https://arxiv.org/abs/2309.02405
Generating Realistic Images from In-the-wild Sounds
Representing wild sounds as images is an important but challenging task due to the lack of paired datasets between sound and images and the significant differences in the characteristics of these two modalities. Previous studies have focused on generating
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
image로 wild sound를 나타내는 것은 중요하지만, sound와 image paired dataset이 부족하기 때문에 어려운 task입니다. 그리고 두 modality는 매우 다른 특성을 가지고 있습니다. 이전 연구들은 제한된 category나 음악 sound에서 image를 생성하는 것에 focus를 맞췄습니다. 이 논문에서는 in-the-wild sound로부터 image를 생성하는 새로운 방식을 제안합니다. 먼저, audio captioning을 사용하여 sound를 text로 변환합니다. 그다음 풍부한 sound의 특성을 나타내고 sound를 시각화하기 위해 audio attention과 sentence attention을 제안합니다. 마지막으로 저자들은 CLIP score와 AudioCLIP을 사용하여 sound를 최적화하고 diffusion based model로 image를 생성하는 방법을 제안합니다. 실험을 통해 저자들의 model이 wild sound로부터 high quality image를 생성할 수 있고, baseline model보다 더 뛰어난 성능을 보인다는 것을 보였습니다.
Introduction
소리는 인간에게 시각과 더불어 가장 중요한 감각 중 하나입니다. 주어진 소리로부터 image를 생성하는 것은 여러 application에서 유용하며, 청각 장애인을 돕기 위해 소리를 설명하는 데 도움을 줄 수 있습니다. 하지만 modality의 차이와 sound & image pair dataset의 부족 때문에, wild sound를 image로 변환하는 것은 어려운 task입니다. 이러한 이유로 이전 연구들은 제한된 sound category 내에서 image를 생성했었습니다. 그리고 sound로 생성한 image들의 quality는 text로 생성한 image에 비해서 quality가 떨어집니다.
이러한 문제를 해결하기 위해, 저자들은 pre-trained Audio Captioning Transformer (ACT)와 Stable Diffusion이라 불리는 diffusion based model을 사용하는 새로운 방식을 제안합니다. 개 또는 사람과 같이 제한된 category로 mapping하는 방식으로 sound에서 image를 생성하는 이전 연구들과 다르게, 저자들은 ACT model을 사용하여 sound를 더 자세한 audio caption으로 변환하는 방식을 사용합니다. audio caption에 pre-trained Stable Diffusion model을 적용하여 image를 생성합니다. 이러한 방식은 modality의 차이를 다룰 수 있고, 대규모 sound & image paired training dataset 없이도 high-quality image를 생성할 수 있습니다.
하지만 저자들의 method는 wild sound의 풍부하고 동적인 characteristic을 image로 표현하는 것이기 때문에, audio caption에서 image를 생성하는 것만으로는 충분하지 않습니다. 그래서 저자들은 이러한 문제를 해결하는 새로운 방법을 제안합니다. 먼저 autio attention을 사용하는 것을 제안합니다. audio attention은 ACT model이 audio caption을 생성할 때 사용했던 확률값입니다. sound의 풍부하고 동적인 characteristic을 image로 나타내기 위해 audio attention을 사용합니다. 그다음 생성된 audio caption에서 객체를 강조하기 위해 sentence attention을 제안합니다. sound를 시각화하기 위해, sound의 characteristic 뿐만 아니라 sound에 존재하는 object를 강조하는 것 또한 중요합니다.
또한, sound에 대응하는 image를 최적화하기 위해 direct sound optimization을 제안합니다. CLIP의 text encoder를 사용하여 audio captioin으로부터 latent vector를 생성하고, sound에 최적화된 latent vector를 얻기 위해 해당 vector를 audio attention과 sentence attention의 초기값으로 사용합니다. 그 다음, latent vector를 condition으로 하는 Stable Diffusion으로 image를 생성하며, 이는 AudioCLIP 유사도와 CLIPscore를 통해 최적화됩니다. 이 과정들을 통해, 저자들은 audio와 image 사이의 modality gap을 해결할 수 있었으며, wild sound로부터 사실적이고 동적인 image를 생성할 수 있습니다.
요약하자면, 저자들의 contribution은 다음과 같습니다.
- 대규모 sound-image pair dataset 없이도 audio captioning과 diffusion based text-to-image moadel을 사용하여 high quality image를 생성할 수 있습니다.
- multi-domain과 time-varying dynamic sound의 characteristic을 나타내는 image를 생성하기 위해 audio attention과 sentence attention을 제안합니다. 추가적으로 CLIPscore와 AudioCLIP 유사도를 사용하여 바로 sound optimization을 수행할 수 있는 방법을 제안합니다.
- 실험 결과를 통해, 저자들의 model은 신뢰할 수 있고 high quality의 image를 만들 수 있음을 보여줍니다.
Related work
Sound-guided Image Generation
sound로부터 image를 생성하는 다양한 연구들이 등장했었습니다. 예를 들어 9개 category에 대해 sound로부터 64x64 크기 image를 생성하는 conditional GAN 연구가 있었습니다. SoundNet이라는 sound dataset을 사용하고, internet에서 image를 모아 총 10,701개 sound-image pair training dataset을 만들어서 사용했었습니다. Wav2clip은 audio dimension으로 CLIP을 확장했으며, audio, image, text를 사용하는 contrastive learning을 수행합니다. model은 audio, image, text로부터 audio feature를 표현하고 VQGAN-CLIP의 input으로 사용하여 audio를 시각화한 image를 생성했었습니다. 이 외에도 다양한 연구가 있었습니다.
하지만 이러한 연구들은 생성된 image들은 특정 category에 대한 한계가 있어, wild sound에서 image를 생성하는 한계가 있었습니다. 이러한 문제를 해결하기 위해, 저자들은 audio attention, sentence attention, direct sound optimization을 사용하는 새로운 method를 제안합니다. 저자들이 알기로는 이 method가 wild sound에서 high quality image를 생성하는 첫 diffusion-based model이라고 합니다.
Sound-guided Image Manipulation
CLIP model을 확장하여 sound, text, image information을 mapping하는 연구가 있었습니다. sound feature 기반 latent vector는 StyleGAN2 model에 feed되어 image를 생성하기도 합니다. 이 방식들은 sound의 semantic information을 사용함에도 불구하고, single domain mapping은 wild sound로부터 생성된 image를 조작하는데 어려움을 겪습니다.
Method
다음 그림과 같이 저자들의 model은 two stage로 구성됩니다.
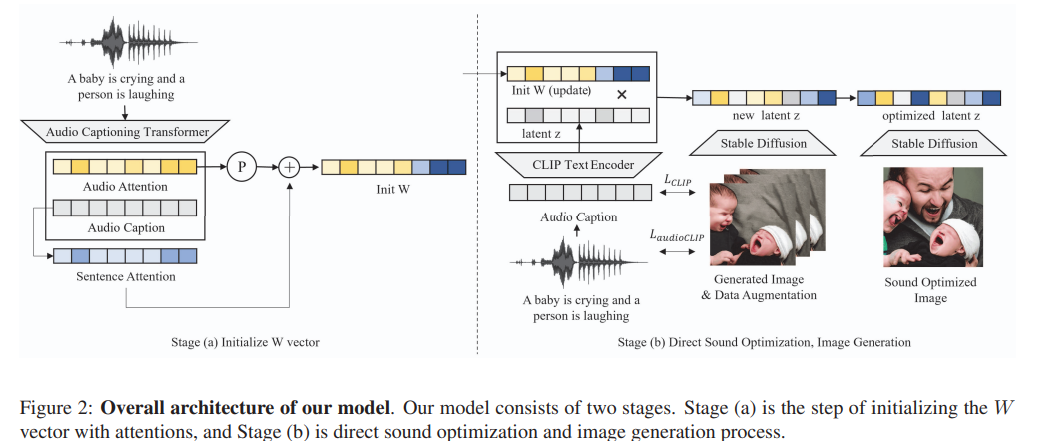
첫 stage는 (a) 부분입니다. Audio Caption Transformer (ACT), audio caption, audio attention, sentence attention을 사용하여 input audio로부터 W_{init}을 초기화합니다. 다음 stage는 (b) 부분입니다. W_{init}과 text latent z를 Stable Diffusion에 feed하여 image를 생성하고 realistic sound characteristic을 위해 W_{init}을 최적화합니다.
Audio Captioning
이전 연구들은 제한된 category로 sound를 mapping함으로써 image를 생성할 수 있었습니다. 하지만, 이러한 방식은 sound의 풍부한 characteristic의 손실을 야기할 수 있습니다. 예를 들어 "a person walking on a beach with waves"를 파도나 사람에 대한 image만 생성하게 됩니다.
이러한 문제를 해결하기 위해, 저자들은 sound를 제한된 category로 mapping하는 대신, single label보다 더 많은 정보를 담고 있을 수 있는 audio caption으로 변환했습니다. 이 논문에서는 pre-trained ACT model을 audio captioning에 사용했으며, ACT model은 vanilla transformer architecture를 사용하고 Audiocaps dataset으로 학습됩니다. encoder의 초기 weight는 pre-trained Deit의 weight로 초기화되고, encoder는 Audioset을 이용한 audio tagging task로 pre-trained 됩니다. sound로부터 audio caption을 생성하여, 저자들은 시각화에 더 많은 정보를 사용할 수 있게 됩니다.
Attentions and Positional Encoding
- Audio Attention
생성된 audio caption은 single label보다 더 많은 정보를 담고 있지만, sound의 intensity나 dynamic characteristic을 표현하기엔 부족합니다. 예를 들어 "크게 웃는 소리"와 "작게 웃는 소리"는 다르고, "멀리서 들리는 천둥"과 "가까이서 들리는 천둥"은 다릅니다. 저자들은 audio attention이라 불리는 sound의 feature를 효율적으로 나타낼 수 있는 새로운 approach를 제안합니다. audio caption을 생성하기 위해 ACT model의 decoder가 사용했던 확률값을 audio attention으로 사용합니다. 이는 각 소리마다 unique하고 audio caption보다 sound를 더 잘 나타냅니다. 예를 들어 천둥소리가 input으로 주어졌을 때, audio caption은 "천둥이 매우 가까이서 치고 있다"라는 output을 생성합니다. 천둥소리가 커질수록 audio attention의 "Thunder"의 value는 점점 커집니다. 이러한 과정을 통해 sound의 풍부하고 다양한 charactersitic을 image로 나타낼 수 있습니다.
- Sentence Attention
sound에서 audio caption을 생성하고 sound characteristic을 image로 표현하기 위해 audio attention을 사용합니다. 하지만 sound를 시각화하기 위해, sound의 characteristic을 표현할 뿐만 아니라 sound의 object를 강조하는 것은 중요합니다. 예를 들어 사람이 크게 웃는 소리가 input sound로 주어졌을 때, audio attention은 사람 보단 웃는 소리에 focus하게 됩니다. 하지만 결국 image로 "사람"이라는 객체를 나타내고 싶기 때문에, 추가적인 방법이 필요합니다. 그래서 저자들은 audio caption에서 명사를 강조하는 sentence attention을 제안합니다. sentence attention은 문장에 있는 단어가 명사일 확률을 나타내줍니다. 이 논문에서 FLAIR model을 사용하여 audio caption에 존재하는 각 단어가 명사일 확률을 구합니다. sentence attention을 사용함으로써, 저자들은 sound에 있는 object를 강조할 수 있게 되며, 이는 sound를 시각화하는 것을 더 용이하게 만들어줍니다.
- Positional Encoding
저자들은 positional encoding을 사용하여 text embedding space에서 attention을 최적화하는 것이 이점이 있다는 것을 경험적으로 발견했습니다. audio attention의 positional encoding P는 다음과 같이 계산됩니다.
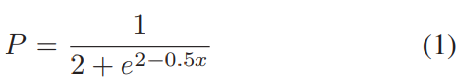
Initializing W_init vector
audio attention, sentence attention, positional encoding을 가지고 W_init vector를 만듭니다. 먼저, audio attention에 positional encoding을 수행합니다. 그 다음 sentence attention과 audio attention을 더합니다. 이 과정에서 object를 강조하기 위해, 저자들은 audio attention의 명사에 weight λ_a를 곱하여 sentence attention의 상대적인 weight를 증가시킵니다. 마지막으로, audio caption을 tokenzing한 다음 W_init을 audio caption token으로 reshape합니다.

식으로 나타내면 위와 같습니다. t는 audio caption을 나타내고 S는 audio caption t에서 sentence attention을 추출하는 function을 의미합니다. P는 positional encoding function, a는 input audio, A는 audio a로부터 audio attention을 추출하는 funciton, W_n은 noun에 대한 weight, W_wn은 non-noun에 대한 weight입니다. W_init vector를 사용하여 sound의 dynamic characteristic을 나타내는 realistic image를 생성합니다.
Image Generation
embedding을 input으로 받는 image generation model G가 있다고 하겠습니다. 저자들은 Stable Diffusion을 G로 사용했습니다. pre-trained model을 사용했습니다. CLIP text encoder를 사용하여 text embedding space에서 audio caption을 latent vector z로 encode합니다. W_{init} vector를 initialize한 다음, latent vector z와 곱하여 새로운 latent vector z_n을 구합니다. model은 z_n을 input으로 하여 image I_{init}을 생성합니다. 식은 다음과 같습니다.
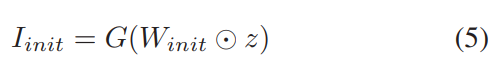
Direct Sound Optimization
new latent z_n을 Stable Diffusion의 input으로 사용하여 image를 생성합니다. Style-CLIP에서 영감을 받아 image & audio caption 사이 CLIPscore와 audio & image 사이의 AudioCLIP similarity를 사용하여 sound를 직접 최적화합니다. 식으로 나타내면 다음과 같습니다.
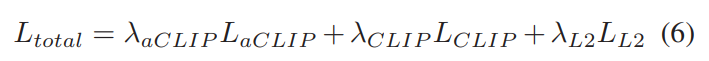
L_{aCLIP}은 input audio a와 생성된 image I 사이의 similarity를 나타냅니다. L_{CLIP}은 생성된 image I와 audio caption t 사이의 similarity를 나타냅니다. 이 두 loss를 maximize하는 방식으로 학습합니다. L_{L_2}는 audio caption t에 의해 생성된 latent vector z와 new latent vector z_n 사이의 L2 norm을 의미합니다. 추가적으로 new latent vector z_n과 VQGAN-CLIP을 이용해 생성한 image를 augmentation method로 augment했습니다. image를 만들 때 audio의 명사 부분에 focusing 하기 위해, W_{init}을 명사 W_n와 비명사 W_wn으로 나눕니다. sound optimization step에서, W_n은 local minimization 문제 때문에 높은 learning rate를 사용하여 최적화됩니다. 이를 통해 audio caption과 audio로부터 더 자연스러운 결과를 만들어 낼 수 있었습니다.
Experiments
Datasets
저자들은 wild sound로부터 image를 생성하는 성능을 효율적으로 평가하기 위해, 저자들은 audio captioning dataset을 사용했습니다.
- Audiocaps
sound in the wild & text paired dataset입니다. dataset은 human annotated caption과 various multi-domain sound로 구성됩니다. 총 957개 audio file로 구성된 test set을 이용해 평가를 진행했습니다.
- Clotho
15초에서 30초 사이 duration을 가진 4981개 wild audio files로 구성된 audio captioning dataset입니다. caption은 24905개 있습니다. 저자들은 1045개 audio로 구성된 test set으로 평가를 진행했습니다.

저자들의 실험 예시는 위와 같습니다.
Conclusion and Limitation
저자들은 audio captioning과 diffusion based text guided image generation model을 사용하여 wild sound으로부터 high quality image를 생성하는 새로운 approach를 제안했습니다. audio attention과 sentence attention을 이용해 sound의 dynamic property를 나타낼 수 있었고, CLIPscore와 AudioCLIP similarity를 사용하여 생성된 image를 optimize했습니다. 결과적으로 저자들의 model은 wild sound로부터 high quality image를 성공적으로 생성할 수 있었으며, baseline보다 뛰어난 성능을 보였습니다. 그럼에도 불구하고, model은 audio caption과 text-guided image generation model에 의존하다 보니, 실패하는 모습을 보이기도 합니다.
'연구실 공부' 카테고리의 다른 글
| [논문] AudioCLIP: Extending CLIP to Image, Text and Audio (0) | 2024.06.23 |
|---|---|
| [논문] AudioLDM: Text-to-Audio Generation with Latent Diffusion Models (0) | 2024.06.22 |
| [논문] What Do I Hear? Generating Sounds for Visual with ChatGPT (0) | 2024.06.19 |
| [논문] VoiceLDM: Text-to-Speech with Environmental Context (0) | 2024.06.19 |
| [논문] Environment Aware Text-to-Speech Synthesis (0) | 2024.06.18 |



