https://arxiv.org/abs/2203.15683
DRSpeech: Degradation-Robust Text-to-Speech Synthesis with Frame-Level and Utterance-Level Acoustic Representation Learning
Most text-to-speech (TTS) methods use high-quality speech corpora recorded in a well-designed environment, incurring a high cost for data collection. To solve this problem, existing noise-robust TTS methods are intended to use noisy speech corpora as train
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
대부분 TTS method들은 well-designed environment에서 녹음된 high-quality speech를 사용합니다. 그리고 dataset을 준비하는 cost는 많이 필요합니다. 이러한 문제를 해결하기 위해, 현재 존재하는 noise-robust TTS method들은 의도적으로 noisy speech corpora를 training data로 사용합니다. 하지만, 해당 TTS들은 time invariant noise나 time-variant noise 중 하나만 사용합니다. 저자들은 추가적인 noise와 환경적 왜곡 둘 다 포함하는 speech corpora를 가지고 학습할 수 있는 degradation robust TTS method를 제안합니다. time-variant additive noise를 frame-level encoder로 나타내고, time-invariant environmental distortion을 utterance-level encoder로 나타냅니다. 그리고 저자들은 linguistic content나 speaker characteristic과 같은 utterance-dependent information으로부터 분리된 clean environmetal embedding을 얻을 수 있는 regularization method를 제안합니다.
Introduction
저자들은 degradation-robust TTS method를 제안합니다. 이는 time-variant addtivie noise와 time-invariant environmental distortion 모두 포함하고 있는 degrade speech를 가지고 학습할 수 있습니다. 저자들의 method는 frame-level noise encoder를 사용하여 time-variant additive noise를 표현하고, utterance-level environment encoder를 사용하여 time-invariant environmental distortion을 표현합니다. 이 두 encoder는 TTS model을 가지고 동시에 학습됩니다. 그리고 environmental distortion을 modeling 하기 위해, 저자들은 regularization method를 제안합니다. 이는 linguistic content와 speaker characteristic과 같은 utternace-dependent information으로부터 분리된 clean environmetal embedding을 얻는 regularization method입니다. 저자들의 main contribution은 다음과 같습니다.
- 저자들은 additive noise와 environmental distortion을 동시에 다룰 수 있는 degradation-robust TTS를 제안합니다.
- 저자들은 linguistic content와 speaker information으로부터 분리된 clean environmental embedding을 얻는 regularization method를 제안합니다.
Related workd
noisy speech를 가지고 학습하는 noise-robust TTS method들이 연구되어 왔습니다. 이전 몇몇 noise-robust TTS 연구들은 speech enhancement model을 사용했습니다. 예를 들어 TTS model을 enhanced speech와 feature를 가지고 학습하거나, clean speaker로 학습된 model을 noisy new speaker로 적응시키는 방식입니다. 저자들은 degraded speech의 time-variant additive noise와 time-invaraint distortion 둘 다 표현하는 method를 새롭게 확장하는 것을 목표로 합니다. 이전 몇몇 연구들은 speech enhancement model을 사용하지 않고 background noise 또는 distortion을 modelling 했습니다. 하지만 time-invariant noise만 focusing 했었고, 사용성에 제한이 생기게 됩니다.
Method
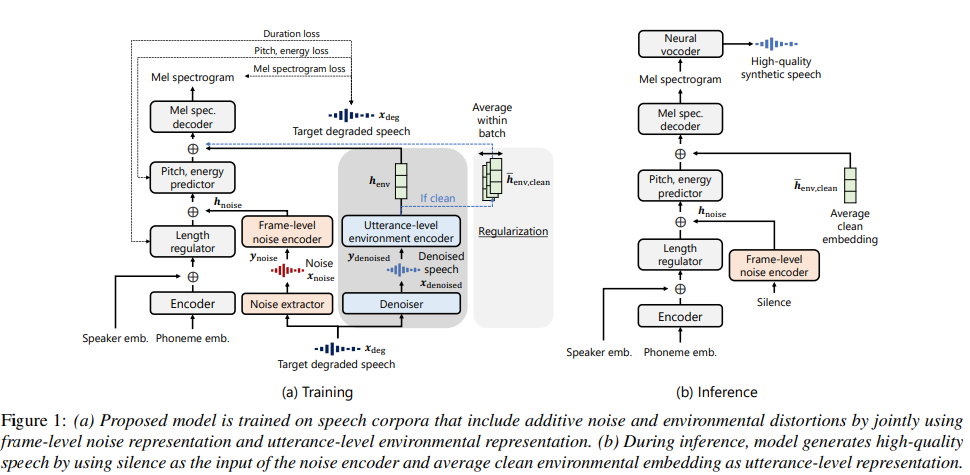
저자들의 method는 위와 같습니다. 이는 frame-level noise representation과 utterance-level environmental representation을 동시에 사용합니다. 저자들의 base method는 FastSpeech2이며, input phoneme embedding을 hidden sequence로 encoding 하는 phoneme encoder와 encoded representation의 length를 확장하고 예측하는 length regulator, 중간 representation을 가지고 output acoustic feature를 output하는 decoder로 구성됩니다. model은 multispeaker model이며, embedded speaker ID를 phoneme encoder의 output에 더하는 방식으로 구현되었습니다.
Frame-level noise representation learning
time-variant noise를 고려하여 TTS model을 학습시키기 위해, 저자들은 noise extractor를 사용하여 frame-level noise representation을 도입합니다. 이전 연구들은 중간 frame-level noise representation을 사용하는 TTS model이 단순하게 denoised speech feature를 training target으로 사용하는 것보다 더 좋은 합성 speech quality를 달성합니다. 해당 이전 연구에서는 간단한 U-Net model을 noise extractor로 사용했지만, 저자들은 waveform domain에서 noise extract를 수행하는 Conv-TasNet을 improved noise extractor로 사용했습니다. 이를 통해 더 다양한 종류의 additive noise에 대한 일반화를 진행할 수 있었다고 합니다. noise extractor는 target degraded speech로부터 additive noise만 추출하고, noise encoder는 hidden noise representation을 output합니다.
위 그림 (1)에서 볼 수 있듯이, target degraded waveform x_{deg}은 noise extractor의 input으로 사용되고, pre-trained noise extractor는 noisy speech waveform으로부터 noise waveform을 output하도록 학습됩니다. output noise waveform x_{noise}는 mel spectrogram y_{noise}로 변환된 다음 frame-level noise encoder로 input됩니다. noise encoder는 noise representation h_{noise}를 output하고, 이 representation은 target mel-spectrogram과 동일한 수의 frame을 표현하고 length regulator의 output에 추가됩니다. inference 할 때는 frame-level additive noise가 없는 output speech를 만들기 위해 침묵을 x_{noise}(n) = 0 (for all n)로 표현했습니다.
Utterance-level environmental representation learning
frame-level noise representation 외에도, proposed method는 utterance-level environmental representation도 학습합니다. speech로부터 environmental condition만 추출하기 위해, 저자들은 additive noise를 제거하는 denoiser를 사용합니다. 저자들의 denoiser는 Conv-TasNet을 기반으로 하며, 이는 noisy speech waveform으로부터 denoised speech waveform을 output하도록 pre-train 됩니다. target degraded waveform x_{deg}는 denoiser의 input이고, denoiser는 denoised speech waveform x_{denoised}를 output합니다. mel-spectrogram y_{denoised}는 x_{denoised}로부터 얻어지며, 이 y_{denoised}를 utterance-level environment encoder에 input 하여 environmental reprsentation h_{env}를 얻습니다. 저자들은 utterance-level environmental encoder에 style token layer를 사용했습니다. environmental embedding h_{env}는 TTS model의 condition으로 사용되며, 위 그림 (a)와 같습니다.
style token layer를 처음 제안한 논문에서는 reverberation condition에서 학습된 TTS model을 evaluation 했습니다. inference할 때는, clean condition에 대응하는 style token을 직접 선택하며, 이는 시간이 걸리는 작업입니다. 그러므로 저자들의 inference에서는 average clean embedding h_{env, clean}을 TTS model의 condition으로 사용하는데, 이 h_{env, clean}은 clean environmental condition에서 녹음된 모든 training data의 h_{env}의 평균으로 구해집니다.
하지만 training할 때 각 utterance로부터 h_{env}를 구하고 inference 할 때 average clean embedding h_{env, clean}을 TTS model에 단순히 제공하는 것은 요구되는 degradation-robust training을 달성한다는 보장이 없습니다. 왜냐하면 h_{env}는 utterance-dependent 하고 speaker characteristic과 연관이 있기 때문입니다. 그래서 h_{env, clean}은 clean condition을 필수적으로 나타내는 것은 아니며, 이를 바로 사용하는 것은 low-quality synthetic speech를 유발할 수 있습니다. 그래서 저자들은 regularization method를 제안합니다.
Training objective with regularization term
저자들의 model의 training objective는 duration, pitch, energy에 대한 mean squared error (MSE) loss와 mel-spectrogram의 L1 loss로 구성됩니다. 위 loss들의 sum을 L_{main}으로 나타내며, 이는 FastSpeech2의 objective와 동일합니다.
추가로, 저자들은 학습 과정에서 average clean environmental embedding을 사용하는 regularization method를 사용합니다. regularization의 경우, 저자들은 clean environmental condition의 speech data만 사용하는 subtask learning을 사용합니다. subtask learning에서, target speech로부터 environmental embedding h_{env, clean}을 추정하고, batch에 맞춰 average를 수행합니다. averaged embedding은 TTS model의 condition으로 사용되고, main task의 loss에 맞춰 동일하게 loss function이 적용됩니다. L_{average}가 subtask learning에 의해 정의된 regularization term입니다. 전체 training objective는 다음과 같습니다.
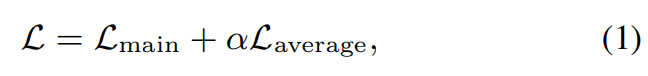
위 식에서 α는 weighting term으로, 1.0으로 설정하여 실험했다고 합니다. 이 regularization을 사용해 utterance-level encoder는 여러 utterance에서 공유된 acoustic aspect (i.e., time-invariant environmental condition)를 추출할 수 있으며, 이는 linguistic content와 speaker characteristic과 같은 utterance-dependent information과 분리되어 구해집니다. 그림 (a)에서 진한 회색 부분은 L_{main}을 정의하는 main-task learning을 묘사하고, 연한 회색 부분은 subtask learning을 묘사합니다.
Experimental evaluation
Evaluation of DRSpeech and baseline methods
DRSpeech를 여러 baseline method와 비교했습니다. baseline으로 Conv-TasNet 기반 Enhancement TTS와 enhanced data로 학습된 FastSpeech2를 사용했습니다.

먼저 mel cepstral distortion (MCD)와 log F0 root mean squared error (RMSE)를 수행한 결과입니다. 저자들의 method가 noise + reverb에서 가장 좋은 성능을 보이는 것을 볼 수 있습니다.

그 다음 MOS score입니다. 결과는 위와 같습니다. 다른 model들에 비해 noise나 reverberation이 있을 때 좀 더 강건한 모습을 보이는 것을 볼 수 있습니다.
Conclusion
저자들은 degradation-robust TTS method를 제안합니다. 이는 frame-level noise representation과 utterance-level environmental representation을 사용합니다. 저자들은 학습 과정에서 utterance-independent clean environmental embedding을 얻기 위해 regularization method도 사용합니다. 실험 결과를 통해 저자들의 method가 noise-robust TTS method보다 더 뛰어나다는 것을 보였습니다.



