https://arxiv.org/abs/2302.08841
Lip-to-Speech Synthesis in the Wild with Multi-task Learning
Recent studies have shown impressive performance in Lip-to-speech synthesis that aims to reconstruct speech from visual information alone. However, they have been suffering from synthesizing accurate speech in the wild, due to insufficient supervision for
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
최근 연구들은 visual information만 가지고 speech를 reconstruct하는 Lip-to-speech synthesis에서 인상적인 성능을 보여주고 있습니다. 하지만 model이 올바른 내용을 추론하도록 유도하는 supervision이 충분하지 않아, 실생활에서 정확한 speech를 합성하는데 어려움을 겪고 있습니다. 이전 method와 다르게 이 논문에서는 실생활에서도 input lip movement로부터 정확한 content를 가진 speech를 합성할 수 있는 powerful한 Lip2Speech를 연구합니다. 이를 위해 저자들은 model이 multimodal supervision을 사용할 수 있도록 multi-task learning을 design합니다. 즉 text와 audio를 사용하여 acoustic feature reconstruction loss의 불충분한 word representation을 보완합니다. 따라서 저자들이 제안하는 framework는 여러 speaker에 대해 제약이 없고 올바른 문장을 말하고 있는 speech를 합성할 수 있다는 장점이 있습니다.
Introduction
visual information만 사용하는 speech reconstruction, speech recognition 연구가 계속되고 있습니다. 하지만 visual information (i.e., lip movement)에만 의존하기 때문에 speech에 대한 정보가 불충분하며 여전히 어려움을 겪고 있습니다. 특히 Lip to speech synthesis (Lip2Speech)로 알려진 video-driven speech reconstruction은 visual speech recognition에 비해 더 낮은 성능을 보여줍니다. 그래서 Lip2Speech는 speaker 수가 한정적이거나 문장들이 고정된 문법을 따르는 등 제한된 datset을 이용해 연구되고 있습니다. 하지만 visual speech recognition은 많은 speaker가 존재하는 wild dataset을 가지고도 크게 성능 향상을 이끌어냈습니다. Lip2Speech는 speech의 다양한 charateristic (e.g., voice, accent, intonation)을 고려하기 때문에 성능이 더 낮습니다. 그리고 Lip2Speech task에서 연속적인 audio representation의 reconstruction criteria가 visual speech recognition과 비교했을 때 불충분하기 때문에 성능 차이가 존재합니다. visual speech recognition의 경우 text의 discrete supervision으로 학습될 수도 있으며 speaker characteristic을 고려할 필요도 없습니다.
이와 같이 Lip2Speech와 visual speech recognition 사이의 성능 차이를 줄이기 위해, 이 논문에서 저자들은 wild environment에서도 정확하게 spoken word를 capture할 수 있는 powerful Lip2Speech method를 연구합니다. 이를 위해 저자들은 content supervision을 가지고 text를 예측하고 acoustic feature를 예측하도록 학습하는 multi-task learning method를 제안합니다. 이를 통해 저자들은 제안된 content supervision을 통해 acoustic feature reconstruction에서 불충분한 content guidance를 보완할 수 있습니다. 구체적으로 저자들은 두 가지 content supervision을 제안합니다: feature- and output- level. feature-level content supervision의 경우, Connectionist Temporal Classification (CTC) loss를 이용하여 model이 acoustic feature를 합성하기 전에 input visual representation에 align된 text를 예측하도록 학습됩니다. 따라서 저자들은 visual input과 audio output 사이의 어떠한 alignment 손실 없이 strong text supervision을 Lip2Speech에 부여할 수 있게 됩니다. output-level content supervision의 경우, 저자들은 Automatic Speech Recognition (ASR) model을 사용하여 model이 정확한 단어를 포함한 speech를 합성할 수 있도록 도와줍니다. 제안된 content supervision과 함께 model은 연속적인 청각적 feature에 적용된 reconstruction loss에 의해 guide되어 multi-task 학습을 형성합니다. 저자들이 제안한 framework를 통해 수백 명의 speaker가 다양한 sentence를 말하고 있는 wild dataset의 visual information을 가지고도 고품질의 speech를 합성할 수 있습니다.
Method
X = {x_1, ... , x_T} ∈ R^(T x H x W x C)를 lip movement를 포함하고 있는 input video라고 하고 Y = {y_1, ... , y_S} ∈ R^(K x S)를 mel-spectrogram으로 구성된 ground-truth speech의 acoustic feature라 하겠습니다. 그리고 U = {u_1, ... , u_L} ∈ R^L을 L개 token으로 구성된 utterance의 ground-truth transcription이라 하겠습니다. 여기서 T는 frame length를 의미하고 H는 frame height, W는 frame widht, C는 frame channel size을 의미합니다. K는 mel-spectral channel이고 S는 sequence length를 의미합니다. 그리고 L은 transcription의 length를 의미합니다. 저자들의 main goal은 speaker 수나 sentence에 대한 constraint 없이 input lip video X를 적절한 speech Y로 변환하는 것입니다. 이를 위해 content supervision을 사용하는 text prediction과 reconstruction supervision을 사용하는 acoustic feature를 포함하는 multi-task에 대하여 model을 guide합니다. content supervision의 경우, 저자들은 feature- and output-level의 두 가지 supervision을 사용합니다. 전체 구조는 다음과 같습니다.

Feature-level content supervision
lip movement만 보고 speech를 합성하기 위해서는 사전에 올바른 발화 단어를 예측하는 것이 중요합니다. 하지만 대부분의 이전 연구들은 예측된 acoustic representation과 ground-truth acoustic representation (e.g., MFCC or mel-spectrogram) 사이의 reconstruction loss에만 의존합니다. text의 discrete feature와 달리, 같은 단어도 화자의 speaker characteristic, tone, accent 등에 따라 acoustic representation은 달라질 수 있습니다. 그래서 Lip2Speech에서 continuous acoustic feature를 위해 reconstruction loss만 사용하는 것은 network가 silent talking face video로부터 올바른 단어를 예측하는데 불충분한 guide를 제공합니다. 이러한 문제를 해결하기 위해, 저자들은 Connectionist Temporal Classification (CTC) loss를 이용한 추가적인 discrete text modality를 사용했습니다. CTC loss는 network가 올바른 단어를 예측할 뿐만 아니라 aligned representation도 생성하는 데 guide를 제공하기 때문에 visual-audio synchronization가 유지되어야만 하는 Lip2Speech task에서는 적절합니다.
input video X의 frame은 CNN-based visual front-end Φ_v를 이용해 embed되고 temporal relationship은 conformer Φ_c에 의해 modelling됩니다. 식으로 나타내면 다음과 같습니다.

final encoded visual representation F = {f_1, ... , f_T} ∈ R^(T x D)는 text prediction과 speech prediction 모두에 사용되며 D는 embedding size입니다. text prediction p = Softmax(FW_ctc + b_ctc)는 CTC loss로 guide됩니다. CTC loss는 L_ctc(p, U)로 정의되고, W_ctc ∈ R^(D x N)은 text prediction의 weight이고 b_ctc ∈ R^N는 text prediction의 bias입니다. N은 class 수를 의미합니다. feature-level content supervision을 통해 visual representation F는 input visual speech의 올바른 단어를 포함할 수 있으며 결과적으로 output acoustic feature로 변환됩니다.
Output-level content supervision
speech를 합성하기 전에 CTC loss를 사용하는 것은 model이 올바른 단어를 학습하도록 model을 명시적으로 guide하는 것입니다. 추가적으로 저자들은 output level에 맞는 content supervision도 부여합니다. 이를 위해 저자들은 text annotation이 없을 때도 model이 정확한 content 를 modelling하는데 초점을 맞추도록 guide하는 feedback network를 제안합니다. 합성된 speech가 올바른 단어를 포함하고 있는지 아닌지를 확인하기 위해 pre-trained ASR model를 사용합니다. 합성된 speech의 content representation Z'와 Y'는 last classification layer 이전에 ASR model을 통해 추출됩니다. 그러고 난 후 content representation Z'는 ground-truth speech Y로부터 추출된 ground-truth content representation Z와 유사해지도록 guide됩니다. 식으로 나타내면 다음과 같습니다.

이를 통해 model은 feedback model의 도움을 받아 output의 content를 더 정확하게 modelling하는데 focusing할 수 있게 됩니다. 그리고 output-level content supervision이 어떠한 text annotation을 필요로 하지 않기 때문에 text annotation을 사용하지 못하는 경우에도 output-level content supervision을 사용할 수 있습니다.
Lip-tp-Speech synthesis in the wild
이전 연구들과 다르게 speaker characteristic을 제공해주는 speaker embedding을 speech synthesizer바로 이전에 배치하여 front model (i.e., visual front-end and conformer)가 speech content를 modelling하는 데 더 집중하도록 만들었습니다. speaker characteristic을 final output speech로 적절히 embed하기 위해 저자들은 1D CNN layer로 구성된 deeper speech synthesizer를 사용했습니다.
Speech Synthesizer ψ로부터 visual feature F를 이용해 acoustic feature를 생성합니다. generation은 다음과 같은 reconstruction loss를 통해 guide됩니다.

정의된 세 가지 loss function을 weighted sum하여 제안된 multi-task learning을 위한 objective fuction을 정의할 수 있습니다. network를 multimodal supervision을 이용하여 guide함으로써 합성된 speech는 content supervision을 통해 정확한 content를 포함할 수 있습니다. 안정적인 학습을 위해 저자들은 학습 초기에는 L_asr의 weight를 0으로 두었고 reconstruction loss가 충분히 떨어지고 난 후에 해당 output-level content supervision의 weight를 키웠습니다.
Experiments
Architectural details
visual front-end의 경우, ResNet18의 첫 layer만 3D convolution으로 수정해서 사용했습니다. conformer의 경우, LRS2와 LRS3로 학습할 때는 12개 layer, 8개 head, convolution kernel size를 31로 설정하여 사용했습니다. LRW를 사용할 때는 6개 layer가 있는 conformer를 사용했습니다. speech synthesizer의 경우, 1D convolution의 hidden dimension을 256, 128, 320으로 설정하여 사용했으며, kernel size는 7입니다. 1D convolution의 hidden dimension이 128, 256, 256으로 설정하고 kernel size를 7로 두어 random short clip에서 speaker embedding을 추출했습니다. LRW의 경우 0.2초 random audio clip을 사용했으며 LRS2와 LRS3는 0.5초 random audio clip을 사용했습니다. 이전 연구들은 pre-trained speaker verification model을 사용하여 speaker embedding을 추출했었습니다. LRS2와 LRS3 dataset의 경우 pre-trained ASR model은 CTC loss를 사용하여 학습했으며, ASR model은 4개 head를 가진 6개 conformer encoder로 구성됩니다. LRW dataset의 경우 temporal average pooling과 cross entropy loss를 사용했습니다.
Ablation study
저자들의 method에 있는 각 component들을 baseline인 SVTS에 추가하면서 효과를 확인했습니다. 저자들은 LRS2 dataset을 사용해서 wild environment에서의 효율성을 입증했습니다. 결과는 다음과 같습니다.

baseline model의 WER은 93.91%이며, baseline model이 정확한 content를 가진 speech를 생성하는 데 어려움을 겪고 있다는 것을 의미합니다. feature-level content supervision (+ Feature-level C.S)를 추가함으로써 저자들은 WER를 17.51% 향상시켰습니다. 추가적으로 speech synthesizer를 deeper architecture (+ Conv1D)를 추가하고 speaker embedding(+ Speaker Embedding)을 inject하는 위치를 변경했더니, WER 성능은 향상되어 68.80%가 되었습니다. 마지막으로 output-level content supervision (+ Output-level C.S)를 추가하였더니 최종 60.54%까지 성능이 향상되었습니다.
Comparisons with previous methods
여러 명의 speaker가 녹음한 다양한 utterance로 구성된 large-scale audio-visual dataset인 LRS2와 LRS3를 사용하여 이전 method들과 성능을 비교했습니다. LRS dataset과 같이 wild sentence-level dataset을 이용하여 WER를 측정하는 이전 연구들이 존재하지 않았기 때문에, VCA-GAN과 SVTS를 LRS2로 학습한 다음 WER를 측정했습니다. 결과는 다음과 같습니다.
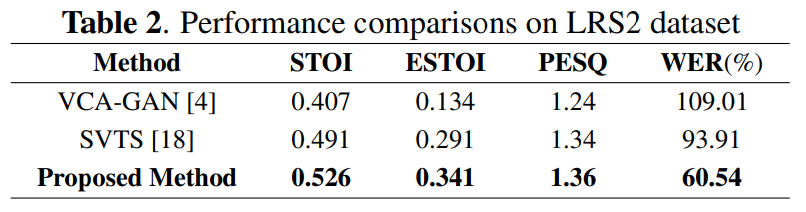
VCA-GAN, SVTS와 비교했을 때, 저자들의 method가 가장 좋은 WER와 PESQ를 달성하면서 정확한 단어를 포함하는 speech를 합성하는 것을 볼 수 있습니다.
Conclusion
이 논문에서 저자들은 wild 환경에서도 잘 동작하는 powerful Lip2Speech framework를 제안합니다. 이를 위해 저자들은 multi-task content learning을 수행했습니다.



