https://arxiv.org/abs/2403.08764
VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
We propose VLOGGER, a method for audio-driven human video generation from a single input image of a person, which builds on the success of recent generative diffusion models. Our method consists of 1) a stochastic human-to-3d-motion diffusion model, and 2)
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 VLOGGER를 제안했습니다. 이는 사람에 대한 단일 input image를 가지고 주어진 audio에 맞춰 video를 생성하는 method입니다. 저자들은 diffusion method를 이용해 구현했습니다. method는 다음을 이용해 구성됩니다. 1) stochastic human-to-3d-motion diffusion model 2) spatial & temporal control을 이용해 text-to-image model을 증강하는 새로운 diffusion based architecture로 구성됩니다. 이 method는 다양한 length의 고품질 video를 생성할 수 있으며 사람의 얼굴과 몸의 high-level representation을 통해 쉽게 controllable 할 수 있습니다. 이전 연구들과 다르게 저자들의 method는 각 person에 대한 training을 필요로 하지 않으며, face detection과 cropping에 의존하지 않은 채로 얼굴이나 입술뿐만 아니라 전체 image를 생성할 수 있습니다. 그리고 저자들은 3d pose and expression annotation을 가지고 있는 새롭고 다양한 dataset인 MENTOR를 제안합니다.
Introduction
text나 audio, 1개 사람 image를 기반으로 말하고 움직이는 사람 video를 자동으로 생성할 수 있는 method인 VLOGGER를 제안합니다. VLOGGER는 audio와 animated visual representation을 갖춘 multi-modal interface입니다. 복잡한 얼굴 표정과 점점 더 많은 신체 동작을 feature로 사용하여 사람 사용자와 자연스로운 대화를 지원하도록 설계된 conversation agent입니다. VLOGGER는 발표, 교육, 내레이션, 저대역폭 online communication, text 전용 HCI interface로 사용될 수 있습니다. 이 논문에서는 추가적인 video editing task의 potential도 설명합니다.
multi-modal, photorealistic human synthesis는 data 수집, 자연스러운 얼굴 표정 연출, 표정과 얼굴의 동기화, 가림 현상 및 전신 움직임을 표현하는 것 때문에 복잡합니다. 특히 single image만 주어졌을 땐 더 복잡합니다. video에서 입 영역만 편집하는 방식으로 lip sync를 맞추는 것에 매우 focus하는 방식으로 연구가 진행되었습니다. 최근에는 audio로 face motion을 예측함으로써 단일 image로 말하는 head video를 생성하기 위해 face reenactment 기술을 사용합니다. 시간적 일관성을 위해 주로 얼굴의 key point에서 부드러운 움직임에 의존하여 frame별 image를 생성하는 network를 사용합니다. 하지만, blurriness를 유발하기도 하고 얼굴에서 거리가 먼 영역의 시간적 일관성을 보장하지 않습니다. 그래서 대부분의 method들은 머리 부분을 detect하고 crop하는 방식을 사용합니다. 이 논문에서 저자들은 communication이란 audio와 lip and face motion을 결합하는 것 이상이라고 주장합니다 - 인간은 gesture, gaze, blink pose 등 몸을 이용해 communicate합니다.
최근에 MODA는 face와 body 둘 다에 대한 animation을 연구했습니다. 하지만 MODA는 제한된 scenario에서만 동작하며 새로운 identity에 대해선 일반화 성능을 보이지 못했습니다. 저자들의 method는 머리와 손 gesture를 포함한 동작의 현실성과 다양성에 focusing하여 정체성이나 자세에 제한받지 않는 일반적인 synthesis solution을 목표로 합니다.
저자들의 goal을 위해, 2 step approach를 사용합니다. 먼저, input audio signal에 맞춰 body motion과 facial expression을 예측하는 generative diffusion based network를 사용합니다. 이 stochastic approach는 speech를 pose, gaze, expression 간의 미묘한 one to many mapping을 modelling하는 데 필요합니다. 그다음 최근 image diffusion model 기반 새로운 architecture입니다. 이 architecture는 temporal and spatial domain에서의 control을 제공합니다. 저자들의 architecture가 일관된 human image를 생성하는 데 어려움을 겪는 image diffusion model의 성능 향상을 이끌어낸다는 것을 보였습니다.
VLOGGER는 high quality video를 얻기 위해 super-resolution diffusion model을 기반으로 합니다. 저자들은 이전 연구들처럼 얼굴 표정을 포함하여 신체 전체를 나타내는 2D condition을 사용하여 video를 생성합니다. 임의 길이의 video를 생성하기 위해 저자들은 이전 frame을 기반으로 하는 새로운 video clip을 condition으로 만드는 temporal outpainting 방식을 사용합니다. 마지막으로 VLOGGER의 flexibility는 입술 영역이나 얼굴 영역과 같은 input video의 일부 part를 수정할 수 있습니다.
강건함과 일반화 성능을 위해 저자들은 이전에 사용 가능했던 data들보다 더 많은 다양한 feature (피부 톤, 신체 자세, 시점 등)를 가지고 있는 large-scale dataset을 curate합니다. 이전 연구들과 대조적으로 dataset은 dynamic한 손 움직임을 포함하며, 이는 human communication의 복잡성을 배우는 데 중요합니다. VLOGGER는 이전 연구들보다 다양한 측면에서 더 뛰어난 결과를 보여줍니다.
요약하자면 저자들의 contribution은 다음과 같습니다.
- VLOGGER은 주어진 input speech에 맞춰 말하고 움직이는 사람을 만들어 낸 첫 연구입니다.
- MENTOR라는 다양하고 curate된 dataset을 사용하며, 저자들의 model을 학습하고 test할 때 사용했습니다. 이 dataset은 현재 존재하는 dataset보다 더 많은 양의 data를 가지고 있습니다.
- 저자들의 method가 기존의 diffusion based model보다 더 뛰어난 controlled video generation 성능을 보인다는 것을 ablation study로 증명했습니다.
- VLOGGER는 3가지 public benchmark에서 SOTA보다 더 뛰어난 결과를 보입니다.
- VLOGGER가 더 낮은 편향을 보이며 baseline을 능가하는 다양성 분석을 수행합니다.
- VLOGGER는 video를 편집할 수 있습니다.
Method
저자들의 goal은 실제 같은 머리 움직임과 gesture를 취하는 다양한 길이의 photorealistic target human talking video V를 생성하는 것입니다. 저자들의 framework인 VLOGGER는 다음과 같습니다.

VLOGGER는 two-stage pipeline입니다. 이는 speech to video인 one-to-many mapping을 수행하는 stochastic diffusion model을 기반으로 합니다. 첫 network는 sample rate가 S인 audio waveform a ∈R^NS를 input으로 받습니다. 여기서 target video length인 N에 맞춰 얼굴 표정과 3D pose와 같이 중간 body motion control C를 생성합니다. 그다음 network는 temporal image-to-image translation model입니다. 이는 대응하는 frame을 생성하기 위해 예측된 body control을 받아서 image-to-image translation을 수행합니다. 이 model로 저자들은 large image diffusion model을 사용했습니다. 특정 identity에 맞춰 이 과정을 condition하기 위해, network는 reference image를 받습니다. VLOGGER를 새롭게 소개된 MENTOR dataset을 이용하여 학습했습니다.
Audio-Driven Motion Generation
- architecture
저자들의 pipeline의 첫 network는 input speech를 기반으로 motion을 예측하도록 design됩니다. 저자들은 input을 waveform으로 변환하는 TTS model을 통해 input text를 처리합니다. 그리고 결과 audio를 Mel-spectrogram으로 표현합니다. M은 temporal dimension에 4개 multi-head attention layer를 가진 transformer architecture를 기반으로 합니다. 저자들은 frame 수와 diffusion step에 대한 position encoding을 포함하고 input audio와 diffusion step에서 embedidng MLP를 사용합니다. 각 frame에서 저자들은 causal mask를 사용하여 model이 이전 frame에만 attend할 수 있도록 만들었습니다. model은 매우 긴 sequence도 생성할 수 있도록 만들기 위해 variable length video를 사용해 학습했습니다.
저자들은 추정된 statistical and expressive 3D body model의 parameter에 의존하여 합성된 video의 중간 control representation을 생성합니다. 이러한 model들은 facial expression과 body motion 둘 다 고려하는데, 더 표현력 있고 다양한 gesture를 가진 human synthesis를 가능하게 만들어줍니다. 저자들은 face와 body parameter를 예측하기 위해 motion generation network를 사용했습니다. M(a_i) = {θ_i^e, Δθ_i^b}에서 θ_i^e는 face parameter이며 θ_i^b는 body parameter이고, frame i에서의 input audio a_i를 가지고 구해집니다. 구체적으로는 model이 θ_i^e를 생성하고 residual body pose θ_i^b을 생성합니다. displacement (i.e., Δθ_i^b)를 예측함으로써 model이 target subject에 대한 input image와 reference pose θ_ref^b를 받아 1≤i≤N frame에서 사람을 상대적으로 animation화 (θ_i^b= θ_ref^b + Δθ_i^b) 할 수 있게 합니다. 기하학적 domain에서 사람의 identity는 body shape code를 이용해 modelling됩니다. train과 test에서 저자들은 parametric body model을 input image에 fitting함으로써 얻어지는 estimated 3D shape parameter를 사용합니다. CNN기반 architecture를 가지고 2D / 3D prediction을 사용하기 위해서, model이 예측된 θ_i^e, θ_i^b parameter를 사용하여 model의 pose를 잡았습니다. 그다음 pose를 취한 body의 vertex position을 dense reprensentation으로 rasterize (3D를 2D로)해서 dense mask C를 얻었습니다. 그리고 몸의 semantic region을 rasterize하였습니다. 여기서는 semantic class N_c에 맞춰서 rasterize했습니다. 즉 예측한 parameter를 이용해 3D posed body를 구한 다음 2D로 변환했습니다. 그 다음 2D에서 body의 sematic region을 따로 구했습니다.
이전 face reencatment 연구들은 종종 warped image를 사용하기도 했습니다. 하지만 human animation을 위한 diffusion-based architecture들은 warped image를 사용하지 않습니다. 저자들은 이 두 representation 사이의 간극을 줄이고 warped image를 generative process의 guide로 사용하여 network의 task를 용이하게 만들고 identity를 유지하는 데 도움을 줄 수 있도록 만들었습니다. 저자들은 reference image에서 각 신체 vertex에 pixel color를 할당하고 각 신체를 렌더링하여 부분적인 warped image를 얻습니다. 위 그림과 같이 reference pose에서 색이 구분된 것을 볼 수 있습니다.
- Loss function
이 model은 점진적으로 Gaussian noise를 ground-truth sample에 더하는 diffusion framework를 사용합니다. 진짜 머리와 몸의 움직임 분포를 model하는 것이 목표입니다. 이를 수행하기 위해 noisy input으로부터 추가된 noise를 예측하는 denoising network를 학습하는 방식으로 움직임 분포를 modelling할 수 있습니다. 저자들의 경우 noise의 분포를 예측하는 대신 ground-truth 분포를 바로 예측함으로써 더 나은 성능을 얻을 수 있었다고 합니다.
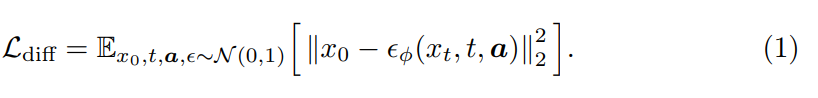
저자들은 연속 frame에서 prediction 차이에 penalty를 부여하기 위해 추가적인 temporal loss를 사용했습니다.

식으로 나타내면 위와 같습니다. 실제로 저자들은 머리와 손의 부드러운 움직임을 보장하면서 얼굴 표현의 더 큰 역동성을 허용하기 위해 facial expression과 head에 서로 다른 가중치의 temporal loss를 적용했다고 합니다.
Generating Photorealistic Talking and Moving Humans
- architecture
input image I_ref를 animate하게 만들어서 이전에 예측된 body and face motion을 따르도록 만드는 것이 goal입니다. 이러한 image-based control을 바탕으로, 저자들은 최신 diffusion model의 temporally aware extension을 제안합니다. ControlNet에서 영감을 받아, 저자들은 학습된 model의 initial을 freeze합니다. 그리고 그 model의 encoding layer의 0으로 초기화된 학습가능한 복사본을 만듭니다. 이 복사본은 input temporal controls C를 받습니다. 저자들은 각 downsampling block의 첫 layer 뒤와 두 번째 GroupNorm activation 전에 temporal domain 1d convolutional layer를 끼워 넣습니다. networks는 N개의 연속된 frame과 control을 받아서 학습되며, input control의 맞춰서 reference person을 animate하는 짧은 clip을 만듭니다.
Conclusion
저자들은 VLOGGER라는 method를 제안합니다. 이는 single input image와 audio 또는 text를 condition으로 주어졌을 때, 그에 맞는 face and body를 포함하는 human video synthesis를 수행하는 method입니다. VLOGGER는 control-based diffusion model의 temporal extension을 기반으로 하며, 고품질의 다양한 길이의 animation을 생성할 수 있도록 3d human head와 body pose를 기반으로 합니다.



