https://arxiv.org/abs/2110.03342
VisualTTS: TTS with Accurate Lip-Speech Synchronization for Automatic Voice Over
In this paper, we formulate a novel task to synthesize speech in sync with a silent pre-recorded video, denoted as automatic voice over (AVO). Unlike traditional speech synthesis, AVO seeks to generate not only human-sounding speech, but also perfect lip-s
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문에서 저자들은 silent pre-recorded video에 맞춰 speech를 합성하는 새로운 task인 automatic voice over (AVO)를 정형화합니다. 기존 speech synthesis와 다르게, AVO는 사람과 같이 들리는 speech를 합성할 뿐만 아니라, 완벽한 lip-speech synchronization을 목표로 합니다. AVO를 수행하는 가장 자연스러운 방법 중 하나는 video의 lip의 시간적 움직임 sequence를 condition으로 사용하는 것입니다. 저자들은 visual input을 condition으로 하는 새로운 text-to-speech model인 VisualTTS를 제안하며, 이를 통해 정확한 lip-speech synchronization을 수행할 수 있습니다. VisualTTS는 1) textual-visual attention, 2) visual fusion strategy during acoustic decoding이라는 2가지 새로운 mechanism을 제안합니다. 둘 다 input lip sequence의 lip motion과 input text content의 정확한 alignment를 형성하는 데 도움을 줍니다.
Introduction
Automatic voice over (AVO)는 silent pre-recorded video에 맞춰 speech를 합성하는 것입니다. AVO system은 spoken utterance의 silent video와 그에 맞는 text script를 input으로 받으며, lip motion, emotional state, dialogue scenario에 맞춰 자연스러운 speech를 생성합니다.
neural TTS 관련 연구에서 영감을 받아, AVO의 solution으로 text script를 input으로 받고, lip movement와 facial expression의 시간적 과정을 condition으로 사용하는 TTS system을 구현하는 것이 자연스러운 방법입니다. 하지만 사람은 audio-video mismatch에 sensitive하기 때문에 쉽지 않습니다. minor mismatch도 인지되는 speech quality와 intelligibility에 크게 영향을 끼칠 수 있습니다. 그리고 일반적인 TTS system은 visual information 없이 lip-speech synchronization을 보장하지 않습니다.
Audio-video synchronization은 multi-modal speech recognition, multi-modal speech separation과 같은 multi-modal signal processing에서 사용되었습니다. 예를 들어 audio-visual information fusion을 위해 Transformer을 사용하는 연구가 있었으며, 이를 통해 multi-modal speech recognition 성능을 크게 향상시켰었습니다.
이 논문에서 저자들은 visual information을 사용하는 VisualTTS를 제안합니다. 이는 textual-visual attention과 visual fusion strategy를 사용하여, spoken video clip으로부터 얻은 lip image sequence input의 lip motion과 text script 사이 정확한 alignment를 학습할 수 있습니다. GRID dataset을 사용하여 실험을 진행했습니다. VisualTTS는 정확한 lip-speech synchronization을 수행하며, 모든 baseline system들보다 뛰어난 성능을 보여줍니다.
이 논문의 main contribution은 다음과 같습니다. 1) AVO 연구를 정형화했으며, visual information을 사용하는 새로운 neural TTS model을 제안했습니다. 2) 저자들은 textual-visual attention과 visual fusion strategy라는 새로운 2가지 mechanisim을 제안했으며, 정확한 lip-speech synchronization을 수행합니다. 저자들이 알기론, speech synthesis 분야에서 automatic voice over를 수행하는 첫 연구입니다.
Related Work
Visual embedding
video clip은 lip motion, facial expression, emotional state와 같은 speech synthesis에 중요한 정보들을 포함합니다. 적절한 output speech의 phonetic duration rendering은 정확한 lip-speech synchronization에 의해 결정됩니다. lip-speech synchronization modeling은 lip motion과 speech signal의 characterization을 만드는 것이고, video의 lip motion feature representation은 상당히 중요합니다.
speech 관련 연구에서 visual embedding을 성공적으로 사용되어 왔습니다. visual speech recognition으로 알려진 lip-reading task의 경우, visual embedding을 사용하는 것은 video의 lip motion information을 응축하여 유용한 information을 제공하는 것으로 여깁니다. audio-visual speech enhancement task의 경우, lip reading task에서 추출된 visual embedding을 audio embedding과 결합하여 lip-speech correlation information을 제공하기도 합니다.
이러한 최근 visual embedding을 성공적으로 사용하는 연구들에 영감을 받아, 저자들은 lip-reading network로부터 visual embedding을 추출하여 duration alignment의 guide로 사용하여 정확하게 lip-speech synchronization을 수행하는 VisualTTS를 제안합니다.
VisualTTS

Overall architecture
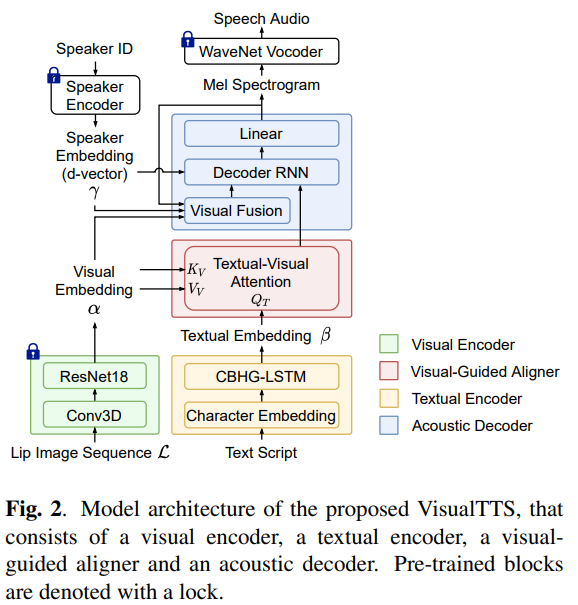
위 그림은 VisualTTS의 전체적인 구조를 나타내며, visual encoder, textual encoder, speaker encoder, visual-guided aligner, acoustic decoder와 WaveNet vocoder로 구성됩니다.
visual encoder는 주어진 lip image sequence에 대한 lip motion information을 나타내는 visual embedding α을 학습하는 것을 목표로 합니다. textual encoder는 input script를 input으로 받고 textual embedding β을 생성합니다. speaker encoder는 speaker ID를 utterance level speaker embedding γ로 encode 합니다. textual embedding과 visual embedding은 visual-guided aligner에 전해지고, aligner는 textual-visual alignmnet를 학습합니다. visual-guided aligner의 output은 acoustic decoder에 의해 mel-spectrogram feature로 decode 되며, 이 mel-spectrogram feature는 pre-trained WaveNet vocoder를 통해 audio waveform으로 변환됩니다.
textual encoder는 character embedding layer와 CBHG-LSTM module로 구성되며, Tacotron과 비슷한 구조입니다.
- Visual encoder
AVO task는 text와 video를 input으로 받으며, 전처리를 통해 video frame에서 lip region만 crop 하여 lip image sequence L을 얻습니다. 각 frame마다 1개 lip image가 있습니다. 저자들은 lip image sequence로부터 visual cue를 사용하기 위해 visual encoder를 사용합니다. 위 구조의 왼쪽 부분입니다.
visual encoder는 3D convolutional (Conv3D) layer와 ResNet-18 block으로 구성됩니다. 이러한 구조는 video에서 lip motion information을 학습하는 lip-reading task에서 효과적이었습니다. visual encoder는 lip image sequence L을 input으로 받고, lip image sequence L의 각 frame에 대한 visual embedding α을 output 합니다.
visual encoder의 모든 module은 lip-reading task에 맞춰 pre-train 하여 사용합니다. 즉 VisualTTS 학습 과정에서, visual encoder의 모든 weight는 fix 한 상태로 사용합니다.
- Speaker encoder
VisualTTS는 multi-speaker speech synthesis를 목표로 하기 때문에, speaker encoder를 위 그림과 같이 사용합니다. 이 speaker encoder는 주어진 speaker ID에 맞는 speaker embedding을 생성해주고, 이 speaker ID는 각 speaker에 맞는 unique integer입니다. speaker encoder로 lookip table을 사용하여 pre-trained speaker verification model에 의해 얻어지는 d-vector γ로 match 합니다.
- Visual-guided aligner
visual-guided aligner는 textual-visual attention (TVA) mechanism으로 구성됩니다. 이 TVA mechanism은 textual & visual information인 cross-modal information을 align 합니다.
구체적으로 visaul encoder의 output인 visual embedding α가 TVA에 key K_v, value V_v로 사용됩니다. Textual embedding β는 TVA의 query Q_T로 사용됩니다. multi-head scaled dot-product attention을 사용하여 TVA를 수행했습니다. textual-visual context는 다음과 같이 구해집니다.

위 식에서 d_K_v는 α의 dimension을 의미합니다.
speech의 내용이 text script로만 결정되기 때문에, speech의 content가 lip motion information과 일치한다면 lip motion을 통해 정확하게 speech를 합성할 수 있습니다. 이렇기 때문에 TVA는 textual-visual dependency를 위해 long-term information을 capture 하고, textual embedding과 visual embedding 사이의 alignment를 학습합니다. 이를 통해 lip motion과 잘 align 한 speech를 합성하는데 도움을 줄 수 있습니다.
- Acoustic decoder
acoustic decoder는 visual fusion layer와 Tacotron의 decoder로 구성됩니다. Tacotron decoder는 attention-based recurrent neural network (RNN)과 linear layer로 구성됩니다.
speech audio와 video는 시간적으로 synchronize 되기 때문에, mel-spectrogram의 length는 visual embedding의 length와 일정한 비율을 가집니다. mel-spectrogram의 각 frame은 이 ratio에 맞춰 video frame에 indexing 될 수 있습니다. acoustic decoding의 각 time step에서 mel-spectrogram feature의 frame은 visual fusion layer에 의해서 visual embedding과 concatenate 됩니다. 이렇게 하는 목적은 visual embedding과 mel-spectrogram 사이 시간적 correlation을 활용하는 것입니다. concatenated representation은 speaker embedding과 더해져 multi-modal representation을 형성하며, 이는 visaul fusion layer의 output으로 multi-modal hidden sequence로 project 됩니다. acoustic decoding 과정에서 TVA의 output은 speaker embedding과 concatenate 되고, visual fusion output과 함께 남은 decoder 부분에 pass 되고 mel-spectrogram feature로 decode 됩니다.
acoustic decoder는 합성된 speech가 video clip의 length에 도달했을 때 speech generation을 멈출 수 있으며, visual embedding length가 정확한 utterance duration을 나타내므로 autoregressive speech synthesis의 infinite decoding 문제를 해결할 수 있습니다.
Experiments
저자들은 objective evaluation과 subjective evaluation 모두 수행하여 VisualTTS를 평가했습니다. 저자들은 automatic voice over에 대한 baseline이 존재하지 않기 때문에, 저자들은 Tacotron과 Tacotron에 TVA를 결합한 model을 baseline TTS로 사용했습니다.
Datasets and experimental setup
저자들은 GRID dataset을 가지고 실험을 진행했으며, 이는 33명 speaker가 있고, 각 speaker마다 1000개의 짧은 영어 utterance로 구성된 audio-visual dataset입니다. traininig set으로 33명 speaker 마다 900개 sentence를 사용했으며, 총 32670개 utterance를 사용했습니다. 그리고 남은 data들은 test set으로 사용했습니다. speech audio들은 24kHz로 resample 했으며, 25Hz frame rate video로 합성했습니다.
저자들은 TVA의 head 수를 2개로 설정했습니다. TVA의 output을 64차원으로 project 했습니다. visual fusion layer output의 차원은 256으로 설정했습니다. textual embedding의 차원은 512로 설정했습니다. RNN decoder는 256차원 hidden size인 1개 attention RNN layer와 10% zoneout rate인 256차원 hidden size인 2개 LSTM layer로 구성했습니다. acoustic decoder는 80차원 mel-spectrogram feature를 생성하고, 한번에 2개 frame을 생성했습니다. visual encoder는 LRS2와 LRS3로 pretrain 했습니다. Conv3D의 kernel size는 {5, 7, 7}로 설정하여 사용했습니다. lip image sequence의 각 frame을 512차원 visual embedding으로 사용했습니다. AISHELL2 corpus로 speaker verification task를 수행하도록 pretrain 된 d-vector extractor로 추출된 256차원 d-vector를 speaker embedding으로 사용했습니다. speaker embedding은 TVA output으로 concatenate 되기 전에 64차원으로 project 되었습니다. 모든 model들은 waveform generation을 수행하는 vocoder로 VCTK dataset으로 pre-train 된 WaveNet을 사용했습니다.
Objective evaluation
저자들은 Lip Sync Error - Confidence (LSE-C)와 Lip Sync Error - Distasnce (LSE-D)를 사용하여 silent video와 합성된 speech 사이의 lip-speech synchronization을 평가했습니다. LSE-D는 spoken utterance video로부터 얻은 audio representation과 lip representation 사이 평균 distance를 측정합니다. LSE-C는 평균 confidence score를 의미합니다. LSE-C와 LSE-D는 pre-trained SyncNet으로 측정됩니다. 낮은 LSE-D value와 높은 LSE-C value가 더 나은 lip-speech synchronization을 나타냅니다. 결과는 다음과 같습니다.

저자들의 VisualTTS는 뛰어난 성능을 보여주고, 다른 baseline보다 더 뛰어난 결과를 보여줍니다.
Subjective evaluation
voice quality와 lip-speech synchronization 관점에서 평가를 수행했습니다. 12명 참여자가 평가를 수행했으며, 각 framework마다 30개 speech sample을 사용했습니다. 결과는 다음과 같습니다.

저자들은 recored speech와 video pair를 보여주며 평가를 수행했습니다. 실험 결과를 통해 VisualTTS의 효율성을 보였습니다.
Conclusion
이 논문에서 저자들은 정확하게 lip-speech synchronization을 수행할 수 있게 TTS에 visual information을 적용한 AVO solution을 제안합니다. 저자들은 VisualTTS가 lip-speech synchronization 관점에서 baseline보다 명확히 뛰어나다는 것을 보였습니다.



