https://arxiv.org/abs/2208.05890
Speech Synthesis with Mixed Emotions
Emotional speech synthesis aims to synthesize human voices with various emotional effects. The current studies are mostly focused on imitating an averaged style belonging to a specific emotion type. In this paper, we seek to generate speech with a mixture
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
emotional speech synthesis는 다양한 emotional effect를 가진 human voice를 합성하는 것을 목표로 합니다. 현재 연구들은 대부분 특정 감정 type에 속하는 평균적인 style을 모방하는 데 focus를 맞추고 있습니다. 이 논문에서 저자들은 실시간으로 mixture emotion을 가지는 speech를 생성하는 것을 목표로 합니다. 다양한 감정의 음성 sample 간 상대적 차이를 측정하는 새로운 공식을 제안합니다. 그리고 저자들의 공식을 sequence-to-sequence emotional TTS framework에 적용합니다. 학습 과정에서 framework는 emotion style을 characterize 할 뿐만 아니라 다른 감정과의 차이를 정량화하여 감정의 ordinal 특성을 탐구합니다. run-time에서는, emotion attribute vector를 정의하여 원하는 emotion mixture를 생성할 수 있도록 mdoel을 control합니다.
Introduction
저자들은 mixed emotion을 가진 speech synthesis에 대한 연구를 진행합니다. 심리학에서는 혼합된 감정의 paradigm과 측정 방식에 대한 연구들이 있었습니다. 하지만 음성 합성 분야에서 혼합 감정에 대한 연구는 아직 주목을 받지 못했으며, 두 가지 주요 연구 문제가 존재합니다: 1) speech emotion의 mixture를 어떻게 characterize하고 정량화할 것인가, 2) 합성된 speech를 어떻게 평가할 것인가. 이 논문에서는 이 두 가지 문제를 다룹니다.
main contribution은 다음과 같습니다.
- speech synthesis를 위해 mixed emotion을 modelling하는 첫 연구입니다. 이를 통해 emotional intelligence에 한 걸음 더 다가갈 수 있습니다.
- 감성 category 사이의 상대적 차이를 측정하는 새로운 방식을 제안하며, emotional TTS framework가 학습 중에 speech sample의 emotion style 간 차이를 정량화하도록 만듭니다. run-time에서는 정의된 emotion attribute vector을 가지고 model이 원하는 emotion mixture를 생성할 수 있도록 만듭니다.
- 저자들이 제안한 framework의 효과와 speech의 감정적 표현을 확인하기 위해 objective evaluation과 subjective evaluation을 고안했습니다.
Backgroiund and Related Work
Characterization of Emotions
인간의 감정을 이해하는 것(e.g., 그 본질과 기능)은 심리학에서 많은 주목을 받아왔습니다. 감정의 원 이론과 감정의 ordinal 특성을 포함한 많은 이전 연구들에서 영감을 받아 이 연구를 진행했습니다.
- Theory of the Emotion Wheel
사람은 약 34000개의 감정을 경함 할 수 있습니다. 모든 구분된 emotion을 이해하는 것은 어렵지만, Plutchik은 8가지 기본 감정을 제안했습니다: 분노, 공포, 슬픔, 혐오, 놀람, 기대, 신뢰, 기쁨이며, 이를 감정의 원에 나열했습니다. 아래 그림과 같습니다.

모든 감정들은 이 기본 감정들의 혼합 또는 파생 상태로 간주될 수 있습니다. 감정의 원 이론에 따라, 강도의 변화는 우리가 느낄 수 있는 다양한 감정을 만들어낼 수 있습니다. 그리고 기본 감정을 추가하여 새로운 감정을 생성할 수 있습니다. 예를 들어 기쁨과 놀람을 결합하여 즐거움을 만들 수 있습니다.
심리학에서 이러한 노력에도 불구하고, speech synthesis 분야에서 mixed emotion을 model하는 시도는 거의 존재하지 않았습니다. 감정의 원 이론에 영감을 받아, 저자들은 다양한 기본 emotion을 결합하여 speeh에 mixed emotion을 합성하는 것이 가능하다고 생각했습니다. 이러한 기술을 통해 실생활에서 모으기 힘든 새로운 감정 type을 생성할 수 있으며, 인간 감정을 더 잘 모방할 수 있습니다.
- The Ordinal Nature of Emotions
감정은 본질적으로 상대적이며, annotation과 ordinal path를 따라야 합니다. 절대적인 점수나 감정 category를 할당하는 대신, ordinal method는 비교 평가를 통해 감정을 characterize합니다(e.g., 첫 번째 문장이 두 번째 문장보다 더 행복해 보이는가??). ordinal method는 speech emotion recognition에서 특히 눈에 띄는 성능을 보여줍니다.
ordinal method의 key idea는 주어진 criterion에 따라 순위를 학습하는 것입니다. preference learning에서 sample 사이의 preference를 추정하는 것이 예시입니다. 선호도가 추정되면, sample의 순위를 측정하는 것은 간단합니다. 또 다른 rank-based method들도 speech emotion recognition에서 효과를 보여줍니다. emotional speech synthesis와 관련하여 연구자들은 감정의 강도를 modelling하기 위해 emotion의 ordinal nature 관련 연구 또한 진행하며, 감정의 강도는 중립적인 sample과 감정적 sample 사이의 상대적 차이로 여깁니다. 이전 연구들에서 영감을 받아, 저자들은 다른 감정 category의 speech sample 사이의 상대적 차이를 정량화하는 rank-based method를 연구합니다.
Controllable Emotional Speech Synthesis
speech emotion은 다양한 prosody 측면에서 나타납니다. Emotion rendering은 다양한 prosody 신호를 수정함으로써 제어할 수 있습니다. 최근 연구들은 주로 representation learning framework에서 파생된 control vector로서 prosody embedding을 design하는 것에 중점을 둡니다. 예를 들어 style tokens은 spaeker style, pitcch range, speaking rate와 같은 high-level style을 나타내기 위해 design되었습니다. Emotion rendering은 특정 token을 선택함으로써 control 할 수 있습니다. 또 다른 최신 연구들은 style token-based diagram에 계층적이고 세밀한 prosody representation을 포함하는 방법을 연구하기도 합니다. 다른 연구들은 VAE를 사용하여 분리된 representation을 결합하거나 scaling하거나 학습하는 방식으로 speech style을 control하기도 합니다.
최근에는 감정의 강도를 control하는 것은 emotional speech synthesis에서 많은 주목을 받고 있습니다. 감정의 강도는 음성 감정에 기여하는 모든 음향 신호와 관련이 있다고 여겨져, 이를 modelling하는 것은 더 도전적인 과제가 됩니다. 일부 연구들은 음성/비음성/침묵 (VUS)의 상태, attention weight, saliency map과 같은 보조 feature를 사용하여 emotion intensity를 control합니다. 또 다른 연구들은 interpolation, scaling, distance-based quantization을 통해 internal emotion representation을 조작합니다. 또 다른 연구들에서는 해석 가능한 emotion intensity의 representation을 학습하기 위해 relative attribute를 사용하기도 합니다. 하지만 이러한 framework들 모두 emotion 사이의 correlation과 상호작용을 연구하지는 않습니다.
Mixed Emotion Modelling and Synthesis
저자들은 합성된 emotion을 조절할 수 있는 새로운 relative scheme을 제안합니다(여러 다른 emotion style을 mixing).
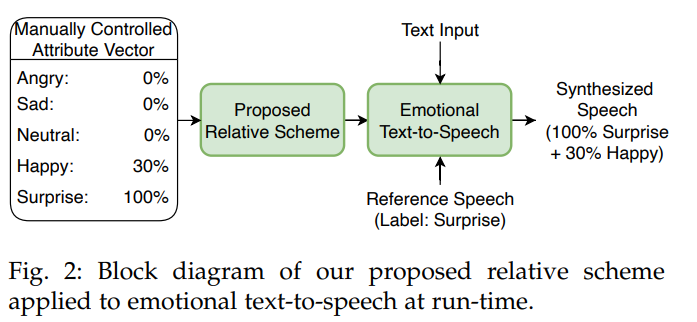
그림으로 나타내면 위와 같습니다. 저자들이 제안한 scheme은 음성에서 각 emotion의 intensity를 유연하게 조절할 수 있습니다. 이 framework는 text input에 대해서 reference emotion을 가지고 있는 새로운 utterance를 실시간으로 만들어 낼 수 있는 emotional texto-to-speech가 가능합니다.
Characterization of Mixed Emotions in Speech
감정은 categorical 또는 dimensional representation으로 characterize될 수 있습니다. design된 emotion label을 사용하면, emotion category approach는 emotion을 표현하기 가장 직접적인 방법입니다. 하지만 이러한 representation은 감정의 미세한 변화는 무시합니다. 다른 방법들은 dimensional representation으로 speech emotion의 물리적 성질을 modelling하는 방식입니다. 예시로 Russell의 원형 model이 있으며, 이는 감정을 arousal, valence dimension을 포함하는 2차원 원형 space에 분포하는 방식입니다.
mixed emotion을 characterize하는 가장 직접적인 방법은 연속적인 공간에 다양한 emotion style을 inject하는 것입니다. mixed emotion은 각 dimesion을 잘 조절하여 합성될 수 있습니다. 하지만 speech dataset은 적은 수의 감정만 포함되어 있습니다. 그리고 해당 감정의 annotation도 주관적이고 모으기 어렵습니다. 그래서 저자들은 대부분의 database에서 사용할 수 있는 discrete emotion label을 사용합니다. 감정의 원 이론에 기반하여 가정을 세웠습니다: 'mixed emotion은 기본 감정들의 결합, 혼합 또는 복합에 의해 characterize된다'는 것입니다. 감정을 단순히 더하는 것은 간단하지 않지만, 대신 감정의 ordinal nature에 대해 연구를 했습니다.
저자들은 서로 다른 감정 type으로 녹음된 speech 사이의 상대적인 차이를 정량화하기 위해 ranked-based relative scheme을 제안했습니다. mixed emotion은 서로 다른 emotion type 사이의 상대적인 차이를 조정하여 characterize 될 수 있습니다. 상대적인 차이는 각 감정의 참여 수준을 정량화할 수도 있습니다.
Design of a Novel Relative Scheme
mixed emotion을 합성하는데 어려움 중 하나는 다른 감정들의 연관성이나 상호성을 정량화하는 것입니다. 감정의 ordinal nature에 영감을 받아, 저자들은 이 문제를 해결할 수 있는 새로운 relative scheme을 제안합니다. 저자들은 emotion wheel 이론에 따라 두 가지 가정을 세웁니다. 1) 모든 감정은 어느 정도 관련이 있다, 2) 각 감정은 고유한 style을 가지고 있다,라는 두 가지 가정입니다. 저자들은 각 감정의 식별 가능한 style을 characterize 할 뿐만 아니라 서로 다른 감정 style의 유사도를 정량화합니다.
감정 category 사이의 상대적 차이를 측정하는 rank-based method를 연구했으며, 이를 통해 더 많은 정보를 제공하여 사람의 supervision과 유사하게 만들 수 있다고 합니다. computer vision 분야에서 상대적 특성은 서로 다른 category의 data 사이의 상대적 차이를 modelling하기에 효과적인 방법입니다. 다양한 computer vision task에서 영감을 받아 저자들은 상대적 속성이 low-level feature와 high-level semantic meaning 사이의 연결 역할을 해준다고 생각한다고 합니다. 이는 discrete emotion label만 가지고 emotion 간의 상대적 차이를 modelling 할 수 있게 만들어줍니다. 이 방식으로 저자들은 식별 가능한 emotion style을 speech data의 특성으로 간주하며, 이는 풍부한 emotion 관련 acoustic feature를 가지고 표현할 수 있습니다. emotion style의 상대적 차이는 "emotion attribute"라고 불리는 relative attribute로 modelling 될 수 있습니다. emotion attribute는 max-margin optimization problem을 통해 학습될 수 있습니다.
x_n은 n번째 training sample의 acoustic feature이고 T = A ∪ B (A와 B는 서로 다른 emotion set)인 training set T = {x_n}이 주어졌을 때, ranking function을 학습하는 것을 목표로 합니다.

위 식에서 W는 emotion style의 차이를 나타내는 weighting matrix입니다. 저자들이 말한 가설에 따라, 저자들은 다음 constraint를 제안합니다.

weight matrix W는 다음 support vector machine 문제를 해결하는 방식으로 구해질 수 있습니다.
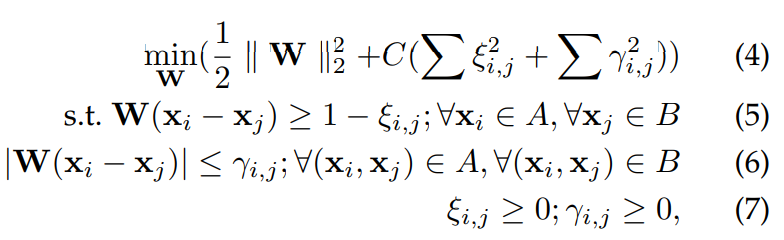
C는 margin과 slack variable ξ, γ 크기의 trade-off입니다.
위 식을 통해 저자들은 각 training point의 ordering을 할 수 있게 wide-margin ranking function을 학습합니다.

위 그림에서 (a)처럼, 각 emotion pair 사이의 relative ranking function f(x)를 학습합니다. 위 그림의 (b)처럼 inference에서 학습된 function은 unseen data의 emotion attribute를 추정할 수 있습니다. 각 emotion attribute value는 [0, 1]로 정규화되며, 낮은 value는 비슷한 emotional style임을 나타냅니다. 모든 normalized emotion attribute는 emotion attribute vector를 만듭니다. emotion attribute vector는 discrete primary emotion label을 결하며 sequence-to-sequence emotion training에 통합됩니다.
Training Strategy
저자들은 voice conversion의 joint training과 함께 emotional text-to-speech framework를 채택했습니다. text-to-speech와 voice conversion은 internal representation으로부터 실제 같은 speech를 생성한다는 공통적인 goal을 공유하며, joint training은 효과적입니다. text-to-speech와 voice conversion이 공유하는 decoder는 robust decoding process에 기여합니다.
전체 emotional text-to-speech framework는 sequence-to-sequence system으로 학습되는 encoder-decoder이며 아래 그림과 같은 구조입니다.

text encoder와 linguistic encoder는 input에 맞춰 embedding sequence를 생성하고, emotion encoder는 전체 reference speech sample을 capsule화하는 embedding을 생성합니다.
text와 speech가 input으로 주어졌을 때, text encoder는 text로부터 linguistic embedding을 예측하도록 학습되고, linguistic encoder는 speech로부터 linguistic embedding을 예측하도록 학습됩니다. decoder는 epoch이 홀수일 때는 text로부터 linguistic embedding을 받고 짝수일 때는 speech로부터 linguistic embedding을 받습니다. contrastive loss는 두 type의 linguistic embedding 사이의 유사도를 ensure하기 위해 사용됩니다. emotion classifier를 사용한 adversarial training strategy은 acoustic linguistic embedding에서 residual emotion information을 제거하기 위해 사용됩니다.
emotion encoder는 emotion label의 supervision을 사용하여 input speech로부터 emotion embedding vector를 추출합니다. 반면에 emotion attribute vector는 pre-trained relative scheme과 fully connected layer를 이용해 생성됩니다. emotion embedding은 input speech의 emotion style을 나타내지만, emotion attribute vector는 input emotion style과 다른 emotion style 사이의 차이를 나타냅니다. 마지막으로 decoder는 emotion과 relative embedding의 combination으로부터 input emotion style을 reconstruct하도록 학습됩니다.
전체 training 과정은 sequence level에서 recognition-synthesis process로 볼 수 있습니다. 저자들의 framework는 database에서 얻어지는 풍부한 emotion variance 뿐만 아니라 서로 다른 감정 category 사이의 correlation과 연관성을 학습합니다. 이는 실시간으로 감정 차이 level을 명시적으로 조정할 수 있게 해주며, 동시에 mixed emotion synthesis 및 emotion rendering을 유연하게 control 할 수 있게 만들어줍니다.
Control of Emotion Rendering
저자들의 emotional TTS framework는 실시간으로 controllable emotional speeh를 redering할 수 있으며, 다음과 같습니다.
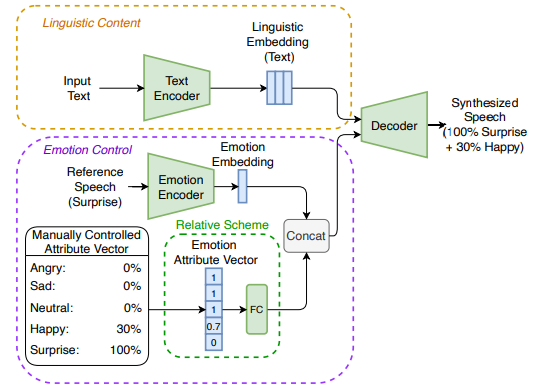
세 가지 main module로 구성되며, content encoder, emotion controller, decoder입니다. text encoder는 input intext로부터 얻어진 linguistic information을 internal representation으로 project합니다. emotion encoder는 reference speech로부터 embedding에서 emotion style을 capture하고, relative scheme은 수동으로 할당된 attribute vector를 통해 다른 emotion type의 characteristic을 추가로 도입합니다. attribute vector에 있는 각 primary emotion의 percentage를 조절하여 쉽게 원하는 emotion effect를 합성할 수 있고 합성된 speech의 emotion rendering을 control 할 수 있습니다.
Experiments and Evaluations
Training Pipeline
emotional speech dataset을 이용하여 각 emotion pair 사이의 relative ranking function을 pre-train합니다. 저자들은 open-source relative ranking function을 사용했습니다. 저자들은 openSMILE로부터 추출한 acoustic feature를 input feature로 사용했습니다. 학습된 ranking function은 test set에 대해서 분류 정확도가 97% 정도 나왔습니다.
그다음 저자들은 two-stage training strategy를 사용하여 TTS framewokr를 학습했습니다. 1) Multi speaker TTS training with VCTK Corpus, 2) Emotion Adaptation for TTS with single speaker from ESD dataset입니다. 저자들의 TTS framework는 multi-speaker corpus를 가지고 풍부한 speaker style을 학습하며 적은 양의 emotional speech data를 가지고 실제의 emotion information을 학습합니다. 저자들은 5가지 emotion을 고려했습니다. 'Neutral, Angry, Happy, Sad, Suprise'이며, 각 emotion에 대해 ESD에서 나눠서 사용했습니다. 각 speaker에 대해서 각 감정마다 학습에 300개의 utterance를 사용하고 tset에는 20개의 utterance를 사용했습니다. 총 emotional speech training data의 길이는 약 50분입니다.
Objective Evaluation
저자들은 pre-trained speech emotion recognition (SER) model을 사용하여 저자들의 method의 효과를 측정하고 분석했습니다. 그리고 저자들은 Mel-cepstral Distortion (MCD)와 Pearson correlation coefficient (PCC)를 objective evaluation metric으로 사용했습니다.
- Analysis with Speech Emotion Recognition
저자들은 mixed emotion을 pre-trained SER로 평가했습니다. SER의 softmax layer로부터 얻어지는 classification probability를 사용하여 mixed emotion의 효과를 분석했습니다. high-level feature로서, classification probability는 마지막 deicsion을 결정짓기 위해 마지막 layer로부터 유용한 emotion information을 요약합니다. classification probability는 emotion mixture로부터 각 emotional component가 SER에 의해 얼마나 잘 인지되는지를 정당화하는 효과적인 도구를 제공합니다.

위 결과는 남성 speaker에 대한 classification probability를 보여줍니다. 저자들은 surpise라는 감정은 100%로 유지한 채로 angry, happy, sad라는 감정은 점진적으로 (0%, 30%, 60%, 90%)으로 향상시킨 상태로 평가를 진행했습니다. (a)의 경우 angry를 0에서 90까지 증가시킨 결과입니다. angry의 확률이 상승한 것을 볼 수 있지만, surprise는 감소했습니다. 그래도 surprise가 다른 감정들에 비해 훨씬 높은 확률 값을 보이고 있습니다. (b)에는 hapyy에 대한 결과를 보여주고 (c)에서는 sad에 대한 결과를 보여줍니다. 모두 비슷한 경향을 보입니다.
- Mel-cepstral Distortion
sound의 short-term power spectrum을 기반으로 하는 Mel-cepstral coefficient와 같은 Spectral feature는 표현력과 emotion에 대한 풍부한 정보를 포함하고 있습니다. Mel-cepstral Distortion (MCD)은 spectrum의 유사도를 측정하는데 자주 사용되며, 합성된 spectrum과 target MCEP 사이의 유사도를 측정합니다. 식은 다음과 같습니다.
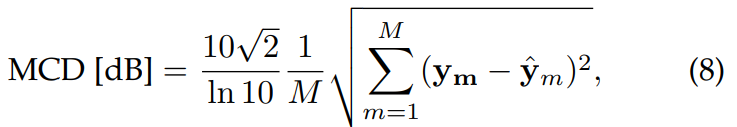
- Pearson Correlation Coefficient
Pitch는 speech emotion에 대해 주요 prosodic factor로 여겨집니다. pitch는 fundamental frequency (F0)로 표현되며 harvest algorithm을 통해 구해질 수 있습니다. 저자들은 두 F0 sequence 사이의 선형적 의존성을 측정하기 위해 F0의 pearson Correlation Coefficient (PCC)를 계산했습니다. 두 F0 sequence 사이의 PCC는 다음과 같이 구해집니다.

위 식에서 cov()는 covariance function을 의미하고, sigma는 두 F0 sequence의 표준편차를 의미합니다. PCC value가 높을수록 prosody의 유사도가 높다는 것을 의미합니다.
- Discussion of the MCD and PCC Results
합성한 mixed emotion의 효과를 보이기 위해, 저자들은 합성된 결과와 reference emotion (Angry, Happy and sad) 사이의 MCD와 PCC를 계산했습니다. 저자들은 남성 speaker 한 명과 여성 speaker 한 명을 선택했습니다. 각 speaker에 대해 20개의 evaluation을 사용하여 평가를 진행했습니다. 저자들은 각 감정에 대해 0%, 30%, 60%, 90%로 percentage를 설정하고 실험을 진행했습니다. 그리고 아까와 같이 surprise는 primary emotion으로서 100%로 유지했습니다.
spectrum similarity는 다음과 같습니다.
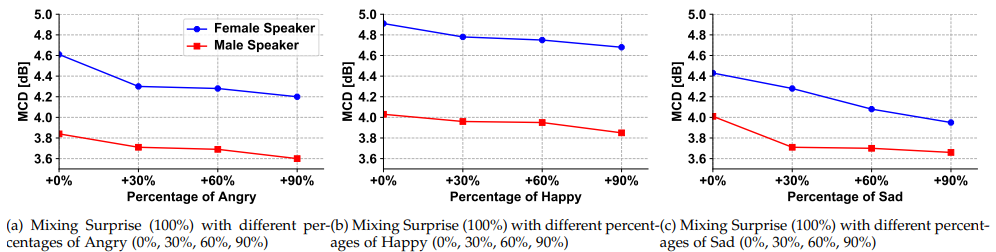
세 가지 다른 combination에서 reference emotion (angry, happy, sad)이 증가됨에 따라 MCD value가 감소되는 것을 볼 수 있습니다. 이러한 결과를 통해 spectrum에서 reference emotion의 percentage가 증가됨에 따라 합성된 emotion이 reference emotion과 점점 유사해지는 것을 의미합니다.
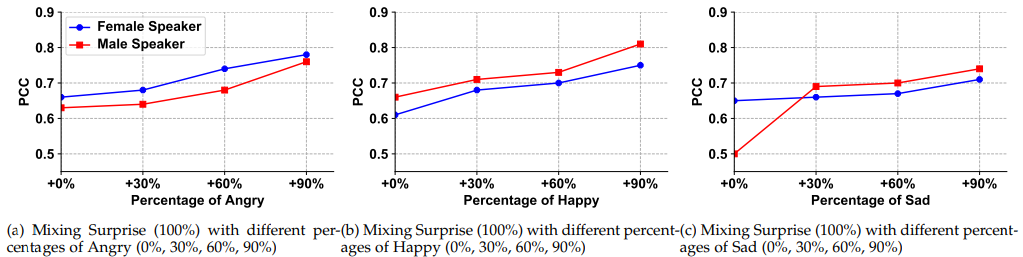
prosody 유사도는 위와 같습니다. reference emmotion의 percentage가 증가함에 따라, 저자들은 PCC value가 일관성있게 증가되는 것을 확인했습니다. prosody variance 관점에서 합성된 mixed emotion이 reference emotion과 강한 correlation을 띈다는 것을 의미합니다.
Conclusion
이 연구는 speech synthesis와 mixed emotion synthesis 사이의 gap을 채워주는 역할을 합니다. 저자들은 sequence-to-sequence model 기반 emotional speech synthesis framework를 제안합니다. 저자들의 method는 mixed emotion을 합성할 수 있을 뿐만 아니라 mixed emotion의 rendering을 control 할 수 있습니다. key highlight는 다음과 같습니다.
- 저자들은 각 emotion pair 사이의 차이를 측정하는 새로운 relative scheme을 제안합니다. 저자들의 relative scheme은 효과적인 합성과 mixed emotion의 rendering을 control할 수 있습니다.
- mixed emotion을 평가하는 연구입니다. objective, subjective evaluation을 통해 저자들의 idea를 입증했습니다.
- 저자들은 쓸쓸하면서도 달콤한 감정을 합성하고 emotion triangle을 합성하는 것에 대해 조사를 진행했습니다.



