https://arxiv.org/abs/2404.18398
MM-TTS: A Unified Framework for Multimodal, Prompt-Induced Emotional Text-to-Speech Synthesis
Emotional Text-to-Speech (E-TTS) synthesis has gained significant attention in recent years due to its potential to enhance human-computer interaction. However, current E-TTS approaches often struggle to capture the complexity of human emotions, primarily
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
최근 몇 년 동안 emotional TTS synthesis는 human computer interaction의 향상을 위해 큰 주목을 받았습니다. 하지만 최근 E-TTS 방식은 과하게 단순한 emotional label을 사용하거나 single modality input을 사용하는 방식이며, 인간 감정의 복잡성을 capture하는데 어려움을 겪고 있습니다. 이러한 한계를 해결하기 위해, 저자들은 Multimodal Emotional TTS system (MM-TTS)라는 표현력이 좋고 감정적으로 공감되는 음성을 생성하기 위해 여러 modality에서 감정적 단서를 얻어 사용하는 unified framework를 제안합니다. MM-TTS는 두 가지 key component로 구성됩니다. 1) emotional feature를 text, audio, visual modality와 align하는 contrastive learning을 수행하는 Emotion Prompt Alignment Module (EP-Align), 2) aligned emotional embedding와 최신 TTS model을 사용하여 의도된 감정을 정확하게 반영하는 speech를 합성하는 Emotion Embedding-Induced TTS (EMI-TTS)입니다.
다양한 dataset으로 평가를 진행했을 때, traditional E-TTS model보다 MM-TTS는 뛰어난 성능을 보였습니다.
Introduction
자연스럽고 고품질의 speech를 합성하는 TTS 기술들이 상당히 발전했음에도 불구하고, 주된 focus는 감정적 뉘앙스를 capture하는 것이 아니라 언어적 정확도에 있습니다. 현대 E-TTS 방식은 emotion label이나 emotional reference speech를 사용하여 차이를 줄이기 위해 노력했지만, 이러한 방법들은 단순화된 표현이나 single modality input에 의존하여 인간 감정의 복잡성을 완전히 포착하는 데 어려움을 겪습니다. E-TTS의 잠재력을 진정으로 발휘하고 감정적으로 공감되는 speech를 합성하기 위해, multiple modality의 풍부한 emotional information을 사용하는 포괄적인 접근 방식이 필요합니다.
얼굴 표현, silent video clip, reference audio sample과 같은 시각적 단서를 사용할 수 있는 상태에서 감정적으로 일관된 음성을 생성하려는 voiceover scenario에 대해 생각해 보겠습니다.

단일 modality information을 사용하는 기존 E-TTS는 한계가 존재합니다. 얼굴 표현은 dynamic하며, context에 맞춰 다르게 해석될 수 있습니다. reference emotional audio만 사용하는 것은 scenario의 감정적 뉘앙스를 capture하기 어려울 수 있습니다. 그리고 실제 application에서는 다양한 modality의 이용 가능성은 다를 수 있습니다. multimodal cue를 사용하는 것은 감정적 state에 대해 더 포괄적인 이해를 할 수 있게 도와주며, 이를 통해 특정 맥락에 맞게 더 정교하고 미묘한 감정 표현을 가진 음성을 생성할 수 있습니다. 이렇게 multimodal을 통합하는 것은 더 유연한 emotional speech synthesis 방식이 가능하게 만들어줍니다.
그래서 저자들은 text, audio 및 visual information을 포함하는 multimodal cue를 통합하여 합성된 음성의 표현력을 향상시키는 Multimodal Emotional Text-to-Speech System (MM-TTS) framework를 제안합니다. MM-TTS는 emotion Prompt Alignment Module (EP-Align)과 Emotion Embedding-Induced TTS (EMI-TTS)로 구성됩니다. EP-Align은 cue anchoring mechanism을 통해 modality 전반의 emotional data를 align하여 multimodal information을 원활하게 융합할 수 있게 합니다. EMI-TTS는 이 aligned emotional embedding을 사용하여 다양한 application에 적합한 표현력 있고 감정적으로 공감되는 음성을 합성합니다. EP-Align과 EMI-TTS를 통합하는 것은 MM-TTS가 감정적인 speech를 합성할 수 있게 만들어 줍니다. 저자들의 key contribution은 다음과 같이 요약됩니다.
- Emotion Prompt Alignment Module (EP-Align)이라는 modality에 걸쳐 emotional feature를 synchronize하는 새로운 contrastive learning approach를 제안합니다. multimodal content에서 emotional feature를 효과적으로 align하고 complex noise를 filtering out 함으로써 EP-Align은 분포 불일치 문제를 해결하고, 이를 통해 high-quality emotional speech를 생성할 수 있습니다.
- EP-Align을 기반으로 저자들은 의도된 감정을 반영하는 speech를 합성하기 위해 aligned emotional embedding을 사용하는 Emotion Embedding Induced TTS (EMI-TTS) framework를 개발했습니다. 이러한 embedding들을 통합하는 것은 생성된 audio의 자연스러움과 신뢰성을 향상시켜 더욱 몰입감 있고 매력적인 사용자 경험을 제공합니다.
- 저자들은 MM-TTS의 적응성과 우수한 처리 능력을 검증하기 위해 다양한 emotional category와 scenario에 걸쳐 여러 실험을 수행했습니다. 실험 결과를 통해 MM-TTS가 개인의 speaker characteristic을 유지한 채로 감정적 일관성을 유지하는 것을 확인할 수 있었습니다.
Related Work
Emotional Text-to-Speech Synthesis
Emotional TTS는 감정적으로 표현력을 가진 음성을 합성하는 것에 focus를 맞춥니다. 연구자들은 감정을 TTS system에 통합하는 방법을 개발해 왔습니다. 1) emotion label을 추가적인 conditioning data로 TTS model에 적용합니다. 예를 들어 EmoSpeech는 FastSpeech2 framework에 Conditional Layer Normalization을 통해 speaker label과 emotion label을 추가했습니다. 비슷하게 Tacotron-based model에 emotion label을 hidden feature로 embed 한 다음 condition으로 사용하기도 합니다. EmoDiff는 감정에 대한 one-hot vector 대신 soft label을 사용하는 diffusion model입니다. 2) 요구되는 emotional state를 capture하기 위해 referenced speech를 사용하기도 합니다. dual emotion classifier와 style loss를 사용하여 생성된 speech의 emotional content와 reference mel-spectrum을 align합니다. 추가적으로 reference speech로부터 얻은 emotional style을 합성된 speech로 transfer하는 기술에 대한 연구들도 등장했습니다. 3) 또 다른 연구들은 감정의 textual description을 conditioning data로 사용하기도 합니다. target 감정에 대한 textual description이 speech 합성의 guidance가 되는 방식입니다.
이러한 발전에도 불구하고, 이전 ETTS 방식들은 single modality나 감정 표현의 단순화와 같은 한계에 직면합니다.
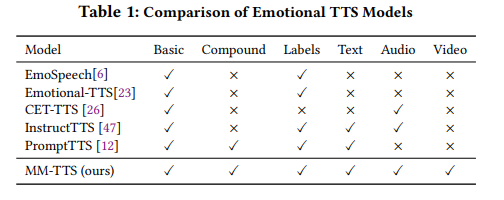
위 표는 존재하는 model들의 차이를 보여줍니다. 이러한 한계들을 해결하기 위해, 저자들은 다양한 emotion 관련 data를 통합하기 위해 multimodal represntation learning을 사용하여 감정적으로 풍부한 speech를 합성할 수 있는 MM-TTS를 제안합니다.
Multi-modal Representation Learning
현대 연구에서 중심 area 중 하나인 multi-modal representation learning은 text, image, video, audio와 같은 다양한 modality를 효과적으로 통합하는 shared latent space를 찾는 것을 목표로 합니다. 이러한 multimodal의 통합은 감정적 content를 더 깊게 이해할 수 있는데 도움을 줍니다. Multi-modal encoder는 각 modality에서 문맥적으로 관련된 feature들을 추출하고 unique한 characteristic을 capture합니다. 이러한 feature들은 supervised or unsupervised method를 이용하 align되고 cross-modal task를 돕는 connection을 만듭니다.
특히 중요한 발전으로는 image와 text의 joint embedding을 설정하는 Contrastive Language-Image Pretraining (CLIP) model, audio까지 확장된 AudioCLIP model이 있습니다. 또한 audio와 visual data를 결합하여 소리 위치 추적 및 audio-visual event detection과 같은 application을 가능하게 하는 방법들이 연구되었습니다. 저자들의 framework인 MM-TTS는 합성된 speech의 감정적 표현력을 향상시키기 위해 multi-modal representation learning을 사용하였습니다. contrastive learning을 통해 text, iamge, video, audio에서 emotion tag으로 feature representation을 추출하고 align하여 MM-TTS가 포괄적인 감정 관련 정보를 capture 하도록 만들었습니다. 이러한 풍부한 이해는 MM-TTS가 emotional cue를 align하도록 만들고 감정적으로 풍부하고 뉘앙스가 담긴 speech를 합성하도록 만들어줍니다.
MM-TTS Framework
MM-TTS의 primary goal은 다양한 modality에서 추출한 emotion을 이용하여 각 speaker에 맞는 emotional speech를 생성하는 것입니다.

framework는 위와 같습니다. EP-Align과 EMI-TTS로 구성됩니다.
- Emotion Prompt Alignment Module (EP-Align)은 visual data, audio segment, texture description과 같은 다양한 modality에서 얻어지는 emotional representation을 align하는 데 주요한 역할을 합니다. multimodal emotional data tuple Tup^emo = <v, a, s, p>를 input으로 하며, 여기서 v는 visual data (image or video)를 나타내고, a는 audio segment입니다. 그리고 s는 emotional text description을 나타내며, p는 emotional prompt label을 나타냅니다. EP-Align은 multimodal encoders ε = {ε^vis, ε^audio, ε^tex, ε^prop}을 이용해 이러한 input에서 emotion feature를 추출하고 통합된 emotion embedding을 생성합니다. 이 emotion embedding은 EMI-TTS로 pass됩니다.
- Emotion Embedding-induced TTS(EMI-TTS)는 aligned emotion embedding과 함께 input text Tex, model library M으로부터 pre-trained TTS model을 input으로 받아서 emotion speech를 생성합니다. emotion embedding은 필수적인 emotional context를 제공해지만, input text와 TTS model은 생성된 speech의 전체 style과 content를 결정해 줍니다.
MM-TTS Φ을 이용하여 emotional audio를 생성하는 과정을 식으로 나타내면 다음과 같습니다.
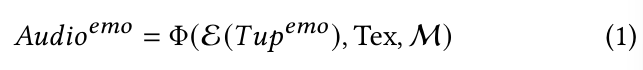
MM-TTS framework는 여러 modality에서 제공해 주는 보완적인 information을 활용하여 emotional speech를 생성할 때 생기는 어려움을 해결하는 것을 목표로 합니다. 다양한 source에서 얻어지는 emotional representation을 align하고 aligned emotional representation을 TTS process에 적용하여, MM-TTS는 speaker의 characteristic은 유지한 채로 원하는 감정을 가지고 있는 speech를 정확하게 합성할 수 있게 됩니다.
Emotion Prompt Alignment Module
Contrastive Language-Image Pre-training(CLIP)에서 영감을 받아, EP-Align은 다양한 modality에서 emotion feature를 추출하기 위해 multi-modal encoder set을 사용합니다. ε = {ε^vis, ε^audio, ε^tex, ε^prop}으로 encoder를 나타낼 수 있으며, 각각은 vision, audio, text, emotion prompt encoder입니다. 추출된 feature는 단일 emotion embedding space로 align됩니다.
- Multimodal Encoders
각 modality는 관련된 emotion feature를 추출하기 위해 encoder를 사용합니다. multimodal emotional data tuple Tup^emo = <v, a, s, p>가 주어졌을 때, encoder는 feature representation을 다음과 같이 생성합니다.

위 식에서 f^vis는 visual feature representation을 나타내고, f^audio는 audio feature representation, f^tex는 textual feature representation, f^prop는 emotional prompt feature representation을 나타냅니다. 각 feature representation은 K 차원이며, 저자들은 K = 512으로 설정했습니다.
text encoder, prompt encoder, visual encoder는 CLIP과 비슷한 구조입니다. audio encoder는 효율적인 audio encoding을 위해 wav2vec 2.0을 사용했습니다. training 과정에서 text encoder와 image encoder는 pre-trained CLIP weight를 가지고 초기화되었으며, audio encoder는 pre-trained model을 사용했습니다. video input을 다루기 위해, 저자들은 visual encoder가 frame sequence를 처리하도록 만들었습니다. feature bank를 추출한 다음 final representation을 얻기 위해 temporal dimension에 맞춰 average pooling을 수행했습니다. audio input의 경우, 추가적인 linear projection layer를 사용해 audio feature를 text feature와 image feature와 동일한 차원을 갖도록 mapping했습니다.
- Multimodal Emotional Alignment
여러 modality에서 얻은 emotion representation을 aligning하는 것은 MM-TTS에서 중요한 단계입니다. 저자들은 prompt-based bridging으로 multimodal representation을 align 할 수 있는 prompt-anchoring scheme을 제안합니다. 먼저 학습된 projection metric을 통해 vision, audio, text feature를 embedding space로 project하여 vision-prompt (vis-pro)와 audio-prompt (aud-pro) embedding space를 구성합니다. 식으로 나타내면 다음과 같습니다.

W^(vis-pro), W^(aud-pro), W^(tex-pro) ∈ R^(K x K)는 projection matrix을 의미하며, u^(vis), u^(audio), u^(text)는 vis-pro space로 project된 embedding, aud-pro space로 project된 embedding, tex-pro space로 project된 embedding을 나타냅니다.
prompt embedding u^(prop)는 alignment modality를 기반으로 하는 projection matrix를 곱하여 얻어집니다.

emotion prompt에서 얻어지는 explicit emotion embedding u^(exp)과 vision, audio, text에서 얻어지는 implicit emotion embedding을 나타내는 u^imp를 사용합니다. explicit embedding과 implicit embedding 사이의 cosine similarity는 다음과 같이 계산됩니다.
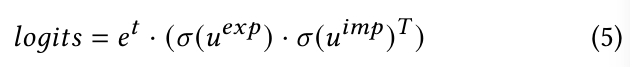
여기서 t는 학습된 temperature parameter를 나타내고, σ는 normalization operation을 의미합니다.
multimodal alignment loss L_(align)은 explicit embedding과 implicit embedding 사이의 symmetric cross-entropy loss를 이용해 정의됩니다.
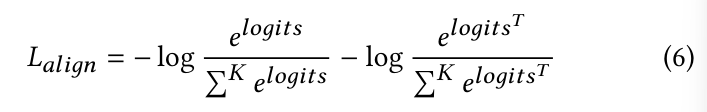
inference할 때, EP-Align은 가장 높은 similarity score를 가지고 있는 implicit embedding을 aligned emotion representation u^emo로 사용합니다. 이 aligned emotion representation은 multimodal input에 의해 capture되는 emotional content이고 TTS process의 unified representation으로 사용됩니다. prompt-anchoring scheme과 multimodal encoder를 사용함으로써, EP-Align은 효과적으로 다양한 modality에서 얻어진 emotion representation을 shared embedding space로 align하게 됩니다. 이 alignment는 TTS model이 input의 source modality에 상관없이 input emotional context에 일관적인 emotional speech를 생성할 수 있게 만들어 줍니다.
Emotion Embedding-induced TTS
이전 EP-Align module에서 얻어진 aligned emotion embedding u^emo를 가지고 Emotion Embedding-induced TTS (EMI-TTS)는 emotion representation을 TTS process에 적용하여 emotional speech를 생성합니다.
- Prompt-Anchoring Multimodal Fusion
multimodal emotion embedding space를 통해 bias를 완화시키기 위해, 저자들은 prompt-anchoring을 사용하여 aligned emotion embedding u^emo를 input text representation과 fuse합니다. 구체적으로 저자들은 cosine similarity 기반으로 implicit emotion embedding u^imp와 가장 유사한 prompt embedding u^prop를 찾습니다. 찾아진 prompt embedding은 implicit emotion representation과 explicit emotion representation 사이의 anchor 역할을 하며 연결 지어 줍니다. 이를 통해 TTS model에 emotion embedding을 일관되게 통합할 수 있습니다.
- Unified Emotional-TTS Framework
EMI-TTS는 Tacotron2, VITS, FastSpeech2와 같은 다양한 TTS model을 통합하는 unified framework를 제공합니다. 이러한 model들은 text encoder, length regulator, acoustic model, vocoder로 구성됩니다. text encoder는 input text Tex를 linguistic feature sequence h_lg로 변환합니다. length regulator는 linguistic feature의 duration을 원하는 speech length에 맞춰 조절합니다. acoustic model은 linguistic feature, emotion embedding, speaker embedding을 condition으로 하여 acoustic feature h_ac를 생성합니다. 마지막으로 vocoder는 acoustic feature를 speech waveform으로 변환합니다. EMI-TTS의 경우 emotion embedding u^emo와 speaker embedding u^spk는 concatenate된 다음 추가적인 conditioning input으로 TTS model에 통합됩니다. emotion embedding은 필수적인 emotional context를 제공하지만, speaker embedding은 speaker의 characteristic을 capture 합니다. 이를 통해 TTS model은 요구되는 emotion과 target speaker의 style을 반영하는 speech를 생성할 수 있게 됩니다. 식으로 나타내면, EMI-TTS는 다음과 같습니다.

위 식에서 h_lg^emo는 emotion embedding과 speaker embedding을 condition으로 하는 linguistic feature를 나타냅니다. Audio^emo는 생성된 emotional speech를 나타냅니다. 학습 과정에서, EMI-TTS는 추가적인 loss term 없이 기본 TTS model과 동일한 loss function을 사용합니다. model은 input text, emotion features, speaker information을 input pair로 사용하여 학습됩니다. EMI-TTS의 vocoder는 TTS model에 의해 결정됩니다. VITS는 본인의 decoder를 그대로 사용하고, Tacotron2와 FastSpeech2는 WaveNet vocoder를 사용합니다.
- Model Library
EMI-TTS는 Tacotron2, VITS, FastSpeech2를 포함하는 여러 최신 TTS model을 통합합니다. 다양한 TTS model set을 제공함으로써 EMI-TTS는 다양한 scenario와 요구사항에 맞춰 emotional speech를 생성할 수 있는 flexibility를 얻을 수 있게 됩니다.
- Tacotron2
기존 Tacotron model을 기반으로 하며, WaveNet technology를 사용하여 성능을 향상시켰습니다. Character Encoder는 text를 hidden state h_lg로 변환하고, u^emo를 추가하여 감정적으로 풍부한 state h_lg^(emo)를 생성합니다. 식으로 나타내면 다음과 같습니다.
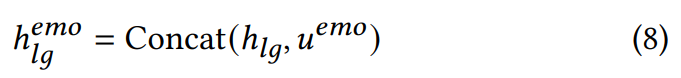
model이 speech synthesis에 있어 감정적 뉘앙스를 더 잘 capture 하도록 만들기 위해 Location Sensitive Attention을 nuanced Location & Emotion Sensitive Attention으로 발전시켰습니다.
- VITS
이 model은 variational inference를 normalizing flow와 adversarial training을 결합했습니다. Text Encoder, Length Regulator, Emotion-condition Flow로 구성됩니다. Emotion-condition Flow는 Text Encoder로 encode 된 phoneme sequence를 emotional hidden state h_lg^emo으로 조절합니다.
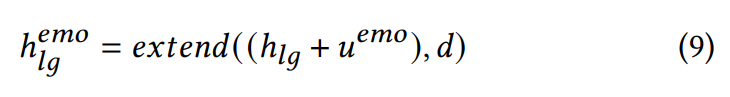
위 식에서 d는 각 unit의 예측된 duration입니다. 이 구조는 inference 할 때 더 다양하고 감정적인 표현을 포함하고 있는 speech를 합성하도록 만들어줍니다.
- FastSpeech2
Transformer 구조를 사용하여, FastSpeech2보다 이 model은 합성 속도가 빠르고 quality도 뛰어납니다. 이는 합성된 speech에 감정적 뉘앙스를 효과적으로 embed 하기 위해 Conditional Cross-Attention을 사용하는 Mel-spectrogram Decoder를 이용합니다.
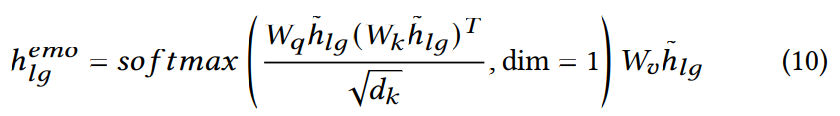
위 식에서 h~ = h+u^emo는 text input hidden state과 emotion embedding의 덧셈을 나타냅니다. 각 single-step computation은 hidden state의 확장, emotional modulation, cross-attention application을 효율적으로 처리하여 원활하고 표현력 있는 음성 합성을 실현합니다.
prompt-anchoring multimodal fusion과 unified emotional-TTS framework를 사용함으로써, EMI-TTS는 target speaker의 characteristic은 유지하면서 원하는 감정을 정확하게 반영하고 있는 emotional speech를 생성합니다. 합성 속도, voice quality, emotional expressiveness 등과 같은 application의 요구사항을 기반으로 TTS model을 선택하면 됩니다.
Experiments
Experimental Setting
- Dataset
- Multimodal EmotionLines Dataset(MELD)는 Emo-Alignment module 성능을 평가하기 위해 사용되었습니다. MELD dataset은 13708개 utterance로 구성되고, Anger, Disgust, Sadness, Joy, Neutral, Surprise, Fear 라는 감정을 다룹니다. training (9989개 utterance), validation (1109개 utterance), test set(2610개 utterance)로 구성됩니다.
- Emotion Speech Dataset (ESD)는 model의 vocal emotion expression을 평가하기 위해 사용됩니다. ESD는 10명 speaker로부터 녹음된 17600개 utterance로 구성됩니다. utterance는 neutral, happy, angry, sad, surprise라는 5가지 category로 나눠집니다. dataset은 training (14000개 utterance), validation (1750개 utterance), test (1750개 utterance)로 나눠집니다.
- Real-world Expression Database (RAF-DB)는 model이 visual data로부터 복잡한 감정을 인지할 수 있는지 평가하기 위해 사용됩니다. RAF-DB의 basic emotion dataset은 7가지 category로 나눠지는 15339개 image로 구성되며, emotion dataset은 11개 class로 나눠진 3954개 image로 구성됩니다.
Ablation Study
- Effectiveness of Multimodal Fusion
emotion recognition에 있어서 Emotion Prompt Alignment Module (EP-Align)의 영향을 평가하기 위해, 저자들은 MELD dataset을 이용하여 test를 진행했습니다. 실험 결과는 다음과 같습니다.
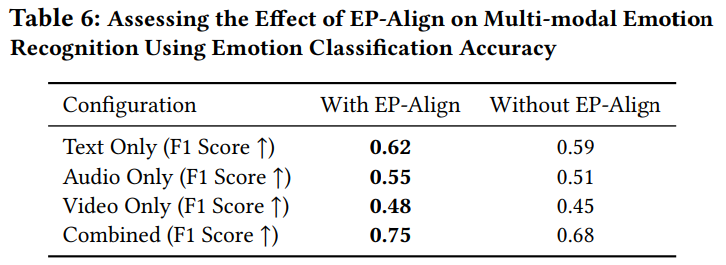
EP-Align이 emotion recognition 정확도를 상당히 향상시키는 것을 볼 수 있습니다. 여러 modality를 결합한 input을 사용했을 때, 가장 큰 성능 향상을 보였습니다. Multimodal fusion 상황에서 EP-Align의 효과를 보여주며, 감정 단서가 여러 channel에 분산된 환경에서 특히 효과적임을 보여줍니다.
Conclusion
이 논문에서 저자들은 textual, auditory, visual information을 사용하여 emotional speech를 합성할 수 있는 multimodal framework인 MM-TTS를 제안합니다. EP-Align module은 contrastive learning을 통해 modality 간의 잠정적 feature alignment를 원활하게 보장하며, EMI-TTS는 최신 TTS model들과 결합합니다. human emotional expression을 매우 가깝게 모방하는 감정적으로 풍부한 speech를 생성할 수 있습니다.



