https://arxiv.org/abs/2104.11178
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
We present a framework for learning multimodal representations from unlabeled data using convolution-free Transformer architectures. Specifically, our Video-Audio-Text Transformer (VATT) takes raw signals as inputs and extracts multimodal representations t
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
convolution을 사용하지 않는 Transformer architecture를 이용하여 unlabeled data로부터 multimodal representation을 학습할 수 있는 framework를 제안합니다. 구체적으로, 저자들의 Video-Audio-Text Transformer (VATT)는 raw signal을 input으로 받아서 다양한 downstream task에서 사용할 수 있는 multimodal representation을 추출합니다. 저자들은 multimodal contrastive loss를 사용하여 end-to-end 방식으로 VATT를 학습하고 vidoe action recognition, audio event classification, image classification, text-to-video retrieval과 같은 downstream task에 적용하여 성능을 평가했습니다. 나아가 저자들은 세 가지 modality가 weight를 공유함으로써 단일 backbone Transformer를 가지고 다양한 modality에서 동작하는 Transformer에 대한 연구를 진행했습니다. ConvNet-based architecture와 비교했을 때 저자들의 convolution-free VATT가 더 뛰어난 모습을 보여줍니다. VATT의 audio Transformer 또한 waveform based audio event recognition에서 뛰어난 성능을 보여줍니다.
Introduction
Transformer의 large-scale supervised train에는 문제가 존재합니다. 방대한 unlabeled, unstructured visual data를 배제합니다. 결과적으로 supervised training 방식은 편향된 system을 만들게 될 것이고 이를 해결하기 위해선 더 많은 labeled data가 필요합니다.
이 논문에서는 대규모 unlabeled visual data를 가지고 Transformer를 학습하는데, 어떻게 성능을 더 향상시킬지에 대한 연구를 진행합니다. 저자들은 자연어 처리 분야에서 영감을 받아 transformer 성능 향상에 대한 연구를 진행했습니다. BERT, GPT는 masked language modeling을 그들의 pre-training task로서 사용했습니다. 자연어는 Transformer에 유기적인 supervision을 제공합니다. visual data의 경우, 가장 유기적인 supervision을 제공해 주는 것은 multimodal video data입니다. video data는 풍부하게 존재하며 추가적인 human annotation을 필요로 하지 않습니다. multimodal video는 visual world를 model 하기 위해 필요한 사전 지식을 Transformer에게 가르칠 수 있는 잠재력을 가지고 있습니다.
이를 위해 3가지 self-supervised, multimodal pre-training transformer를 제안합니다. 각 trasnformer는 video에 존재하는 raw RGB frame, audio waveform, speech audio의 transcription을 input으로 받습니다. 각 transformer를 video, audio, text Transformer VATT라 부릅니다. 구조는 다음과 같습니다.
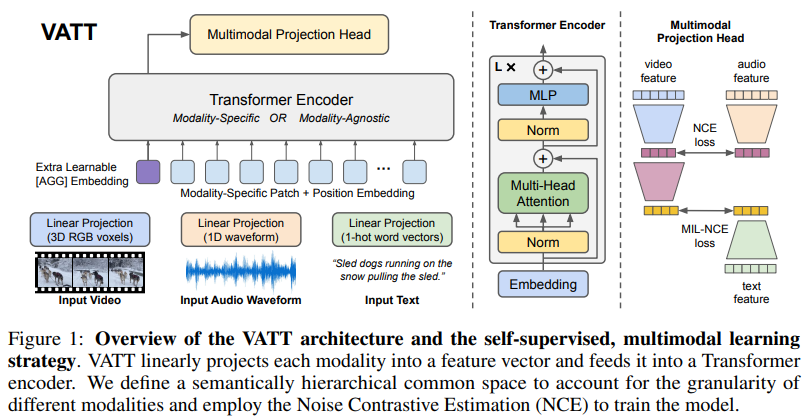
VATT는 각 modality에 대해 따로 tokenization layer와 linear projection을 적용하는 부분을 제외하면 BERT와 ViT의 구조를 가져와 사용합니다. 이 design은 최소한의 구조 변경으로 학습된 model이 다양한 framework와 각 task에 맞춰 weight를 trasfer할 수 있도록 설계된 ViT의 spirit을 공유합니다. 또한 self-supervised multimodal learning 방식은 BERT와 GPT의 spirit과 일치하는데, 이는 pre-training을 할 때 최소한의 human curated label이 필요하다는 spirit입니다.
더 나아가 저자들은 video, audio, text modality에 전부 동일한 weight를 사용하는 Transformer를 VATT에 적용시키는 연구도 진행합니다. single, general-purpose model을 모든 modality에 대해 평가를 진행하면 됩니다. 물론 각 modality에 맞춰 tokenlization과 linear projection layer를 사용하기는 합니다만, 이 modality-agnostic Transformer는 약간 작은 크기의 3가지 modality-specific model과 동등한 성능을 보입니다.
마지막으로 저자들의 또 다른 기여는 DropToken입니다. 이는 단순하지만 효과적인 기술로, 최종 Transformer의 성능이 아주 조금 감소하지만 학습 복잡도를 감소시킬 수 있습니다. DropToken은 학습 중에 각 input sequence로부터 얻은 audio token과 video의 일부를 랜덤하게 drop 하는데, 이를 통해 고해상도 input이 가능해지며, 많은 정보량을 사용할 수 있게 됩니다. Transformer 자체의 연산량이 많기 때문에 특히 효과적인 방법입니다.
Related Work
Trasformer in Vision
Transformer는 원래 자연어 처리 task에서 사용되었으며 단어들의 long-term correlation을 modelling하기 위해 multi-head attention을 사용했습니다. image super-resolution, object detection and multimodal video understanding과 같은 vision task에 Transformer를 사용하는 시도가 있었습니다. 하지만 이러한 method들은 CNN을 이용해 feature를 추출합니다. 최근에는 convolution을 사용하지 않는 vision Transformer가 등장했습니다. 이는 raw image를 바로 사용하고 CNN과 비교할만한 성능을 보여줍니다. 이와 같은 방식으로 pure Transformer가 다양한 방식으로 여러 vision task에 사용되고 있습니다. 저자들이 아는 한 저자들의 VATT가 raw multimodal input video, audio, text에 Transformer를 사용하는 첫 연구입니다.
Self-Supervised Learning
- Single vision modality
self-supervised visual representation learning의 초기 연구는 보통 auto-encoding, patch location prediction, solving jigsaw puzzle, image rotation prediction과 같이 unlabeled image를 이용해 학습합니다. 최근 contrastive learning trend는 data augmentation과 instance discrimination을 통합하여 image의 representation과 augmented view representation 사이의 일관성을 유지합니다. video domain에서는 시간적 신호를 pretext task로 활용하는 것이 자연스럽습니다. 예를 들어 future frame을 예측하거나 motion과 appearance의 통계를 구하거나 속도를 예측하거나 frame 또는 video clip을 sorting 하는 방식이 있습니다. 최근에는 시간적으로 일관성있는 spatial augmentation을 사용하여 contrastive learning을 video에 적용하기도 합니다.
- Multimodal video
video는 multimodal data의 natural source입니다. multimodal self-supervised learning은 video가 audio stream과 일치하는 지 예측하거나, cross-modality clustering 등을 통해 수행될 수 있습니다. 최근에는 contrastive loss를 사용하여 video, audio, text로 학습을 진행하고 narrow view에서 좀 더 긴 시간적 context를 아우르는 더 넓은 view를 예측하는 법을 학습합니다. VATT는 convolution-free Transformer와 multimodal contrastive learning의 장점들을 결합한 첫 연구입니다.
Approach
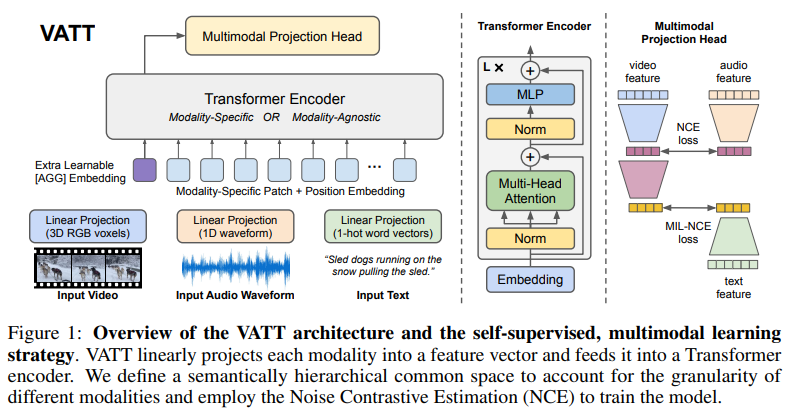
위 그림과 같이 각 modality를 tokenization layer에 feed합니다. raw input이 embedding vector로 project 된 다음 Transformer에 feed 됩니다. 2가지 주요 setting이 있습니다. 1) backbone Transformer는 분리되고 각 modality별로 weight가 존재하는 방식 2) Transformer가 weight를 공유하는 single backbone Transformer 방식이 있습니다. 두 setting 모두 backbone은 modality-specific representation을 추출한 다음 contrastive loss에 의해 서로 비교되는 common space로 mapping 됩니다.
Tokenization and Position Encoding
VATT는 raw signal을 사용합니다. vision-modality input은 video frame의 3-channel RGB로 구성됩니다. audio input은 air density amplitude (waveform) 형태이며, text input은 sequence of word입니다. 먼저 raw signal을 input으로 받는 modality-specific tokenization layer를 보겠습니다. 이 layer의 output은 Transformer의 input으로 사용됩니다. 각 modality는 각각에 맞춰 positional encoding을 가지고 있으며, 이는 Transformer에 token 순서를 inject해줍니다. 먼저 전체 T x H x W 크기의 video clip을 T/t x H/h x W/w 길이의 sequence of patch로 나눠서 사용합니다. 각 patch의 크기는 t x h x w x 3가 됩니다. 각 patch에 linear projection을 수행하여 d차원 vector representation을 얻습니다. 이 projection은 학습 가능한 weight W_vp ∈ R^(thw3d)에 의해 수행됩니다. 이 patch들의 position을 encode 하기 위해 저자들은 학습 가능한 embedding의 dimension-specific sequence를 정의합니다.
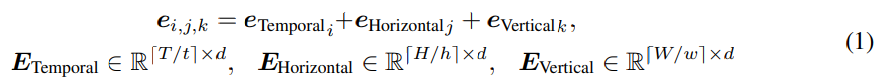
위 식에서 e_i는 E의 i번째 row를 의미합니다. video clip의 모든 patch를 encode하기 위해 positional embedding들을 더하면 됩니다(T/t + H/h + W/w). raw audio waveform은 T'길이의 1D input이며, 이는 [T'/t'] segment로 나눠지고 각각은 t'개의 waveform amplitude를 포함하고 있습니다. video와 유사하게 patch에 존재하는 모든 element들을 d차원 vectore representation을 얻기 위해, 학습 가능한 weight W_ap∈R^(t'd)를 사용하여 linear projection을 수행합니다. text의 경우에는 training dataset에 존재하는 모든 단어들에 대해 v 크기의 vocabulary를 구성합니다. 예를 들어 input text sequence가 있을 때, 각 단어를 v차원 one-hot vector로 mapping 한 다음 학습 가능한 weight W_tp를 사용하여 linear projection을 수행합니다.
- DropToken
학습 과정에서 연산 복잡성을 줄이기 위해 효과적이면서도 단순한 DropToken을 제안합니다. video나 audio modality에서 token sequence를 얻었을 때, token의 일부를 random하게 sample하여 전체 token set을 Transformer에 feed하는 대신 sampled sequence를 feed합니다. Transformer의 연산량은 quadratic O(N^2)이기 때문에(여기서 N은 input sequence의 token 수를 의미) 이와 같은 방법을 사용한다면 연산량을 효과적으로 줄일 수 있습니다. 이를 통해 train time을 바로 줄일 수 있고 제한된 hardware로도 학습을 진행할 수 있도록 도와줍니다. raw input의 resolution이나 dimension을 줄이는 대신 이와 같이 random하게 token을 sample하는 방식이 input에 대한 더 나은 high-fidelity를 유지할 수 있다고 합니다.
- The Transformer Architecture
단순화를 위해, 저자들은 자연어처리에서 많이 사용되는 Transformer architecture를 가져와 사용했습니다. ViT와 유사하게 저자들은 구조를 수정하지 않았으며 다른 Transformer로 쉽게 transfer 될 수 있습니다. Transformer의 input token sequence는 다음과 같습니다.

여기서 x_n은 input patch sequence를 의미하고 x_AGG는 special aggregation token의 학습 가능한 embedding입니다. special aggregation token은 모든 input token sequence의 정보를 요약해주는 token입니다. Transformer의 output인 z_out은 전체 input sequence에 대한 aggregated representation으로 사용됩니다. 이는 나중에 classification과 common space mapping에 사용됩니다. 저자들은 Multi-Head Attention (MHA) module을 sel-attention으로 사용했으며, GeLU를 MLP layer의 activation function으로 사용했습니다. 그리고 저자들은 MHA와 MLP 이전에 Layer Normalization을 적용했습니다. text model의 경우, 저자들은 position encoding e_pos를 제거하고 MHA module의 첫 layer의 attention score에 학습 가능한 상대적 bias를 추가합니다. 이러한 간단한 변화를 통해 저자들의 text model의 weight는 다른 text model로 바로 transfer할 수 있습니다.
Common Space Projection
저자들은 common space projection과 contrastive learning을 사용하여 저자들의 network를 학습합니다. 더 구체적으로 video-audio-text triplet이 주어졌을 때, 저자들은 의미론적인 hierarchical common space mapping을 정의합니다. 이 mapping은 video-audio, video-text pair를 cosine simlarity로 바로 비교할 수 있습니다. 각 modality가 서로 다른 level의 의미론적 세밀도가 있다고 가정했을 때, 더 실현 가능합니다.
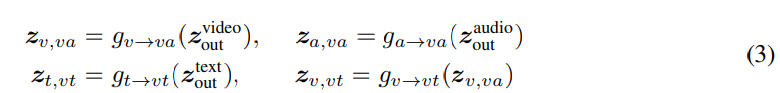
g_v-to-va는 video Transformer의 output을 video-audio common space S_va로 mapping하는 projection head를 의미하고 g_a-to-va는 audio Transformer의 output을 video-audio common space S_va로 mapping하는 projection head를 의미합니다. g_t-to-vt와 g_v-to-vt는 text Transformer의 output과 S_va에 있는 video embedding을 video-text common space S_vt로 mapping하는 projection을 의미합니다. 이러한 multi-level common space projection은 위 그림의 오른쪽 부분입니다. 이 계층의 주요 직관은 다음과 같습니다. 서로 다른 modality는 서로 다른 의미적 세밀도 level을 가지고 있을 것이고, 그렇기 때문에 이러한 의미적 세밀도 level 차이를 common space projection에서 유도된 bias로 적용해야 한다는 것입니다. 그래서 저자들은 g_a-to-va, g_t-to-vt, g_v-to-vt에 대해 linear projection을 사용하고 g_v-to-va에서는 2개 layer projection with ReLU를 사용했습니다. 학습을 용이하게 하기 위해, 저자들은 각 linear layer 뒤에 batch normalization을 적용했습니다.
Multimodal Contrastive Learning
저자들은 Noise Contrastive Estimation (NCE)를 사용하여 video-audio pair를 align했으며 Multiple Instance Learning NCE (MIL-NCE)를 사용하여 video-text pair를 align했습니다. video-audio-text stream에서 서로 다른 temporal location으로 pair를 구성합니다. 두 modality에서 얻은 positive pair는 video에서 동일한 location의 stream을 sampling함으로써 구성합니다. negative pair는 video에서 서로 맞지 않는 location의 stream을 sampling하여 구성합니다. common space을 고려할 때, loss는 다음과 같이 정의될 수 있습니다.
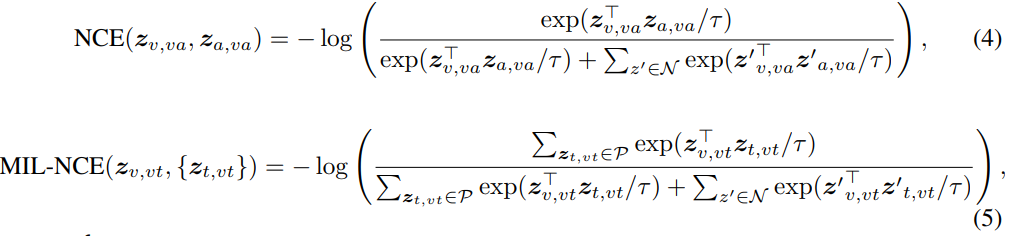
여기서 N은 batch에 있는 모든 non-matching pair를 포함합니다. (5) 식에서 P는 video clip과 시간적으로 가장 가까운 5개 text clip을 포함합니다. τ는 positive pair와 negative pair를 구분하는 objective의 softness를 조절하는 temperature입니다. 전체 VATT model을 end-to-end방식으로 학습하기 위해 각 sample마다의 objective는 다음과 같습니다.
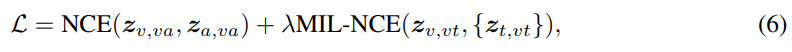
위 식에서 λ는 두 loss 사이의 균형을 위해 사용합니다.
Experiments
Experimental Setup
VATT를 pretrain하기 위해 AudioSet과 HowTo100M dataset을 결합하여 사용했습니다. 이때 HowTo100M 중에서는 YouTube 정책을 준수하기 위해 일부만 사용했다고 합니다. HowTo100M으로부터 video-audio-tex ttriplet clip을 얻어서 사용하지만 AudioSet dataset에서는 video-audio pair만 사용합니다. 저자들은 224x224 크기로 10fps에서 32개 frame을 sample하며, random crop, horizontal flip, color augmentation을 수행했습니다. audio waveform을 48kHz로 sample했습니다. video와 audio 둘 다 [-1, 1] 사이로 normalize했습니다. 저자들은 4x16x16 크기로 video tokenization을 수행하고 128 크기로 raw waveform tokenization을 수행했습니다. 그리고 text sequence를 encode하기 위해 one-hot vector를 사용했습니다. 모든 pre-training 실험에서, 저자들은 DropToken을 drop rate 50%로 설정하여 사용했습니다.
pre-trained VATT를 4개의 downstream task로 downstream했습니다. UCF101, HMDB51, Kinetics-400, Kinetics-600, Moments in Time을 videco action recognition을 위해 사용했습니다. ESC50, AudioSet은 audio event classification을 위해 사용했으며, YouCook2와 MSR-VTT를 사용하여 zero-shot text-to-video retrieval으로 video-text common space representation 성능을 평가했습니다. 마지막으로 ImageNet classification에 맞춰 finetuning하여 저자들의 vision backbone의 transferability를 평가했습니다. HMDB51, UCF101, ESC50은 network size에 비해 현저히 작은 dataset이기 때문에, 저자들은 fronzen pre-trained backbone 위에 linear classifier만 학습하는 데 사용되었습니다.
Results

위 표와 같이 저자들의 model이 video action recognition task에서 좋은 성능을 보이는 것을 볼 수 있습니다.

Table 2를 보면 알 수 있듯이 저자들의 model의 audio event classification 성능이 다른 model들보다 더 좋은 것을 볼 수 있습니다. 여기서 흥미로운 점은 modality specific VATT와 modality-agnostic backbone의 성능이 비슷하다는 점입니다. 저자들이 알기로는 VATT가 CNN 기반으로 audio event recognition을 수행하는 첫 model입니다.
multimodal video domain으로 pretrain된 model임에도 불구하고 학습된 지식을 다른 domain으로 transfer할 수 있습니다 (저자들의 경우 image classification을 수행하기 위해 knowledge transfer를 수행). 저자들은 VATT-BBS의 vision Transformer를 ImageNet으로 fine-tune했습니다. 이때 계층적 구조를 만족시키기 위해 input image를 4번 복제하여 network에 feed했습니다. Table 3와 같이 성능을 얻을 수 있었습니다. 처음부터 끝까지 학습하는 것보다 fine-tuning하는 것의 성능이 더 좋은 것을 볼 수 있습니다. 마지막 Table 4와 같이 zero-shot text-to-video retrieval 성능도 뛰어난 것을 볼 수 있습니다.
- Feature visualization
저자들의 modality-specific and modality-agnostic VATT를 Kinetics-400으로 fine-tuning한 다음 t-SNE를 사용하여 output feature representation을 visualize했습니다. 비교를 위해, 저자들은 Kinetics-400으로 처음부터 학습된 vision Transformer의 feature visualization도 비교했습니다.
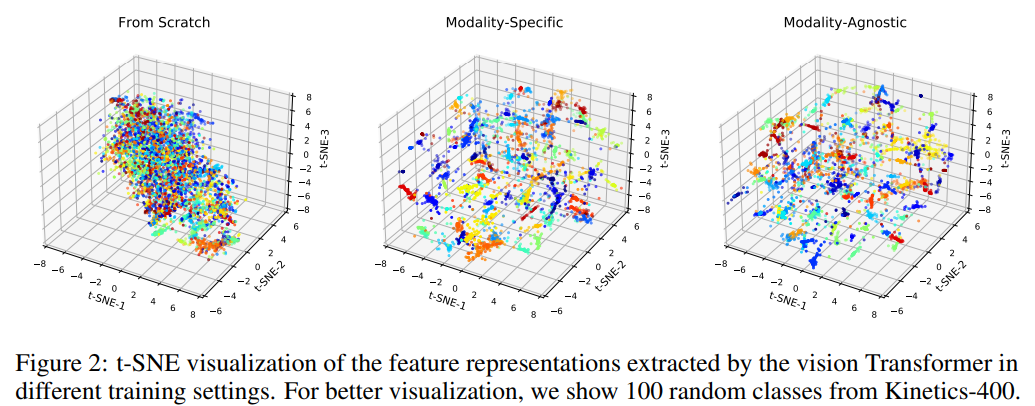
fine-tuend VATT는 처음부터 학습된 model보다 좀 더 잘 분리하는 것을 볼 수 있습니다. modality-agnostic feature와 modality-specific feature와 큰 차이가 없는 것을 볼 수 있습니다.
fine-tuninig 없이 VATT backbone에 대해 추가적인 연구를 진행했습니다. 저자들은 YouCook2 dataset에서 random하게 1k video clip을 선택한 다음 pre-trianed VATT model의 두 point에서 representation을 저장합니다. 하나는 tokenization layer 뒤 (Transformer의 input space)이고 또 다른 하나는 common space projection한 이후 (output space, loss가 계산되는 space)입니다.
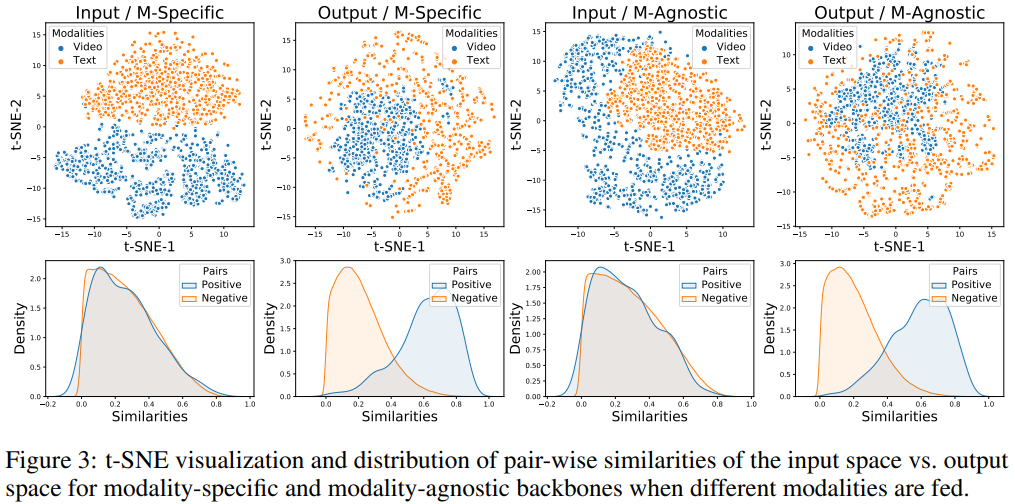
위 그림에서 위에 있는 그림을 보겠습니다. 이는 두 point에서 얻은 modality-specific representation, modality-agnostic representation을 visualize한 결과입니다. 흥미롭게도 modality-specific model과 비교했을 때 modality-agnostic setting의 결과가 약간 더 섞인 결과를 보여줍니다. 즉 modality-agnostic backbone이 다른 modality를 동일한 개념을 설명하는 다른 기호로 인식한다는 것을 의미합니다. 이는 여러 언어를 지원하는 NLP model과 유사한 결과입니다.
VATT가 얼머나 잘 positive video-text pair와 random하게 sample된 pair를 잘 구분하는지 확인하기 위해, 저자들은 pair-wise similarity를 계산한 후 Kernel Density Estimation (KDE)를 수행하여 positive pair와 negative pair의 distribution을 시각화했습니다. modality에 specific하거나 agnostic한 setting 모두 VATT의 output space에서 positive pair와 negative pair를 구분하는 것을 볼 수 있습니다. 즉 modality 간 backbone을 공유하더라도, VATT가 다른 modality에 대해 의미론적 common space를 효과적으로 학습하는 것을 의미합니다.
- Model Activations
저자들은 full multimodal input이 model에 feed 되었을 때의 modality-agnostic VATT의 average activation을 측정했습니다. 더 구체적으로 저자들은 HowTo100M의 test split에서 100k short video clip을 sample하고 model에 feed했습니다. 각 modality에 대해 MLP module의 output의 각 node의 average activation을 계산했습니다.
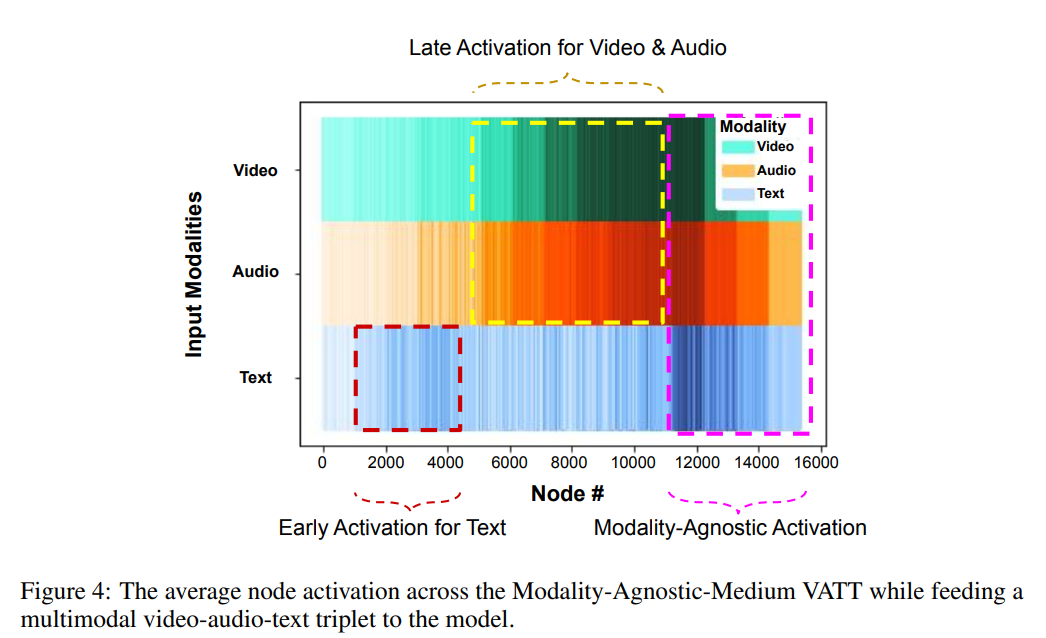
위 그림이 Medium-size model의 average activation across all node를 시각화한 모습입니다. text input의 경우 earlier node가 activate되는 것을 볼 수 있습니다. 다른 두 modality는 그것보다 좀 더 뒷부분에서 activate되며, network의 마지막 layer 부분에서는 모든 modality가 거의 동일하게 activate되는 것을 볼 수 있습니다. 이는 model이 특정 modality에 대해 다른 node들을 할당하면서 후반부 layer에서는 모든 modality에 대해 동일한 수준의 의미론적 인식을 달성하는 것이라고 볼 수 있습니다.
- Effect of DropToken

위 표와 같이 DropToken의 성능도 볼 수 있습니다. DropToken을 이용하여 high resolution input을 사용하면 low resolution input을 사용했을 때와 비슷하거나 좀 더 나은 성능을 보이는 것을 알 수 있습니다.
Conclusion and Discussion
이 논문에서는 Transformer based self-supervised multimodal representation learning framework를 제안합니다. Transformer가 semantic video/audio/text represenetation을 학습하는데 효과적임을 제안합니다. 그리고 multimodal self-supervised pre-training은 large-scale labeled data에 대한 의존성을 줄일 수 있는 유망한 방법임을 보입니다. 그리고 저자들은 DropToken이 상당히 pre-training complexity를 감소시킬 수 있음을 보입니다. 연산량은 줄이면서 model의 일반화에 미치는 영향은 적다는 것을 보여줍니다.
저자들의 method에는 몇 가지 limitation이 존재합니다. 모든 video가 자연스러운 audio나 speech를 포함하는 것은 아니며, 저자들의 model은 의미있는 multimodal correspondence에 의존한다는 문제가 있습니다. 그리고 text modality는 speech transcript로 구성되기 때문에 noisy하고 때로는 sparse합니다.
그래도 저자들의 method는 앞으로의 연구를 통해 개선할 수 있을 것이라고 말합니다.



