https://arxiv.org/abs/2206.04769
CLAP: Learning Audio Concepts From Natural Language Supervision
Mainstream Audio Analytics models are trained to learn under the paradigm of one class label to many recordings focusing on one task. Learning under such restricted supervision limits the flexibility of models because they require labeled audio for trainin
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
주류 오디오 분석 model들은 task에 맞춰 하나의 class에 대해 여러 개의 recording들을 사용하는 방식으로 학습됩니다. 이러한 제한된 supervision을 사용하여 학습하는 것은 model의 유연성을 제한하는데, 왜냐하면 학습을 위해서 labeled audio를 필요로 하고 사전 정의된 category에 대해서만 예측이 가능하기 때문입니다. 그래서 저자들은 이러한 학습 방법 대신 자연어로 audio concept을 학습하는 방법을 제안합니다. 저자들은 이를 Contrastive Language-Audio Pretraining (CLAP)이라 부르며, 두 가지 encoder와 contrastive learning 방식을 사용하여 audio와 text description의 공통 multimodal space를 구현하는 방식으로 language와 audio를 연결하는 방법을 학습합니다. 저자들은 CLAP을 128k audio-text pair를 사용하여 학습했으며, 16개 downstream task에 대한 평가를 진행했습니다.
Introduction
self-supervised learning (SSL)은 unlabeled audio를 가지고 model을 pretrain하기 때문에, class label로부터 제한된 supervision을 사용하는 것을 피할 수 있습니다. 하지만 SSL은 자연어에서 의미적 지식을 포함하지는 않습니다. 그래서 pretrained model은 class label paradigm 하에서 supervised setup learning에서 downstream task에 적응됩니다. 주류 model과 SSL model은 통계적 output layer를 가지고 있으며 predefined category에 대해서만 예측할 수 있습니다. 반면, zero-shot prediction이 가능한 model은 input audio를 받아서 사용자가 입력한 class에 맞춰 prediction score를 구할 수 있습니다. 이러한 유연함과 일반화가 가능하기 위해, model은 acoustic semantic과 language semantic 사이의 관계를 학습할 필요가 있습니다.
두 방식의 중간 path를 사용하면 자연어 supervision으로부터 audio concept을 학습할 수 있습니다. Computer Vision에서는 자연어 supervision을 사용하여 image representatation을 성공적으로 학습했으며, 이를 통해 여러 downstream task에서 Zero-shot prediction을 수행할 수 있었고 supervised setup에서 target dataset으로 adapt 할 수도 있었습니다. audio domain에서 Wav2clip과 Audioclip은 CLIP을 이용해 distill되고 AudioSet의 audio와 class label로 훈련됩니다. 성능은 유망했으나, 어떻게 자연어가 새로운 class와 task에 대한 유연성과 일반화 성능에 도움을 주었는지는 아직 탐구되지 않았습니다.
저자들은 본인들이 제안한 방식을 Contrastive Language-Audio Pre-training(CLAP)이라 부르며, 이는 두 가지 encoder와 contrastive learning을 사용하여 audio와 text desciription을 공통 multiomodal space로 mapping하여 자연어와 audio를 연결 짓는 것을 학습합니다.
Method
CLAP 구조는 다음과 같습니다.
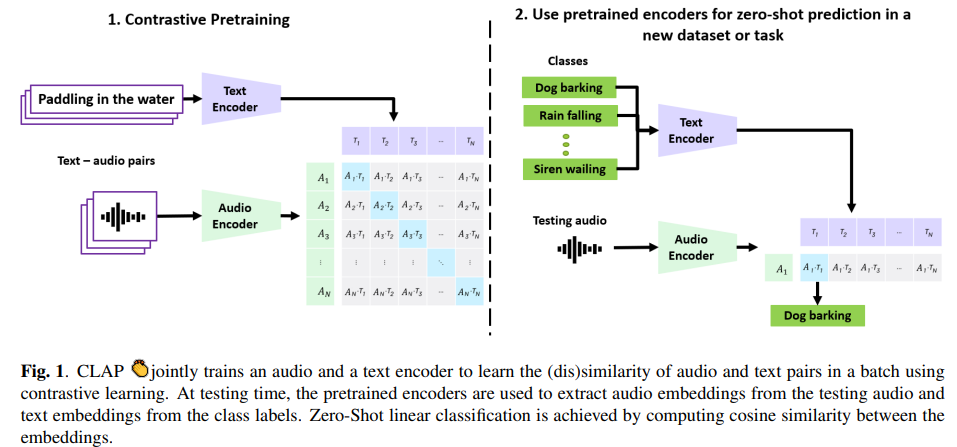
input으로 audio-text pair를 사용합니다. audio는 audio encoder로 feed되고 text는 text encoder에 feed됩니다. 두 representation은 linear projection을 이용해 joint multimodal space로 연결됩니다. 해당 multimodal space는 batch에 존재하는 audio-text pair에 contrastive learning을 적용하여 (dis)similarity를 구해 학습됩니다. projection layer와 pretrained encoder는 audio embedding과 text embedding을 구하는 데 사용되고, 이는 나중에 Zero-shot classification에 사용될 수 있습니다.
Contrastive Language-Audio Pretraining
embedding을 거친 audio representation는 X_a가 되고, X_a ∈ R^(F x T)이며, 여기서 F는 spectral component (e.g. Mel bins) 수이고, T는 time bin 수입니다. text representation은 X_t로 표현됩니다. batch에 있는 N개의 각 audio-text pair는 {X_a, X_t}_i, i ∈[0, N]로 표현됩니다. 편의를 위해 i를 제외한 {X_a, X_t}를 N개의 batch로 표현하겠습니다.
pair에 존재하는 audio는 audio encoder에 들어가고, text는 text encoder에 들어갑니다. f_a는 audio encoder를 의미하고, f_t는 text encoder를 나타낸다면, 다음과 같이 representation을 표현할 수 있습니다.

X^_a ∈ R^(N x V)는 V차원 audio representation을 의미하고, X^_t ∈ R^(N x V)는 U차원 text representation을 의미합니다.
learnable linear projection으로 X^_a와 X^_t를 d차원 joint multimodal space로 표현합니다. 식으로 나타내면 다음과 같습니다.
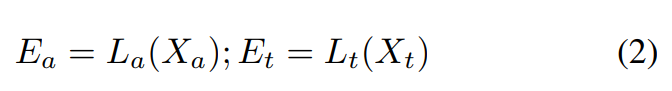
E_a ∈ R^(N x d)는 audio representation에 linear projection을 적용한 output이고, E_t ∈ R^(N x d)는 text representation에 linear projection을 적용한 output입니다.
이제 audio & text embedding (E_a, E_t)를 이용해 similarity를 측정합니다.
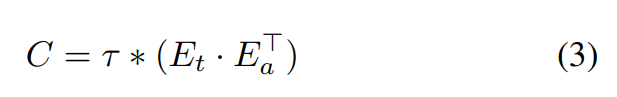
위 식에서 τ는 temperature parameter이고, 이는 logit의 range를 scale하는데 사용됩니다. similarity matrix C ∈ R^(N x N)는 N개 correct pair와 N^2 - N개 incorrect pair가 존재합니다. 대각행렬이 correct pair를 의미하고, 아닌 부분이 incorrect pair를 나타냅니다.
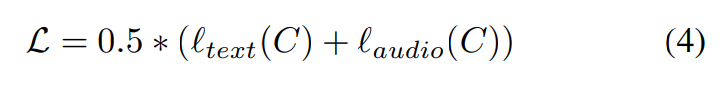
l_k = ∑_{i=0}^{N}log(diag(softmax(X)))/N이고, k는 text, audio axis를 의미합니다. 저자들은 audio encoder와 text encoder를 linear projection과 동시에 학습시키기 위해 similarity matrix에 symmetric cross entropy loss를 사용했습니다.
Zero-Shot Linear Classification
Zero-Shot classification을 위해, 저자들은 audio와 text 사이 similarity를 결정할 수 있는 CLAP의 능력을 사용합니다. target dataset이 C개의 class label을 가지고 있고, N개의 test audio가 있다고 하겠습니다. 먼저 pretrained encoder와 projection layer를 사용하여 N개의 audio embedding을 계산하고, C개의 class에 대한 text embedding을 계산합니다. 그다음 각 embedding은 common space에 있기 때문에, test audio와 class label 사이 cosine similarity를 구할 수 있습니다. 각 audio는 class label에 맞춰 logit이 존재하게 됩니다. 마지막으로 softmax나 sigmoid를 사용하여 확률 분포를 구하여 classification을 수행할 수 있습니다.
Experiments
Datasets
저자들은 CLAP을 학습시키기 위해 4개 dataset으로부터 128,010개 audio-text pair를 가져와 사용했습니다. FSD50k에서 36,796 pair를 준비하고, ClothoV2에서 29,646 pair를 준비했으며, AudioCaps에서 44,292 pair를 준비하고 MACS에서 17,276 pair를 준비했습니다.
Experimental Setup
CNN14 model을 audio encoder로 사용했습니다. embedding size는 2048이고, pre-train하여 사용했습니다. text encoder로는 BERT를 사용했습니다. 연산 효율성을 위해 text sequence length는 100 char로 제한을 두었습니다. BERT의 final layer의 [CLS] token는 769 크기 text embedding으로 사용했습니다. audio embedding과 text embedding은 learnable projection matric로 multimodal space로 projection됩니다. output dimension은 1024로 설정했습니다. temperature parameter는 0.007로 초기화하고 학습 가능하게 만들었습니다. 그리고 maximum value는 100으로 제한을 두었습니다.
Results and Discussion
저자들은 가장 Zero-Shot Learning 성능이 좋은 'Benchmark (ZS)'와 Supervised Learning 성능이 가장 좋은 'Benchmark (Best)'를 가져와 비교 대상으로 사용했습니다. 실험 결과는 다음과 같습니다.

Zero-Shot (ZS) results
CLAP (ZS)는 FSD50k, US8k, ESC50과 같은 Sound Event Classification (SEC)에서 SoTA를 찍었습니다. CLAP (ZS)는 모든 downstream에서 좋은 성능을 보여주고, speech 관련 task에서도 좋은 성능을 보여줍니다.
Supervised results
CLAP (Best)는 supervised setup에서 5가지 dataset에 대해 SoTA 성능을 보여줍니다. GTZAN Music vs Speech Classification에서 CLAP은 100% 정확도를 보여줍니다.
Effect of freezing CLAP encoders
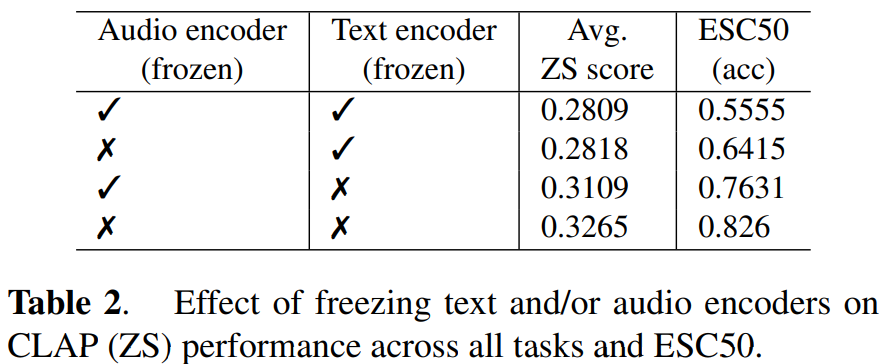
unfreezing text encoder가 unfreezing audio encoder보다 더 좋은 성능을 보여줍니다. unfreezing audio encoder는 pretrained AudioSet information로부터 SEC 이외의 것들도 학습할 수 있기 때문이라고 생각한다고 합니다.
Conclusion
저자들은 자연어 supervision으로부터 audio concept을 학습하는 CLAP을 제안합니다. CLAP은 학습을 위한 gold standard class label을 필요로 하지 않고, class prediction에 대해 유연성을 띄고, downstream task에 대한 일반화 성능을 가지고 있습니다. CLAP은 자연어 supervision으로 학습할 수 있는 audio foundation model을 설계할 때 사용될 수 있을 것이고, 광범위한 task에서 SoTA를 달성하는 데 사용될 수 있을 것이라고 생각한다고 합니다.



