https://arxiv.org/abs/2112.09726
Soundify: Matching Sound Effects to Video
In the art of video editing, sound helps add character to an object and immerse the viewer within a space. Through formative interviews with professional editors (N=10), we found that the task of adding sounds to video can be challenging. This paper presen
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
video 편집 분야에서, 소리는 물체의 특성을 추가하거나 시청자가 몰입하도록 도와줍니다. 전문적인 편집자들에게 인터뷰를 진행했었는데, video에 소리를 추가하는 것이 어려운 task라고 답변했었다고 합니다. 이 논문에서는 video와 sound를 matching하는 task를 지원하는 system인 Soundify를 제안합니다. Soundify는 video가 주어지면, 그에 맞는 sound를 식별하고 video에 sync를 맞춥니다. 그리고 공간적 audio를 생성하기 위해 panning 및 volume을 dynamic하게 조정합니다. 889명의 사람에게서 진행한 평가를 따르면, Soundify는 다양한 audio category에 대해 video와 sound를 즉시 matching할 수 있습니다. 그리고 전문가들을 대상으로 한 실험을 통해서, Soundify가 video editor들이 더 적은 작업량으로 sound를 video에 matching하는 데 도움을 줄 수 있고, 작업 완료 시간을 줄이고 사용성을 개선하는 데 유용하다는 것을 보였습니다.
Introduction
이 논문에서는 sound effect와 video를 matching하는 assistance system인 Soundify를 제안합니다. video가 주어지면, Soundify는 sound audio를 matching하고 sound clip을 video의 object와 sync를 맞추며, video content 에 맞춰 sound clip (panning and volume)을 공간적 관점에서 동적으로 조절하고, foreground object 및 배경음을 중첩하여 더 몰입감있는 soundscape를 생성할 수 있도록 도와줍니다. 저자들의 contribution은 다음과 같이 요약할 수 있습니다.
- sound와 video를 matching하는 system인 Soundify를 제안합니다.
- Soundify의 기능을 baseline들과 비교하여 test를 진행했습니다. 실험 참여자들은 Soundify를 상당히 선호하는 결과를 보였습니다.
- 전문가들은 Soundify를 활용하여 가벼운 작업량, 짧은 작업 완료 시간, 높은 유용성을 경험할 수 있습니다.
Related Work
Audio-Visual Correspondence Learning
최근에 연구자들은 audio-visual correspondence (i.e., image와 audio 사이의 연관성을 학습)를 학습하는 task들은 연구하고 있으며, 대규모 labeled dataset을 사용합니다. 초기 audio-visual correspondence learning task는 visual network와 audio network를 나눠서 학습하고 나중에 fusion layer를 적용하여 audio-visual pair가 연관성이 있는지 없는지 결정하는 방식으로 문제를 해결했었습니다. audio-visual pair는 video로부터 구해지기 때문에 noise가 존재하고, 이로 인해 연구자들은 많은 양의 video를 사용하는 weak-supervised training을 사용하기도 합니다. 이 논문에서는 labeled audio clip library와 CLIP의 image-text correspondence capability를 사용하여 audio-visual correspondence learning의 필요성을 우회합니다. 그리고 저자들은 activation map을 활용하여 neural network가 'looking at'하고 있는 위치를 modelling하여 CLIP을 확장하고, 이를 통해 세밀한 sound source의 위치를 파악하여 공간 음향을 구현합니다.
Princples of Sound to Video matching
저자들은 video에 sound를 matching하는 task를 위한 4가지 주요 원칙을 도출했습니다.
Principle 1: Surface
Soundify는 video content에 맞는 audio clip을 사용자에게 보여줘야 합니다. 대부분의 video editor들은 'Epidemic Sound'와 같은 high-quality sound library를 사용합니다. keywork 검색을 통해 알맞는 sound를 찾는 것은 큰 노력이 필요하지 않을 수 있지만, 수백 또는 수천 개의 video clip과 여러 sound가 포함된 video가 많아질수록 어려워집니다. 그래서 저자들은 video 에 맞는 sound를 노출시키는 것을 첫번째 원칙으로 정했습니다.
Principle 2: Synchronize
Soundify는 video clip 기반 audio clip을 synchronize할 수 있도록 도와줘야 합니다. 예를 들어 자전거 페달 소리 효과가 주어지면, audio는 scene에 자전거가 등장할 때 시작하고 사라질 때 끝나야 합니다. 그러나 audio clip이 주어진 상태에서 수동으로 선택된 video frame에 맞추는 것은 번거로운 작업입니다. 그래서 저자들은 synchronize를 두번째 원칙으로 정했습니다.
Principle 3: Spatial
audio clip을 동적으로 spatial sound로 변환하는 데 도움을 줄 수 있어야 합니다. 자전거 예시를 사용하면, 자전거가 왼쪽에서 오른쪽으로 페달링을 할 때, audio clip은 청자의 왼쪽 귀에서 오른쪽 귀로 점진적으로 움직여야 합니다(i.e., audio panning). 만약 자전거가 멀리서 출발해 가까워지면, audio clip은 점점 커져야 합니다(i.e., audio volume). 하지만 synchronizing과 같이 pan과 volume parameter를 frame 별로 수정하는 것은 매우 번거로운 작업입니다. 그래서 저자들은 spatial을 세번째 원칙으로 정했습니다.
Principle 4: Stack
Soundify는 editor에게 여러 audio track을 stack할 수 있는 기능을 제공해야 합니다. 합창단이 서로 다른 음역대에서 노래하는 여러 명의 가수로 구성되어 더 풍부하고 깊이 있는 소리를 만드는 것처럼, 좋은 soundscape는 여러 audio track의 중첩을 포함합니다. audio stacking은 일반적으로 기본 배경음 layer와 여러 효과음 layer로 구성됩니다. 그래서 저자들은 stack을 네번째 원칙으로 정했습니다.
Implementation
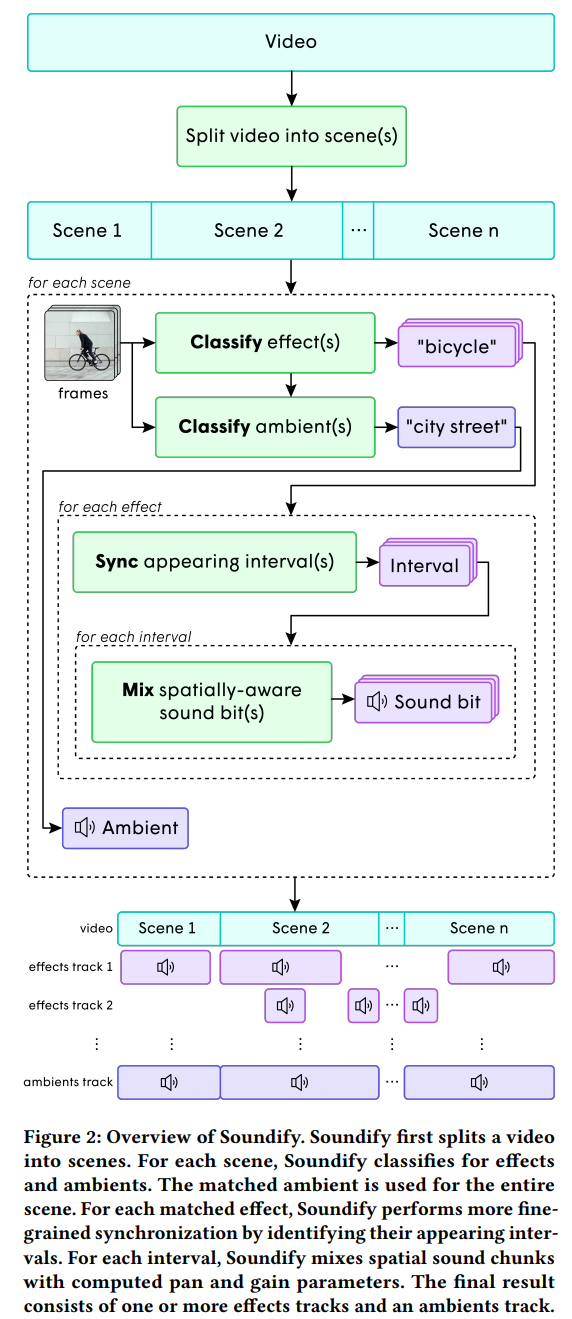
저자들의 system은 위와 같은 구조입니다. 긴 video에서 분류해야 할 audio의 수를 줄이기 위해, 주어진 video를 장면으로 분할합니다. color histogram distance기반 boundary detection algorithm을 사용해 scene을 분할합니다. 이웃한 frame들의 histogram 사이의 거리가 큰 경우 scene의 변화를 나타냅니다. 각 scene의 대해 저자들은 여러 효과음과 배경음을 분류합니다. 분류된 각 효과음에 대해, 저자들은 video에 object가 등장하는 기간에 맞춰 audio clip을 sync합니다. 분류된 배경음은 전체 scene에 사용됩니다. 각 synchronized interval에 대해, 저자들은 video에 등장하는 객체의 위치와 크기에 맞춰 시간에 따라 pan parameter와 volume parameter를 조정합니다. 마지막으로 matched effect와 배경음을 stack하여 최종 결과를 생성합니다.
Classifiy

Soundify의 첫 stage는 classification입니다. 저자들은 video 내 "sound emitter"를 분류하여 sound effect를 video에 matching합니다. sound emitter는 소리를 내는 객체나 환경으로, 'Epidemic Sound'라는 90,000개의 high-quality sound effect로 구성된 dataset의 sound category를 이용하여 정의됩니다. realistic soundscape를 만들기 위해, 저자들은 각 scene을 두 type의 sound로 나눴습니다: effect(e.g., bicycle, camera, keyboard, ... ), ambients(e.g., street, room, cafe, ... ). 주어진 scene에 대해, 저자들은 각 video frame에 CLIP image encoder를 적용하여 구한 encoded frame을 concatenate하여 전체 scene을 표현하는 vector representation을 구합니다. sound dataset에 있는 각 effect label들에 CLIP text encoder를 적용하여 각 label의 vector representation을 구합니다. 그 다음 encoded scene vector와 각 encoded effect label vector 사이 cosine similarity를 비교하여 top-5 matching effect label을 구합니다. 사용자는 이 중에서 1개 이상 추천된 effect를 고를 수 있습니다. 배경음 label도 동일한 과정을 거칩니다. 배경은 시각적으로 focus가 나가있을 가능성이 있기 때문에, 배경음 분류는 error가 발생하기 쉬울 수 있습니다. 그래서 저자들은 예측된 배경음과 이전에 추천된 effect 중 사용자가 선택한 effect를 CLIP text encoder에 다시 입력하여 consine 유사도에 따라 예측된 배경음을 재정렬합니다.
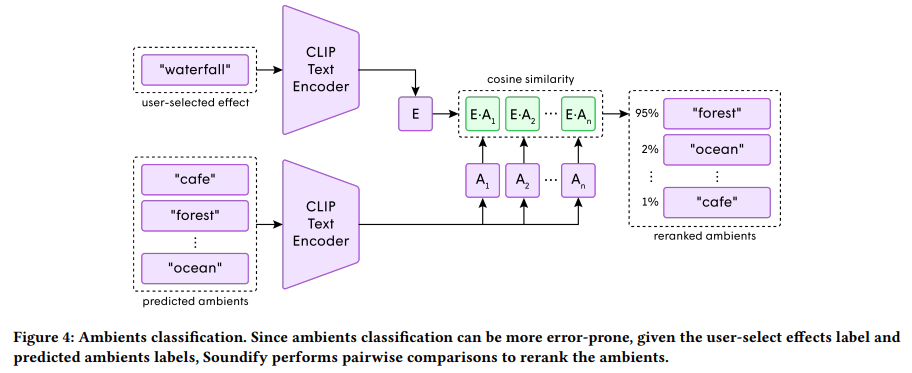
예를 들어 사용자가 waterfall을 effect로 선택했었다면, cafe보단 forest가 더 높게 rank될 것입니다. 이렇게 효과음을 사용하여 배경음을 예측하여 사용자에게 추천합니다.
Sync
sound emitter는 scene의 일부에만 등장할 수도 있습니다. 그래서 저자들은 sound emitter가 등장했을 때에 맞춰 effect를 동기화하길 원합니다.
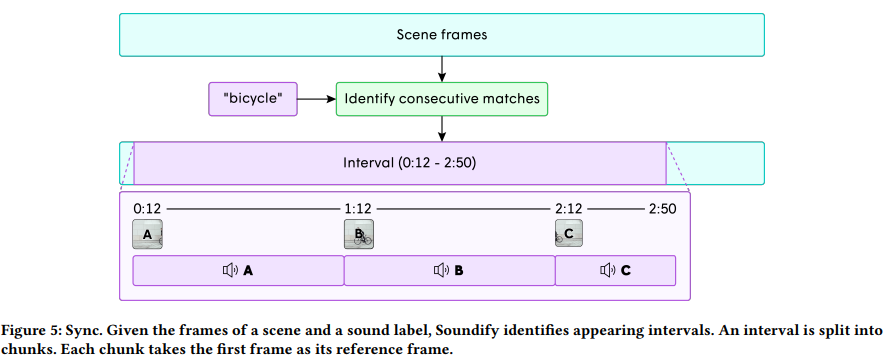
저자들은 scene의 각 frame과 effect label을 비교하여 각 구간을 찾아냅니다. 연속적인 frame sequence가 threshold보다 높은 유사도 score를 갖는다면, 한 구간으로 식별했습니다. sound emitter가 사라졌다가 다시 등장하는 것과 같이 각 장면에는 여러 구간이 있을 수 있습니다.
Mix
video editor들은 scene의 상태에 맞춰 sound를 조절합니다. 예를 들어 자전거가 한쪽에서 다른 쪽으로 페달을 밟을 때, 우리는 stereo panning (i.e., 소리가 왼쪽에서 오른쪽으로 이동)에서 변화를 듣게 됩니다. 비행기가 가까이 날아갈 때 소리의 강도 (i.e., 소리 볼륨 변화)가 커집니다. 비슷하게, effect의 pan과 gain parameter를 시간에 따라 조정합니다.
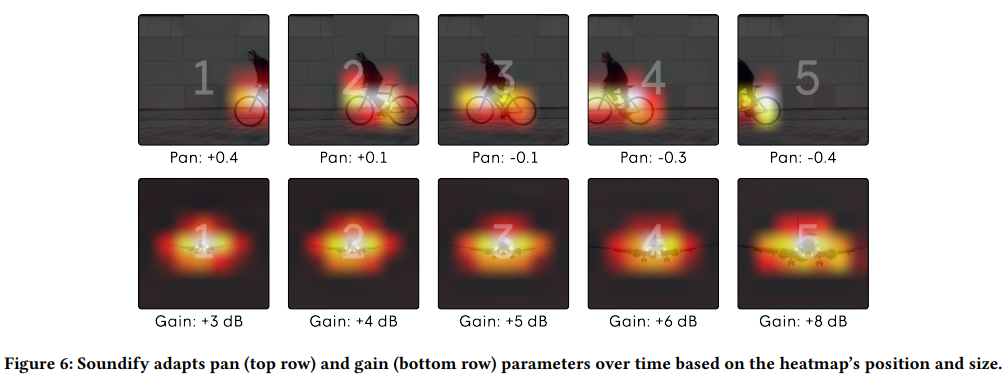
이를 구현하기 위해, 저자들은 효과음 간격을 약 1초 단위로 나누고, 각 1초에 대해 pan과 gain parameter를 조정한 후 crossfade를 사용하여 부드럽게 연결합니다. 저자들은 ResNet-50의 마지막 visual layer (ReLU activation 사용)에서 Grad-CAM을 적용하여 activation map을 생성합니다. 이렇게 sound emitter의 위치를 지정하여 기능을 수행할 수 있게 됩니다. pan parameter는 x 축에 따라 localized sound emitter의 질량의 중심을 통해 계산되고 gain parameter는 normalized area에 의해 구해집니다. 그런 다음 해당 audio file .wav를 찾아낸 후 pan과 gain에 맞춰 remix합니다. screen에 등장하는 sound object의 duration보다 길거나 duration이 동일한 audio clip을 우선적으로 가져옵니다. 배경음의 경우, 각 장면에 대해 일정한 환경을 가정합니다. 그러므로 저자들은 audio file .wav를 찾은 후 전체 scene에 main sound effect보다 크지 않게 조절하여(-5dB) 전체 장면에 사용합니다. 최종적으로 선택된 모든 effect audio track들과 배경음을 stack하여 video에 대한 audio track을 생성합니다.
Interface
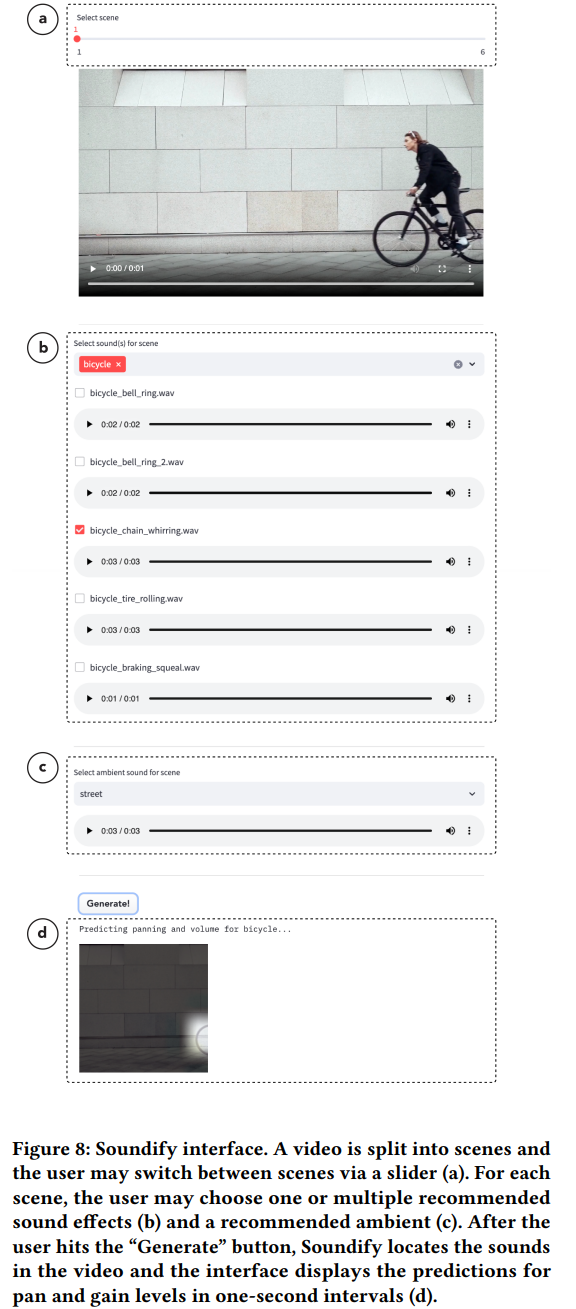
저자들은 system의 예측 결과를 보여주고 sound design decision을 만들 수 있도록 interface를 사용자에게 제공합니다. 위와 같이 제공해줍니다. video를 다양한 scene으로 나누고 사용자가 각 scene의 sound effect와 배경음을 선택할 수 있게 만듭니다. 사용자는 slider를 사용하여 scene을 변경할 수 있습니다. sound effect panel로 가장 점수가 높은 sound effect들을 default로 보여줍니다. 사용자들은 sound effect를 추가하거나 제거하여 여러 sound effect를 stack할 수 있습니다. system이 default로 제안하는 sound effect 이외 effect들도 score 기반으로 정렬되어 보여집니다. 배경음도 점수를 기반으로 정렬되어 보여집니다. 사용자가 "Generate" button을 누르면, 1초 간격으로 heatmap 예측을 시각화합니다. 생성이 완료된 후, 사용자는 video와 audio track을 장면별로 분할하고 번호를 매겨 zip 파일로 내보낼 수 있습니다.
Human Evaluation
Soundify의 sound emitter detecting과 sound matching의 효과를 평가하기 위해, 저자들은 YOLO 기반 baseline method와 비교를 진행했습니다. 저자들은 기존의 sound effect clip을 사용하기 때문에, audio synthesis model과는 비교하지 않습니다.
Setup
- Source Material Collection
저자들은 서로 matching된 audio clip과 videp clip을 모았습니다.
- Audio Clip Collection: 저자들은 audio clip로 ESC-50 datsaet과 UrbanSound8K dataset의 subset의 combination을 사용했습니다. 최종 54개 category고, 각 category별로 40개 audio clip이 존재하며, 총 2160개 audio clip을 사용했습니다.
- Video Clip Collection: Getty Image라는 대규모 professional video footage를 사용하여 video clip을 모았습니다. audio category label을 keyword로 사용하여 Getty Image의 video에 query를 했습니다. 그렇게 각 keywork마다 80개를 얻었고, 수동으로 연관 없는 video들은 제거했습니다. 최종 저자들은 여러 object를 포함하고 있는 다양하고 복잡한 scene을 표현하는 1,105개 video set을 모았습니다.
- Soundify and Baseline Setup
synchronization, pan과 volume을 통해 spatial tuning을 하는 방식으로 audio clip을 video에 맞췄습니다. 두 system을 이용해 진행했습니다.
- Soundify Setup: 위에서 서술한 방식에 맞춰 matching을 수행했습니다.
- Baseline Setup: YOLO기반 baseline system을 사용했습니다. 다양한 category를 가지고 있는 COCO dataset으로 학습된 YOLO model을 사용했습니다. model이 object를 탐지한 후, bounding box의 x-value의 평균을 구해 sound panning을 수행하고, boundary box 영역에 맞춰 sound volume을 조절했습니다.
Procedure
저자들은 mechanical Turk study를 수행하여 Soundify와 baseline system으로 sound match가 수행된 video를 평가했습니다. 각 video에 대해 5가지 문항에 대해서 1점에서 5점으로 평가를 진행했습니다. 문항은 'audio가 video에 등장하는 object의 type과 일치하는가?', 'audio가 video와 시간적으로 잘 맞는가?', 'audio volume이 video와 잘 맞는가?', 'audio panning이 video와 잘 맞는가?', '전반적으로 video와 audio가 잘 맞는가?' 입니다.
Results

실험 결과는 위와 같습니다. activation map을 사용하는 CLIP의 확장이 open-vocabulary object detection을 가능하게 만들어주어, training set 외의 객체도 감지할 수 있고 더 세밀한 audio에 대해 더 큰 유연성을 제공할 수 있습니다. 그리고 CLIP의 heatmap이 YOLO의 bound box보다 객체 크기와 위치를 더 잘 추정할 수 있음을 나타냅니다.



