https://arxiv.org/abs/2308.15256
Let There Be Sound: Reconstructing High Quality Speech from Silent Videos
The goal of this work is to reconstruct high quality speech from lip motions alone, a task also known as lip-to-speech. A key challenge of lip-to-speech systems is the one-to-many mapping caused by (1) the existence of homophenes and (2) multiple speech va
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문의 goal은 lip motion만 가지고 high quality speech를 reconstruct하는 것이고, 이는 lip-to-speech로 알려져 있습니다. lip-tp-speech system의 주요 challenge는 one-to-many mapping입니다. one-to-many mapping은 1) 동음이의어의 존재, 2) 잘못 발음되거나 over-smooth한 speech로 인해 발생되는 multiple speech variation 때문에 발생합니다. 이 논문에서 저자들은 다양한 관점에서 one-to-many mapping 문제를 완화시켜 생성 quality를 상당히 향상시킨 새로운 lip-to-speech system을 제안합니다. 구체적으로 저자들은 1) 동음이의어의 모호성을 줄이기 위해 self-supervised speech representation을 사용하고, 2) 다양한 speech syle을 model하기 위해 acoustic variance information을 사용합니다. 추가적으로 문제를 더 잘 해결하기 위해, 저자들은 생성된 speech의 세부 사항을 포착하고 정제하는 flow based post-net을 사용합니다.
Introduction
이 논문에서 저자들은 내제된 one-to-many mapping 문제를 완화시킴으로써 합성 quality를 향상시키는 새로운 Lip-to-Speech system을 제안합니다. 동음이의어의 모호성을 완화시키기 위해, 저자들은 self-supervised speech representation을 linguistic information condition으로 사용합니다. 이전 연구들에서 self-supervised learning (SSL) speech model이 수동으로 생성된 labeled text 없이도 풍부한 speech representation을 얻을 수 있다는 것이 증명되었습니다. 특히 SSL model의 특정 layer에서 얻어지는 representation은 비언어적 feature와 독립적인 정교한 linguistic information을 포함하고 있습니다. 이러한 사실에서 영감을 받아, 저자들은 SSL model의 중간 layer에 대한 연구를 진행했으며 text label 없이 정확한 content를 생성하기 위해 hidden representation을 사용했습니다.
또한 다양한 speech variation을 modelling하기 위해 pitch, energy와 같은 acoustic variance information을 modelling합니다. acoustic variation 덕분에 model은 one-to-many mapping을 완화할 뿐만 아니라 실제 같은 음성 합성에 있어 주요한 key인 speech의 prosody도 학습할 수 있습니다. one-to-many mapping 문제를 해결하기 위해, 추가적으로 저자들은 세밀한 detail까지 capture할 수 있고 acoustic representation을 정제할 수 있는 flow based post-net을 사용했습니다. variance information과 결합된 post-net은 phoneme과 speech 사이의 복잡한 one-to-many mapping을 학습할 수 있고, 합성된 speech의 자연스러움도 향상시킬 수 있습니다.
Related work
Self-Supervised Learning
최근 몇 년동안, SSL은 unlabeled data로부터 포괄적인 data representation을 얻는 유망한 방식으로 떠오르고 있으며, 자연어 처리, computer vision에서 주목할 만한 성공을 거두었습니다. 음성 처리 분야에서는 wav2vec2.0, HuBERT가 유망한 결과를 보였으며, speech recognition, voice conversion과 같은 다양한 application에서 사용될 수 있습니다. 그 뒤에 등장한 연구들은 다른 layer에서 얻어지는 hidden representation이 voice characteristic, linguistic content와 같은 speech 특성과 관련이 있음을 보였습니다. 이에 영감을 받아, 저자들은 SSL model의 특정 layer에서 self-supervised hidden representation을 활용하여 linguistic condition을 제공하고 동음이의어 문제를 완화합니다.
Method
무성 talking face video가 주어졌을 때, 저자들의 목표는 그에 맞는 mel-spectrogram을 합성하는 것입니다.
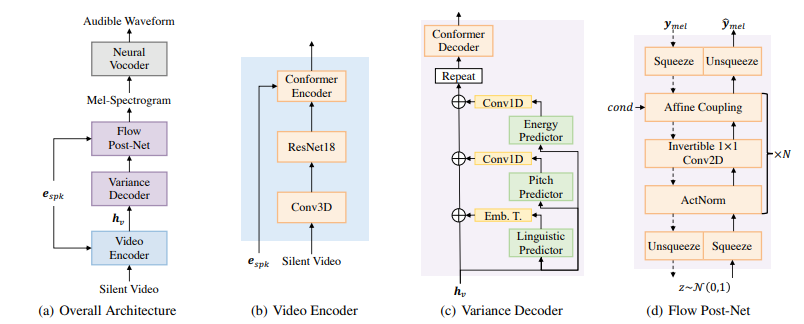
위 그림 중 (a)와 같이 model은 video encoder, variance decoder, flow based post-net 이라는 세 가지 주요 구성 요소로 구성됩니다. video encoder는 input video에서 뚜렷한 visual feature를 추출하고, variance decoder는 linguistic feature와 acoustic speech variation (i.e. pitch and energy)를 condition으로 하여 mel-spectrogram을 순차적으로 생성합니다. flow based post-net은 mel-spectrogram을 세밀하게 정교화시키며, 결과는 pre-trained neural vocoder에 의해 waveform으로 변환됩니다.
Video Encoder
T_v개 frame이 있는 input video로부터 video encoder는 뚜렷한 hidden representation h_v ∈R^(T_v x d)를 추출합니다. 여기서 d는 hidden embedding dimension을 의미합니다. 위 그림의 (b)와 같이 video encoder는 3D convolution, ResNet18, conformer encoder로 구성됩니다. 3D convolution과 결합된 ResNet18은 인접한 context와 local visual feature를 capture할 수 있습니다. ResNet18 위에 저자들은 conformer encoder를 추가했습니다. conformer encoder는 conformer layer의 stack으로 구성됩니다. conformer encoder는 long-term dependency를 학습할 수 있으며 convolution layer에서 얻어지는 locality를 유지한 채로 globality를 활용할 수 있습니다. 또한 각 speaker마다 서로 다른 visual characteristic을 갖고 있기 때문에, embedding table을 통해 speaker identity를 conformer encoder에 inject했습니다. 저자들의 실험을 통해, speaker embedding은 model이 discriminative visual feature를 추출할 수 있도록 도와주며, 합성된 speech의 자연스러움과 명료성을 향상시켜줍니다.
Variance Decoder
Lip-to-Speech에서 one-to-many mapping problem을 완화하기 위해 variance decoder는 풍부한 variance information을 가지고 acoustic representation을 생성하는 것을 목표로 합니다. 위 그림 (c)와 같이, variance decoder는 variance predictor, conformer decoder로 구성됩니다. variance predictor는 linguistic, pith, energy predictor로 구성되며, 각각은 variance information을 hidden visual representation h_v의 condition으로 만드는 것을 목표로 합니다. 학습 과정에서 ground truth variance information을 hidden sequence에 입력하고, inference 할 때는 예측된 value를 사용합니다. 그 뒤에 존재하는 conformer decoder는 강화된 hidden visual feature를 중간 acoustic representation으로 변환합니다.
Linguistic predictor
동음이의어의 존재는 정확한 발음으로 명료한 speech를 합성하는 것을 방해합니다. 이전 연구들이 text supervision을 사용하여 동음이의어의 모호함을 해결하는 시도를 했지만, 수동으로 annotated된 text label을 필요로 하고 LTS system의 이점을 누릴 수 없었습니다. self-supervised 특성을 유지한 채로 명료한 speech를 생성하기 위해, 저자들은 text label 없이 동음이의어의 모호함을 해결하는 linguistic predictor를 제안합니다.
이를 위해 저자들은 양자화된 self-supervised speech representation을 사용합니다. pre-trained SSL speech model (HuBERT)를 사용하여 raw waveform으로부터 연속적인 linguistic representation을 추출한 다음, 학습의 강건함을 위해 연속적인 representation을 quantise합니다. 이전 연구들에서 HuBERT의 특정 layer로부터 얻은 speech representation을 양자화한 것은 정확환 발음과 관련된 정교한 linguistic feature를 포함하고 있다는 것을 보였습니다. 저자들은 다양한 linguistic feature extraction 구성의 효과를 조사했으며, HuBERT-LARGE의 12번째 layer로부터 얻은 representation에 K-mean algorithm을 사용하여 200개 cluster로 양자화될 때 linguistic information과 가장 높은 연관성을 보인다는 것을 실험을 통해 알아냈습니다.
visual hidden feature h_v가 주어졌을 때, linguistic predictor는 각 frame의 cluster를 추정하는 것을 목표로 합니다. linguistic predictor는 cross-entropy (CE) loss를 이용해 최적화됩니다. 식으로 나타내면 다음과 같습니다.
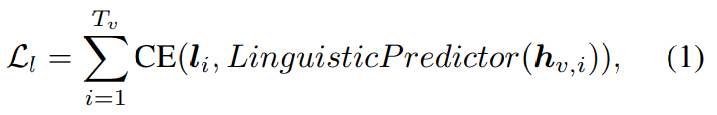
위 식에서 l_i는 target sequence의 i번째 cluster index를 의미하고, h_(v, i)는 i번째 visual representation을 의미합니다.
Pitch Predictor
Pitch는 자연스러운 prosody를 가진 실제와 같은 speech를 합성하는데 중요한 역할을 합니다. 하지만 pitch는 성별, 나이, 감정에 의해 다양한 변화를 보이며 LTS의 one-to-many problem을 악화시킵니다. lip motion으로부터 pitch information을 정확하게 capture하기 위해서, 저자들은 pitch predictor를 사용합니다. pitch predictor는 hidden visual feature를 기반으로 pitch sequence를 추정합니다.
저자들은 pYIN algorithm을 통해 ground truth audio로부터 ground truth pitch value를 추출하고, 더 나은 sampling을 위해 표준화하여 평균이 0이고 분산이 1이 되도록 만듭니다. 추출된 pitch value는 visual feature의 시간적 dimension에 맞추기 위해 순차적으로 downsampling됩니다. pitch predictor는 ground truth와 predicted pitch sequence 사이의 L1 loss를 가지고 최적화됩니다. 식으로 나타내면 다음과 같습니다.
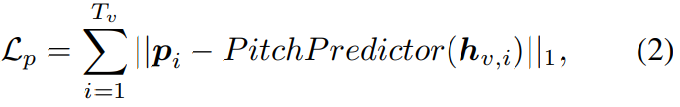
위 식에서 p_i는 video의 i번째 frame으로부터 얻은 ground truth pitch입니다.
Energy Predictor
Energy는 speech의 강도를 나타내는데, speech의 volume과 prosody에 영향을 줍니다. frequency axis를 따라 mel-spectrogram에 L2 norm을 적용하여 target enery sequence를 얻습니다. h_v로부터 energy sequence를 추정하기 위해, 저자들은 energy predictor를 사용합니다. energy predictor는 ground truth enery sequence와 predicted energy sequence 사이의 L1 loss를 적용하여 최적화됩니다. 식은 다음과 같습니다.
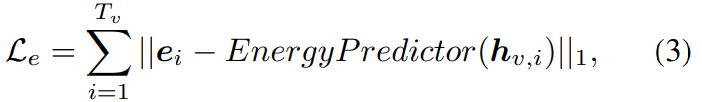
위 식에서 e_i는 i번째 target energy value입니다.
각 variance information은 embedding table (linguistic)을 통해 variance embedding으로 encode되거나 single 1D convolution layer (pitch and energy)를 통해 variance embedding으로 encode됩니다. variance embedding은 visual representation h_v에 더해지고, adapted reprsentation은 target mel-spectrogram의 time resolution과 match될 때까지 upsample됩니다. 마지막으로 conformer decoder는 representation을 mel-spectrogram으로 변환합니다. ground truth-mel-spectrogram과 predicted mel-spectrogram 사이에 L1 loss를 적용합니다. 식은 다음과 같습니다.
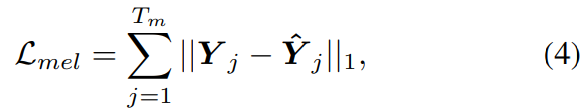
Y_j는 T_m 길이의 ground truth mel-spectrogram의 j번째 frame을 의미하고, Y^j는 predicted mel-spectrogram의 j번째 frame을 의미합니다.
variance predictor는 conditional information을 제공하여 acoustic target distribution을 단순화시켰으며, 이를 통해 one-to-many mapping issue를 완화시켰습니다.
Post-net
자연스러운 human speech는 dynamic variation에 의해 얻어집니다. 하지만 단순한 reconstruction loss (L1 or L2 loss)는 detail을 capture하는데 한계가 존재하며, blurry하거나 oversmooth한 speech를 합성하도록 만듭니다. sample quality를 향상시키기 위해 저자들은 flow based post-net을 사용합니다. 이는 coarse-grained mel-spectrogram을 fine-graind mel-spectrogram으로 정교화합니다.
post-net 구조는 위 그림의 (d)와 같습니다. 학습 단계에서 post-net은 training data x의 mel-spectrogram을 가역 function f = f_0of_1o...of_k를 통해 계산 가능한 prior distribution으로 변환합니다. 이 function은 conformer decoder의 input과 output, speaker embedding을 condition으로 합니다. post-net은 data x에 대한 negative likelihood를 minimize하여 최적화됩니다. 식으로 나타내면 다음과 같습니다.

p_θ(z)는 latent variable z에 대한 tractable prior (isotropic multivariate Gaussian)이고 J는 Jacobian입니다. inference stage에서 prior distribution에서 sample z를 얻고 post-net의 inverse에 feed하여 mel-spectrogram을 얻어냅니다. 이 flow-based module은 복잡한 data 분포를 modelling하는 능력을 향상시켜 one-to-many mapping 문제를 해결하는데 도움을 줄 수 있습니다. 최종 loss (L_final)은 다음과 같습니다.

위 식에서 L_var = L_l + L_p + L_e이고, 저자들은 실험에서 λ_var = λ_post = 0.1로 설정했습니다.
Neural Vocoder
predicted mel-spectrogram을 audible waveform으로 변환하기 위해서 저자들은 pre-trained Fre-GAN을 neural vocoder로 사용했습니다. adversarial network를 기반으로, 이 vocoder는 lossless downsampling method인 wavelet transform을 사용하여 frequency-consistent waveform을 생성합니다. Griffin-Lim algorithm과 비교했을 때, Fre-GAN vocoder는 뛰어난 reconstructing waveform 성능을 보입니다. vocoder는 inference때만 사용됩니다.
Experimental Settings
Model Configuration
conformer encoder를 제외하고 나머지 model들은 전부 동일한 구조로 만들었습니다. speaker embedding은 embedding table을 통해 구해졌고, 각 speaker identity는 고정된 크기의 embedding vector로 변환됩니다. pitch와 energy predictor는 2개 1D convolution layer로 구성되며 linguistic predictor는 4개 1D convolution으로 구성됩니다.
Evaluation Metrics
저자들이 제안한 method의 성능은 qualitative and quantitative evaluation metric으로 평가했습니다. qualitative evaluation의 경우, 저자들은 mean opinion score (MOS) test를 수행했습니다. 그리고 word error rate (WER)과 character error rate (CER)을 진행했습니다. error calcuation을 위해, 저자들은 사용가능한 automatic speech recognition (ASR) model을 가지고 speech clip의 transcription을 구해 사용했습니다.
Experimental Results
Qualitative Results
생성된 speech의 quality를 평가하기 위해, 저자들은 자연스러움과 명료성에 대한 MOS를 수행했습니다.

저자들의 model이 좋은 성능을 보이는 것을 알 수 있습니다. GRID와 비교했을 때 Lip2Wav의 WER와 CER 수치가 더 좋지 않습니다. 하지만 다른 model들도 동일하며, 저자들의 model들이 가장 성능이 덜 감소했습니다. 즉 저자들의 model이 unconstrained environment에서도 사용 가능함을 의미합니다.
Analysis on Acoustic Variance Information
acoustic variance condition의 영향을 입증하기 위해, 저자들은 합성된 speech와 ground truth speech의 300개 pair를 가지고 similarity를 측정했습니다. pitch의 경우, pitch 분포의 moment (평균, 표준편차, 왜도, 첨도)를 계산하여 값들이 실제 음성의 값들과 얼마나 유사한지 분석했습니다. 결과는 다음과 같습니다.

저자들의 model의 output의 수치들이 가장 ground-truth와 유사한 것을 볼 수 있습니다. 즉 저자들의 model이 pitch 정확도가 높은 speech를 생성할 수 있음을 의미합니다.
energy의 경우, 저자들은 생성된 speech와 ground speech의 frame 별로 energy를 구해 mean absolute error (MAE)를 측정했습니다. 결과는 다음과 같습니다.
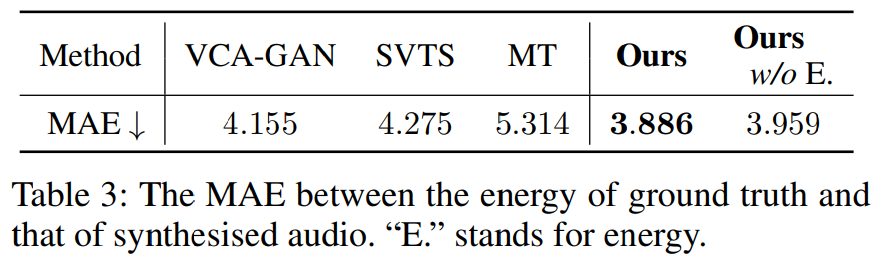
저자들이 제안한 model이 가장 낮은 error rate를 나타냅니다. energy predictor가 없는 경우, error가 증가했으며, error predictor가 효과가 있었다는 것을 볼 수 있습니다.
Analysis on Self-Supervised Features
SSL speech model의 중요성은 최근 연구들을 통해 입증되었으며, 중간 representation을 이용한 다양한 downstream task에 활용되는 연구들이 등장했습니다. 첫 번째 layer의 output을 이용해 speaker identity를 추출하는 연구가 있었고, middle layer를 이용해 linguistic representation을 추출하는 연구가 있었습니다. 특히, quantized linguistic representation을 사용할 때 K-mean의 cluster 수가 model 성능에 명확하게 영향을 준다는 것이 연구되었습니다.
optimal linguistic feature configuration을 찾기 위해, 저자들은 WER, CER을 계산하고 phoneme error rate를 계산했습니다. 1번째 layer, 12번째 layer, 24번째 layer를 이용해 실험을 진행했습니다. 그리고 continuous linguistic feature를 100, 200 cluster를 이용해 quantization 했습니다. 각 cluster들은 linguistic predictor의 target으로 사용됩니다. 실험 결과는 다음과 같습니다.
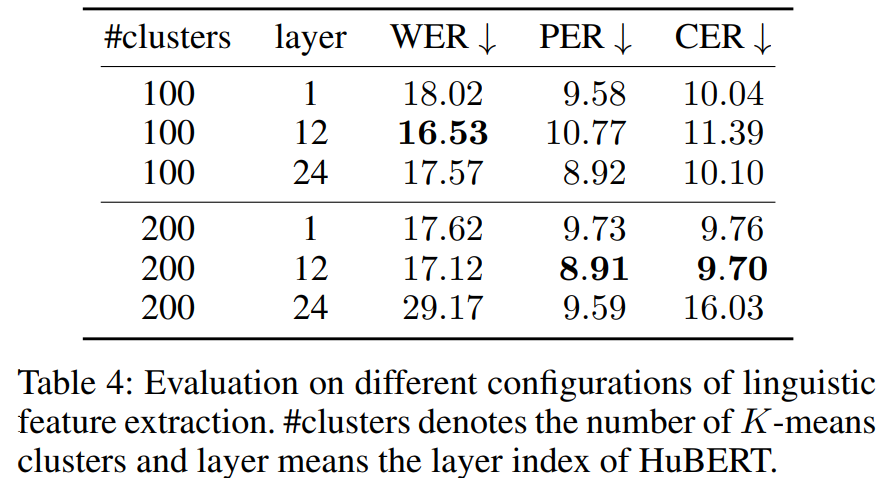
12번째 layer를 이용한 것이 가장 좋은 성능을 보여줍니다. 그중 200개 cluster를 사용하는 경우가 PER과 CER이 가장 좋게 나왔습니다. PER이 가장 낮은 경우가 가장 명확한 speech를 생성하기 때문에, 저자들은 200개 cluster와 12번째 layer를 사용했다고 합니다.
Conclusion
이 논문에서 저자들은 새로운 LTS system을 제안했습니다. 이는 자연스러움과 명확성에 있어 human-level quality와 유사한 speech를 생성할 수 있습니다. 저자들은 LTS의 내재된 one-to-many mapping 문제를 직접적으로 해결하고, linguistic information과 acoustic variance information을 제공하면서 문제를 해결했습니다. 그리고 modelling 능력을 향상시켜 생성된 speech를 더욱 정교화했습니다.



