https://arxiv.org/abs/2005.08209
Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
Humans involuntarily tend to infer parts of the conversation from lip movements when the speech is absent or corrupted by external noise. In this work, we explore the task of lip to speech synthesis, i.e., learning to generate natural speech given only the
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
speech가 없거나 외부 noise때문에 손상될 때, 사람은 무의식적으로 입술의 움직임을 통해 대화의 일부를 추론하는 경향이 있습니다. 이 논문에서 저자들은 입술 모양을 통해 speech를 합성하는 task에 대해 연구합니다(speaker의 입술 움직임만 주어지고, 그에 맞는 자연스러운 음성을 생성하기). 정확하게 입술 움직임을 읽기 위해서는 문맥적 단서와 speaker 특정 단서가 중요하며, 저자들은 그에 맞춰 현재 존재하는 연구들과 다른 방향을 제안합니다. 저자들은 제한이 없는 대규모 단어 setting에서 각 speaker들의 lip sequene를 speech로 mapping하는 것에 대한 학습에 초점을 맞춥니다. 이를 위해 저자들은 large-scale benchmark dataset을 collect하고 공개했습니다. 저자들은 이러한 unconstrained scenario에서 natural lip을 speech로 합성하는 첫 연구입니다.
Introduction
아기들은 말하는 것을 배우기 시작할 때 사람의 입술 움직임을 적극적으로 관찰합니다. 성인이 되면, 매우 noise가 심한 환경에서 시각적으로 듣기 위해 입술 움직임에 매우 집중합니다. 입술 움직임은 많은 양의 speech information을 담고 있습니다. 자연스럽게 '화자의 입술 움직임을 관찰함으로써 model이 해당 화자의 말을 음성으로 만들 수 있지 않을까?' 라는 질문이 발생하게 됩니다. 이러한 model을 학습하기 위해서는 사람들이 말하는 동영상만 필요하며 추가적인 수동 annotation 작업이 필요하지 않습니다.
입술 움직임만 가지고 speech를 추론하는 것은 상당히 어려운 task입니다. 청각적으로 구별되지만 입술 모양은 비슷한 phoneme들이 있기 때문입니다(homophenes problem). 예를 들어 phoneme /p/ (park)를 발음할 때 입술 모양은 /b/ (bark)와 /m/ (mark)와 매우 혼동될 수 있습니다. 영어의 경우, 25%에서 30%만이 입술 모양만으로 식별할 수 있습니다. 즉 입술 모양을 읽는 것 뿐만 아니라 다른 information들이 필요하다는 것을 의미합니다. 예를 들어 speaker가 선호하는 대상, 어떤 topic으로 말을 하고 있는지, 얼굴 표현, 머리 움직임, 언어 지식 등 다양한 정보들이 필요합니다.
하지만 이와 대조적으로 입술 움직임으로 speech를 생성하거나 입술 움직임으로 text를 생성하는 현대 연구들은 다른 접근방식을 취하고 있습니다.
입술 모양으로 text를 만드는 최근의 연구들은 수천 명의 speaker가 말하고 있는 unconstrained, 대규모 단어 dataset을 사용하여 학습을 진행합니다. 하지만 이러한 dataset들은 각 speaker에 대해 2분 정도만 말을 하며, 이는 speaker에 맞는 modeling을 하기엔 불충분합니다.
이 논문에서 저자들은 입술 모양을 speech로 합성하는 문제를 특정한 관점으로 연구합니다. 청각 장애인 또는 입모양을 읽는 전문가들은 자주 상호작용하는 사람들의 입모양을 읽는 것이 더 쉽다는 사실에서 영감을 받아 연구를 진행했습니다. 따라서 random speaker의 입술 모양을 speech로 만드는 대신, 특정 speaker의 speech pattern을 단순히 장기간 관찰함으로써 학습하는 것을 초점으로 맞췄습니다.
저자들은 5명 speaker가 unconstrained setting에서 자연스러운 speech를 녹음해서 얻은 120시간 video dataset을 모았으며, 공개했습니다. 저자들의 Lip2Wav datset은 현재 존재하는 multi-speaker dataset에 비해 한 speaker 당 800배 더 많은 발화 시간을 포함하고 있으며, 이를 통해 특정 화자에 대한 audio-visual 단서에 대한 정확한 modelling이 가능해집니다. 그리고 저자들의 dataset은 기존 dataset의 single speaker가 말하는 단어보다 100배 더 많은 단어를 말을 합니다. 저자들이 아는 한, 저자들의 dataset이 unconstrained setting에서 입술 모양으로 speech를 합성하기 위해 공개된 유일한 large-scale benchmark라고 합니다. 이러한 dataset의 도움을 받아 저자들은 Lip2Wav을 개발했습니다. 이는 주어진 speaker의 입술 움직임을 자연스러운 speech로 match하여 정확하고 자연스러운 speech를 만들 수 있는 model입니다. 저자들의 key contribution은 다음과 같습니다.
- 저자들은 large vocabulary, unconstrained setting을 사용하여 slient lip video로 speech를 생성하는 첫 연구입니다.
- 저자들은 Lip2Wav dataset을 제안했습니다. 이를 이용해 각 speaker에 맞춰 입술 모양으로 speech를 정확히 합성할 수 있습니다. head pose나 sentence length와 같은 제약 없는 자연스러운 setting에서 speech를 생성할 수 있습니다.
- 저자들의 sequence to sequence modeling approach는 이전 연구에 비해 4배 정도 더 명료한 speech를 생성합니다. 사람들이 듣기에도 풍부한 prosody를 가진 훨씬 자연스러운 speech를 생성할 수 있었다고 합니다.
Related Work
Lip to Speech Generation
초기에는 sensor나 active appearance model을 통해 얻은 visual feature를 추출하는 방식으로 이 문제를 해결했었지만, 최근 연구들은 end-to-end approach를 사용합니다. Vid2Speech와 Lipper는 주어진 짧은 K개(K<15)의 frame으로부터 low-dimensional LPC (Linear Predictive Coding) feature를 생성합니다. 얼굴 frame은 channel-wise하게 concatenate 되고 2D-CNN을 이용해 LPC feature를 추출합니다. 저자들은 model이 머리 움직임, 침묵, 많은 양의 단어와 같이 real-world talking face video가 포함하는 특징들을 modelling하기에 부적합하다고 생각합니다. 그리고 이 연구들에서 사용되는 low dimensional LPC feature들은 speech information이 상당히 부족하기 때문에 강건한 speech를 생성할 수 없으며 기계적인 음성을 생성합니다.
Vid2Speech의 후속 연구는 LPC feature를 사용하지 않고 high-dimensional mel-spectrogram을 사용하는 optical flow network가 명시적으로 입술 움직임에 의존하도록 만들었습니다. 이러한 방식은 머리 움직임이 없는 GRID corpus에서는 효과적일지라도, optical flow는 unconstrained setting에서는 좋지 않습니다. 또 다른 연구는 GAN을 이용해 생성된 음성의 speech quality를 향상시켰습니다. 하지만 이 두 연구들 모두 TTS에서 사용되는 잘 연구든 sequence2sequence 패러다음을 사용하지는 않았습니다. 그래서 speech quality와 정확도를 향상시키기에 큰 개선 여지가 남아 있습니다.
마지막으로, 모든 위 연구들은 GRID corpus에 대해서 결과를 보였는데, 이 data는 매우 적은 vocabulary를 포함하며, larget vocabulary setting에서는 잘 동작하지 못합니다. 그래서 저자들은 새로운 dataset을 제안했으며, 이 dataset은 YouTube video clip에서 수집되었으며, 자연스러운 음성 변화와 머리의 움직임을 상당량 포함하고 있습니다.
Lip to Text Generation
lip to text generation도 단어가 부족하고 dataset이 작다는 한계가 있었습니다. 하지만 lip to speech와 다르게 일상 생활에서 open vocabulary lip to text를 다루는 연구들이 있습니다. transformer sequence to sequence model을 사용하여 주어진 silent lip movement sequence로 sentence를 생성합니다. 이러한 연구들도 입술 움직임을 읽을 때 여러 문제가 존재하는데, 특히 본질적인 모호성과 language model을 사용하는 것에 대한 문제가 있습니다. 저자들의 task는 lip to text generation보다 더 복잡합니다.
Text to Speech Generation
최근 몇 년동안, neural TTS model은 주어진 text를 condition으로 하여 고품질의 natural speech를 생성합니다. attention mechanism을 사용하는 sequence-to-sequence learning을 사용하면 auto-regressive 상태로 mel-spectrogram을 생성합니다. 저자들은 Lip2Wav라는 model을 제안하며, Tacotron 2를 수정했으며 text 대신 facce sequence를 condition으로 합니다.
Speaker-Specific Lip2Wav Dataset
lip to speech or text를 위한 현재 존재하는 dataset들은 2가지로 나눌 수 있습니다. 1) 작고 constrained vocabulary, 예를 들어 GRID, TCD-TIMIT 2) unconstrained, open vocabulary multi-speaker, LRS2, LRW, LRS3.
2)에 속하는 dataset들은 각 speaker마다 2~5분 사이의 video만 포함하고 있으며, model이 speaker에 맞춰 시각적 cue를 학습하기에 어려움이 존재하게 됩니다. 시각적 cue가 있어야 입술 움직임으로부터 정확한 speech를 추론할 수 있기 때문에 필수적인 요소입니다. 저자들은 unconstrained lip to speech synthesis를 위한 benchmark dataset을 제안합니다. 이 dataset은 'speaker의 입 모양을 통해 해당 speaker의 speech style과 content를 얼마나 잘 추론할 수 있을까?"에 대한 질문을 답하기 위해 제작되었습니다. Lip2Wav dataset을 만들기 위해 저자들은 5명의 speaker가 각 120시간 정도의 이야기를 하는 talking face video를 준비했습니다. 이 video들은 온라인 강의 영상과 chess 분석 영상입니다. 저자들은 영어만 존재하도록 만들었습니다. 각 speaker마다 약 20시간 정도 자연스러운 speech를 하고 있으며, 약 5000단어 정도의 vocabulary size를 띄고 있습니다. 저자들의 dataset은 GRID나 TIMIT보다 훨씬 더 unconstrained하고 realistic합니다. 이는 speaker에 맞춰 입 모양으로 speech를 생성하는 task에 이상적입니다.

Lip to Speech Synthesis in the Wild
face image sequence I = (I_1, I_2, ... , I_T)가 입술 모양과 같이 주어졌을 때, 저자들의 목표는 그에 대응하는 speech segment S = (S_1, S_2, ... , S_T')을 생성하는 것입니다. unconstrained setting에서 자연스러운 speech를 생성하기 위해, 새로운 Lip2Wav architecture를 개발했습니다.
Problem Formulation
이전에 speech representation (mel-spectrogram)을 2D-image로 다루거나 LCP feature와 같이 단일 feature vector를 사용하는 lip to speech 연구이 있었습니다. 두 경우 모두 2D CNN을 사용하여 speech representation을 decode합니다. 이렇게 함으로써, 미래 time step이 현재 time step에 영향을 주는 것과 같이 sequential speech data를 model하는 순서를 위반하게 됩니다. 하지만 저자들은 standard sequence-to-sequence learning paradigm을 사용합니다. 구체적으로, 각 output speech time-step S_k는 이전 speech time-step S들과 input facce image sequence에 조건부 분포로 modelling됩니다. 각 output speech time-step의 확률 분포는 다음과 같이 modelling됩니다.

Lip2Wav의 구조는 다음과 같습니다.
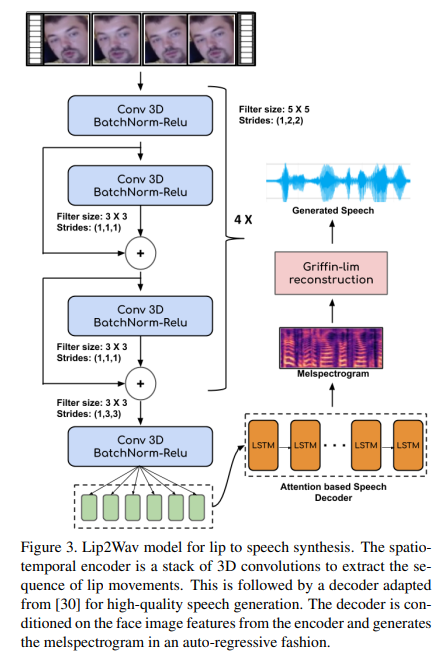
위 그림과 같이 Lip2Wav는 2가지 module로 구성됩니다. 1) Spatio-temporal face encoder 2) Attention-based speech decoder입니다. module은 end-to-end 방식으로 동시에 학습됩니다. sequence-to-sequence 방식은 model이 암묵적인 speech level language model을 학습할 수 있게 만들어주며, 이는 homophene을 구분하는 데 도움을 줍니다.
Speech Representation
명료한 음성을 복구할 수 있는 여러 가지 output representation을 가질 수 있지만, 이는 trade-off 관계입니다. LPC feature는 저차원이고 생성하기 쉽습니다. 하지만 복원된 음성은 기계음이 들리고 인조적인 소리가 들립니다. raw wavefrom을 생성할 수도 있지만, output이 고차원이며(16000 samples per second) network를 학습시키는 과정을 상당히 비효율적으로 만듭니다. 그래서 저자들은 입술 움직임을 condition으로 하여 mel-spectrogram을 생성했습니다.
Spatio-temporal Face Encoder
저자들의 visual input은 face image의 short video sequence입니다. model은 세밀한 입술 움직임 sequence를 추출하고 처리할 수 있어야만 합니다. 3D convolutional neural network는 spatio-temporal video data를 처리하는 여러 task에서 효과적임이 증명되었습니다. 이 논문에서 저자들은 입술 움직임의 spatio-temporal information을 3D convolution을 stack하여 encode했습니다. 저자들의 network의 input은 T x H x W x 3 차원의 facial image의 sequence입니다. 여기서 T는 input video sequence의 time-step (frame) 수를 의미하고, H와 W는 face image의 spatial dimension입니다. 저자들은 점진적으로 feature map을 공간적으로 축소하면서 시간 dimension T는 보존하면서 down-sample합니다. 그리고 저자들은 residual skip connection과 batch noormalization을 사용합니다. encoder는 T개의 facial image에 대해 각각 D차원 single vector를 output합니다. 그래서 T x D 차원 spatio-temporal feature를 추출할 수 있으며, feature를 speech decoder에 feed합니다. encoder로 구한 embedding의 각 time-step은 미래 입술 움직임에 대한 information도 포함하고 있기 때문에 그다음 step을 생성할 때 도움을 줄 수 있습니다.
Attention-based Speech Decoder
고품질의 speech를 생성하기 위해, 저자들은 최근 TTS model들의 돌파구를 사용합니다. text input을 condition으로 하여 mel-spectrogram을 생성하는 Tacotron 2 decoder를 사용합니다. 저자들의 연구에서는 encoded face embedding을 사용하여 decoder의 condition으로 사용합니다. encoder와 decoder는 생성된 mel-spectrogram과 ground-truth mel-spectrogram 사이의 L1 reconstruction loss를 minimize함으로써 end-to-end 방식으로 학습됩니다.
Gradual Teacher Forcing Decay
학습 초기에는 (30K iteration 이전까지) teacher forcing을 이용합니다. 이를 통해 decoder가 speech level language model을 학습하는 데 도움을 줄 수 있으며, homophene을 구별하는 데 도움을 줄 수 있다고 저자들은 가설을 세웠습니다. 비슷한 관측이 lip to text 실험에서 발견되었으며, 해당 실험에서는 transformer 기반 sequence-to-sequence model입니다. 학습 과정에서 저자는 점진적으로 teacher forcing을 감소시켰으며, 이를 통해 model이 입술 영역에만 attend하도록 만들었으며 implicit language model이 train set vocabulary에 over-fitting되는 것을 방지할 수 있습니다.
Context Window Size
speech time-step을 추론할 때 visual context window size는 model이 homophenes를 구분하는 데 도움을 줄 수 있습니다. 저자들은 이전 연구들보다 6배 더 큰 context size를 사용했으며, 이를 통해 speech의 정확도를 상당히 향상시킬 수 있었습니다.
Benchmark Datasets and Training Details
Datasets
저자들은 unconstrained large vocabulary setting에서 single-speaker lip to speech synthesis를 목표로 합니다. 이전 연구들처럼 Lip2Wav model을 GRID corpus로 학습했으며 TCD-TIMIT lip speaker corpus로도 학습했습니다. 그 다음 저자들은 Lip2Wav dataset에서 새로운 5명 speaker에 대해 train했습니다.
Training Methodology and Hyper-parameters
저자들은 3초 sequence를 무작위로 sampling하여 train에 사용했습니다. 다양한 context window size를 가져가는 것이 효과적이라는 것을 저자들은 알아냈다고 합니다. 저자들은 SFD face detector를 사용하여 video frame에서 face를 detect하고 crop했습니다. crop된 face는 48x48로 resize했습니다. 선택된 짧은 video segment에 대응하는 audio의 mel-spectrogram은 training할 때 ground-truth로 사용되었습니다. GRID, TIMIT과 같이 작은 dataset을 사용해 학습할 때, 저자들은 overfitting을 막기 위해 hidden dimension을 절반으로 줄였습니다. 저자들은 batch size를 32로 했으며 mel reconstruction loss가 안정적일 때까지 반복했는데, 최소 30K iteration은 진행했다고 합니다. unconstrained single-speaker에 대해 실험을 진행할 때, 수렴은 200K interation 정도에서 이뤄졌다고 합니다. Adam optimizer를 사용했습니다.
Speech Generation at Test Time
inference할 때, 저자들은 lip movement의 sequence를 받은 상태로 auto-regressive하게 speech를 생성했습니다. 어떤 길이의 lip sequence가 들어와도 speech를 생성할 수 있었다고 합니다. 저자들은 연속적인 T초 window를 받아서 각 window에 대해 독립적으로 speech를 생성한 다음 concatenate했다고 합니다. 저자들은 boundary effect를 조절하기 위해 sliding window를 조금 overlap되는 것을 유지했습니다. 저자들은 생성된 mel-spectrogram에 standard Griffin-Lim algorithm을 사용하여 waveform을 얻었습니다. 생성된 mel-spectrogram에 neural vocoder를 사용하면 성능이 좋지 않다는 것을 발견했으며, 최신 TTS system보다 훨씬 낮은 정확도를 보였다고 합니다. 마지막으로 어떤 길이든 lip sequence에 대해 speech를 생성하는 능력은 강조할만한 가치가 있다고 합니다. sentence level에서 학습된 lip to text 연구들이 4~5초를 겨우 넘는 긴 문장에 대해서는 급격히 성능이 떨어지기 때문입니다.
Multi-speaker Word-level Lip to Speech
저자들의 Lip2Wav이 single-speaker lip to speech에서는 뛰어난 성능을 보였고, random identity에 대한 multi speaker lip to speech synthesis에서도 baseline 정도의 성능을 보였습니다. speaker embedding을 input으로 model에 주어서 multi speaker lip to speech synthesis가 가능했다고 합니다. 저자들은 LRW dataset을 이용해 baseline result를 구했습니다. LRW datsaet은 word-level lip reading을 위한 dataset입니다. 결과는 다음과 같습니다.
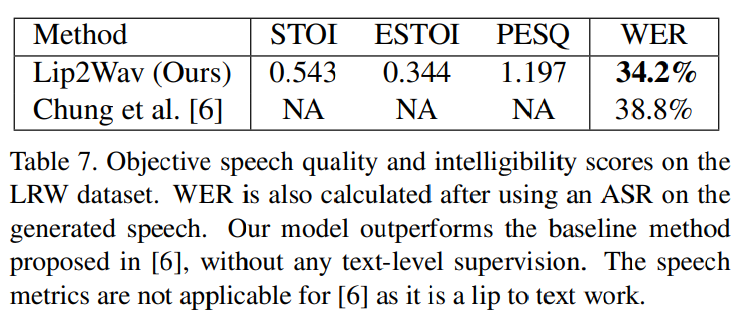
저자들의 multi-speaker Lip2Wav model을 LRW test set으로 test한 결과입니다. 이전 연구들은 multi-spekaer case에 대해 lip to speech를 다루지 않았기 때문에 비교 대상이 없었습니다. 저자들의 model의 WER은 LRW를 가지고 lip to text를 한 연구들의 baseline 정도라고 합니다.
Conclusion
이 논문에서 저자들은 입술 움직임을 기반으로 speech를 합성하는 연구를 진행했습니다. 저자들은 각 speaker에 focusing하는 방식으로 문제를 해결했습니다. 저자들은 large scale benchmark dataset을 만들어서 unconstrained, large vocabulary single-speaker lip to speceh synthesis를 수행할 수 있도록 학습했습니다. 저자들은 sequence-to-sequence problem으로 문제를 정의했으며 이전 method보다 훨씬 정확하고 자연스러운 speech를 생성할 수 있었습니다.



