https://arxiv.org/abs/2305.10763
CLAPSpeech: Learning Prosody from Text Context with Contrastive Language-Audio Pre-training
Improving text representation has attracted much attention to achieve expressive text-to-speech (TTS). However, existing works only implicitly learn the prosody with masked token reconstruction tasks, which leads to low training efficiency and difficulty i
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
사람들은 표현력이 풍부한 TTS를 달성하기 위해 text representation들을 개선하는 것에 더 많은 관심을 갖고 있습니다. 하지만 현재 존재하는 방식들은 masked token reconstruction task를 활용하여 암묵적으로 prosody를 학습하는 방법을 사용하며, 이는 낮은 학습 효율성과 prosody modelling에 어려움을 초래할 수 있습니다. 그래서 저자들은 CLAPSpeech를 제안합니다. 이는 다른 context에서 나온 동일한 text token들의 prosody variance를 명시적으로 학습할 수 있는 cross-modal contrastive pre-training framework입니다. 구체적으로, 1) encoder input과 contrastive loss의 정교한 설계를 통해, joint multi-modal space에서 model이 text context와 그에 대응하는 prosody pattern을 연결시키도록 만듭니다. 2) 다양한 level에서 prosody pattern을 capture하기 위해 설계된 multi-scale pre-training pipeline을 제안합니다. 저자들은 CLAPSpeech를 TTS model에 적용하여 더 나은 prosody를 표현할 수 있음을 보여줍니다.
Introduction
TTS를 위한 text represenetation learning method들은 masked language model task (i.e., text corpus를 가지고 BERT같은 large language model을 학습시키기)를 기반으로 하거나 masked acoustic model task (i.e., input text를 기반으로 masked mel-spectrogram을 reconstruct)를 기반으로 수행됩니다. 하지만 이는 2가지 단점이 존재합니다. 첫째, 이전 model들은 reconstruction loss를 통해 암묵적으로 prosody를 학습하기 때문에, model이 prosody를 modelling하기 쉽지 않습니다. 둘째, pronunciation space와 prosody space를 분리할 수 없으며, 학습 효율성이 떨어지고 model의 capacity를 낭비하게 됩니다.
기술적으로 prosody는 동일한 token의 condition (text context and speaker)에 따라 pitch와 duration variance으로 여길 수 있습니다. 이 논문에서는 text context에 연관 있는 prosody에 대한 연구를 주로 진행했습니다. 예를 들어, "higher"라는 동일한 단어를 "higher up" 또는 "slightly higher"에 사용할 수 있으며, 이는 다른 prosody로 발음될 수 있습니다. 최근 cross-modal contrastive learning 연구들에 영감을 받아, 저자들은 Contrastive Language-Audio Pre-Training for Text-to-Speech (CLAPSpeech)라 불리는 text context와 high-level prosody pattern을 연결하는 contrastive learning method를 제안합니다. 구체적으로, text encoder는 text context로 prosody를 예측하도록 학습되고 prosody encoder는 선택된 token의 speech segment로부터 ground-truth prosody를 추출할 수 있도록 학습됩니다. 학습 과정에서 동일한 발음이 가능한 토큰을 포함한 N개 text-speech pair를 선택합니다. text token을 그에 대응하는 prosody (GT speech에서 추출)와 align하고 다른 text context로부터 뽑아낸 prosody representation은 밀어냄으로써, text encoder는 text context로부터 prosody를 추출하도록 학습됩니다. pre-training CLAPSpeech는 다음과 같이 나타낼 수 있습니다.

prosody pattern이 여러 level로 표현될 수 있습니다. 그래서 저자들은 두 CLAPSpeech model이 phoneme level에서 prosody information을 capture하고, word level에서 prosody information을 capture하게 학습하는 multi-scale pre-training framework를 사용합니다. pre-training 이후, 저자들의 CLAPSpeech는 모든 TTS model의 text encoder에 사용될 수 있고, 세밀한 prosody representation을 생성할 수 있게 됩니다.
저자들의 방식의 효율성과 일반화 성능을 입증하기 위해, 저자들은 pre-train CLAPSpeech model에 두 large-scale automatic speech recognition (ASR) dataset을 사용했습니다. CLAPSpeech의 pre-trained text encoder를 TTS baseline model에 적용하여 표현력 있는 TTS system을 구현하여 CLAPSpeech의 효과를 확인할 수 있었습니다.
요약하자면, CLAPSpeech는 3가지 이점이 있습니다.
- prosody를 명시적으로 학습하는 contrastive objective를 사용하여 이전 method들보다 더 작은 model scale을 가지고도 더 나은 prosody representation을 수행할 수 있습니다.
- CLAPSpeech의 text representation은 TTS system에 쉽게 적용될 수 있습니다.
- 세밀한 prosody transfer와 같은 potential application을 보여줍니다.
Related Work
Expressive TTS
최근 몇 년동안, 현대 neural TTS는 실용성과 오디오 품질 면에서 상당한 발전을 이루었습니다. 그러나 plain input text에 맞춰 expressive prosody를 modling하는 것은 여전히 어려운 문제입니다. expressive TTS를 수행하기 위해, 한 가지 실용적인 방법은 reference encoder와 style token을 사용하는 것입니다. 하지만 inference 할 때 적절한 reference audio를 선택하는 것은 어렵습니다. 다른 연구들은 prosody를 modeling하는 것에 focus를 맞춥니다. 이는 2가지로 나눌 수 있습니다. 1) prediction-based (PB) TTS system으로, pitch contour, duration, energy와 같은 prosody 특성들을 예측하는 external predictor를 학습하는 방법입니다. 2) variation-based (VB) TTS의 경우, latent space에서 prosody를 modelling하기 위해 variational audio-encoder (VAE) 또는 normalizing flow를 사용하는 방식입니다.
또 다른 연구들은 prosody prediction을 잘 수행하기 위해 풍부한 prior knowledge로 text representation을 더 잘 표현하는 방법에 대한 탐구를 수행합니다. graph network와 같은 전용 modeloling 방법을 통해 syntax information을 통합하기도 합니다. text pre-training과 speech pre-training을 위한 representation learning method 또한 TTS의 prosody를 향상시킬 수 있습니다.
Representation Learning for TTS
self-supervised pre-training method는 TTS의 text processing이나 speech generation 성능을 향상시키기 위해 사용되어 왔습니다. 초기에는 pre-trained word embedding을 사용하여 TTS system의 robustness를 향상시켰습니다. 최근에는 pre-trained large masked language models (MLMs)을 사용하여 web-scale text corpus로부터 학습된 풍부한 semantic information을 사용하기 위한 연구가 진행되었습니다. 하지만 text space에만 focus 하여 연구가 진행되었으며, model이 speech space에서 알지 못하는 다양한 prosody pattern들도 고려하는 expressive prosody를 modelling 하는 것은 여전히 문제로 남아있습니다. TTS의 경우, ProsoSpeech는 speech로부터 이산적인 prosody representation을 추출하기 위해 word-level vector quantization bottleneck을 사용하기도 합니다. Masked acoustic model (MAM)은 continuous speech (prosody) represntation을 생성하도록 speech encoder를 학습시킵니다. 구체적으로, 학습 과정에서 speech spectrogram 중 일부를 mask token으로 대체하거나, text condition 없이 masked spectrogram을 recover 하도록 학습시킵니다. 이를 통해 speech encoder를 학습시킬 수 있습니다. A3T는 MAM이 masked mel-spectrogram을 reconstruction 할 수 있도록 보조 information으로 text encoder를 학습시키기도 합니다.
CLAPSpeech와 이전 TTS 연구들과 다른 점은 다음과 같습니다: 이전 연구들은 masked token reconstruction task를 이용해 implicit하게 prosody information을 학습하지만, CLAPSpeech는 context-correlated prosody를 명시적으로 학습할 수 있도록 cross-modal contrastive learning을 사용하는 첫 연구입니다. 이를 통해 더 나은 prosody prediction이 가능하고 model capacity를 더 효율적으로 사용할 수 있습니다.
CLAPSpeech
저자들은 cross-modal contrastive learning approach를 사용해서 TTS의 prosody prediction을 더 잘 수행하는 text representation을 제공하는 CLAPSpeech를 제안합니다. 구조는 아래 figure 1처럼 생겼습니다.
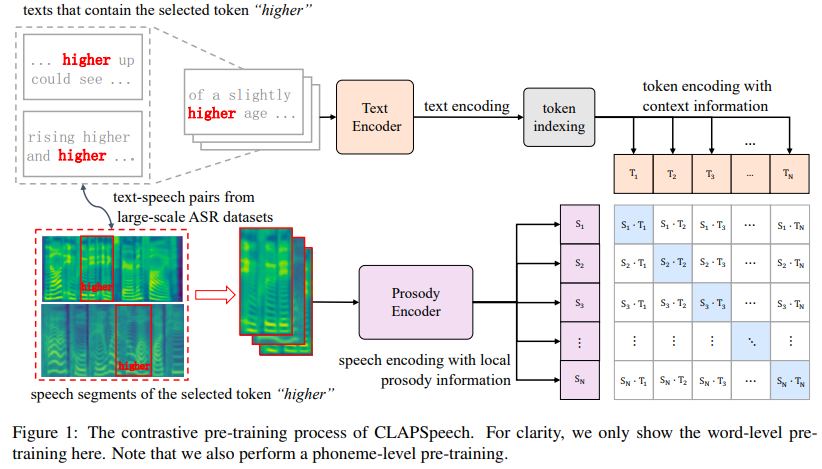
CLAPSpeech는 text encoder와 prosody encoder로 구성되며, training objective는 text token과 speech segment를 공통 prosody space에서 연결되도록 만듭니다. 이 network structure는 정교하게 설계되어 text encoder가 효율적으로 text context를 처리할 수 있고, prosody encoder는 timbre와 같은 다른 변수들을 제거하여 speech segment에서 high-level prosody pattern을 추출할 수 있었습니다. 그다음 multi-scale contrastive pre-training framework을 사용하여 CLAPSpeech가 phoneme level과 word level에서 prosody를 capture 할 수 있게 만들었습니다. 최종적으로 CLAPSpeech의 pre-trained text encoder가 최신 TTS system에 간단하게 적용될 수 있고, prosody prediction을 향상시킬 수 있음을 보여줬습니다.
Text Encoder and prosody Encoder
동일하게 발음되는 token의 prosody는 text context에 따라 다양합니다. CLAPSpeech는 text context와 high-level prosody pattern 사이 연관성을 modelling 하는 것을 목표로 합니다. 이를 위해 저자들은 text encoder와 prosody encoder를 구현하여 text-speech multi-modal prosody embedding space를 만듭니다.
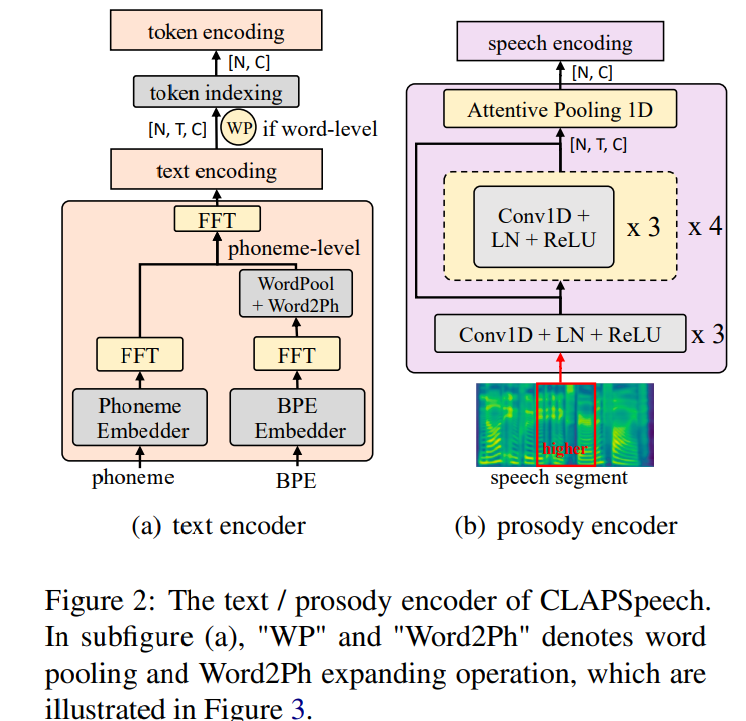
위 그림에서 (a)와 같이 text encoder는 input text의 phoneme과 byte pair encoding (BPE)를 input으로 사용합니다. phoneme sequence는 model이 phonological habit (예를 들어 영어의 linking phenomenon)에 연관된 prosody pattern을 추출하도록 도와주고, BPE sequence는 model이 semantic information을 추출하도록 도와줍니다. text encoder의 network 구조는 몇 개 Feed Forward Transformer (FFT)로 구성되며, 이는 TTS model이 long text sequence를 robust하게 처리할 수 있다고 증명된 방식입니다. 구체적으로 두 개 독립적인 FFT block이 각 phoneme sequence와 BPE sequence를 처리하도록 학습됩니다. 이로 phoneme FFT block이 phonetic space에서 phonological habit을 modelling 하고, BPE FFT block은 semantic information을 추출할 수 있게 됩니다. 한 가지 어려움은 phoneme sequence와 BPE sequence의 length가 맞지 않는다는 점입니다. 두 sequence를 time 축에 따라 concatenation하는 대신, 저자들은 word-level pooling (WP)를 BPE에 수행하여 word level로 encoding 한 다음, 이를 phoneme level로 확장하는 방법을 사용했습니다(word2ph 연산이라 불림). 구체적으로 다음과 같습니다.
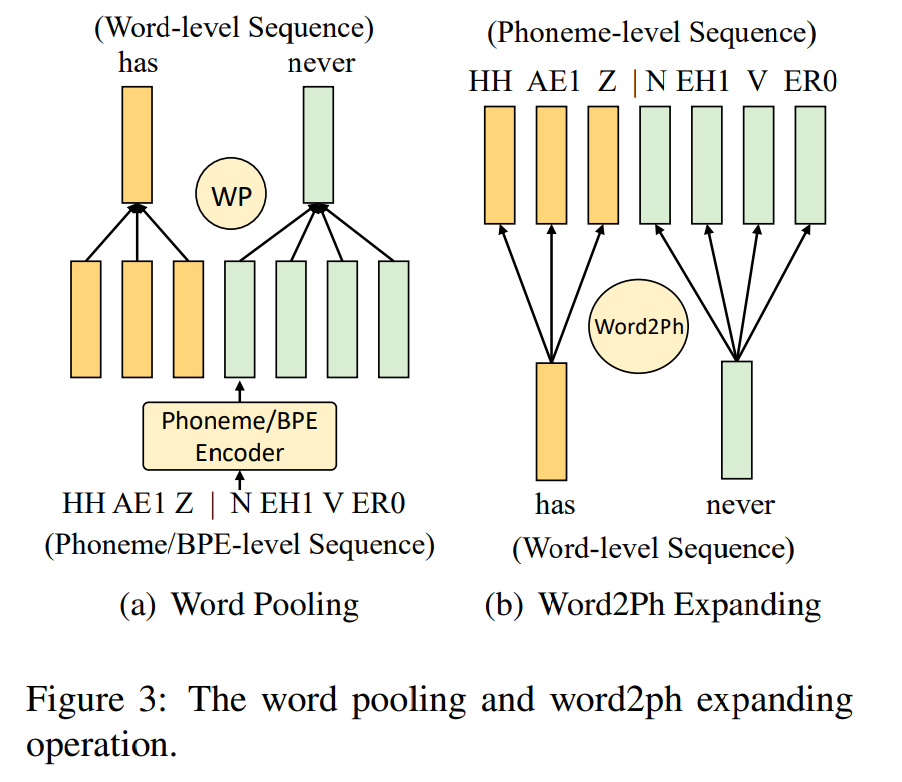
WP operation은 word boundary에 맞춰 각 단어들의 phoneme hidden state들을 average합니다. 그리고 word2ph operation은 word hidden state를 반복하여 word boundary 내부의 각 phoneme을 표현합니다.
phoneme sequence와 BPE sequence가 fusion된 후, 추가적인 FFT block을 사용하여 aligned phoneme encoding과 BPE encoding을 fusion 하여 최종 phoneme-level text encoding을 얻습니다. pre-training 과정에서, 선택된 한 개 token을 분석하기 때문에, phoneme-level text encoding에서 indexing 하여 선택된 token encoding을 얻고, 이를 cross-modal embedding space로 linear하게 projection합니다. TTS를 수행할 땐, text encoder의 phoneme level output이 쉽게 TTS system의 feature로 사용될 수 있습니다.
prosody encoder는 선택된 token의 Ground-Truth speech segment로부터 prosody pattern을 추출하는 것을 목표로 합니다. 그러므로 mel-spectrogram을 word boundary에 맞춰 clip하여 input speech feature로 사용합니다. 그다음 prosody encoder는 input mel-spectrogram을 global encoding으로 처리하여 token encoding과 연결합니다. 선택된 token에 대한 clipped speech segment는 local prosody information만 포함하고 contextual information은 유출하지 않습니다. contrastive learning을 통해 추출된 global prosody encoding은 phonetic and speaker space와 분리될 수 있습니다. 왜냐하면 positive sample과 negative sample은 동일한 소리로 발음되는 token에 속할 수 있기 때문에 phonetic information은 제거되게 됩니다. 그리고 speaker information은 text encoder에게 제공되지 않으며, prosody encoder는 학습 과정에서 output feature에 prosody information을 maximize하고 speaker information은 filter out 하기 때문에 global prosody encoding을 분리할 수 있습니다.
context-aware text encoding과 context-unaware mel encoding을 connecting하면서 prosody encoder는 speech segment에서 high-level prosody information을 추출하도록 학습합니다. 동시에 text encoder는 text context를 이용하여 prosody encoder에서 추출된 prosody를 예측하도록 학습됩니다. 즉 text encoder의 phonetic FFT가 prosody encoder의 prosody를 잘 반영할 수 있도록 학습된다는 것입니다. 저자들은 prosody encoder로 ResNet-50을 사용했는데, ResNet-50이 robust 하기 때문에 사용했다고 합니다.
Multi-scale Contrastive Pre-training
CLAPSpeech의 key idea는 다른 context에 대한 동일한 text token의 prosody variance를 modelling 하는 것입니다. contrastive pre-training을 위해 mini-batch를 생성했으며, random하게 text token을 선택하여 N개 text-speech pair batch를 sample했다고 합니다. phoneme level과 word level에서 prosody variance를 더 잘 추출하기 위해, 저자들은 multi-scale contrastive training framework를 사용합니다. 구체적으로 저자들은 phoneme-level text token과 word-level text token에 대해 두 가지 CLAPSpeech를 학습시켰습니다.
phoneme-level CLAPSpeech training process부터 보겠습니다. 선택된 phoneme token을 포함하는 text context를 X_{text}로 나타냅니다. phoneme token의 처리된 speech segment를 X_{speech}로 나타내며, X_{speech} ∈ R^(F x T)이고, F는 mel bin을 나타내고 T는 time bin을 나타냅니다. 단순화를 위해 X_{text}와 X_{speech}를 N개 text-speech pair를 나타내도록 사용합니다.
text와 speech는 text encoder와 prosody encoder를 통해 pass됩니다. text encoder의 output은 input text의 phoneme-level encoding이고, phoneme-level text sequence의 phoneme token의 index를 사용하여 표현합니다. speech encoding의 output은 input speech segment의 gloabl representation입니다. output representation은 normalize 된 다음 multi-modal embedding space로 linear하게 project됩니다. 식으로 나타내면 다음과 같습니다.
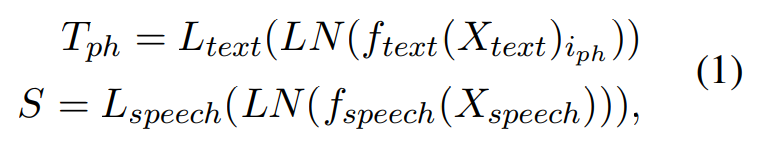
위 식에서 T_{ph} ∈ R^(N x C)는 phoneme token representation을 의미하고, S ∈ R^(N x C)는 channel size가 C인 speech representation을 의미합니다.
이를 이용해 CLAPSpeech는 N x N text-speech pari을 예측하도록 학습됩니다. 구체적으로 text encoder와 prosody encoder는 N개 real pair에 대해서는 cosine similarity를 maximize하도록 학습되고, N^2 - N 개 incorrect pair에 대해서는 minimize하도록 학습됩니다. symmetric cross-entropy loss는 다음과 같이 정의될 수 있습니다.
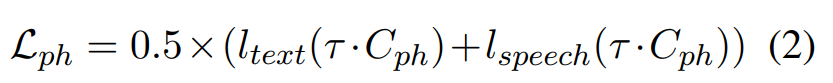
C_{ph} ∈ R^(N x N)은 phoneme token encoding T_{ph}와 speech encoding S 사이의 cosine similarity matrix를 의미하고, 이는 T_{ph}S^T로 구해집니다.
word-level CLAPSpeech은 phoneme-level text encoding을 word level로 처리하기 위해 word pooling을 수행합니다. 그 다음 word token encoding T_{word}를 얻기 위해 indexing 합니다. trianing loss는 다음과 같이 정의될 수 있습니다.
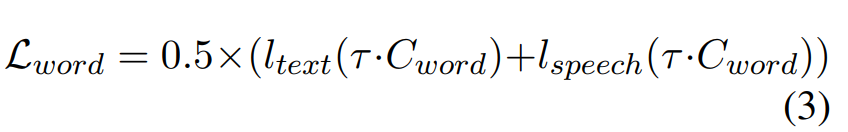
위 식에서 C_{word}는 word token encoding T_{word}와 speech encoding S 사이 cosine similarity를 의미합니다.
CLAPSpeech Plugged in TTS Systems
CLAPSpeech의 text encoder는 풍부한 prosody information과 함께 text representation을 TTS task에 제공할 수 있습니다. 생성된 text representation은 phoneme level이기 때문에, CLAPSpeech는 TTS system의 unit으로 쉽게 적용되어 prosody prediction을 향상시킬 수 있습니다. 구체적으로, 저자들은 최신 variation-based TTS system인 PortaSpeech를 예시로 사용했습니다. 그림으로 나타내면 다음과 같습니다.
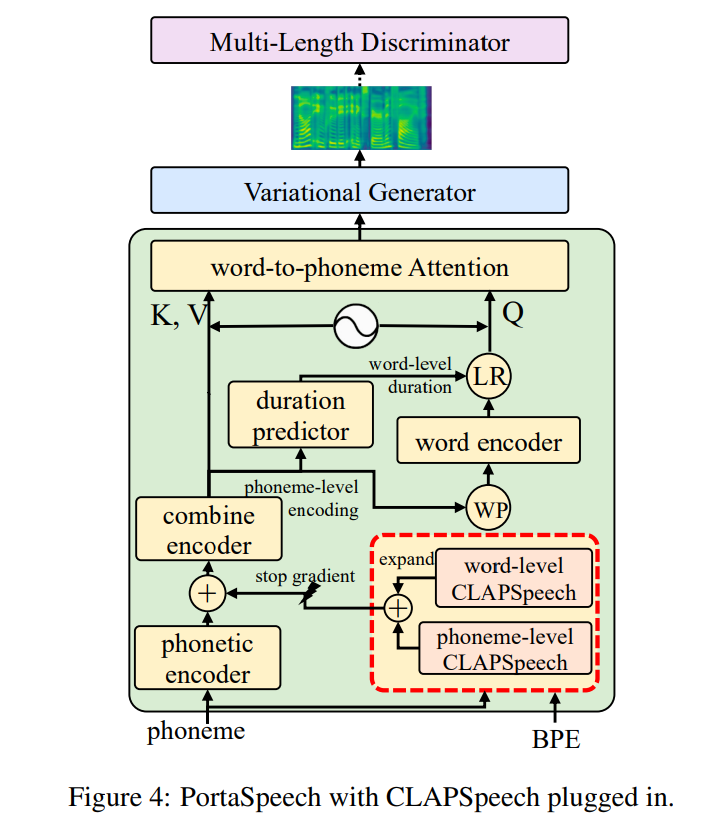
CLAPSpeech의 pre-trained text encoder (위 그림에서 빨간색 점선 직사각형 부분)는 PortaSpeech의 original phonetic encoder의 추가적인 encoder로 사용됩니다. phonetic encoder의 phoneme-level output과 CLAPSpeech text encoder의 output은 fusion되고 뒤에 오는 encoder에 의해 처리됩니다. TTS sytem을 학습할 때 CLAPSpeech의 text encoder parameter는 고정시킵니다. CLAPSpeech는 다른 TTS system에 쉽게 적용될 수 있습니다.
Experiments
저자들은 CLAPSpeech를 다른 model과 비교했습니다. 실험 결과는 다음과 같습니다.
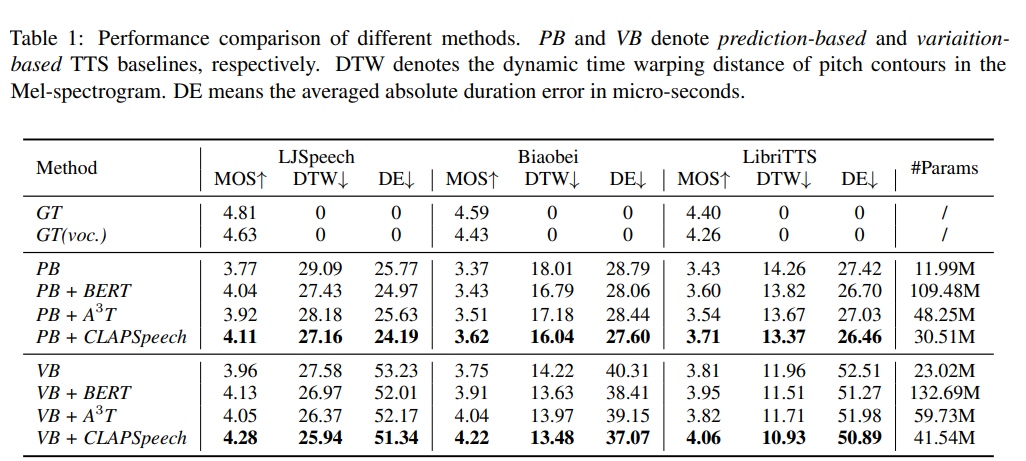
CLAPSpeech가 다른 method보다 더 좋은 성능을 보이는 것을 볼 수 있습니다. 최근에 등장한 expressive TTS model들보다 더 효과적으로 prosody prediction을 향상시키는 것을 볼 수 있습니다. 게다가 CLAPSpeech는 BERT와 A3T model들보다 훨씬 적은 수의 parameter로 더 좋은 성능을 보입니다.

위 그림을 보면 CLAPSpeech가 더 실제같은 pitch contour를 생성하는 것을 볼 수 있습니다.
Conclusion
이 논문에서는 더 나은 text representation과 풍부한 prosody information을 제공하는 cross modal contrastive pre-training framework인 CLAPSpeech를 제안합니다. text encoder와 prosody encoder의 design을 통해, CLAPSpeech는 text context와 그에 대응하는 prosody pattern을 연결시킬 수 있도록 학습합니다. 저자들은 multi-scale pre-training을 통해 multiple level에서 prosody pattern을 추출합니다.



