https://arxiv.org/abs/2110.03887
Environment Aware Text-to-Speech Synthesis
This study aims at designing an environment-aware text-to-speech (TTS) system that can generate speech to suit specific acoustic environments. It is also motivated by the desire to leverage massive data of speech audio from heterogeneous sources in TTS sys
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 연구는 acoustic environment에 맞는 speech를 생성할 수 있는 environment-aware TTS를 design 하는 것을 목표로 합니다. speech audio에 있는 acoustic environment를 data variability의 factor로 modelling하는 것과 speech synthesis 기반 neural network process의 condition으로 이를 사용하는 것이 key idea입니다. 두 embedding extractor는 speech에서 speaker의 characterization과 environment factor를 분리하기 위해 구성된 dataset을 가지고 학습됩니다. neural network model은 추출된 speaker, environment embedding을 가지고 speech를 생성합니다.
Introduction
이 연구에서는 다양한 환경에서 얻은 data를 활용하여 system을 개발하고 TTS system의 사용 범위를 넓히는 방법을 제안합니다. speech recording의 acoustinc environment를 data variability factor로 modelling하고 condition으로 사용하는 speech generation process를 개발하는 것이 main idea입니다. 구체적으로 저자들은 room reverberation만 environment로 정의하며, noise와 같은 environment는 다루지 않았습니다.
실제로는 특정 화자로부터 녹음된 speech data는 주로 제한된 범위의 환경에서 녹음되며, speaker factor와 environment factor는 매우 높은 상관관계를 가집니다. 극단적인 경우, 각 speaker로부터 얻은 speech들은 단일 environment와 연관이 있을 수도 있습니다. 이러한 문제를 해결하기 위해, 저자들은 speech의 speaker factor와 environment factor를 분리하는 방법을 제안합니다.
speech audio에서 환경과 관련 있는 factor를 modelling하는 것에 대한 이전 연구들이 있습니다. speaker와 noise를 분리하는 것은 data augmentation과 facorization을 통해 수행되었습니다. 또 다른 연구에서는 domain adversarial training을 사용하기도 했습니다. 두 연구 모두 noisy speech data만 사용 가능한 환경에서, data를 잘 활용해 clean speech를 생성하는 것이 목표입니다. 또 다른 연구들은 speech에서 reverberation을 줄이는 것이 목표였습니다. reverberation environment에서 얻은 signal을 clean environment에서 얻은 것으로 conversion하는 task로 볼 수도 있습니다. 이러한 conversion 과정은 일반적으로 waveform-to-waveform 상황으로 수행됩니다. 저자들이 제안하는 방식은 acoustic environment가 neural TTS의 variation의 factor로 여겨집니다.
저자들은 clean and reverberant speech data 모두 사용하는 TTS model을 design합니다. model은 지정된 acoustic environment에서 target speaker의 speech를 합성하도록 학습됩니다. 특별히 design된 dataset으로 학습된 두 extractor module은 speaker embedding과 environment embedding을 추출하는 데 사용됩니다. TTS module은 두 embedding을 condition으로 하여 speech를 생성합니다. reference utterance에서 얻어진 speaker information과 environment information을 활용하면, 합성된 specch는 요구되는 speaker characteristic과 environment attribute 모두 가지도록 만들 수 있습니다.
The proposed system

저자들이 제안한 system은 위 그림과 같습니다. system은 speaker embedding extractor, environment embedding extractor, TTS module로 구성됩니다.
Speaker embedding extractor
speaker embedding extractor는 speaker verification (SV) system을 기반으로 개발되었습니다. SV system은 generalized end-to-end loss를 통해 학습됩니다. loss는 동일한 speaker로부터 녹음된 utterance로부터 추출되는 embedding들은 서로 가깝게, 다른 speaker로부터 얻어지는 embedding들은 서로 거리가 멀게 만들어줍니다.
각 training batch에서, s명 speaker들은 선택되고 각 speaker마다 u개의 utterance를 선택합니다. 각 utterance는 원본 utterance에서 random하게 선택된 location에서 80-frame length의 speech segment를 구해 extractor의 input으로 사용됩니다. extractor model은 LSTM layer와 linear layer로 구성됩니다. extractor의 output은 L2-normalized 된 후 speaker embedding이 됩니다. E_s^(i, j)가 i번째 speaker의 j번째 utterance로부터 얻어진 speaker embedding이라고 하겠습니다. speaker i의 경우, speaker embedding의 centroid는 두 가지 방식으로 계산될 수 있습니다. 1) speaker i의 모든 utterance를 통해 구해지거나, 2) j번째 utterance를 제외한 utterance들로 구하는 방법입니다. speaker embedding은 similarity matrix을 구성하기 위해 모든 speaker의 centroid와 비교됩니다. centroid, similarity matrix, loss function은 다음과 같이 표현할 수 있습니다.

w와 b는 학습 안정성을 위한 parameter입니다. speaker embedding extractor는 L(E_s)를 minimize하도록 학습됩니다.
Voxceleb1 dataset을 이용하여 speaker embedding extractor를 학습했습니다. 이 dataset은 1251명 speaker로 구성됩니다. 이 datset은 다른 acoustic environment에서 동일한 speaker가 녹음한 speech data로 구성되어 있기 때문에, speaker-dependent factor를 modling하는 목적에 알맞은 dataset입니다.
Environment Embedding Extractor
environment embedding extractor는 speech utterance로부터 environment embedding을 얻습니다. environment-specific information은 측정된 room impulse respone (RIR)로 표현될 수 있습니다 (이 연구에서는 environment로 reverberation만 고려하니까). extractor module을 학습하기 위해, 저자들은 각 environment type이 여러 speaker와 연관 있는 speech dataset을 필요로 했습니다 (즉 여러 speaker가 동일한 environment에서 speech를 녹음한 dataset). 저자들은 247명 speaker로부터 clean speech utterance (LibriTTS dataset의 subset인 "train-clean-100"에서 얻음)를 얻어서 사용했습니다. BUT ReverbDB dataset에서 측정된 2325가지 RIR를 사용하여 다양한 environment를 표현했습니다. 각 environment condition 마다 여러 speaker로부터 얻어지는 clean speech를 convolving하여 reverberant speech가 생성했습니다. environment embedding extractor는 speaker embedding extractor와 유사한 방식으로 학습되었으며, 즉 동일한 environment에서 얻어진 embedding은 가깝게, 서로 다른 environment에서 얻어진 embedding은 서로 멀게 만들도록 학습되었습니다. 각 training batch마다 저자들은 e개 environment를 선택하고 각 environment마다 u개 utterance를 선택했습니다. 각 utterance-level environment embedding E_e^(i, j)는 모든 environment의 centroid와 비교되며, similarity matrix, softmax loss는 다음과 같이 정의될 수 있습니다.

environment embedding extractor는 L(E_e) loss를 minimize 하도록 학습됩니다.
TTS module
TTS module은 Tacotron2와 DurIAN architecture의 combination으로 design 되었습니다. 대신 저자들의 method는 look-up table을 embedding extractor module로 대체했습니다. TTS module은 encoder, duration predictor, length regulator, Prenet, decoder로 구성됩니다. duration predictor는 input text로부터 phone-level duration을 결정하는 데 사용됩니다. input text와 phone-level duration은 encoder와 length regulator에 의해 처리됩니다. speaker embedding과 environment embedding은 위에서 언급한 것처럼 두 embedding extractor를 통해 생성됩니다. 두 embedding들은 broadcast 되고 encoder의 output과 concatenate 되어 decoder의 input으로 사용됩니다. Prenet과 decoder는 output speech의 mel-spectrogram을 생성하며, 이 mel-spectrogram은 HiFi-GAN vocoder를 이용해 다시 speech waveform으로 변환됩니다. 생성된 spectrogram과 ground-truth 사이의 L2-norm loss를 minimize하는 방식으로 TTS module은 학습됩니다.
전체 system의 loss는 다음과 같이 정의됩니다.

Experimental setup
Speech dataset
TTS module은 특별히 구성된 dataset으로 학습됩니다. 이 dataset은 speaker factor와 environment factor가 완전히 entangle 한 상태입니다. 각 speaker가 특정 environment와 연관되어 있습니다. 여러 speaker로 구성된 clean speech data는 VCTK dataset으로 구성되었습니다. 측정된 RIRs는 환경의 차이를 나타내며, 이 RIRs는 REVERB challenge database, Aachen impulse response database로부터 얻었습니다. 108명 speaker와 108개 environment가 random하게 선택되어 108개의 unique pair를 만들었고, 각 pair마다 100개 utterance를 생성했습니다. clean도 environment 중 하나이며, clean dataset은 TTS system을 학습할 때 바로 사용되었습니다. 각 environment에 대응하는 speaker들의 clean speech utterance는 주어진 RIR과 convolve 되어 training speech를 생성합니다. speaker-environment pair의 95%를 선택하고 그 pair에서 95%의 utterance를 선택하여 training dataset으로 사용했습니다. TTS module을 학습할 때 사용된 training dataset은 두 embedding extractor를 학습할 때 사용된 data와 overlap 되면 안 됩니다(speaker identity와 environment type만 일치하지 않으면 괜찮음).
System configuration
audio data의 sampling rate는 22,050Hz입니다. mel-spectrogram을 구하고, 이 mel-spectrogram은 speaker embedding extractor, environment embedding extractor, TTS module을 학습할 때 사용됩니다.
speaker or environment embedding extractor를 학습하는 경우, 각 batch는 64명 speaker 또는 environment를 포함하며, 각 speaker마다 10개의 utterance를 sample 하여 사용했다고 합니다. 각 utterance들은 80-frame length의 mel-spectrogram으로 crop 되어 학습할 때 사용됩니다. 그래서 각 batch마다 640 mel-spectrogram이 존재합니다. 각 embedding extractor는 256차원 unidirectional LSTM layer 3개와 1개 linear layer로 구성됩니다. speaker (or environment) embedding은 256차원 vector입니다.
Baseline system
baseline system은 speaker embedding extractor, environment embedding extractor, TTS smodule로 구성됩니다. 이 module들은 저자들의 dataset으로 동시에 학습됩니다. baseline system의 loss는 3개 part로 구성됩니다: speaker embedding vector를 학습할 때 사용되는 speaker classification loss, environment embedding extractor를 학습할 때 사용되는 environment classification loss, TTS module을 학습할 때 사용되는 speech reconstruction loss입니다. hyperparameter values는 저자들의 method와 동일하게 설정했습니다. baseline system에서는 speaker and environment embedding extractor가 저자들의 방식과 다르게 학습됩니다. 전체 baseline system의 loss는 다음과 같습니다.
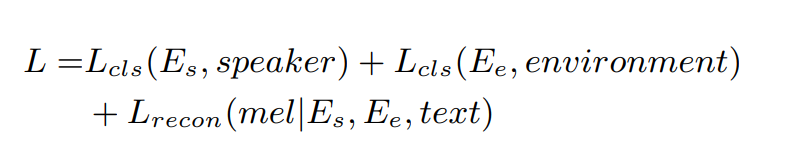
Results and discussion
Visualization of extracted embeddings
speaker embedding과 environment embedding이 speech의 대응하는 factor를 model 하거나 control 할 수 있는지 아닌지 확인하기 위해, 저자들은 서로 다른 utterance에서 추출한 speaker embedding와 environment embedding을 condition으로 하여 utterance를 합성했습니다. 그다음 speaker embedding extractor와 environment embedding extractor를 이용해 embedding을 추출했습니다. 그 다음 T-SNE visualization을 사용했습니다 결과는 다음과 같습니다.
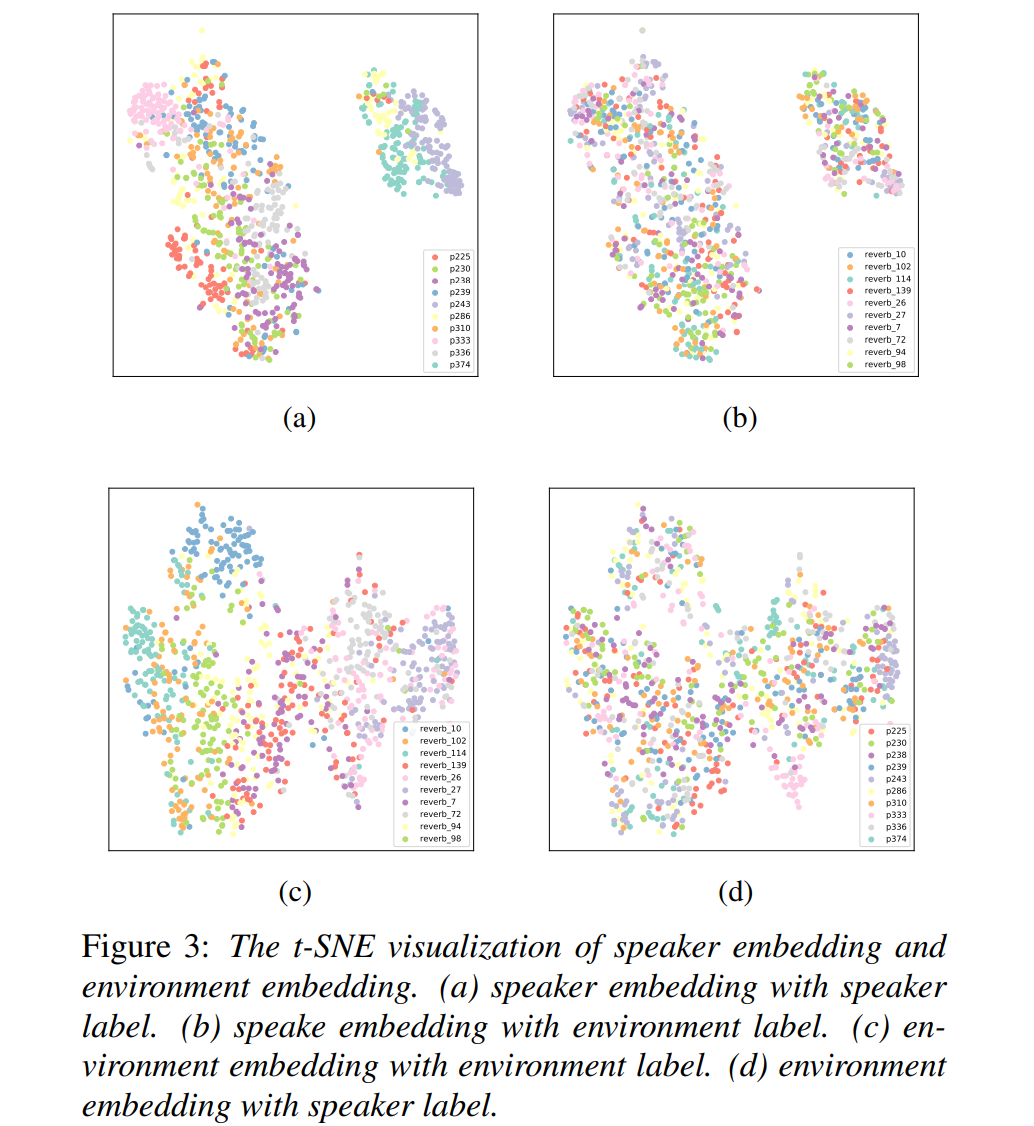
(a)와 (b)는 동일한 speaker들이 같은 cluster를 이루는 경향을 볼 수 있으며, 동일한 환경에 관한 speaker embedding들은 서로 섞여있는 것을 볼 수 있습니다. 즉 추출된 speaker embedding은 speaker-related information을 capture 하면서 environment-related information은 capture 하지 않는다는 것을 의미합니다. (c)와 (d)를 통해 추출된 environment embedding은 environment-related information을 capture하지만 speaker-related information은 capture하지 않는다는 것을 볼 수 있습니다.
Objective evaluation
- Mel-cepstrum distortion
합성된 speech utterance의 객관적인 평가를 위해 mel-cepstral distortion (MCD)를 수행했습니다. 저자들은 3가지 case에 대해 실험을 진행했습니다. 모든 경우에서, ground-truth speech는 clean speech를 그에 대응하는 RIR로 convolve 해서 얻어집니다. 3가지 case는 다음과 같습니다.
- training dataset에 있는 (seen combinations) speaker-environment combination으로 생성된 speech에 대한 case입니다. 이 MCD results는 speech generation의 일반적인 performance를 보여줄 수 있습니다.
- training dataset에 없는 새로운 speaker-environment combination으로 생성된 speech에 대한 case 입니다. 각 speaker identity와 environment type은 training dataset에 존재하긴 하지만, combination이 존재하지는 않습니다. MCD result는 speaker factor와 environment factor의 분리에 대한 평가를 반영할 수 있습니다.
- speaker와 environment 모두 system을 학습할 때 포함되지 않았던 case입니다. MCD는 system의 일반화 성능을 보여줄 수 있습니다.
결과는 아래와 같습니다.
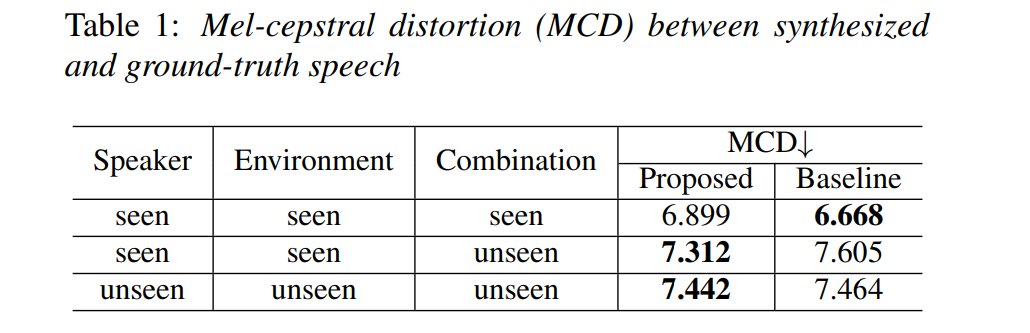
저자들의 method가 seen speaker-environment combination에서 baseline보다 좋지 않은 결과를 보입니다. 하지만 unseen speaker-environment combination의 경우, 저자들의 system이 baseline보다 더 좋은 MCD 결과를 보여주며, 이를 통해 speaker factor와 environment factor를 분리할 수 있고 독립적으로 modelling 한다는 것을 볼 수 있습니다.
Conclusion
이 논문에서 저자들은 environment-aware TTS system을 제안합니다. 이는 design 된 speaker timbre와 environment attribute를 반영하는 speech를 생성할 수 있습니다. speech에서 speaker factor와 environment factor를 characterization 하고 분리하는 방식으로 system을 design 했습니다. 객관적인 평가와 주관적인 평가 모두에서, 저자들의 method가 speaker와 environment 모두 modelling 할 수 있다는 것을 보여줬을 뿐만 아니라, baseline system보다 더 나은 성능을 보였습니다.



