 되어도, FastPitch model은 robust 하게 speech quality를 유지할 수 있음을 의미합니다.
Pitch of Input Symbol
정확환 autocorrelation method를 사용하여 acoustic periodicity detection을 통해 ground truth pitch value를 얻습니다. windowed signal은 Hann window를 사용하여 계산됩니다. algorithm은 normalize된 autocorrelation function의 최댓값 array를 찾아 후보 주파수로 사용합니다. 후보 주파수 array들에 Viterbi algorithm을 적용하여 가장 작은 cost path를 구합니다. path는 후보 frequency 사이 transition을 최소화합니다. window size를 training mel-spectrogram의 resolution과 맞추고, 각 frame마다 F_0 value를 구했습니다.
F_0는 추출된 duration d를 사용하여 모든 input symbol에 대해 평균화를 진행합니다. unvoiced value는 계산에서 제외됩니다. 학습을 위해 평균을 0, 분산을 1로 정규화합니다. 특정 symbol에 대한 음성 F_0 추정치가 없는 경우, 해당 symbol의 pitch는 0으로 설정합니다. 저자들은 F_0를 log-domain에서 modelling 했을 때 이점을 얻지 못했다고 합니다.
Experiments
저자들은 duration predictor와 pitch predictor를 동일한 구조로 구현했습니다. kernel size 3이고 input channel이 384, output channel이 256인 1-D conv, kernel size 3이고 input channel이 256, output channel이 256인 1-D conv를 사용하고, 각 뒤에는 ReLU, Layer Norm, Dropout layer를 붙였습니다. 마지막 payer는 256-channel vector를 scalar로 project합니다. dropout rate는 0.1로 사용했습니다.
Evaluation

Tacotron2와 MOS를 비교한 모습입니다. 저자들의 model이 더 좋은 평가를 받았습니다.

F_0를 증가시키거나 감소시킨 결과가 위와 같습니다. 단순히 frequency domain을 shifting하는 것보다 FastPitch는 speaker identity를 보존한 결과를 보여줍니다.
Conclusion
저자들은 FastPitch를 제안하며, 이는 FastSpeech 기반 parallel text-to-speech model입니다. FastSpeech는 prosody를 control 하면서 high-fidelity mel-scale spectrogram을 빠르게 합성할 수 있습니다. model은 prosodic information을 condition으로 하는 것이 수렴을 상당히 향상시키고 합성된 speech의 quality도 상당히 향상시킨다는 것을 입증했습니다. 저자들의 pitch conditioning method는 알려진 여러 다른 model들보다 훨씬 간단합니다.



